Лекция
Привет, сегодня поговорим про бинарный поиск, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое бинарный поиск, метод деления пополам, поиск по бинарному дереву , настоятельно рекомендую прочитать все из категории Структуры данных.
Будем предполагать, что имеем упорядоченный по возрастанию массив чисел. Основная идея - выбрать случайно некоторый элемент AM и сравнить его с аргументом поиска Х. Если AM=Х, то поиск закончен; если AM M >X.
Выбор М совершенно произволен в том смысле, что корректность алгоритма от него не зависит. Однако на его эффективность выбор влияет. Ясно, что наша задача- исключить как можно больше элементов из дальнейшего поиска. Оптимальным решением будет выбор среднего элемента, т.е. середины массива.
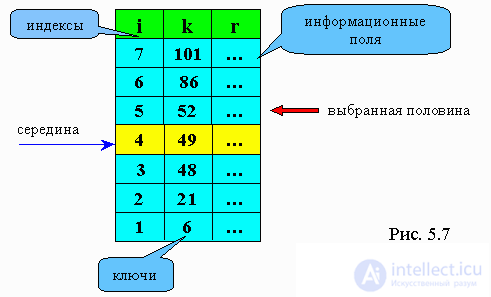
Рассмотрим пример, представленный на рис. 5.7. Допустим нам необходимо найти элемент с ключом 52. Первым сравниваемым элементом будет 49. Так как 49<52, то ищем следующую середину среди элементов, расположенных выше 49. Это число 86. 86>52, поэтому теперь ищем 52 среди элементов, расположенных ниже 86, но выше 49. На следующем шаге обнаруживаем, что очередное значение середины равно 52. Мы нашли элемент в массиве с заданным ключом.
Программы на псевдокоде и Паскале:
Low = 1 hi = n while (low <= hi) do mid = (low + hi) div 2 if key = k(mid) then search = mid return endif if key < k(mid) then hi = mid - 1 else low = mid + 1 endif endwhile search = 0 return |
low := 1; hi := n; while (low <= hi) do begin mid := (low + hi) div 2; if key = k[mid] then begin search := mid; exit; end; if key < k[mid] then hi := mid - 1 else low := mid + 1; end; search := 0; exit |
При key = 101 запись будет найдена за три сравнения (в последовательном поиске понадобилось бы семь сравнений).
Если С - количество сравнений, а n - число элементов в таблице, то
С = log2n.
Например, n = 1024.
При последовательном поиске С = 512, а при бинарном
С = 10.
Можно совместить бинарный и индексно-последовательный поиск (при больших объемах данных), учитывая, что последний также используется при отсортированном массиве.
Бинарный поиск производится в упорядоченном массиве.
При бинарном поиске искомый ключ сравнивается с ключом среднего элемента в массиве. Если они равны, то поиск успешен. В противном случае поиск осуществляется аналогично в левой или правой частях массива.
Алгоритм может быть определен в рекурсивной и нерекурсивной формах.
Бинарный поиск также называют поиском методом деления отрезка пополам или дихотомии.
Количество шагов поиска определится как
log2n↑,
где n-количество элементов,
↑ — округление в большую сторону до ближайшего целого числа.
На каждом шаге осуществляется поиск середины отрезка по формуле
mid = (left + right)/2
Если искомый элемент равен элементу с индексом mid, поиск завершается.
В случае если искомый элемент меньше элемента с индексом mid, на место mid перемещается правая граница рассматриваемого отрезка, в противном случае — левая граница.

