Лекция
Привет, Вы узнаете о том , что такое стек, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое стек, стеки, операции pop, операция push , настоятельно рекомендую прочитать все из категории Структуры данных.
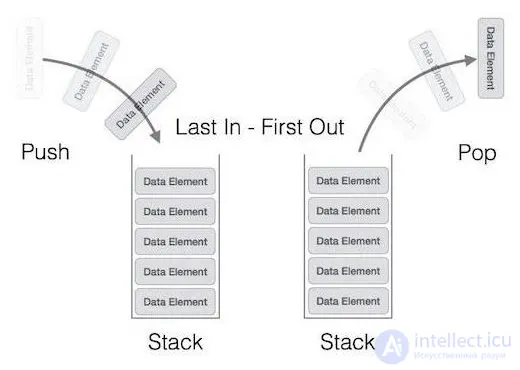
стек (англ. stack — стопка; читается стэк) — это абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришел — первым вышел»).
Чаще всего принцип работы стека сравнивают со стопкой тарелок: чтобы взять вторую сверху, нужно снять верхнюю.
В цифровом вычислительном комплексе стек называется магазином — по аналогии с магазином в огнестрельном оружии (стрельба начнется с патрона, заряженного последним).
В 1946 Алан Тьюринг ввел понятие стека . А в 1957 году немцы Клаус Самельсон и Фридрих Л. Бауэр запатентовали идею Тьюринга .
В некоторых языках (например, Lisp, Python ) стеком можно назвать любой список, так как для них доступны операции pop и push. В языке C++ стандартная библиотека имеет класс с реализованной структурой и методами И т. д.
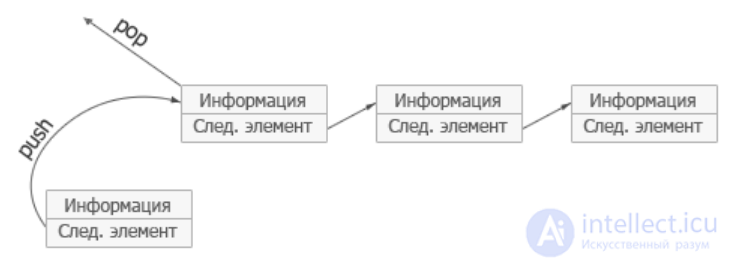
Иллюстрация организации стека
Стек (stack) является как бы противоположностью очереди, поскольку он работает по принципу "последним пришел — первым вышел" (last-in, first-out, LIFO) . Чтобы наглядно представить себе стек, вспомните стопку тарелок. Первая тарелка, стоящая на столе, будет использована последней, а последняя тарелка, положенная наверх — первой. стеки часто применяются в системном программном обеспечении, включая компиляторы и интерпретаторы.
Как известно, программы состоят из двух частей — алгоритмов и структур данных. В хорошей программе эти составляющие эффективно дополняют друг друга. Выбор и реализация структуры данных насколько же важны, как и процедуры для обработки данных. Способ организации и доступа к информации обычно определяется природой программируемой задачи. Таким образом, для программиста важно иметь в своем распоряжении приемы, подходящие для различных ситуаций.
Степень привязки типа данных к своему машинному представлению находится в обратной зависимости от его абстракции. Другими словами, чем более абстрактными становятся типы данных, тем больше концептуальное представление о способе хранения этих данных отличается от реального, фактического способа их хранения в памяти компьютера Простые типы, например, char или int, тесно связаны со своим машинным представлением. Например, машинное представление целочисленного значения хорошо аппроксимирует соответствующую концепцию программирования. По мере своего усложнения типы данных становятся концептуально менее похожими на свои машинные эквиваленты. Так, действительные числа с плавающей точкой более абстрактны, чем целые числа. Фактическое представление типа float в машине весьма приблизительно соответствует представлению среднего программиста о действительном числе. Еще более абстрактной является структура, принадлежащая к составным типам данных.
На следующем уровне абстракции сугубо физические аспекты данных отходят на второй план вследствие введения механизма доступа(data engine) к данным, то есть механизма сохранения и получения информации. По существу, физические данные связываются с механизмом доступа, который управляет работой с данными из программы. Именно механизмам доступа к данным и посвящена эта глава.
Существует четыре механизма доступа:
Каждый из этих методов дает возможность решать задачи определенного класса. Эти методы по существу являются механизмами, выполняющими определенные операции сохранения и получения передаваемой им информации на основе получаемых ими запросов. Они все сохраняют и получают элемент, здесь под элементом подразумевается информационная единица. В этой главе показано, как создавать такие механизмы доступа на языке С. При этом проиллюстрированы некоторые распространенные приемы программирования в С, включая динамическое выделение памяти и использование указателей.

Другие названия: магазин, стековая память, магазинная память, память магазинного типа, запоминающее устройство магазинного типа, стековое запоминающее устройство.
