Лекция
Привет, Вы узнаете о том , что такое список , Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое список , односвязные списки, связанные списки, двусвязные списки, односвязный список, связанный список, двусвязный список , настоятельно рекомендую прочитать все из категории Структуры данных.
В информатике, список (англ. list) — является абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться более одного раза. Экземпляр списка является компьютерной реализацией математического понятия конечной последовательности. Экземпляры значений, находящихся в списке, называются элементами списка (англ. item, entry либо element); если значение встречается несколько раз, каждое вхождение считается отдельным элементом.

Структура односвязного списка из трех элементов
Термином список также называется несколько конкретных структур данных, применяющихся при реализации абстрактных списков, особенно связных списков.
Как известно, программы состоят из двух частей — алгоритмов и структур данных. В хорошей программе эти составляющие эффективно дополняют друг друга. Выбор и реализация структуры данных насколько же важны, как и процедуры для обработки данных. Способ организации и доступа к информации обычно определяется природой программируемой задачи. Таким образом, для программиста важно иметь в своем распоряжении приемы, подходящие для различных ситуаций.
Степень привязки типа данных к своему машинному представлению находится в обратной зависимости от его абстракции. Другими словами, чем более абстрактными становятся типы данных, тем больше концептуальное представление о способе хранения этих данных отличается от реального, фактического способа их хранения в памяти компьютера Простые типы, например, char или int, тесно связаны со своим машинным представлением. Например, машинное представление целочисленного значения хорошо аппроксимирует соответствующую концепцию программирования. По мере своего усложнения типы данных становятся концептуально менее похожими на свои машинные эквиваленты. Так, действительные числа с плавающей точкой более абстрактны, чем целые числа. Фактическое представление типа float в машине весьма приблизительно соответствует представлению среднего программиста о действительном числе. Еще более абстрактной является структура, принадлежащая к составным типам данных.
На следующем уровне абстракции сугубо физические аспекты данных отходят на второй план вследствие введения механизма доступа(data engine) к данным, то есть механизма сохранения и получения информации. По существу, физические данные связываются с механизмом доступа, который управляет работой с данными из программы. Именно механизмам доступа к данным и посвящена эта глава.
Существует четыре механизма доступа:
Каждый из этих методов дает возможность решать задачи определенного класса. Эти методы по существу являются механизмами, выполняющими определенные операции сохранения и получения передаваемой им информации на основе получаемых ими запросов. Они все сохраняют и получают элемент, здесь под элементом подразумевается информационная единица. В этой главе показано, как создавать такие механизмы доступа на языке С. При этом проиллюстрированы некоторые распространенные приемы программирования в С, включая динамическое выделение памяти и использование указателей.

Другие названия: магазин, стековая память, магазинная память, память магазинного типа, запоминающее устройство магазинного типа, стековое запоминающее устройство.
Другие названия: цепной список, список с использованием указателей, список со ссылками, список на указателях.
Другие названия: дерево двоичного поиска.
При помощи нотации метода синтаксически-ориентированного конструирования Ч. Хоара определение списка можно записать следующим образом:






