Лекция
Это продолжение увлекательной статьи про дисперсионный анализ.
...
Вам нужно сделать определенные усилия, чтобы овладеть техникой дисперсионного анализа, реализованной на STATISTICA, и ощутить все ее преимущества в конкретных исследованиях.
Управление факторами. Предположим, что в рассмотренном выше примере анализа двух выборок мы добавим еще один фактор, например, Пол - Gender. Пусть каждая группа теперь состоит из 3 мужчин и 3 женщин. План этого эксперимента можно представить в виде таблицы 2 на 2:
| Экспериментальная группа 1 |
Экспериментальная группа 2 |
|
|---|---|---|
| Мужчины |
2 3 1 |
6 7 5 |
| Среднее | 2 | 6 |
| Женщины |
4 5 3 |
8 9 7 |
| Среднее | 4 | 8 |
До проведения вычислений можно заметить, что в этом примере общая дисперсия имеет, по крайней мере, три источника: (1) случайная ошибка (внутригрупповая дисперсия), (2) изменчивость, связанная с принадлежностью к экспериментальной группе, и (3) изменчивость, обусловленная полом объектов наблюдения. (Отметим, что существует еще один возможный источник изменчивости - взаимодействие факторов, который мы обсудим позднее). Что произойдет, если мы не будем включать пол как фактор при проведении анализа и вычислим обычный t-критерий? Если мы будем вычислять суммы квадратов, игнорируя пол (т.е. объединяя объекты разного пола в одну группу при вычислении внутригрупповой дисперсии и получив при этом сумму квадратов для каждой группы равную SS =10 и общую сумму квадратов SS = 10+10 = 20), то получим большее значение внутригрупповая дисперсии, чем при более точном анализе с дополнительным разбиением на подгруппы по полу (при этом внутригрупповые средние будут равны 2, а общая внутригрупповая сумма квадратов равна SS = 2+2+2+2 = 8).
Итак, при введении дополнительного фактора: пол, остаточная дисперсия уменьшилась. Это связано с тем, что среднее значение для мужчин меньше, чем среднее значение для женщин, и это различие в средних значениях увеличивает суммарную внутригрупповую изменчивость, если фактор пола не учитывается. Управление дисперсией ошибки увеличивает чувствительность (мощность) критерия. На этом примере видно еще одно преимущество дисперсионного анализа по сравнению с обычным t-критерием для двух выборок. Дисперсионный анализ позволяет изучать каждый фактор, управляя значениями других факторов. Это, в действительности, и является основной причиной его большей статистической мощности (для получения значимых результатов требуются меньшие объемы выборок). По этой причине дисперсионный анализ даже на небольших выборках дает статистически более значимые результаты, чем простой t-критерий.
Эффекты взаимодействия
Существует еще одно преимущество дисперсионного анализа перед обычным t-критерием: дисперсионный анализ позволяет обнаружить эффекты взаимодействия между факторами и, поэтому, позволяет проверять более сложные гипотезы. Рассмотрим еще один пример, иллюстрирующий только что сказанное. (Термин взаимодействие впервые был использован Фишером в работе Fisher, 1926)
Главные эффекты, попарные (двухфакторные) взаимодействия. Предположим, что имеется две группы студентов, причем психологически студенты первой группы настроены на выполнение поставленных задач и более целеустремленны, чем студенты второй группы, состоящей из более ленивых студентов. Разобьем каждую группу случайным образом пополам и предложим одной половине в каждой группе сложное задание, а другой - легкое. После этого измерим, насколько напряженно студенты работают над этими заданиями. Средние значения для этого (вымышленного) исследования показаны в таблице:
| Целеустремленные | Ленивые | |
|---|---|---|
| Трудное задание Легкое задание |
10 5 |
5 10 |
Какой вывод можно сделать из этих результатов? Можно ли заключить, что: (1) над сложным заданием студенты трудятся более напряженно; (2) честолюбивые студенты работают упорнее, чем ленивые? Ни одно из этих утверждений не отражает сущность систематического характера средних, приведенных в таблице. Анализируя результаты, правильнее было бы сказать, что над сложными заданиями работают упорнее только честолюбивые студенты, в то время как над легкими заданиями только ленивые работают упорнее. Другими словами характер студентов и сложность задания взаимодействуя между собой влияют на затрачиваемое усилие. Это является примером попарного взаимодействия между характером студентов и сложностью задания. Заметим, что утверждения 1 и 2 описывают главные эффекты.