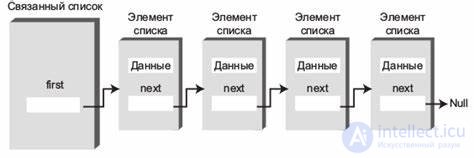
Другие названия: цепной список, список с использованием указателей, список со ссылками, список на указателях.
Другие названия: дерево двоичного поиска.
При работе со стеками операции занесения и извлечения элемента являются основными. Об этом говорит сайт https://intellect.icu . Данные операции традиционно называются "затолкать в стек" (push) и "вытолкнуть из стека" (pop) . Поэтому для реализации стека необходимо написать две функции: push(), которая "заталкивает" значение в стек, и pop(), которая "выталкивает" значение из стека. Также необходимо выделить область памяти, которая будет использоваться в качестве стека. Для этой цели можно отвести массив или динамически выделить фрагмент памяти с помощью функций языка С, предусмотренных для динамического распределения памяти. Как и в случае очереди, функция извлечения получает из списка элемент и удаляет его, если он не хранится где-либо еше. Ниже приведена общая форма функций push() и pop(), работающих с целочисленным массивом. Стеки данных другого типа можно организовывать, изменив базовый тип данных массива.
int stack[MAX];
int tos=0; /* вершина стека */
/* Затолкать элемент в стек. */
void push(int i)
{
if(tos >= MAX) {
printf("Стак полон\n");
return;
}
stack[tos] = i;
tos++;
}
/* Получить верхний элемент стека. */
int pop(void)
{
tos--;
if(tos < 0) {
printf("Стек пуст\n");
return 0;
}
return stack[tos];
}
Переменная tos ("top of stack" — "вершина стека" ) содержит индекс вершины стека. При реализации данных функций необходимо учитывать случаи, когда стек заполнен или пуст. В нашем случае признаком пустого стека является равенство tos нулю, а признаком переполнения стека — такое увеличение tos, что его значение указывает куда-нибудь за пределы последней ячейки массива. Пример работы стека показан в табл. 22.2.
| Действие | Содержимое стека |
|---|---|
| push(A) | A |
| push(B) | В А |
| push(C) | C B A |
| рор() извлекает С | В А |
| push(F) | F В А |
| рор() извлекает F | В А |
| рор() извлекает В | А |
| рор() извлекает А | пусто |
Прекрасный пример использования стека — калькулятор с четырьмя действиями. Большинство современных калькуляторов воспринимают стандартную запись выражений, называемую инфиксной записью , общая форма которой выглядит как операнд-оператор-операнд. Например, чтобы сложить 100 и 200, необходимо ввести 100, нажать кнопку "плюс" ("+"), затем ввести 200 и нажать кнопку "равно" ("="). Напротив, во многих ранних калькуляторах (и некоторых из производимых сегодня) применяется постфиксная запись , в которой сначала вводятся оба операнда, а затем оператор. Например, чтобы сложить 100 и 200 в постфиксной записи, необходимо ввести 100, затем 200, а потом нажать клавишу "плюс". В этом методе операнды при вводе заталкиваются в стек. При вводе оператора операнды извлекаются (выталкиваются) из стека, а результат помещается обратно в стек. Одно из преимуществ постфиксной формы заключается в легкости ввода длинных сложных выражений.
Следующий пример демонстрирует использование стека в программе, реализующей постфиксный калькулятор для целочисленных выражений. Для начала необходимо модифицировать функции push() и pop(), как показано ниже. Следует знать, что стек будет размешаться в динамически распределяемой памяти, а не в массиве фиксированного размера. Хотя применение динамического распределения памяти и не требуется в таком простом примере, мы увидим, как использовать динамическую память для хранения данных стека.
int *p; /* указатель на область свободной памяти */
int *tos; /* указатель на вершину стека */
int *bos; /* указатель на дно стека */
/* Занесение элемента в стек. */
void push(int i)
{
if(p > bos) {
printf("Стек полон\n");
return;
}
*p = i;
p++;
}
/* Получение верхнего элемента из стека. */
int pop(void)
{
p--;
if(p < tos) {
printf("Стек пуст\n");
return 0;
}
return *p;
}
Перед использованием этих функций необходимо выделить память из области свободной памяти с помощью функции malloc() и присвоить переменой tos адрес начала этой области, а переменной bos — адрес ее конца.
Текст программы постфиксного калькулятора целиком приведен ниже.
