Лекция
Сразу хочу сказать, что здесь никакой воды про структуры данных, и только нужная информация. Для того чтобы лучше понимать что такое структуры данных , настоятельно рекомендую прочитать все из категории Структуры данных.
Структура данных (англ. data structure) — программная единица, позволяющая хранить и обрабатывать однотипные и/или логически связанные данные.
Элементарные структуры данных - это основные и простейшие способы организации и хранения данных в программировании.
Под элементарными структурами данных будем понимать структуры данных, которые либо предоставляются непосредственно в компьютере, либо моделируются средствами данных с использованием типов данных, доступных на уровне компьютера. Таким образом, элементарной структурой данных можно назвать любую базовую структуру данных. Ниже будут рассмотрены такие, как массив и связный список. Необходимо отметить, что их можно считать атомарными структурами данных, так как не предполагается их моделирование путем использования других элементарных структур данных. Хотя такая возможность и существует с точки зрения данных, построенная реализация не даст ощутимый выигрыш перед системной структурой данных, поскольку она заведомо ведет к снижению эффективности некоторых из базовых операций, таких, как вставка и удаление элемента.
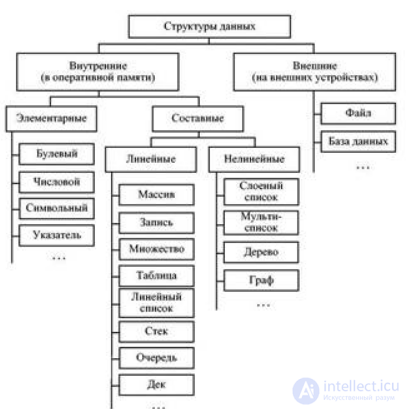
рис. 1 классификация структур данных
Булевый тип данных:
Указательный тип данных:
Числовой тип данных:
Символьный тип данных:
Массив – линейная, однородная, элементарная структура данных, представляющая собой непрерывную упорядоченную последовательность ячеек памяти и предназначенная для хранения данных одного и того же типа. Доступ к элементам массива осуществляется по индексу либо по набору индексов, где под индексом будем понимать некоторое целочисленное значение. В общем виде массив представляет собой многомерный параллелепипед, в котором величины измерений могут быть различны. Массив c измерениями будем называть m-мерным и обозначать через :
A[n1,n2, ... ,nm ]
где ni – число элементов, которое может быть записано на уровне i 1<=i<=m.
Таким образом, массив A c m измерениями позволяет хранить внутри себя 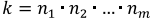 элементов c затратами памяти k*s = O(k) ,
элементов c затратами памяти k*s = O(k) ,
где s – количество ячеек памяти, требуемое для хранения одного элемента. Об этом говорит сайт https://intellect.icu . Как было отмечено ранее, любой массив – это непрерывный участок памяти, поэтому многомерный массив технически представляет собой одномерный массив, доступ к элементам которого осуществляется по следующей формуле:
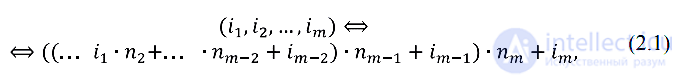
В дальнейшем изложении будем предполагать, что индексация элементов массива начинается с единицы, если не оговорено иное. Процедура вычисления соответствующего индекса согласно приведенному выражению представлена ниже (процедура
Процедура 2.1.1. Get Index
Get Index Impl(i1, i2, ..., im) index = 0 for j = 1 to m – 1 do index = (index + ij) * nj+1 index = index + im return index
Рассмотрим основные операции, которые позволяют манипулировать данными, хранящимися в массиве, при этом не ограничивая общности, будем считать, что задан одномерный массив A[n] , состоящий из n элементов:
1) чтение/запись элемента требуют O(1) времени, так как массив является структурой данных с произвольным доступом;
2) трудоемкость поиска элементов в массиве зависит от того, упорядочен он или нет: в случае упорядоченного массива поиск необходимых данных можно осуществить за O(log n) операций, иначе потребуется O(n) операций в худшем случае;
3) вставка/удаление элементов в массив требуют O(n) операций в худшем случае, так как изменение структуры массива требует перемещения элементов.
Если же вставка и удаление элементов осуществляются только на конце массива, то трудоемкость операций составит O(1) . Алгоритм вставки элемента в массив приведен ниже (процедура 2).
Процедура 2. Array:Insert
Insert Impl(A, index, element) if index > 0 then for i = n downto index do A[i + 1] = A[i] A[index] = element
В заключение еще раз подчеркнем, что многомерный массив можно неявно рассматривать как массив массивов одинакового размера. В то же самое время существует понятие рваного массива * , использование которого оправдано в том случае, если его элементами являются массивы произвольной длины и следует явно обозначить, что он состоит из массивов. В этом случае рваный массив будем обозначать как A ... .