Взаимодействия высших порядков. В то время как объяснить попарные взаимодействия еще сравнительно легко, взаимодействия высших порядков объяснить значительно сложнее. Представьте, что в рассматриваемый выше пример, введен еще один фактор пол и получена следующая таблица средних значений:
| Женщины | Целеустремленные | Ленивые |
|---|---|---|
| Трудное задание Легкое задание |
10 5 |
5 10 |
| Мужчины | Целеустремленные | Ленивые |
| Трудное задание Легкое задание |
1 6 |
6 1 |
Какие теперь выводы можно сделать из полученных результатов? Графики средних позволяют объяснять сложные эффекты. Модуль дисперсионного анализа позволяет строить эти графики практически одним щелчком мыши. Изображение на этих графике внизу представляет собой изучаемое трехфакторное взаимодействие.
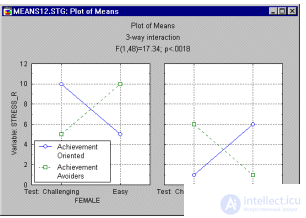
Глядя на график, можно сказать, что у женщин существует взаимодействие между характером и сложностью теста: целеустремленные женщины работают над трудным заданием более напряженно, чем над легким. У мужчин то же взаимодействие носит обратный характер. Видно, что описание взаимодействия между факторами становится более запутанным.
Общий способ описания взаимодействий. В общем случае взаимодействие между факторами описывается в виде изменения одного эффекта под воздействием другого. В рассмотренном выше примере двухфакторное взаимодействие можно описать как изменение главного эффекта фактора, характеризующего сложность задачи, под воздействием фактора, описывающего характер студента. Для взаимодействия трех факторов из предыдущего параграфа можно сказать, что взаимодействие двух факторов (сложности задачи и характера студента) изменяется под воздействием Пола. Если изучается взаимодействие четырех факторов, можно сказать, что взаимодействие трех факторов, изменяется под воздействием четвертого фактора, т.е. существуют различные типы взаимодействий на разных уровнях четвертого фактора. Оказалось, что во многих областях взаимодействие пяти или даже большего количества факторов не является чем-то необычным.
| В начало |
Сложные планы
В этом разделе будет дан обзор основных "кирпичиков", из которых строятся сложные планы.
Для просмотра других разделов Вводного обзора выберите соответствующее название ниже.
См. Методы дисперсионного анализа, Компоненты дисперсии и смешанные модели ANOVA/ANCOVA и Планирование экспермента.
Межгрупповые планы и планы с повторными измерениями
При сравнении двух различных групп обычно используется t-критерий для независимых выборок (из модуля Основные статистики и таблицы). Когда сравниваются две переменные на одном и том же множестве объектов (наблюдений), используется t-критерий для зависимых выборок. Для дисперсионного анализа также важно зависимы или нет выборки. Если имеются повторные измерения одних и тех же переменных (при разных условиях или в разное время) для одних и тех же объектов, то говорят о наличии фактора повторных измерений (называемого такжевнутригрупповым фактором, поскольку для оценки его значимости вычисляется внутригрупповая сумма квадратов). Если сравниваются разные группы объектов (например, мужчины и женщины, три штамма бактерий и т.п.), то разница между группами описывается межгрупповым фактором. Способы вычисления критериев значимости для двух описанных типов факторов различны, но общая их логика и интерпретации совпадает.
Меж- и внутригрупповые планы. Во многих случаях эксперимент требует включение в план и межгруппового фактора, и фактора повторных измерений. Например, измеряются математические навыки студентов женского и мужского пола (где пол -межгрупповой фактор) в начале и в конце семестра. Два измерения навыков каждого студента образуют внутригрупповой фактор (или фактор с повторными измерениями). Интерпретация главных эффектов и взаимодействий для межгрупповых факторов и факторов повторных измерений совпадает, и оба типа факторов могут, очевидно, взаимодействовать между собой (например, женщины приобретают навыки в течение семестра, а мужчины их теряют).