/* Простой калькулятор с четырмя действиями. */
#include
#include
#define MAX 100
int *p; /* указатель на область свободной памяти */
int *tos; /* указатель на вершину стека */
int *bos; /* указатель на дно стека */
void push(int i);
int pop(void);
int main(void)
{
int a, b;
char s[80];
p = (int *) malloc(MAX*sizeof(int)); /* получить память для стека */
if(!p) {
printf("Ошибка при выделении памяти\n");
exit(1);
}
tos = p;
bos = p + MAX-1;
printf("Калькулятор с четырьмя действиями\n");
printf("Нажмите 'q' для выхода\n");
do {
printf(": ");
gets(s);
switch(*s) {
case '+':
a = pop();
b = pop();
printf("%d\n", a+b);
push(a+b);
break;
case '-':
a = pop();
b = pop();
printf("%d\n", b-a);
push(b-a);
break;
case '*':
a = pop();
b = pop();
printf("%d\n", b*a);
push(b*a);
break;
case '/':
a = pop();
b = pop();
if(a==0) {
printf("Деление на 0.\n");
break;
}
printf("%d\n", b/a);
push(b/a);
break;
case '.': /* показать содержимое вершины стека */
a = pop();
push(a);
printf("Текущее значение на вершине стека: %d\n", a);
break;
default:
push(atoi(s));
}
} while(*s != 'q');
return 0;
}
/* Занесение элемента в стек. */
void push(int i)
{
if(p > bos) {
printf("Стек полон\n");
return;
}
*p = i;
p++;
}
/* Получение верхнего элемента из стека. */
int pop(void)
{
p--;
if(p < tos) {
printf("Стек пуст\n");
return 0;
}
return *p;
}
Иными словами, в магазинном порядке.
А также: проталкивать (в стек), помещать на стек, класть в стек, поместить в стек, положить в стек, сохранить в стеке.
А также: выталкивать данные из стека, выталкивание из стека, выталкивание данных из стека, снимать со стека, вынимать из стека, считывать из стека, вытаскивать из стека.
Называется также верхушкой.
Другие названия: инфиксное представление, инфиксная нотация.
Другие названия: постфиксная нотация, польская инверсная запись.
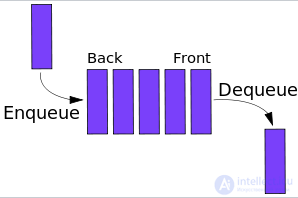
| Характеристика | Очередь (Queue) | Стек (Stack) | Связанный список (Linked List) | Массив (Array) | Дек (Deque) | Куча (Heap) |
|---|---|---|---|---|---|---|
|
Принцип работы
|
FIFO (первый вошел — первый вышел) | LIFO (последний вошел — первый вышел) | Элементы связаны указателями | Индексы фиксированы | Доступ к обоим концам | Дерево, где родитель >= (max heap) или <= (min heap) дочерних элементов |
|
Добавление элементов
|
В конец (enqueue) | В конец (push) | В начало или конец | В любую позицию | В начало или конец | В корень (с балансировкой) |
|
Удаление элементов
|
Из начала (dequeue) | Из конца (pop) | В любой позиции (требует обхода) | В любой позиции (но требует сдвига) | В начало и конец | Из корня (с перестановкой) |
|
Доступ к элементам
|
Только к первому (head) | Только к последнему (top) | Последовательный (через ссылки) | Прямой доступ по индексу | В начало и конец | Только к корню (наибольший или наименьший элемент) |
|
Время работы (среднее)
|
O(1) (добавление/удаление) | O(1) (добавление/удаление) | O(1) (добавление в начало/конец) | O(1) (доступ), O(n) (вставка/удаление) | O(1) (операции с концами) | O(log n) (добавление, удаление, доступ к корню) |
| Где используется | Фоновые задачи, управление потоками, BFS-алгоритмы | Рекурсия, отмена действий (Ctrl+Z) | Динамические структуры, обход графов | Статические структуры, быстрый доступ | Буферы, парсеры, обработка данных | Очередь с приоритетами, алгоритмы Дейкстры и Хаффмана, хранение классов |
 |
 |
 |
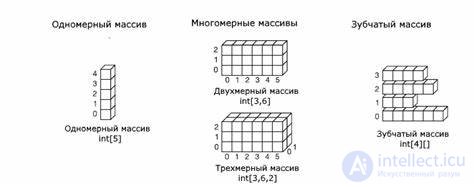 |
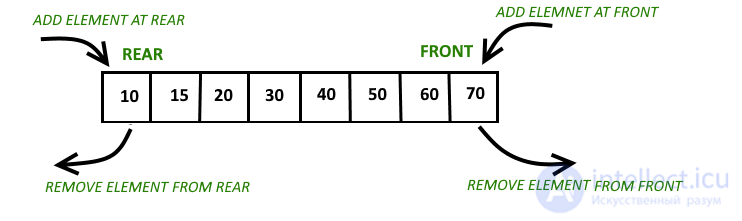 |
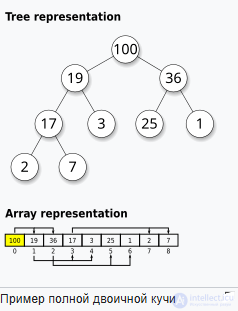 |
Исследование, описанное в статье про стек, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое стек, стеки, операции pop, операция push и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных






Комментарии