Первая строка данного определения обозначает, что список элементов типа  (говорят: «список над ») представляет собой размеченное объединение пустого списка и декартова произведения атома типа со списком над . Для создания списков используются два конструктора (вторая строка определения), первый из которых создает пустой список, а второй — непустой соответственно. Вполне понятно, что второй конструктор получает на вход в качестве параметров некоторый атом и список, а возвращает список, первым элементом которого является исходный атом, а остальными — элементы исходного списка. То есть получается префиксация атома к списку, с чем и связано такое наименование конструктора. Пустой список
(говорят: «список над ») представляет собой размеченное объединение пустого списка и декартова произведения атома типа со списком над . Для создания списков используются два конструктора (вторая строка определения), первый из которых создает пустой список, а второй — непустой соответственно. Вполне понятно, что второй конструктор получает на вход в качестве параметров некоторый атом и список, а возвращает список, первым элементом которого является исходный атом, а остальными — элементы исходного списка. То есть получается префиксация атома к списку, с чем и связано такое наименование конструктора. Пустой список  не является атомом, а потому не может префиксироваться. С другой стороны, пустой список является нулевым элементом для конструирования списков, поэтому любой список содержит в самом своем конце пустой список — с него начинается конструирование.
не является атомом, а потому не может префиксироваться. С другой стороны, пустой список является нулевым элементом для конструирования списков, поэтому любой список содержит в самом своем конце пустой список — с него начинается конструирование.
Третья строка определяет селекторы для списка, то есть операции для доступа к элементам внутри списка. Селектор  получает на вход список и возвращает первый элемент этого списка, то есть типом результата является тип . Этот селектор не может получить на вход пустой список — в этом случае результат операции неопределен. Селектор
получает на вход список и возвращает первый элемент этого списка, то есть типом результата является тип . Этот селектор не может получить на вход пустой список — в этом случае результат операции неопределен. Селектор  возвращает список, полученный из входного в результате отсечения его головы (первого элемента). Этот селектор также не может принимать на вход пустой список, так как в этом случае результат операции неопределен. При помощи этих двух операций можно достать из списка любой элемент. Например, чтобы получить третий элемент списка (если он имеется), необходимо последовательно два раза применить селектор , после чего применить селекто . Другими словами, для получения элемента списка, который находится на позиции
возвращает список, полученный из входного в результате отсечения его головы (первого элемента). Этот селектор также не может принимать на вход пустой список, так как в этом случае результат операции неопределен. При помощи этих двух операций можно достать из списка любой элемент. Например, чтобы получить третий элемент списка (если он имеется), необходимо последовательно два раза применить селектор , после чего применить селекто . Другими словами, для получения элемента списка, который находится на позиции  (начиная с
(начиная с  для первого элемента, как это принято в программировании), необходимо раз применить селектор , после чего применить селектор .
для первого элемента, как это принято в программировании), необходимо раз применить селектор , после чего применить селектор .
Четвертая строка определения описывает предикаты для списка, то есть функции, возвращающие булевское значение в зависимости от некоторых условий. Первый предикат возвращает значение  в случае, если заданный список пуст. Второй предикат действует наоборот. Наконец, пятая строка описывает части списка, которые, как уже сказано, представляют собой пустой и непустой списки.
в случае, если заданный список пуст. Второй предикат действует наоборот. Наконец, пятая строка описывает части списка, которые, как уже сказано, представляют собой пустой и непустой списки.
У определенной таким образом структуры данных имеются некоторые свойства:
, над которым строится список; все элементы в списке должны быть этого типа.Списки используются для хранения наборов однотипных элементов. Такие элементы могут быть отсортированы для использования в функциях поиска или функциях для быстрой вставки новых элементов в список.