Неполные (гнездовые) планы
Во многих случаях можно пренебречь эффектом взаимодействия. Это происходит или когда известно, что в популяции эффект взаимодействия отсутствует, или когда осуществление полногофакторного плана невозможно. Например, пусть изучается влияние четырех добавок к топливу на расход горючего. Выбираются четыре автомобиля и четыре водителя. Полный факторныйэксперимент требует, чтобы каждая комбинация: добавка, водитель, автомобиль - появились хотя бы один раз. Для этого нужно не менее 4 x 4 x 4 = 64 групп испытаний, что требует слишком больших временных затрат. Кроме того, вряд ли существует взаимодействие между водителем и добавкой к топливу. Принимая это во внимание, можно использовать план типа Латинские квадраты, в котором содержится лишь 16 групп испытаний (четыре добавки обозначаются буквами A, B, C и D):
| Автомобиль | ||||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Водитель 1 Водитель 2 Водитель 3 Водитель 4 |
A B C D |
B C D A |
C D A B |
D A B C |
Латинские квадраты описаны в большинстве книг по планированию экспериментов (например, Hays, 1988; Lindman, 1974; Milliken and Johnson, 1984; Winer, 1962), и здесь они не будут детально обсуждаться. Отметим, что латинские квадраты это неnолные планы, в которых участвуют не все комбинации уровней факторов. Например, водитель 1 управляет автомобилем 1 только с добавкой А, водитель 3 управляет автомобилем 1 только с добавкой С. Уровни фактора добавки (A, B, C и D) вложены в ячейки таблицы автомобиль x водитель как яйца в гнезда. Это мнемоническое правило полезно для понимания природы гнездовых планов. Модуль Дисперсионный анализ предоставляет простые способы анализ планов такого типа.
Отметим, что анализ планов такого типа возможен и в некоторых других модулях системы STATISTICA. Подробнее см. в разделе Методы дисперсионного анализа. В частности, модульКомпоненты дисперсии и смешанные модели ANOVA/ANCOVA очень эффективен при анализе планов с несбалансированной вложенностью (т.е. когда вложенные факторы имеют различное число уровней при разных уровнях факторов, в которые они вложены), очень больших гнездовых планов (например, с общим числом уровней более 200) или иерархически вложенных планов (содержащих или не содержащих случайные факторы).
| В начало |
Ковариационный анализ (ANCOVA)
Основная идея
В разделе Основные идеи кратко обсуждалась идея управления факторами и то, каким образом включение аддитивных факторов позволяет уменьшить остаточную сумму квадратов и увеличить статистическую мощность плана. Все это может быть распространено и на переменные с непрерывным множеством значений. Когда такие непрерывные переменные включаются в план в качестве факторов, они называются ковариатами.
Для просмотра других разделов Вводного обзора выберите соответствующее название ниже.
Фиксированные ковариаты
Предположим, что сравниваются математические навыки двух групп студентов, которые обучались по двум различным учебникам. Предположим также, что имеются дополнительные данные о коэффициенте интеллекта (IQ) каждого студента. Можно предположить, что коэффициент интеллекта связан с математическими навыками, и использовать эту информацию. Для каждой из двух групп студентов можно вычислить коэффициент корреляции между IQ и математическими навыками (см. Основные статистики и таблицы). Используя этот коэффициент корреляции, можно выделить долю дисперсии в группах, объясняемую IQ и необъясняемую долю дисперсии (см. Элементарные понятия статистики и Основные статистики и таблицы). Оставшаяся доля дисперсии используется при проведении анализа как дисперсия ошибки. Если имеется корреляция между IQ и математическими навыками, то таким образом можно существенно уменьшить дисперсию ошибки SS/(n-1).
Влияние ковариат на F критерий. F критерий оценивает статистическую значимость различия средних в группах, при этом вычисляется отношение межгрупповой дисперсии (MSошибка) к дисперсии ошибок (MSошибка). Если MSошибка уменьшается, например, при учете фактора IQ, значение F увеличивается.
Множество ковариат. Рассуждения, использованные выше для одной ковариаты (IQ), легко распространяются на несколько ковариат. Например, кроме IQ, можно включить измерение мотивации, пространственного мышления и т.д. Вместо обычного коэффициента корреляции при этом используется множественный коэффициент корреляции (см. раздел Множественная регрессия).
Когда значение F-критерия уменьшается. Иногда введение ковариат в план эксперимента уменьшает значение F-критерия. Обычно это указывает на то, что ковариаты коррелированы не только с зависимой переменной (например, математическими навыками), но и с факторами (например, с разными учебниками). Предположим, что IQ измеряется в конце семестра, после почти годового обучения двух групп студентов по двум разным учебникам. Хотя студенты разбивались на группы случайным образом, может оказаться, что различие учебников настолько велико, что и IQ и математические навыки в разных группах будут сильно различаться. В этом случае, ковариаты не только уменьшают дисперсию ошибок, но и межгрупповую дисперсию. Другими словами, после контроля за разностью IQ в разных группах, разность в математических навыках уже будет несущественной. Ту же мысль можно выразить иначе: после "исключения" влияния IQ, неумышленно исключается и влияние учебника на развитие математических навыков.
