Лекция
Привет, мой друг, тебе интересно узнать все про алгоритмы шахматных программ, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое алгоритмы шахматных программ , настоятельно рекомендую прочитать все из категории Разработка компьютерных игр, гейм-дизайн.
Для начала рассмотрим более простую игру, например, крестики-нолики на доске 3х3. Рассмотрим начальную позицию. Тут у первого игрока (пусть это будут крестики) имеются 9 ходов (симметрию игнорируем). На каждый из них у соперника имеется 8 ответов, в свою очередь на каждый из них - по 7 ответов у крестиков и т.д. Максимальная длина игры - 9 полуходов (т.е. ходов одного из соперников), но она может кончиться и побыстрее, если кто-то выиграет.
Возьмем листок бумаги и сверху нарисуем начальную позицию. Так как из нее возможно 9 ходов, проведем из нее 9 черточек (ветвей). В конце каждой ветви нарисуем позицию, которая получается после этого хода, и в свою очередь проведем из нее ветви - ходы, возможные из данной позиции. И так далее. Полученная структура называется деревом, ибо (1) у нее есть корень - начальная позиция, (2) у нее есть листья - позиции, из которых не идет ветвей, ибо один из игроков победил или случилась ничья, и (3) она отдаленно похоже на дерево, если лист бумаги перевернуть. Крестики-нолики - простая игра, ее дерево должно уместиться на (большом) листе бумаги, но можно себе представить так же нарисованное дерево для шахмат (вроде бы есть всего 10**50 или около того различных позиций, и правило 50 ходов ограничивает максимальную длину партии ~4000 ходов). Разумеется, для такого листа бумаги не хватит всех атомов во вселенной, но представить такой лист все равно можно (я, во всяком случае, могу).
Теперь припишем каждому листу его оценку. Пусть выигрыш крестиков будет -1, ноликов - плюс 1, а ничья будет нулем. Начнем <поднимать> оценку вверх по дереву - рассмотрим вершину, непосредственно стоящую над листом (терминальной позицией). Из нее ведет несколько ветвей (в крестиках-ноликах ровно одна, но это не важно). Представим, что ход сейчас - крестиков. Он заинтересован в получении -1, поэтому из нескольких вариантов он выберет вариант с минимальным значением (-1, если возможно, а если нет, то хотя бы 0). Таким образом, он выберет минимальную оценку из тех, какую имеют его <потомки>, и припишет ее этой вершине.
Уровнем выше - очередь хода <ноликов>. Он, в свою очередь, заинтересован в получении +1, поэтому он будет максимизировать полученную снизу оценку.
В конце концов мы поднимем оценку до корня. В случае крестиков-ноликов это будет, разумеется, 0, ибо теоретическим результатом крестиков-ноликов при оптимальной игре обоих игроков является ничья. Что является теоретическим результатом шахмат науке неизвестно.
Разумеется, имея нарисованное дерево игры, играть очень легко - крестики должны выбирать ход, ведущий из текущей позиции в позицию с минимальной оценкой; нолики - в позицию с максимальной. Как легко понять, описанный алгоритм и есть обещанный минимакс.
Внимательные читатели должны были догадаться что минимакс будет работать не только на деревьях с оценками плюс/минус один, но и на деревьях, листьям которых приписаны просто действительные числа. В дальнейшем мы будем рассматривать именно такие деревья (для объяснения основных алгоритмов я буду говорить о деревьях, забыв на время о собственно играх). Кроме того, я сосредоточусь именно на определении теоретического результата игры, т.е. на подъеме оценки вверх по дереву.
Минимакс - очень трудоемкий алгоритм. Для определения теоретического результата игры размечается абсолютно все дерево. Вопрос: нельзя ли, сохранив математическую корректность минимакса, обходить поменьше?
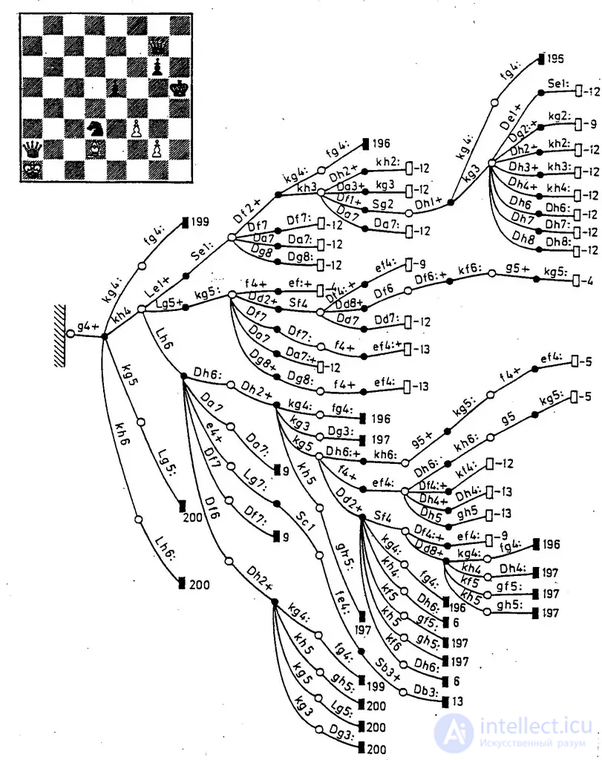
Оказывается, можно. Алгоритм называется альфа-бета. Легко доказать, что он дает те же результаты (не бойтесь, я этого делать не буду). Идея его, если объяснить на пальцах, такова:
Пусть есть корень, у него - 2 потомка, у каждого из них - по 3 потомка-листа. В корне - очередь хода мина, соответственно, в вершинах второго уровня - ход макса. Листам, которые потомки левого поддерева, приписаны оценки 0, 5, 10. Так как в вершинах второго подуровня мы максимизируем, левому поддереву припишем оценку 10.
Начинаем рассматривать правое поддерево. Пусть у самого левого листа оценка 100. А теперь - внимание! Мы знаем, что уровнем выше мы будем максимизировать. Это означает, что оценка *всего правого поддерева* будет уж не меньше 100, т.к. оставшиеся листья могут эту оценку только поднять. Кроме того мы знаем, что в начальной позиции мы будем минимизировать, и значит выберем левое поддерево, оценка которого 10.
Итого, мы получили оценку всего дерева, рассмотрев всего 4 позиции из 6. Шахматная аналогия - предположим, что я рассмотрел один из своих ходов, и обнаружил, что после всех ответов противника позиция равная. Я посмотрел, что происходит после другого моего хода, и обнаружил, что одним из своих ответов противник выигрывает коня. Рассматривать другие его ответы уже не имеет смысла - этот свой ход я уже не сделаю.
Просьба обратить внимание, что нам повезло, что в правом поддереве оценку 100 имеет самый левый лист. Будь он правым, и если при этом оба левых имеют оценку 7, нам пришлось бы обойти все 6 листьев. В наихудшем случае (мы всегда рассматриваем поддерево/лист с наилучшей оценкой в последнюю очередь) альфа-бета вырождается в минимакс. В наилучшем случае (наилучшее поддерево всегда рассматривается первым) рассматривается (очень грубо) 2*(sqrt(количества вершин, рассматриваемых минимаксом)).
Альфа-бета является алгоритмом с - ветвь отсекаются только после того, как хотя бы одного потомка оценили, и убедились, что значение этой ветви не повлияет на итоговый результат.
Разумеется, для реальных игр (шахмат, шашек, го) все дерево машина обойти не сможет. Поэтому идут на жульничество. Во-первых, все дерево не строят - никакой памяти ни у какой машины не хватит. Хранят только текущую позицию и последовательность ходов, в нее приведшую. Идешь вглубь - сделай на доске (точнее, на ее аналоге в памяти) ход. Возвращаешься - возьми ход назад (это еще не жульничество, с теоретической точки зрения то, что мы явно дерево не строим, ничего не меняет).
Во-вторых и в главных, точная оценка заменяется на приближенную. А именно, после перебора на некоторую глубину, если не случилось мата или форсированной ничьи, вместо того, чтобы перебирать дальше, мы зовем оценочную функцию, которая приписывает текущей позиции (а точнее, всему поддереву, начинающемуся с текущей позиции), некоторую оценку. Как эта функция устроена - чуть позже, а пока главное: тут мы бесповоротно порвали с теорией, ибо оценочная функция есть нечто приближенное. Вот это и есть основное жульничество - альфа-бета была научно обоснована совсем в других условиях, и почему она после введения в нее оценочной функции работает в реальных играх, не совсем понятно (точнее говоря, есть сколько угодно работ на эту тему, но мне они представляются неубедительными). Более того, искусственно создан целый класс игр, где альфа-бета в таких условиях не работает.
Как устроена оценочная функция? Во-первых, надо просто сосчитать материал. Простейший вариант: пешка - 1, конь и слон - 3, ладья - 5, ферзь - 9.
Во вторых, надо добавить позиционную оценку, и это есть самое сложное. Факторов много, в шахматных книжках приведены далеко не все, и главное - там сказано <это есть хорошо, а то плохо>, а нам надо <это есть плюс половина, а то - минус три четверти>. Соответственно, приходится сначала факторам приписывать веса с потолка, а потом отлаживать, вручную или пытаясь оптимизировать функцию в пространстве размерности несколько тысяч.
Вот несколько учитываемых факторов, с их ориентировочными весами (веса, разумеется, взяты с потолка, но за порядок величины ручаюсь):
- пара слонов - это плюс треть пешки,
- король прикрыт своими пешками - плюс пол пешки,
- конь или ферзь близки к королю (своему или чужому) - плюс сотая пешки,
- слабая или отставшая пешка - минус четверть пешки,
- ладья на полуоткрытой вертикали - плюс пять сотых пешки,
- ладья на открытой вертикали - плюс одна десятая пешки,
- пара ладей на седьмой горизонтали - плюс полпешки,
- висящая фигура - минус четверть пешки, две висящих фигуры - минус пешка, три или больше - минус три пешки.
И так далее, и так далее. Кроме того, вес многих факторов может зависеть от ситуации на доске - например, пока ферзей не разменяли, прикрытость короля может оцениваться куда выше, чем после размена. Таким образом, получаем позиционную оценку белых, складываем с материалом белых, делаем то же самое для черных, вычитаем одно из другого, и все сведено к одному числу. Красота!
К сожалению, не все так просто. Первые программы использовали только что описанный алгоритм - перебор на фиксированную глубину с вызовом там оценочной функции (если раньше мат не случился). И немедленно выяснилось, что мы можем прекратить перебор, например, в середине размена, или при "висящем" ферзе, или когда на доске стоит мат в один ход, и тот факт, что у атакующей стороны не хватает ладьи, не имеет никакого значения. Были попытки учитывать все это в оценочной функции, но она тогда становилась безумно сложной, и медленной. На каждый починенный таким образом случай начинало приходиться десять других, где замедление программы вследствие более медленной оценочной функции приводило к недостаточной глубине перебора и еще худшей игре.
Кроме того, программа с маниакальным упорством пытается отсрочить свои неприятности, получая взамен худшие. <Ага, я перебираю на 7 полуходов, и вижу, что теряю слона. А вот отдам-ка я вот эту пешку, и тогда слона противник возьмет на 4 полухода позже, получится 11, я и не увижу. Итого минус 1, а не минус 3>. Разумеется, при более глубоком переборе программа бы обнаружила, что в итоге у нее будет минус 4, но времени перебирать глубже нет. Это явление называется <эффектом горизонта>, ибо программа стремится выпихнуть неприятности за горизонт видимости (или горизонт событий).
Попытки использовать селективные методы провалились с еще большим треском. Не удается понять, как человек играет в шахматы, и попытки сделать программы с "forward pruning" - отсечениями ветвей дерева без их предварительного рассмотрения, исходя из чисто шахматных принципов, проваливаются. Всегда находятся позиции, где программа отсекает нужный ход (<выплескивает воду месте с ребенком>).
В конце концов стало понятно, что оценочную функцию можно звать только в спокойных позициях. Поэтому в конце основного перебора вставили еще один, упрощенный, где рассматриваются только взятия, превращения, и, возможно, шахи и ответы на шах. Так как таких ходов немного, <форсированный вариант> (так это называется) замедляет программу всего лишь на 20-50%, а сила игры резко увеличивается, т.к. программа не пытается оценить острые позиции.
Потом заметили, что серия ходов с разменом в конце будет рассмотрена на большую глубину, чем с разменом в середине, и сообразили, что некоторые варианты с разменом в середине тоже неплохо бы рассматривать поглубже. Возникла идея (не знаю, как по русски, пусть будет <углубление>) - при переборе после некоторых ходов не уменьшать оставшуюся глубину перебора. Типичные углубления - после размена, при превращении пешки, при уходе от шаха. Идея та же, что и в форсированном варианте - ситуация на доске может кардинально измениться, этот вариант надо изучить поглубже. Вот какова была ситуация в начале и середине 70-х.
Как уже было сказано, за 40 лет никакой замены альфа-бете не найдено. В этом смысле наиболее печальна история Ботвинника. В течении 20 лет он занимался созданием шахматной программы. Он свято верил, что будучи чемпионом мира по шахматам и одновременно хорошо понимая программирование, он сумеет создать программу, которая будет играть на уровне чемпиона мира. Итог печален - программа так никогда не заиграла (по этому поводу кто-то хорошо сказал <Ботвинник только думает, что он знает, как он думает>). Что еще хуже, Ботвинник напечатал статью с описанием алгоритма в журнале International Computer Chess Association. Статья содержала результаты анализа нескольких позиций, якобы выполненных программой. Независимый анализ показал, что эти результаты являются фальсификацией - они не могли быть получены с использованием алгоритма Ботвинника.
Тем не менее, все эти годы качество игры шахматных программ улучшалось. Частично прогресс обьясняется быстрым развитием аппаратуры - персональные компьютеры по ряду параметров достигли уровня суперкомпьютеров конца 70-х (хотя по ряду параметров все еще серьезно отстают). Частично же <виновато> развитие алгоритмов - прорыва не было, но было множество эволюционных улучшений. Каковы главные из них?
(1) Использование библиотеки дебютов. Дебютная теория в шахматах хорошо разработана, и только естественно, что программы стали ее использовать. Более того, используют они ее лучше, чем гроссмейстеры, т.к. запомнить несколько миллионов позиций для машины проще простого.
(2) Использование баз данных с целиком просчитанными эндшпилями. Сейчас реальный предел для персонального компьютера - 5-фигурные эндшпили (считая королей). Используя такие базы данных, программы играют простые эндшпили безупречно. Более того, современные программы могут во время перебора вариантов <дотянуться> до базы данных из позднего миттельшпиля, когда на доске находится еще 10-15 фигур. Скромно замечу, что к созданию наиболее широко распространенных баз эндшпилей приложил руку я.
(3) Думанье во время хода противника. Мы сделали ход и теперь задумался противник. Зачем времени пропадать? Выберем наиболее разумный с нашей точки зрения ход, который он может сделать, и начнем думать над ответом на него. Об этом говорит сайт https://intellect.icu . Если он сделает другой ход - ну и леший с ним, все равно не наше время было. Это - наиболее простой вариант использования времени противника, и он же наиболее эффективный, т.к. хорошие программы правильно предсказывают ~70% ходов противника.
(4) Различные эвристики, которые помогают отсортировать ходы в процессе перебора. Как уже отмечалось ранее, альфа-бета очень чувствительна к порядку, в котором анализируются ходы. При хорошем порядке она быстрее, причем быстрее принципиально. При этом алгоритм все равно остается экспоненциальным - перебор на N+1 полуходов работает в разы медленнее, чем на N полуходов, но по крайней мере возводимое в степень число ощутимо уменьшается. В типичной шахматной позиции возможно примерно 40 ходов, и для перебора на N полуходов минимаксу (он же альфа-бета с наихудшим упорядочением ходов) надо рассмотреть 40**N позиций. Альфа-бете с наилучшим упорядочением ходов надо рассмотреть примерно 6**Nпозиций - разница принципиальна. Эвристики применяются различные, например: первым делом попытаться съесть только что ходившую фигуру противника (она работает, т.к. большинство рассматриваемых ходов - полнейший идиотизм). Другая полезная эвристика (с меньшим приоритетом) - попытаться сделать ход, который был лучшим у соседа слева (она основана на том, что в похожих позициях наилучший ход часто один и тот же). Имеются еще несколько эвристик, но надеюсь, что идея в целом понятна.
(5) Итеративное углубление (iterative deepening). В реальной игре у программы имеется какое-то время на каждый ход, и им надо с умом распорядиться. Просто начинать перебор на фиксированную глубину, как делали ранние программы, неразумно - в сложной позиции с большим количеством разменов и/или шахов будет много вариантов, которые будут просчитываться очень глубока из-за <углублений>, и программа может не успеть выполнить перебор. А одной из особенностей альфа-беты является то, что результатом незаконченного перебора воспользоваться нельзя - нет никакой гарантии, что найденный к моменту прерывания наилучший ход является хоть сколько-нибудь разумным. С другой стороны, в какой-нибудь закрытой позиции с малым количеством возможных ходов (branching factor) перебор может закончиться неожиданно быстро. Идея итеративного углубления состоит в том, что программа сначала производит перебор на глубину 1. Осталось время - перебираем на глубину 2. Осталось время - на глубину 3. И так далее. Разумеется, при этом приходится часть работы делать заново, но тут понимает как раз экспоненциальный характер алгоритма. Следующий перебор занимает (грубо) в 6 раз больше времени, поэтому мы заново делаем максимум 1/6 работы. Зато у нас всегда есть ход от предыдущей итерации, которым мы можем воспользоваться, если нам придется прервать текущую. Возможны дальнейшие оптимизации - например, не начинать новую итерацию, если мы съели больше половины отведенного на думанье над этим ходом времени, ибо все равно почти наверняка не успеем.
(6) Хэш-таблицы (transposition tables). В шахматах мы имеем не дерево игры, а граф - очень часто после перестановки ходов мы получаем одну и ту же позицию. Возникла простая идея - занять всю память машины, которая иначе бы не использовалась, под запоминание уже рассмотренных позиций. Для каждой позиции надо хранить ее оценку (точнее, оценку поддерева под этой позицией), глубину перебора, наилучший ход, и некоторую служебную информацию. Теперь, начав разбирать позицию, надо взглянуть - а не встречали ли мы уже ее? Если не встречали, то поступаем как раньше. Если встречали, то смотрим, на какую глубину мы ее раньше разбирали. Если на такую же, как нам надо сейчас, или более глубокую, то можно воспользоваться старой оценкой и сэкономить время. Если же на меньшую, то мы все равно можем воспользоваться частью информации, а именно наилучшим ходом. Лучший ход для глубины N может оказаться лучшим и для глубины N+1. То есть, кроме своего изначального предназначения, хэаш-таблица оказывается полезна и для упорядочения ходов. Тут еще неожиданно помогает итеративное углубление - когда мы начинаем следующую итерацию, хэш-таблица оказывается заполнена информацией от предыдущей, и до какого-то момента (до глубины 1) все позиции просто есть в ней, с наилучшим ходом на глубину N-1. Программа, использующая итеративное углубление и хэш-таблицы, часто выполняет все итерации от 1 до N в несколько раз быстрее, чем если бы она сразу начала итерацию N, т.к. с вероятностью 75% она всегда первым выбирает наилучший ход, а с вероятностью ~90% наилучший ход оказывается в числе первых трех рассмотренных.
(7) Пустой ход (null move). В шахматах очередность хода очень важна, и тот игрок, который мог бы сделать два хода подряд, имел бы огромное преимущество. Возникла очень простая идея - пусть игрок A сделал свой ход и теперь очередь B. У него есть преимущество - например, лишний конь. Надо рассмотреть поддерево на глубину N. Игрок A говорит < я не буду делать ход, пусть B делает два хода подряд, зато поддерево после этого мы посмотрим до глубины N-2 а не N-1, как было бы после моего хода>. Мы выполняем этот перебор на меньшую глубину, и если у A все равно преимущество, мы решаем <так как на самом деле он будет делать ход, наверное на самом деле его преимущество будет еще больше>. То есть мы сэкономили, разобрав не настоящее поддерево до глубины N, а другое до глубины N-1 - напоминаю еще раз, что перебор экспоненциален, так что выигрыш очень значителен. Иногда оказывается, что игрок B, имея два хода подряд, может восстановить баланс - пустой ход не сработал, придется перебирать все честно до глубины N. Опять-таки, мы потеряли не очень много времени, т.к. перебирали до глубины N-1. Разумеется, пустой ход, являясь эвристикой, может и наврать - например, в цугцванге право хода лишь мешает. Но в реальной игре цугцванг встречается лишь в эндшпиле, а в эндшпиле пустой ход можно и не использовать. Пустой ход оказался очень серьезным улучшением, т.к. он позволяет сократить время перебора на глубину N с 6**N до (25-3)**N.
(8) Единственный ответ (singular extension). Стандартная альфа-бета прекращает анализ позиции, как только найден ход, который вызовет отсечение. Так как у нас не полное дерево игры, а мы используем оценочную функцию, может оказаться, что мы проврались, и никакого отсечения нет. Соответственно, мы думали, что в этой позиции у нас лучше, а на самом деле мы теряем ферзя. Идея единственного ответа состоит в том, что найдя один хороший ответ, мы не отсекаем сразу все поддерево, а продолжаем перебор, пока не найдем второй хороший ход. Если же мы его не нашли, то позиция анализируется заново, на сей раз на глубину N+1. Очень помогает в тактических позициях - программа начинает видеть комбинации на несколько ходов раньше, но резко замедляет перебор и поэтому используется только программами, работающими на суперкомпьютерах.
Сразу оговорюсь, что про наиболее известную программу (а точнее, машину+программу) - Deep Blue - я напишу в другой раз. Здесь же речь пойдет о типичных современных программах, работающих в основном на обычных компьютерах.
Итак, как они устроены внутри, мы уже разобрались. Тем не менее, продукты, построенные на одинаковых принципах, могут очень сильно друг от друга отличаться, и шахматные программы здесь не исключение. Большую часть современных программ можно разбить на 3 категории:
Категория Fast searchers - идея состоит в том, что, упростив до предела оценочную функцию, и тщательно с оптимизировав всю программу в целом (что обычно достигается путем написания программы на ассемблере), можно довести количество позиций, рассматриваемых программой (nps - nodes per second) до астрономического числа, например, до 150-200k nps на P/200. То есть на каждую позицию программа тратит порядка одной-двух тысяч машинных команд. В это число входит делание хода из предыдущей позиции в эту, оценка позиции, генерация ходов из данной позиции, управляющая логика и т.д. На собственно оценочную функцию остаются вообще крохи - порядка сотни команд. Соответственно, она проста, как топор - перед началом перебора программа строит таблицы, где на каждой клетке нарисовано, какая фигура стоит хорошо, а какая - плохо. Например, вражеский король стоит на E8 - на клетках непосредственно рядом с ним нашему ферзю припишем +0.5 пешки, чуть подальше +0.2, еще дальше +0.1. Слабая пешка - на диагонали, откуда мы можем на нее давить, слону припишем +0.15, а ладье (разумеется, на вертикали или диагонали) - +0.2. И так далее. Для получения оценки достаточно для каждой фигуры слазить в ее таблицу, добавить разницу в материале - и оценка готова.
Проще всего, кстати, не выписывать оценочную функцию явно, а посчитать ее один раз перед началом перебора, а потом обновлять - сделали ход, вычли из нее оценку фигуры на старом месте и добавили на новом. Если кого-то сожрали, надо вычесть материальную и позиционную оценку для него.
Программы получаются безумно быстрыми и превосходно ведут себя в сложных тактических позициях, а также отлично решают комбинационные задачи. Разумеется, за все надо платить. Платой за тактическое умение становится слабая позиционная игра, особенно при нынешних скоростях машин. Длина рассматриваемого варианта может достичь 20 полуходов, и принятые в начале перебора решения оказываются далеки от истины. Например, подтянул я свои фигуры к E8, а вражеский король давно уже убежал и стоит на A3. Или появилась новая слабость в пешечной структуре, про которую программа ничего не знает. И так далее.
Соответственно, вторая категория - это так называемые knowledge-based программы. Тут все силы брошены на написание сложной оценочной функции. Учитывается и взаимодействие фигур друг с другом, и прикрытость короля, и контроль позиций, и чуть ли не фаза луны. В терминах nps программа работает в 10-100 раз медленнее, чем fast searches, но играет в хорошие позиционные шахматы. Точнее, хорошими эти шахматы являются только тогда, когда на доске нет глубокой тактики, или же контроль времени таков, что у программы есть достаточно времени, чтобы эту тактику просчитать. А еще одна стандартная беда - что-то не учтено в оценочной функции. Простейший (хотя и искусственный) пример - предположим, что программа не знает, что отставшая пешка - это плохо. Быстрая программа будет избегать позиций с отставшей пешкой, так как глубоко в дереве увидит *тактические* возможности противника - он подтянет свои фигуры и слопает несчастную пешку, т.е. сумеет перевести позиционное преимущество (о котором программа не знает) в материальное. Медленная же программа без такого знания обречена - что это позиционно плохо она не знает, а глубины перебора для нахождения выигрыша пешки противником не хватит.
Соответственно, большая часть современных программ есть некий гибрид между двумя крайностями. Они работают в 2-5 раза медленнее быстрых программ и имеют уже достаточно сложную оценочную функцию. Тем не менее они регулярно попадают впросак из-за слабой позиционной игры - впрочем, это же делают все программы, даже с самой лучшей оценочной функцией, ибо всегда оказывается, что какой-то фактор создатели программы просмотрели. Утверждается, что имеется очень много факторов, которые в явном виде нигде не записаны, но которые любой мастер (не говоря уж о гроссмейстере) считает самоочевидными.
Вокруг того, как должна быть устроена программа, идут непрекращающиеся споры. Все шахматисты, ровно как и большинство потребителей, очень любят knowledge-based программы. Стало даже модно писать <программа рассматривает всего 10,000 позиций в секунду>. Почему-то из этого делается вывод, что программа обладает немыслимо сложной оценочной функцией, как будто не бывает просто плохо написанных программ.
Программисты любят быстрые программы - хотя бы потому, что можно написать быструю программу, не будучи сильным шахматистом. Эта программа будет играть очень неплохо, во всяком случае, она сумеет обыграть своего автора, равно как и 99% игроков на Земле.
В какую силу играют сейчас лучшие программы на коммерческих машинах (например, на PIII/500)? Точного ответа вам никто не даст, ибо имеется очень мало статистики (гроссмейстеры не любят играть с программами в <серьезные> шахматы, в основном из-за того, что им за это не платят). Так что ниже есть моя личная точка зрения (хотя я могу подтвердить ее некоторой статистикой).
Все зависит от контроля времени:
Разумеется, многое зависит и от любимого человеком стиля игры. Так, Каспарову особенно тяжело играть с компьютерами - он любит острую тактическую игру, а здесь компьютеры особенно сильны. Переиграть компьютер в тактике очень тяжело. А вот стиль игры Карпова, наоборот, тяжел для компьютера - он не знает, как надо играть в закрытой позиции, а Карпов тем временем потихоньку усиливает позицию. Есть и так называемый <антикомпьютерный> стиль - идея состоит в том, что современные программы недооценивают опасность атаки на короля, пока эта атака находится за их <горизонтом видимости>. Хороший антикомпьютерный игрок потихоньку готовит атаку, подтаскивает фигуры, и дает тем временем возможность программе резвиться (заниматься пешкоедством) на другом фланге. Когда программа видит опасность - уже поздно, подтянуть застрявшего там ферзя (или кого-нибудь еще) она уже не успевает. Очень часто хорошие антикомпьютерные игроки с людьми играют плохо, так как человек видит опасность раньше.
Наверное, здесь нет человека, который не слышал бы о Deep Blue. Причем именно слышал бы, на уровне «это такая программа, которая играет лучше Каспарова». Без всяких подробностей. Отсутствие подробностей связано с маркетинговой политикой фирмы IBM. Отделу рекламы там нужно, чтобы средний американец знал, что «IBM сделала непобедимый шахматный компьютер». Он это и знает. Поэтому Deep Blue уже (похоже) никогда не будет играть в шахматы – выиграть от этого IBM ничего не выиграет, а проиграть (в случае выигрыша человека) есть чего.
Так что судить о Deep Blue (точнее, о Deep Blue II – последней машине из семейства) можно только по 6 сыгранным во втором матче с Каспаровым партиям, по редким публикациям в технических журналах, да по лекциям, которые иногда устраивают разработчики. Одна из таких лекций была года полтора назад в MS, я на ней присутствовал; ее читал Murray Campbell, который в Deep Blue отвечал за оценочную функцию. Очень интересна статья Feng Hsiung Hsu (автора специализированных шахматных процессоров) в IEEE Micro, N3 за этот год. По слухам, Joel Benjamin (гроссмейстер, работавший с командой Deep Blue; чемпион США) готовит книгу о Deep Blue, но я ее не видел. Интересная информация иногда проскакивает в rec.games.chess.computer, но там соотношение сигнал/шум очень мало.
Deep Blue – это не первая попытка создать специализированное «железо» для игры в шахматы. Можно вспомнить, например, что в конце 60-х – начале 70-х годов одна из отечественных машин М-20 была немного модернизирована, в нее были вставлены специальные шахматные команды (Россия – родина слонов; каких слонов я вчера видел в зоопарке... но мы отвлеклись от темы). Реальные же специализированные шахматные процессоры появились на Западе, в конце 70-х – начале 80-х годов. Самые известные разработки были сделаны Berliner - HiTech и Ken Thompson (одним из авторов Unix) – Belle. В этих машинах реализован аппаратный генератор ходов, оценочная функция и альфа-бета перебор. Разработки были академические, и невзирая на то, что специализированное железо обычно на порядок быстрее, чем сопоставимое general purpose, о сопоставимости речи не было. Программа Cray Blitz на сверхсовременной тогда машине Cray (стоимостью $60млн) играла все равно лучше.
Deep Blue начинала как студенческая разработка – интересно было группе способных студентов попробовать свои силы, да и тема для диплома отличная. Прогресс технологии позволил сделать первую же версию процессоров (названную ChipTest) очень быстрыми. Последовала следующая, усовершенствованная версия, названная Deep Thought. В этот момент группу заметил маркетинговый департамент фирмы IBM и обратился к ней с предложением, от которого невозможно было отказаться. Результатом стали Deep Blue и Deep Blue II. Таким образом, Deep Blue II – это результат более чем 10 лет работы очень способной группы, в которой были как программисты/железячники, так и сильные гроссмейстеры (кроме уже упомянутого Бенджамина привлекались и другие гроссмейстеры, с хорошей оплатой). Финансировалась вся работа фирмой IBM, таким образом у группы были ресурсы, которые и не снились академическим организациям («Бог на стороне больших батальонов»).
Deep Blue II сделана на основе мощного сервера RS/6000 фирмы IBM. В сервере имеется 31 обычных процессора; один объявлен главным, ему подчиняются 30 остальных. К каждому «рабочему» процессору подключено 16 специализированных шахматных процессора, таким образом всего имеется 480 шахматных процессоров. Они и являются «сердцем» системы, таким образом, утверждение IBM “Мы продаем сервер RS/6000, который обыграл в шахматы Каспарова”, как бы это сказать… не совсем верно.
Первые несколько полуходов (4) перебираются на «главном» процессоре RS/6000. После 4-х полуходов он передает работу остальным 30-ти процессорам, и они рассматривают следующие 4 полухода. Программа здесь написана на обычном C, и не очень отличается от традиционных параллельных шахматных программ. Наиболее существенное отличие – при написании программы было известно, что система обладает огромной скоростью (т.к. в ней основную работу выполняют специализированные шахматные процессоры), соответственно, можно особо не экономить. Напомню – при написании шахматной программы всегда велико желание какие-то варианты рассмотреть поглубже («углубиться»), но всегда приходится помнить, что если мы углубимся здесь, то останется меньше времени на рас смотр других вариантов. Соответственно, обычно приходится искать компромисс между более глубоким рассмотрением «тактических» вариантов (в которых только и работают классические углубления) и «тихих» вариантов (которые с точки зрения человека тоже могут быть тактическими, но только ходы не попадают под слишком узкое машинное определение тактических). Здесь же можно рассматривать более длинные варианты, не заботясь что другим времени не достанется – ресурсов хватит на всех. Так что формальные 4 полухода здесь легко могут превратиться в 30 полуходов.
После этого работу перехватывают специализированные процессоры, и они делают ощутимо больше 99% всей работы системы – а именно, они перебирают еще на 4 полухода. Из-за того, что в них нет программы как таковой, а все, что надо сделать, зашито аппаратно (не микропрограммно!), при их проектировании приходилось серьезно думать, что надо в них делать, а что нет. В частности, в них не предусмотрено почти никакое углубление. Зато в них предусмотрена достаточно сложная оценочная функция – ведь то, что тяжело запрограммировать, часто очень легко сделать на аппаратном уровне. Например, детектор шахов работает один такт, т.к. одновременно проверяются все возможные варианты. Очень прост контроль X-rays(не знаю, как будет по-русски – это когда одна дальнобойная фигура стоит позади другой), вилок, перегрузки фигур и т.д.
Вообще, оценочная функция в шахматном процессоре Deep Blue очень сложна – утверждается, что она соответствует примерно 40,000 командам обычного процессора. В частности, там имеется около 8,000 коэффициентов. Эти коэффициенты не прошиты намертво, а загружаются в процессор после включения. Таким образом можно было вести настройку процессора после его создания, и не бегать на фабрику для каждого изменения. Как решалась задача оптимизации в пространстве размерности 8000 – это отдельная история (и тоже опубликованная).
Шахматные процессоры были выполнены по устаревшей 0,6 микронной технологии и работают со скоростью 2-2.5 млн позиций в секунду. Таким образом, весь монстр обрабатывает примерно миллиард шахматных позиций в секунду. Прошу обратить внимание, что general-purpose системе для этого потребовалось бы быстродействие порядка 40 триллионов операций в секунду.
(Процессоры были серьезно переработаны после первого матча с Каспаровым, когда стало ясно, что в предыдущей версии отсутствуют многие факторы, которые необходимы для игр на таком уровне; большая часть группы не верила, что это удастся сделать меньше чем за год, но Hsu совершил чудеса и управился в срок)
Разумеется, к.п.д. параллельного перебора всегда ниже 100% (раньше уже писалось, что альфа-бета распараллеливается очень тяжело). В данном случае удалось добиться к.п.д порядка 25%, что само по себе является очень большим достижением. То есть система работает как однопроцессорная, не векторная general-purpose машина со скоростью 10 триллионов операций в секунду. Таковых маши не бывает и в ближайшие годы не появится (а может, не появится никогда, т.к. технология упрется в размеры атома и квантовые эффекты).
У шахмат довольно простые правила. Две противоборствующие стороны, шесть разновидностей фигур и одна цель – дать мат сопернику.
Но при этом вариативность шахмат просто огромна. Существует 400 уникальных комбинаций первого хода – 20 вариантов первого полухода белых и 20 вариантов ответа черных. С каждым последующим ходом количество уникальных позиций увеличивается на степень.
Общее количество уникальных партий в шахматы составляет примерно 10120, что на 1040 превышает количество атомов во Вселенной.
Шахматам не грозит быть посчитанными полностью. Поэтому в бой вступают алгоритмы оценки позиции и дерево возможных ходов.
В шахматной теории у каждой фигуры есть своя ценность, которая измеряется в пешках:
Конь – 3 пешки;
Слон – 3 пешки;
Ладья – 5 пешек;
Ферзь – 9 пешек;
Пешка – 1 пешка.
Король – бесценен, потому что его потеря означает проигрыш партии.
Анализ современных машин подтверждает истинность такой оценки. Так, в зависимости от позиции на доске компьютер оценивает ферзя в 9–12 пешек, ладью – в 5–6, коня и слона – в 3–5. Короля же машина оценивает в 300 пешек. Это задает максимальную границу оценки.
Чтобы было более понятно, преимущество в 0,5 пешки – это уже неплохо для шахматиста. В целую пешку – серьезный перевес. В 3 пешки – подавляющее преимущество, которое можно практически без проблем довести до победы.
Но счетные возможности машины ограниченны. Иногда она показывает оценку в +51 или что-то вроде. Это означает, что алгоритм видит колоссальное преимущество белых в позиции и материале, но не может найти конкретный путь к мату.
Минимакс, или прямой перебор вариантов, в таком случае не работает. Даже КМС без проблем найдет на доске мат в 3 хода в миттельшпиле, когда на доске еще много фигур. А программе для этого нужно будет перебрать свыше 750 млн. полуходов.
Даже если программа перебирает 1 млн вариантов в секунду, чтобы найти мат в 3 хода, ей понадобится до 750 секунд, или 12,5 минут.
И это глубина в 3 хода. В стратегических позициях, где развитие игры идет с учетом на пять или десять ходов вперед, такие программы и вовсе будут бесполезными.
Поэтому для анализа позиции используется алгоритм под названием «альфа-бета-отсечение».
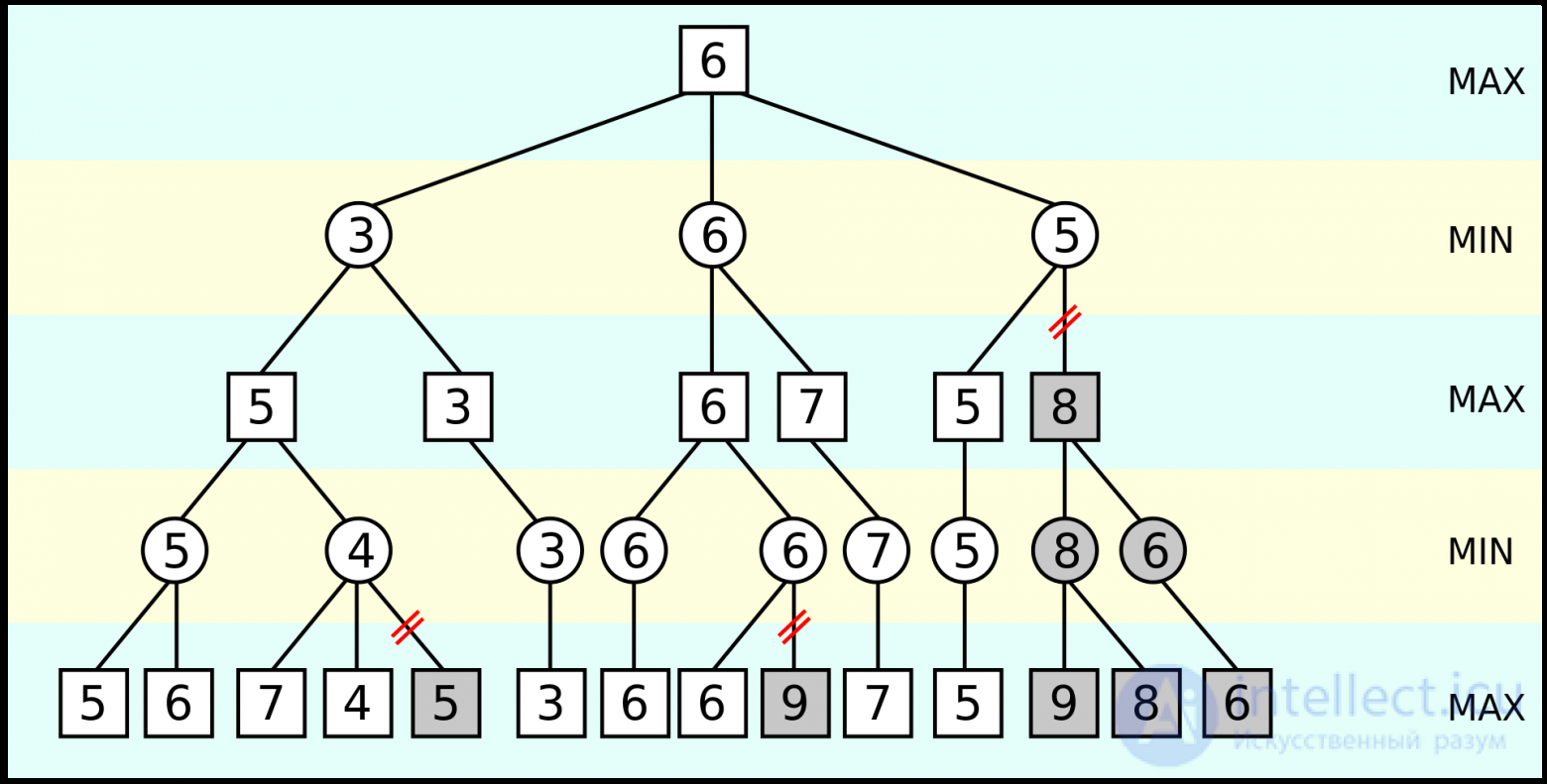
Система анализирует начальные варианты ходов и сразу отсекает те из них, которые ведут к мгновенному ухудшению оценки.
Программа отметает те варианты, в которых она сразу проигрывает материал или которые включают комбинации со стороны соперника, в ходе которых она выигрывает материал или партию.
Это позволяет сократить количество рабочих линий на порядки, сосредотачивая вычислительные ресурсы только на тех ветвях дерева, которые в перспективе ведут к улучшению позиции.
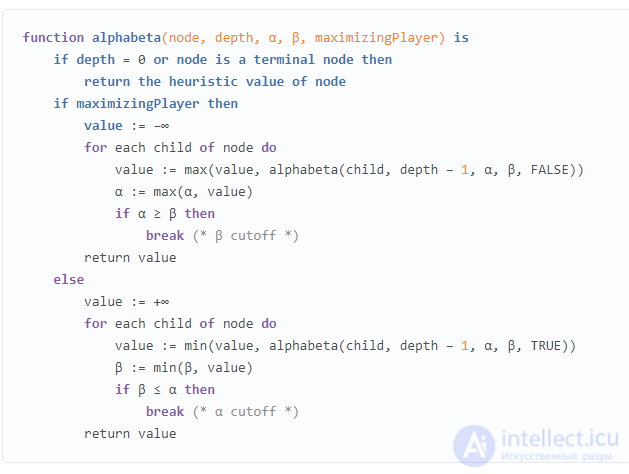
Псевдокод для минимакса с ограниченной глубиной с отсечением альфа-бета выглядит следующим образом:
Рассмотрим на примере. Движок Stockfish считается сегодня одной из самых сильных компьютерных шахматных программ. Обратите внимание на первые пять линий.
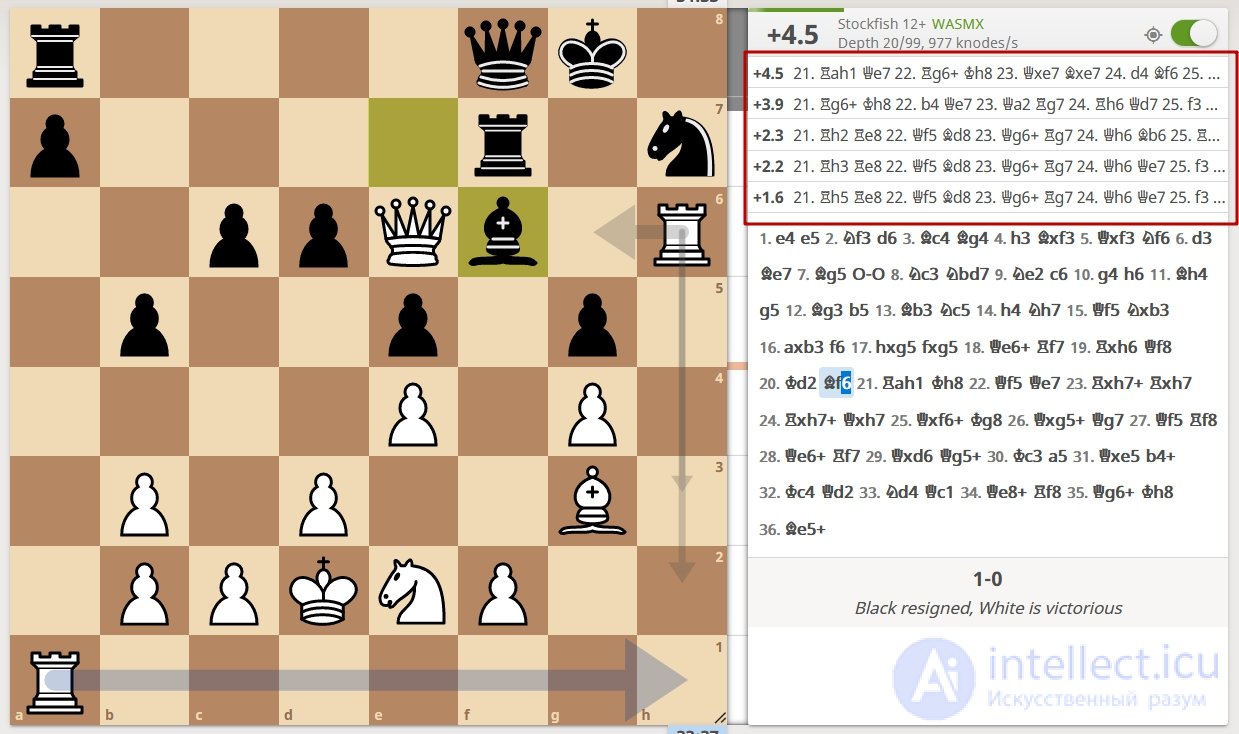
Из всего множества вариантов развития событий программа выбирает ряд линий, которые в перспективе ведут к улучшению позиции. Их она анализирует более глубоко – на 15–20 ходов вперед, чтобы отсечь возможные проигрышные варианты. В результате она выбирает лучшую из возможных линий и делает ход.