Списки обычно реализуются либо в виде связанных списков (односвязных или двусвязных), либо в виде массивов , обычно переменной длины или динамических массивов .
Стандартный способ реализации списков, созданных на языке программирования Lisp , состоит в том, чтобы каждый элемент списка содержал как свое значение, так и указатель, указывающий местоположение следующего элемента в списке. В результате получается либо связанный список, либо дерево , в зависимости от того, есть ли в списке вложенные подсписки. Некоторые старые реализации Лиспа (например, реализация Лиспа Symbolics 3600) также поддерживали «сжатые списки» (с использованием кодирования CDR ), которые имели специальное внутреннее представление (невидимое для пользователя). Об этом говорит сайт https://intellect.icu . Списками можно управлять с помощью итерации или рекурсии . Первый часто предпочитается в императивных языках программирования., в то время как последнее является нормой для функциональных языков .
Списки могут быть реализованы как самобалансирующиеся бинарные деревья поиска, содержащие пары индекс-значение, обеспечивающие равновременный доступ к любому элементу (например, все, находящиеся на периферии, и внутренние узлы, хранящие индекс самого правого дочернего элемента, используемые для направления поиска) , взяв время логарифмическое в размере списка, но пока оно не сильно изменится, обеспечит иллюзию произвольного доступа и также включит операции подкачки, префикса и добавления в логарифмическом времени.
Некоторые языки не предлагают структуру данных списка , но предлагают использование ассоциативных массивов или какой-либо таблицы для имитации списков. Например, Lua предоставляет таблицы. Хотя Lua хранит списки с числовыми индексами в виде массивов внутри, они по-прежнему отображаются как словари.
В Лиспе списки являются основным типом данных и могут представлять как программный код, так и данные. В большинстве диалектов список первых трех простых чисел может быть записан как (list 2 3 5). В нескольких диалектах Лиспа, включая Scheme , список представляет собой набор пар, состоящий из значения и указателя на следующую пару (или нулевого значения), составляющих
односвязный список .
Списки в функциональных языках являются фундаментальной структурой. Большинство функциональных языков имеет встроенные средства для работы со списками вроде получения длины списка, головы (первый элемент списка), хвоста (часть списка, идущая за первым элементом), применения функции к каждому элементу списка (Map), свертки списка и пр.
Как следует из названия, списки можно использовать для хранения списка элементов. Однако, в отличие от традиционных массивов , списки могут расширяться и сжиматься и динамически хранятся в памяти.
В вычислительной технике списки реализовать проще, чем наборы. Конечное множество в математическом смысле может быть реализовано в виде списка с дополнительными ограничениями; то есть повторяющиеся элементы запрещены, и порядок не имеет значения. Сортировка списка ускоряет определение того, находится ли данный элемент уже в наборе, но для обеспечения порядка требуется больше времени для добавления новой записи в список. Однако в эффективных реализациях наборы реализуются с использованием самобалансирующихся двоичных деревьев поиска или хэш-таблиц , а не списка.
Списки также составляют основу для других абстрактных типов данных, включая очередь , стек и их варианты.
Тип абстрактного списка L с элементами некоторого типа E ( мономорфный список) определяется следующими функциями:
ноль: () → L
минусы: E × L → L
сначала: L → E
отдых: L → L
с аксиомами
first (cons ( e , l )) = e
остаток (cons ( e , l )) = l
для любого элемента e и любого списка l . Подразумевается, что
минусы ( д , л ) ≠ л
минусы ( е , л ) ≠ е
cons ( e 1 , l 1 ) = cons ( e 2 , l 2 ), если e 1 = e 2 и l 1 = l 2
Обратите внимание, что first (nil ()) и rest (nil ()) не определены.
Эти аксиомы эквивалентны аксиомам абстрактного типа данных стека .
В теории типов приведенное выше определение проще рассматривать как индуктивный тип, определяемый в терминах конструкторов: nil и cons . В алгебраических терминах, это можно представить как преобразование 1 + Е × L → L . first и rest затем получаются путем сопоставления с образцом в конструкторе cons и отдельной обработки случая nil .
Тип списка образует монаду со следующими функциями (с использованием E * вместо L для представления мономорфных списков с элементами типа E ):