Скорректированные средние. Когда ковариата влияет на межгрупповой фактор, следует вычислять скорректированные средние, т.е. такие средние, которые получаются после удаления всех оценок ковариат.
Взаимодействие между ковариатами и факторами. Также как исследуется взаимодействие между факторами, можно исследовать взаимодействия между ковариатами и группами факторов. Предположим, что один из учебников особенно подходит для умных студентов. Второй учебник для умных студентов скушен, а для менее умных студентов этот же учебник труден. В результате имеется положительная корреляция между IQ и результатом обучения в первой группе (более умные студенты, лучше результат) и нулевая или небольшая отрицательная корреляция во второй группе (чем умнее студент, тем менее вероятно приобретение математических навыков из второго учебника). В некоторых исследованиях эта ситуация обсуждается как пример нарушения предположений ковариационного анализа (см. Предположения и последствия их нарушения). Однако так как в модуле Дисперсионный анализ используются самые общие способы ковариационного анализа, можно, в частности, оценить статистическую значимость взаимодействия между факторами и ковариатами.
Переменные ковариаты
В то время как фиксированные ковариаты обсуждаются в учебниках достаточно часто, переменные ковариаты упоминаются намного реже. Обычно, при проведении экспериментов с повторными измерениями, нас интересуют различия в измерениях одних и тех же величин в разные моменты времени. А именно, нас интересует значимость этих различий. Если одновременно с измерениями зависимых переменных проводится измерение ковариат, можно вычислить корреляцию между ковариатой и зависимой переменной. Например, можно изучать интерес к математике и математические навыки в начале и в конце семестра. Интересно было бы проверить, коррелированы ли между собой изменения в интересе к математике с изменением математических навыков. Модуль Дисперсионный анализ в STATISTICA автоматически оценивает статистическую значимость изменения ковариат в тех планах, где это возможно.
| В начало |
Многомерные планы: Многомерный дисперсионный и ковариационный анализ
Для просмотра других обзорных разделов выберите соответствующее название ниже.
Межгрупповые планы
Все рассматриваемые ранее примеры включали только одну зависимую переменную. Когда одновременно имеется несколько зависимых переменных, возрастает лишь сложность вычислений, а содержание и основные принципы не меняются. Например, проводится исследование двух различных учебников. При этом изучаются успехи студентов в изучении физики и математики. В этом случае имеются две зависимые переменные и нужно выяснить, как влияют на них одновременно два разных учебника. Для этого можно воспользоваться многомерным дисперсионным анализом (MANOVA). Вместо одномерного F критерия, используется многомерный F критерий (лямбда-критерий Уилкса), основанный на сравнении ковариационной матрицы ошибок и межгрупповой ковариационной матрицы. Если зависимые переменные коррелированы между собой, то эта корреляция должна учитываться при вычислении критерия значимости. Очевидно, если одно и то же измерение повторяется дважды, то ничего нового получить при этом нельзя. Если к имеющемуся измерению добавляется коррелированное с ним измерение, то получается некоторая новая информация, но при этом новая переменная содержит избыточную информацию, которая отражается в ковариации между переменными.
Интерпретация результатов. Если общий многомерный критерий значим, можно заключить, что соответствующий эффект (например, тип учебника) значим. Однако встают следующие вопросы. Влияет ли тип учебника на улучшение только математических навыков, только физических навыков, или одновременно на улучшение тех и других навыков. В действительности, после получения значимого многомерного критерия, для отдельного главного эффекта или взаимодействия исследуются одномерные F-критерии. Другими словами, отдельно исследуются зависимые переменные, которые вносят вклад в значимость многомерного критерия.
Планы с повторными измерениями
Если измеряются математические и физические навыки студентов в начале семестра и в конце семестра, то это и есть повторные измерения. Изучение критерия значимости в таких планах это логическое развитие одномерного случая. Заметим, что методы многомерного дисперсионного анализа обычно также используются для исследования значимости одномерных факторов повторных измерений, имеющих более чем два уровня. Соответствующие применения будут рассмотрены позднее в этой части.