После ответа соперника ситуация снова анализируется по тому же алгоритму. Сначала отсекаются заведомо проигрышные линии (таких порядка 95 %), а затем путем более глубокого анализа перспективных вариантов выбирается лучший из них.
В 2017 году компания Deep Mind объявила о создании нейросети Alpha Zero. Тестировать ее решили на трех самых популярных стратегических настольных играх: шахматы, го и сеги.
Обучение и подготовка нейросети отличаются от классических компьютерных движков.
Stockfish и другие движки используют для своей работы существующие дебютные базы и анализ позиций огромного количества сыгранных партий.
Alpha Zero не использует ничего, кроме правил. Ей просто дали стартовую позицию, объяснили, как ходят фигуры, и цель игры – поставить мат сопернику. И все.
За 24 часа игры с самой собой нейросеть смогла достичь сверхчеловеческого уровня игры и по сути изобрести заново всю шахматную теорию, которую человечество по крупицам разрабатывало веками.
В декабре 2018 года Alpha Zero во второй раз сразилась с самой последней версией движка Stockfish.
Исследователи провели 1000 партий с контролем 3 часа на партию плюс 15 секунд на ход. Alpha Zero одержала уверенную победу, выиграв в 155 партиях, сыграв вничью 839 партий и проиграв только 6.
Более того, Alpha Zero одерживала победу даже в партиях с форой по времени на обдумывание. Имея в 10 раз меньше времени, чем у противника, нейросеть все равно победила в суммарном итоге. Только 30-кратная фора во времени смогла уравнять шансы и дать Stockfish примерно равную игру – 3 часа у движка и всего лишь 6 минут у нейросети.
Alpha Zero анализирует лишь 60 000 позиций в секунду, а тестируемая версия Stockfish – 60 млн. позиций. Для достижения аналогичных результатов анализа нейросети нужно в 1000 раз меньше ресурсов, чем движку.
Секрет успеха – в качественно другом уровне анализа. Нейросеть использует метод Монте-Карло, который высчитывает математическое ожидание комплекса ходов.
Если альфа-бета отсечение способно убрать большинство заведомо проигрышных вариантов, то проверять перспективные все равно нужно механическим перебором, нейросеть сосредоточена на вариантах, которые ведут к улучшению позиции фигур, материальному перевесу, стеснению фигур соперника или созданию комплексных угроз, включающих матовые атаки.
И, что гораздо более важно, при оценке ситуации Alpha Zero учитывает стратегическую позицию.
Давайте рассмотрим на примере одной из партий.

После 20-го хода на доске творится невообразимая стратегическая борьба. Но если нейросеть шаг за шагом минимально укрепляет свою позицию, избавляясь даже от призрачных слабостей, то движок с 24-го по 29-й ход просто топчется на месте ладьей.
Интересно, что Stockfish в упор не видит стратегических решений Alpha Zero, оценивая позицию как абсолютно ничейную. Но в результате минимальных укреплений позиции к 39-му ходу оказывается, что все фигуры белых активны, а черный конь и слон занимают пассивную оборонительную позицию. А после размена ферзей и ладей даже Stockfish оценивает преимущество нейросети в +2,2. Еще несколько ходов – и король черных зажат в углу доски, а конь в одиночку не способен справиться с проходной пешкой. Поэтому программа сдалась.
Позиционная игра – это то, что отличает нейросеть от классического шахматного движка. Ведь она подразумевает длительные игровые планы, которые часто превышают вычислительные возможности машин.
Тем не менее нейросеть умеет играть позиционно не хуже человека и при этом идеально играет тактические позиции, где преимущество достигается в течение 5 или меньше ходов.
Более того, нейросеть уже помогла найти теоретикам шахмат целый ряд неочевидных, но при этом очень сильных разветвлений дебютов, которые никогда не рассматривали ранее.
Многие теоретики считают, что благодаря шахматным компьютерам повысился и средний рейтинг топовых шахматистов. Ведь современные тренировки включают глубокую проработку компьютерных вариантов и разбора партий движками. Средний рейтинг ведущих топ-100 шахматистов в 2000 году составлял 2644 пункта Эло, а в январе 2021 года – 2715. За 20 лет среднее значение увеличилось на 71 пункт.
Сегодня человек уже не способен соревноваться с компьютером в шахматах. Нейросеть вобрала в себя все преимущества человеческого шахматного мышления, но при этом лишена его недостатков.
Она умеет мыслить позиционно и при этом не допускает зевков и ошибок. И самое интересное в этом – шахматы для Alpha Zero являются только тестовым полигоном, где система оттачивает навыки работы. Реальные же ее цели Google не раскрывает. Поэтому здесь может быть все что угодно: от анализа изменений климатической ситуации до создания системы идеально персонифицированной рекламы. А как вы считаете, для чего создают настолько мощную нейросеть?
Если я не полностью рассказал про алгоритмы шахматных программ? Напиши в комментариях Надеюсь, что теперь ты понял что такое алгоритмы шахматных программ и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Разработка компьютерных игр, гейм-дизайн

Комментарии