где добавление определяется как:

В качестве альтернативы, монада может быть определена в терминах операций return , fmap и join с помощью:


Обратите внимание, что fmap , join , append и bind четко определены, поскольку они применяются к более глубоким аргументам при каждом рекурсивном вызове.
Тип списка - это аддитивная монада, где nil является монадическим нулем, а добавление - монадической суммой.
Списки образуют моноид при операции добавления . Идентификационным элементом моноида является пустой список nil . Фактически, это свободный моноид над множеством элементов списка.
Очереди и стеки имеют две характерные особенности: обе структуры данных имеют строгие правила доступа к хранящимся в них данным, причем в результате выполнения операций извлечения данные, в сущности, уничтожаются. Другими словами, доступ к элементу в стеке или очереди приводит к его удалению, и если этот элемент не сохранить где-либо в другом месте, он теряется. Кроме того, и в стеке, и в очереди используется один последовательный участок памяти. В отличие от стека или очереди, связанный список допускает гибкие способы доступа, поскольку каждый фрагмент информации имеет ссылку на следующий элемент данных в цепочке. Кроме того, операция извлечения не приводит к удалению из списка и уничтожению элемента данных. В принципе, для этой цели необходимо ввести дополнительную специальную операцию удаления.
Связанные списки могут быть односвязными и двусвязными . Односвязный список содержит ссылку на следующий элемент данных. двусвязный список содержит ссылки как на последующий, так и на предыдущий элементы списка. Выбор типа применяемого списка зависит от конкретной задачи.
Связанные списки часто называются связными. Односвязные списки называются еще односвязными линейными списками, однонаправленными списками, а также однонаправленными цепочками. Двусвязные списки иногда называются также дважды связанными; кроме того, их называют двусвязными линейными списками, а также двунаправленными цепочками.
В односвязном списке каждый элемент информации содержит ссылку на следующий элемент списка. Каждый элемент данных обычно представляет собой структуру, которая состоит из информационных полей и указателя связи. Концептуально односвязный список выглядит так, как показано на рис. 22.2.

Рис. 22.2 Односвязный список
Существует два основных способа построения односвязного списка. Первый способ — помещать новые элементы в конец списка . Второй — вставлять элементы в определенные позиции списка, например, в порядке возрастания. От способа построения списка зависит алгоритм функции добавления элемента. Давайте начнем с более простого способа создания списка путем помещения элементов в конец.
Как правило, элементы связанного списка являются структурами, так как, помимо данных, они содержат ссылку на следующий элемент. Поэтому необходимо определить структуру, которая будет использоваться в последующих примерах. Поскольку списки рассылки обычно хранятся в связанных списках, хорошим выбором будет структура, описывающая почтовый адрес. Ее описание показано ниже:
struct address {
char name[40];
char street[40];
char city[20];
char state ;
char zip[11];
struct address *next; /* ссылка на следующий адрес */
} info;
Приведенная ниже функция slstore() создает односвязный список путем помещения каждого очередного элемента в конец списка. В качестве параметров ей передаются указатель на структуру типа address, содержащую новую запись, и указатель на последний элемент списка. Если список пуст, указатель на последний элемент должен быть равен нулю.
void slstore(struct address *i,
struct address **last)
{
if(!*last) *last = i; /* первый элемент в списке */
else (*last)->next = i;
i->next = NULL;
*last = i;
}
Несмотря на то, что созданный с помощью функции slstore() список можно отсортировать отдельной операцией уже после его создания, легче сразу создавать упорядоченный список, вставляя каждый новый элемент в нужное место в последовательности. Кроме того, если список уже отсортирован, имеет смысл поддерживать его упорядоченность, вставляя новые элементы в соответствующие позиции. Для вставки элемента таким способом требуется последовательно просматривать список до тех пор, пока не будет найдено место нового элемента, затем вставить в найденную позицию новую запись и переустановить ссылки.
При вставке элемента в односвязный список может возникнуть одна из трех ситуаций: элемент становится первым, элемент вставляется между двумя другими, элемент становится последним. На рис. 22.3 показана схема изменения ссылок в каждом случае.