Суммы значений переменной и дисперсионный анализ
Даже опытные пользователи одномерного и многомерного дисперсионного анализа часто приходят в затруднение, получая разные результаты при применении многомерного дисперсионного анализа, например, для трех переменных, и при применении одномерного дисперсионного анализа к сумме этих трех переменных, как к одной переменной. Идея суммирования переменных состоит в том, что каждая переменная содержит в себе некоторую истинную переменную, которая и исследуется, а также случайную ошибку измерения. Поэтому при усреднении значений переменных, ошибка измерения будет ближе к 0 для всех измерений и усредненное значений будет более надежным. На самом деле, в этом случае применение дисперсионного анализа к сумме переменных разумно и является мощным методом. Однако, если зависимые переменные по своей природе многомерны, то суммирование неуместно. Например, пусть зависимые переменные состоят из четырех показателей успеха в обществе. Каждый показатель характеризует совершенно независимую сторону человеческой деятельности (например, профессиональный успех, преуспевание в бизнесе, семейное благополучие и т.д.). Сложение этих переменных подобно сложению яблока и апельсина. Сумма этих переменных не будет подходящим одномерным показателем. Поэтому с такими данными нужно обходится как с многомерными показателями в многомерном дисперсионном анализе.
| В начало |
Анализ контрастов и апостериорные критерии
Для просмотра других обзорных разделов выберите соответствующее название ниже.
Почему сравниваются отдельные множества средних?
Обычно гипотезы относительно экспериментальных данных формулируются не просто в терминах главных эффектов или взаимодействий. Примером может служить такая гипотеза: некоторый учебник повышает математические навыки только у студентов мужского пола, в то время как другой учебник примерно одинаково эффективен для обоих полов, но все же менее эффективен для мужчин. Можно предсказать, что эффективность учебника взаимодействует с полом студента. Однако этот прогноз касается также природы взаимодействия. Ожидается значительное различие между полами, обучающимися по одной книге, и практически не зависимые от пола результаты для обучающихся по другой книге. Такой тип гипотез обычно исследуется с помощью анализа контрастов.
Анализ контрастов
Если говорить коротко, то анализ контрастов позволяет оценивать статистическую значимость некоторых линейных комбинаций факторов сложного плана. Анализ контрастов главный и обязательный элемент любого сложного плана дисперсионного анализа. Модуль Дисперсионный анализ имеет достаточно разнообразные возможности анализа контрастов, которые позволяют выделять и анализировать любые типы сравнений средних (способы задания контрастов описаны в разделе Примечания).
Апостериорные критерии
Иногда в результате обработки эксперимента обнаруживаются неожиданные различия в средних. Хотя в большинстве случаев творческий исследователь сможет объяснить эти различия, ему сложно провести дальнейший анализ. Эта проблема является одной из тех, для которых используются апостериорные критерии, то есть критерии, не использующие априорные гипотезы. Для иллюстрации рассмотрим следующий эксперимент. Предположим, что на 100 карточках записаны числа от 1 до 10. Опустив все эти карточки в шапку, мы случайным образом выбираем 20 раз по 5 карточек, и вычисляем для каждой выборки среднее значение (среднее чисел, записанных на карточки). Можно ли ожидать, что найдется две выборки, у которых средние значения значимо отличаются? Это очень правдоподобно! Выбирая две выборки с максимальным и минимальным средним, можно получить разность средних значений, сильно отличающуюся от разности средних значений, например, первых двух выборок. Эту разность можно исследовать, например, с помощью анализа контрастов. Если не вдаваться в детали, то существует несколько, так называемых апостериорных критериев, которые основаны в точности на первом сценарии (взятие экстремальных средних из 20 выборок), т. е. эти критерии основаны на выборе наиболее отличающихся средних для сравнения всех средних значений в плане. Модуль Дисперсионный анализ предлагает широкий выбор таких критериев. Когда в эксперименте встречаются неожиданные результаты, то используются апостериорные процедуры для исследования их статистической значимости.
| В начало |
Предположения и последствия их нарушения
Для просмотра других обзорных разделов выберите соответствующее название ниже.
Нормальность распределения
Предположения. Имеются следующие предположения дисперсионного анализа: зависимая переменная измерена в интервальной шкале (см. раздел Элементарные понятия статистики); зависимая переменная имеет нормальное распределение внутри каждой группы. Модуль Дисперсионный анализ содержит широкий набор графиков и статистик для проверки этих предположений.