Пример рваного массива приведен ниже (рис. 2.1):
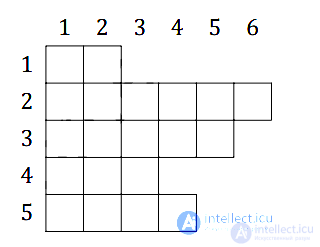
Рис. 2.1. Пример рваного массива
Следует отметить, что большинство современных императивных языков программирования имеют возможности для работы с массивами. Некоторые из языков предоставляют возможности для создания рваных массивов, как одного из типов данных.
Как было отмечено выше, операции вставки и удаления элемента в массив осуществляются в худшем случае за O(n) операций. Поэтому возникает необходимость в разработке структур данных, которые позволят избавиться от данного недостатка и, как следствие, предоставят эффективные методы по включению/исключению элементов. К достоинствам же массива можно отнести экономное расходование памяти, требуемое для хранения данных, а также
быстрое время доступа к элементам массива. Следовательно, применение массивов оправдано в том случае, если обращение к данным происходит по цело- численному индексу и в ряде случаев, не предполагающих модификацию набора данных путем увеличения/уменьшения числа его элементов.
Связным списком будем называть линейную, однородную, элементарную структуру данных, предназначенную для хранения данных одного и того же типа, в которой порядок объектов определяется указателями. В отличие от массива, связный список, как следует из данного определения, хранит элементы необязательно в последовательных ячейках памяти. Данным свойством и обосновано название «Связный список» рассматриваемой структуры данных, поскольку при помощи указателей ячейки памяти связываются в единое целое. Рассматривая связный список, будем предполагать, что его элемент описывается составным типом данных, который хранит в себе пользовательские данные некоторого типа и указатель на следующий элемент списка. У связного списка принято различать концевые элементы: головой называют начальный элемент списка, хвостом – конечный. Таким образом, рекурсивное описание связного списка выглядит следующим образом (процедура 3):
Связный список (Linked List):
Процедура .3. Linked List
Type linkedListElement
{
item: T
linkedList
}
linkedList
{
head: linkedListElement
tail: linkedListElement
}
emptyLinkedList = linkedList
{
head = null
tail = null
}
Помимо данных пользователя и указателей на соседние элементы, элемент списка может хранить и некоторую служебную информацию, продиктованную спецификой задачи (например, время создания элемента списка, адрес элемента в памяти, информацию о владельце и т.д.). На практике же чаще всего используются те либо иные вариации связных списков, которые в большинстве своем обусловлены особенностями итерирования по списку. Основными из них являются односвязные, двусвязные и кольцевые списки, которые будут рассмотрены ниже вместе с базовым набором операций. Если это не будет приводить к противоречиям, то пустой список далее будем обозначать через символ .
Односвязным списком будем называть связный список, в котором каждый из элементов списка содержит указатель непосредственно на следующий элемент того же списка. Односвязный список является простейшей разновидностью связного списка, поскольку каждый его элемент предполагает хранение минимальной информации для связи элементов списка в единую структуру. Можно видеть, что данное определение является идентичным определению связного списка, поэтому и описание их будет похожим.
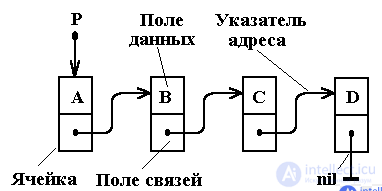
Двусвязным списком будем называть связный список, в котором каждый из элементов содержит указатель как на следующий элемент списка, так и на предыдущий.
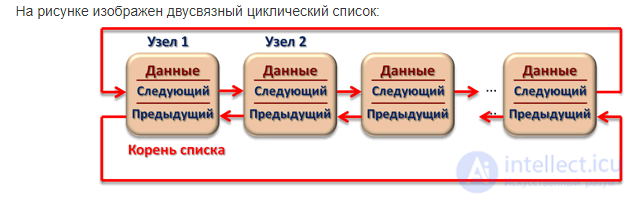
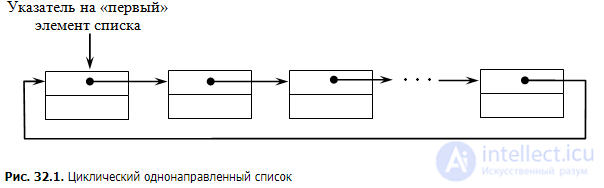
Кольцевые списки
Кольцевым списком будем называть связный список, в котором последний элемент ссылается на первый. Обычно кольцевые списки реализуются на основе либо односвязных списков, либо двусвязных. В силу того, что список замкнут в кольцо, требуется всего лишь один указатель, который будет определять точку входа в список. Реализации базовых операций для кольцевого списка не приводятся по причине большого сходства с соответствующими операциями для односвязного списка. К основным достоинствам кольцевых списков следует отнести возможность просмотра всех элементов списка, начиная с произвольного, а также быстрый доступ к первому и последнему элементам в случае, если список реализован на базе двусвязного списка.
Эти элементарные структуры данных представляют основу для более сложных структур данных и алгоритмов. Выбор структуры данных зависит от конкретных требований и операций, которые необходимо выполнять с данными в программе.
А как ты думаешь, при улучшении структуры данных, будет лучше нам? Надеюсь, что теперь ты понял что такое структуры данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных

Комментарии