Вставка в начало списка

Вставка в середину списка

Вставка в конец списка
Следует помнить, что при вставке элемента в начало (первую позицию) списка необходимо также изменить адрес входа в список где-то в другом месте программы. Чтобы избежать этих сложностей, можно в качестве первого элемента списка хранить служебный сторожевойэлемент . В случае упорядоченного списка необходимо выбрать некоторое специальное значение, которое всегда будет первым в списке, чтобы начальный элемент оставался неизменным. Недостатком данного метода является довольно большой расход памяти на хранение сторожевого элемента, но обычно это не столь важно.
Следующая функция, sls_store(), вставляет структуры типа address в список рассылки, упорядочивая его по возрастанию значений в поле name. Функция принимает указатели на указатели на первый и последний элементы списка, а также указатель на вставляемый элемент. Поскольку первый или последний элементы списка могут измениться, функция sls_store() при необходимости автоматически обновляет указатели на начало и конец списка. При первом вызове данной функции указатели first и last должны быть равны нулю.
/* Вставка в упорядоченный односвязный список. */
void sls_store(struct address *i, /* новый элемент */
struct address **start, /* начало списка */
struct address **last) /* конец списка */
{
struct address *old, *p;
p = *start;
if(!*last) { /* первый элемент в списке */
i->next = NULL;
*last = i;
*start = i;
return;
}
old = NULL;
while(p) {
if(strcmp(p->name, i->name)<0) {
old = p;
p = p->next;
}
else {
if(old) { /* вставка в середину */
old->next = i;
i->next = p;
return;
}
i->next = p; /* вставка в начало */
*start = i;
return;
}
}
(*last)->next = i; /* вставка в конец */
i->next = NULL;
*last = i;
}
Последовательный перебор элементов связанного списка осуществляется очень просто: начать с начала и следовать указателям. Обычно фрагмент кода перебора настолько мал, что его вставляют в другую процедуру — например, функцию поиска, удаления или отображения содержимого. Так, приведенная ниже функция выводит на экран все имена из списка рассылки:
void display(struct address *start)
{
while(start) {
printf("%s\n", start->name);
start = start->next;
}
}
При вызове функции display() параметр start должен быть указателем на первую структуру в списке. После этого функция переходит к следующему элементу, на который указывает указатель в поле next. Процесс прекращается, когда next равно нулю.
Для получения элемента из списка нужно просто пройти по цепочке ссылок. Ниже приведен пример функции поиска по содержимому поляname:
struct address *search(struct address *start, char *n)
{
while(start) {
if(!strcmp(n, start->name)) return start;
start = start->next;
}
return NULL; /* подходящий элемент не найден */
}
Поскольку функция search() возвращает указатель на элемент списка, содержащий искомое имя, возвращаемый тип описан как указатель на структуру address. При отсутствии в списке подходящих элементов возвращается нуль (NULL).
Удаление элемента из односвязного списка выполняется просто. Так же, как и при вставке, возможны три случая: удаление первого элемента, удаление элемента в середине, удаление последнего элемента. На рис. 22.4 показаны все три операции.

Удаление первого элемента спискаУдаление среднего элемента списка
Удаление последнего элемента списка

Ниже приведена функция, удаляющая заданный элемент из списка структур address.
void sldelete(
struct address *p, /* предыдущий элемент */
struct address *i, /* удаляемый элемент */
struct address **start, /* начало списка */
struct address **last) /* конец списка */
{
if(p) p->next = i->next;
else *start = i->next;
if(i==*last && p) *last = p;
}
Функции sldelete() необходимо передавать указатели на удаляемый элемент, предшествующий удаляемому, а также на первый и последний элементы. При удалении первого элемента указатель на предшествующий элемент должен быть равен нулю (NULL). Данная функция автоматически обновляет указатели start и last, если один из них ссылается на удаляемый элемент.
У односвязных списков есть один большой недостаток: односвязный список невозможно прочитать в обратном направлении. По этой причине обычно применяются двусвязные списки.
Не забывайте, что у односвязного списка, как и у веревки, два конца: начало и конец.
Часто называется еще сигнальной меткой.
Двусвязный список состоит из элементов данных, каждый из которых содержит ссылки как на следующий, так и на предыдущий элементы. На рис. 22.5 показана организация ссылок в двусвязном списке.