Эффекты нарушения. Вообще F-критерий очень устойчив к отклонению от нормальности (подробнее см. Lindman, 1974). Если эксцесс (см. Основные статистики и таблицы) больше 0, то значение статистики F может стать очень маленьким. Нулевая гипотеза при этом не может быть отвергнута, хотя она и не верна. Ситуация меняется на противоположную, если эксцесс меньше 0. Асимметрия распределения обычно незначительно влияет на F статистику. Если число наблюдений в ячейке достаточно большое, то отклонение от нормальности не имеет особого значения в силу центральной предельной теоремы, в соответствии с которой, распределение среднего значения при большом объеме выборки близко к нормальному, независимо от начального распределения. Подробное обсуждение устойчивости F статистики можно найти в Box and Anderson (1955) или Lindman (1974).
Однородность дисперсии
Предположения. Предполагается, что дисперсии в разных группах одинаковы. Это предположение называется предположением об однородности дисперсии. Напомним, что в предыдущих разделах описывая вычисление суммы квадратов ошибок мы производили суммирование внутри каждой группы. Если дисперсии в двух группах отличаются друг от друга, то сложение их не естественно и не дает верной оценки общей внутригрупповой дисперсии (так как в этом случае общей дисперсии вообще не существует). Модуль Дисперсионный анализ -ANOVA/MANOVAсодержит большой набор статистических критериев, позволяющих обнаружить неоднородность дисперсии.
Эффекты нарушения. Линдман (Lindman 1974, стр. 33) показывает, что F критерий вполне устойчив относительно нарушения предположений однородности дисперсии (см. Box, 1954a, 1954b; Hsu, 1938).
Специальный случай: коррелированность средних и дисперсий. Бывают случаи, когда F статистика может вводить в заблуждение. Это бывает, когда в ячейках плана средние значения коррелированы с дисперсией. Модуль Дисперсионный анализ позволяет строить диаграммы рассеяния дисперсии или стандартного отклонения относительно средних для обнаружения такой корреляции. Причина, по которой такая корреляция опасна, состоит в следующем. Представим себе, что имеется 8 ячеек в плане, 7 из которых имеют почти одинаковое среднее, а в одной ячейке среднее намного больше остальных. Тогда F критерий может обнаружить статистически значимый эффект. Но предположим, что в ячейке с большим средним значением и дисперсия значительно больше остальных, т.е. среднее значение и дисперсия в ячейках зависимы (чем больше среднее, тем больше дисперсия). В этом случае большое среднее значение ненадежно, так как оно может быть вызвано большой дисперсией данных. Однако F статистика, основанная на объединенной дисперсии внутри ячеек, будет фиксировать большое среднее, хотя критерии, основанные на дисперсии в каждой ячейке не все различия в средних будут считать значимыми.
Такой характер данных (большое среднее и большая дисперсия) часто встречается, когда имеются резко выделяющиеся наблюдения. Одно или два резко выделяющихся наблюдений сильно смещают среднее значение и очень увеличивают дисперсию.
Однородность дисперсии и ковариаций
Предположения. В многомерных планах, с многомерными зависимыми измерениями, также применяются предположение об однородности дисперсии, описанные ранее. Однако так как существуют многомерные зависимые переменные, то требуется так же чтобы их взаимные корреляции (ковариации) были однородны по всем ячейкам плана. Модуль Дисперсионный анализпредлагает разные способы проверки этих предположений.
Эффекты нарушения. Многомерным аналогом F- критерия является лямбда-критерий Уилкса. Не так много известно об устойчивости (робастности) лямбда-критерия Уилкса относительно нарушения указанных выше предположений. Тем не менее, так как интерпретация результатов модуля Дисперсионный анализ основывается обычно на значимости одномерных эффектов (после установления значимости общего критерия), обсуждение робастности касается, в основном, одномерного дисперсионного анализа. Поэтому должна быть внимательно исследована значимость одномерных эффектов.
Специальный случай:ковариационный анализ. Особенно серьезные нарушения однородности дисперсии/ковариаций могут происходить, когда в план включаются ковариаты. В частности, если корреляция между ковариатами и зависимыми измерениями различна в разных ячейках плана, может
продолжение следует...
Часть 1 Дисперсионный анализ
Часть 2 - Дисперсионный анализ
Часть 3 Вау!! 😲 Ты еще не читал? Это зря! - Дисперсионный анализ
| В начало |
Надеюсь, эта статья про дисперсионный анализ, была вам полезна, счастья и удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое дисперсионный анализ и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Теория вероятностей. Математическая статистика и Стохастический анализ
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии