Лекция
прохождение препятствий врагами и неигровыми персоонажами(обход, перепрыгивание, запрыгивание, ползание и т. д.) может быть реализовано с помощью различных алгоритмов и подходов, в зависимости от сложности ИИ и среды. Вот основные алгоритмы и методы, используемые для прохождения препятствий:
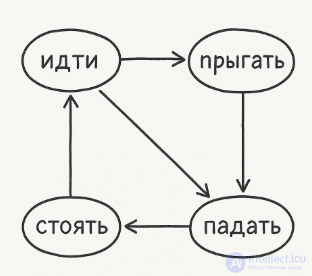
Каждое состояние описывает поведение (например, "идти", "прыгать", "стоять", "падать"). При обнаружении препятствия — переход в соответствующее состояние:
Идти → препятствие → Прыжок
Прыжок → достижение платформы → Идти
Простой, хорошо работает для патрулирующих врагов и NPC.
Сканирование пространства лучами вниз, вперед и вверх позволяет:
определять обрывы (если нет земли под ногами);
видеть стены перед собой;
понимать, можно ли перепрыгнуть.затем используются простые Физические проверки + условия
Подходит для простых ИИ:
if (isGroundAhead() && !isWallAhead())
{
moveRight();
}
else
if (isWallAhead() && canJump())
{
jump();
}
Используется в Unity, Godot, Phaser и других движках.

Применим для более сложных уровней, где нужно добраться до цели, обойдя препятствия:
Мир делится на сетку (в 2D — тайловая карта);
A* находит кратчайший путь;
Спрайт двигается по найденным координатам.
Требует настройки "стоимости" тайлов: можно ли прыгнуть туда, какой длины прыжок и т. д.
Применяется в случае, если A* не подходит.
Пространство разбивается на платформы и связки между ними (можно ли прыгнуть с одной на другую).
Персонаж выбирает оптимальный маршрут по вершинам графа.
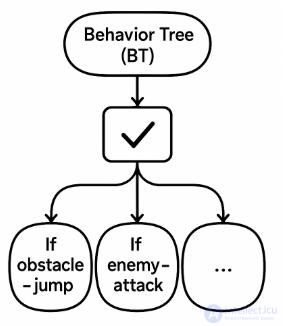
Структурированная форма ИИ-поведения.
Можно задать: "Если препятствие — прыгни", "Если враг — атакуй", и т. д.
Очень гибкая система, часто используется в больших проектах.
Для продвинутых ИИ:
ИИ обучается самостоятельно преодолевать препятствия;
Используется в экспериментах (например, в OpenAI Gym);
Непрактично для простых игр— дорогая разработка и нестабильное поведение.
пример
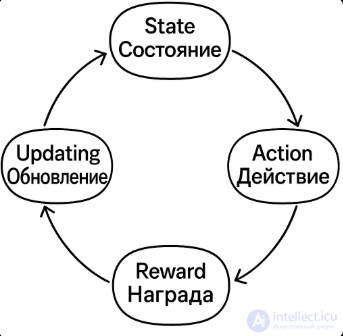
Для прохождения пути в игре с помощью обучения с подкреплением (Reinforcement Learning, RL), можно представить процесс в виде последовательных этапов, которые повторяются в цикле. Вот как бы это выглядело пошагово:
Инициализация:
Агент стартует с начальным состоянием.
Начальные значения Q-функции (или политика) случайны или нулевые.
Получение текущего состояния среды:
Например: "Я стою перед ямой", или "Передо мной враг".
Выбор действия:
Используется стратегия (например, ε-жадная): агент выбирает либо лучшее известное действие, либо случайное для исследования.
Например: "Прыгнуть", "Атаковать", "Пойти вправо".
Выполнение действия и переход:
Агент действует в среде.
Среда обновляется: новое положение, новая ситуация.
Получение награды:
Агент получает обратную связь:
+1 за успешный прыжок,
–1 за падение в яму,
+10 за достижение цели.
Обновление стратегии (обучение):
Q-функция или нейросеть корректируется с учетом нового опыта.
Агент "учится", чтобы в будущем действовать лучше.
Переход в новое состояние и повтор:
Агент теперь находится в новом состоянии, и цикл начинается заново.
| Препятствие | Возможный алгоритм решения |
|---|---|
| Обрыв | Проверка raycast вниз |
| Низкий проход | Состояние "пригнуться" |
| Стена | raycast + "прыжок" |
| Подвижная платформа | FSM + отслеживание платформ |
| Враг | FSM / Behavior Tree |

Комментарии