Рис. 22.5. Двусвязные списки
Наличие двух ссылок вместо одной предоставляет несколько преимуществ. Вероятно, наиболее важное из них состоит в том, что перемещение по списку возможно в обоих направлениях. Это упрощает работу со списком, в частности, вставку и удаление. Помимо этого, пользователь может просматривать список в любом направлении. Еще одно преимущество имеет значение только при некоторых сбоях. Поскольку весь список можно пройти не только по прямым, но и по обратным ссылкам, то в случае, если какая-то из ссылок станет неверной, целостность списка можно восстановить по другой ссылке.
При вставке нового элемента в двусвязный список могут быть три случая: элемент вставляется в начало, в середину и в конец списка. Эти операции показаны на рис. 22.6.
Вставка элемента в начало списка
+-----+ +-----+
| new | \/\/\->| new |
+--+--+ п +--+--+
| | | р .----------->|0 | |
| | | е | | | |
+--+--+ в | +--+|-+
р | _____|
а | |
+-----+ +-----+ +-----+ щ в | +-----+ | +-----+ +-----+
|info | |info | |info | а \/\/\->|info |<-' |info | |info |
\/\/\->+--+--+ +--+--+ +--+--+ т | +--+--+ +--+--+ +--+--+
|0 | |--->| | |--->| |0 | с | | | |--->| | |--->| |0 |
| | |<---| | |<---| | | я '-| | |<---| | |<---| | |
+--+--+ +--+--+ +--+--+ +--+--+ +--+--+ +--+--+
Вставка элемента в середину списка
+-----+ +-----+
| new | | new |
+--+--+ п +--+--+
| | | р .---------| | |
| | | е | .--->| | |
+--+--+ в | | +--+A|+
р | | _____||
а | | | |
+-----+ +-----+ +-----+ щ в +--V--+ | | +--+-V+ +-----+
|info | |info | |info | а \/\/\->|info | | | |info | |info |
\/\/\->+--+--+ +--+--+ +--+--+ т +--+--+ | | +--+--+ +--+--+
|0 | |--->| | |--->| |0 | с |0 | |-' '-| | |--->| |0 |
| | |<---| | |<---| | | я | | | | | |<---| | |
+--+--+ +--+--+ +--+--+ +--+--+ +--+--+ +--+--+
Вставка элемента в конец списка
+-----+ +-----+
| new | | new |
+--+--+ п +--+--+
| | | р | |0 |
| | | е | | |<-----------.
+--+--+ в +|-+--+ |
р |____________ |
а | |
+-----+ +-----+ +-----+ щ в +-----+ +-----+ +--V--+ |
|info | |info | |info | а \/\/\->|info | |info | |info | |
\/\/\->+--+--+ +--+--+ +--+--+ т +--+--+ +--+--+ +--+--+ |
|0 | |--->| | |--->| |0 | с |0 | |--->| | |--->| | |-'
| | |<---| | |<---| | | я | | |<---| | |<---| | |
+--+--+ +--+--+ +--+--+ +--+--+ +--+--+ +--+--+
|
Рис. 22.6. Операции с двусвязными списками (Здесь new - вставляемый элемент, а info - поле данных)
Построение двусвязного списка выполняется аналогично построению односвязного за исключением того, что необходимо установить две ссылки. Поэтому в структуре данных должны быть описаны два указателя связи. Возвращаясь к примеру списка рассылки, для двусвязного списка структуру address можно модифицировать следующим образом:
struct address {
char name[40];
char street[40] ;
char city[20];
char state ;
char zip[11];
struct address *next;
struct address *prior;
} info;
Следующая функция, dlstore(), создает двусвязный список, используя структуру address в качестве базового типа данных:
void dlstore(struct address *i, struct address **last)
{
if(!*last) *last = i; /* вставка первого элемента */
else (*last)->next = i;
i->next = NULL;
i->prior = *last;
*last = i;
}
Функция dlstore() помещает новые записи в конец списка. В качестве параметров ей необходимо передавать указатель на сохраняемые данные; а также указатель на конец списка, который при первом вызове должен быть равен нулю (NULL).