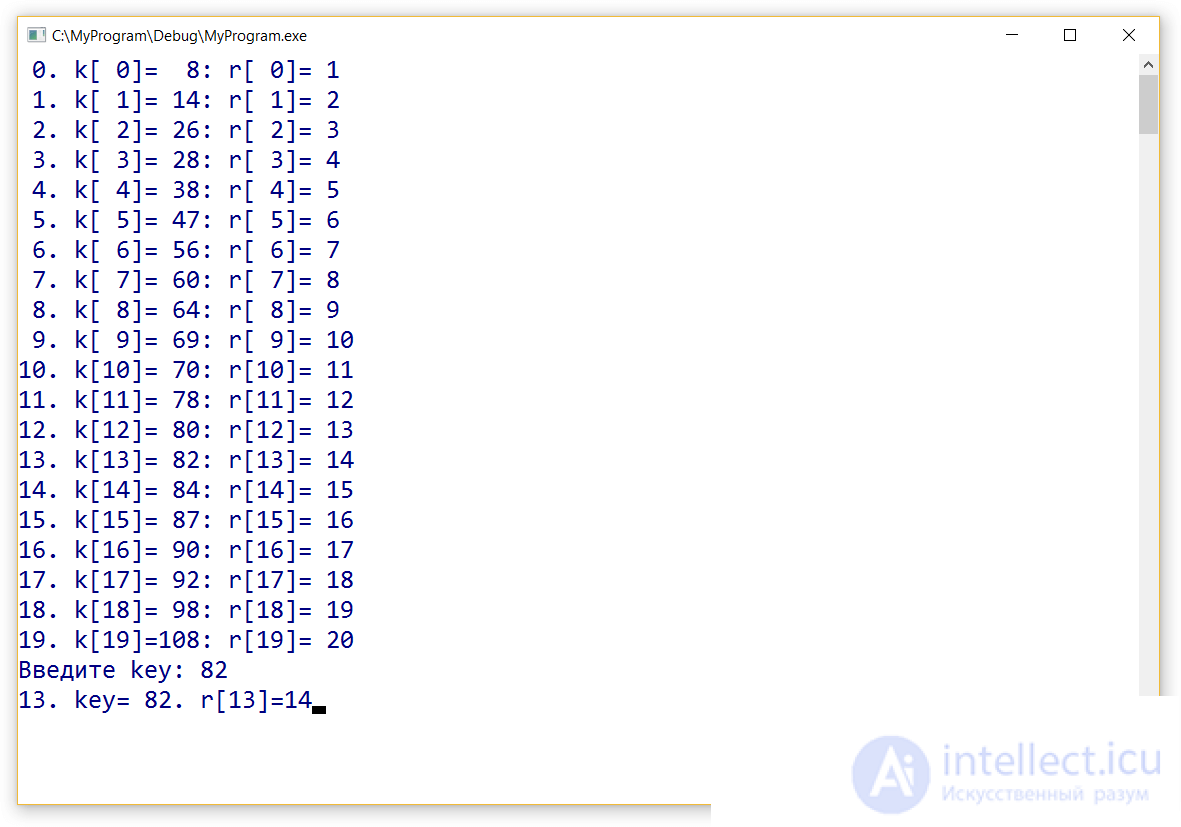
left = 0, right = 19
mid = (19+0)/2=9
Сравниваем значение по этому индексу с искомым:
69 < 82
Сдвигаем левую границу:
left = mid = 9
mid = (9+19)/2=14
Сравниваем значение по этому индексу с искомым:
84 > 82
Сдвигаем правую границу:
right = mid = 14
mid = (9+14)/2=11
Сравниваем значение по этому индексу с искомым:
78 < 82
Сдвигаем левую границу:
left = mid = 11
mid = (11+14)/2=12
Сравниваем значение по этому индексу с искомым:
80 < 82
Сдвигаем левую границу:
left = mid = 12
mid = (12+14)/2=13
Сравниваем значение по этому индексу с искомым:
82 = 82
Решение найдено!
Чтобы уменьшить количество шагов поиска можно сразу смещать границы поиска на элемент, следующий за серединой отрезка:
left = mid + 1
right = mid — 1
Реализация бинарного поиска на Си
Результат выполнения
Назначение его в том, чтобы по заданному ключу осуществить поиск узла дерева. Длительность операции зависит от структуры дерева. Действительно, дерево может быть вырождено в однонаправленный список, как правое на рис. 5.8.
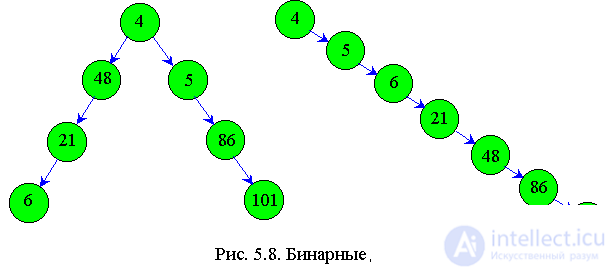
В этом случае время поиска будет такое же, как и в однонаправленном списке, т.е. придется перебирать N/2 элементов.
Наибольшего эффекта использования дерева достигается в том случае, когда дерево сбалансировано.В этом случае для поиска придотся перебрать не больше log2N элементов.
Строго сбалансированное дерево - это дерево, в котором каждый узел имеет левое и правое поддеревья, отличающиеся по уровню не более, чем на единицу.
Поиск элемента в бинарном дереве называется бинарным поиском по дереву.
Такое дерево называют деревом бинарного поиска.
Суть поиска заключается в следующем. Анализируем вершину очередного поддерева. Если ключ меньше информационного поля вершины, то анализируем левое поддерево, больше - правое.
Пусть задан аргумент key
p = tree whlie p <> nil do if key = k(p) then search = p return endif if key < k(p) then p = left(p) else p = right(p) endif endwhile search = nil return |
p := tree; whlie p <> nil do begin if key = p^.k then begin search := p; exit; end; if key < p^.k then p := p^.left else p := p^.right; end; search := nil; |
На этом все! Теперь вы знаете все про бинарный поиск, Помните, что это теперь будет проще использовать на практике. Надеюсь, что теперь ты понял что такое бинарный поиск, метод деления пополам, поиск по бинарному дереву и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных
Комментарии
Оставить комментарий
Структуры данных
Термины: Структуры данных