Подобно односвязным, двусвязные списки можно создавать с помощью функции, которая будет помещать элементы в определенные позиции, а не только в конец списка. Показанная ниже функция dls_store() создает список, упорядочивая его по возрастанию имен:
/* Создание упорядоченного двусвязного списка. */
void dls_store(
struct address *i, /* новый элемент */
struct address **start, /* первый элемент в списке */
struct address **last /* последний элемент в списке */
)
{
struct address *old, *p;
if(*last==NULL) { /* первый элемент в списке */
i->next = NULL;
i->prior = NULL;
*last = i;
*start = i;
return;
}
p = *start; /* начать с начала списка */
old = NULL;
while(p) {
if(strcmp(p->name, i->name)<0){
old = p;
p = p->next;
}
else {
if(p->prior) {
p->prior->next = i;
i->next = p;
i->prior = p->prior;
p->prior = i;
return;
}
i->next = p; /* новый первый элемент */
i->prior = NULL;
p->prior = i;
*start = i;
return;
}
}
old->next = i; /* вставка в конец */
i->next = NULL;
i->prior = old;
*last = i;
}
Поскольку первый и последний элементы списка могут меняться, функция dls_store() автоматически обновляет указатели на начало и конец списка посредством параметров start и last. При вызове функции необходимо передавать указатель на сохраняемые данные и указатели на указатели на первый и последний элементы списка. В первый раз параметры start и last должны быть равны нулю (NULL).
Как и в односвязных списках, для получения элемента данных двусвязного списка необходимо переходить по ссылкам до тех пор, пока не будет найден искомый элемент.
При удалении элемента двусвязного списка могут возникнуть три случая: удаление первого элемента, удаление элемента из середины и удаление последнего элемента. На рис. 22.7 показано, как при этом изменяются ссылки. Показанная ниже функция dldelete() удаляет элемент двусвязного списка:
void dldelete(
struct address *i, /* удаляемый элемент */
struct address **start, /* первый элемент */
struct address **last) /* последний элемент */
{
if(i->prior) i->prior->next = i->next;
else { /* new first item */
*start = i->next;
if(start) start->prior = NULL;
}
if(i->next) i->next->prior = i->prior;
else /* удаление последнего элемента */
*last = i->prior;
}
Поскольку первый или последний элементы списка могут быть удалены, функция dldelete() автоматически обновляет указатели на начало и конец списка посредством параметров start и last. При вызове ей передаются указатель на удаляемый элемент и указатели на указатели на начало и конец списка.
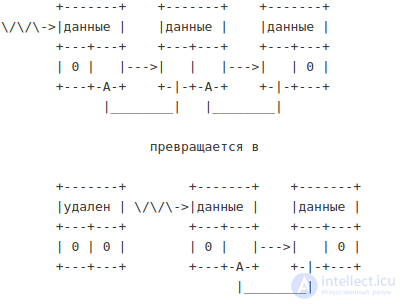
Удаление первого элемента списка

Удаление элемента из середины списка

Удаление первого элемента списка
Рис. 22.7. Удаление элемента двусвязного списка
Чтобы завершить обсуждение двусвязных списков, в данном разделе представлена простая, но законченная программа для работы со списком рассылки. Во время работы весь список хранится в оперативной памяти. Тем не менее, его можно сохранять в файле и загружать для дальнейшей работы.
/* Простая программа для обработки списка рассылки
иллюстрирующая работу с двусвязными списками.
*/
#include
#include
#include
struct address {
char name[30];
char street[40];
char city[20];
char state ;
char zip[11];
struct address *next; /* указатель на следующую запись */
struct address *prior; /* указатель на предыдущую запись */
};
struct address *start; /* указатель на первую запись списка */
struct address *last; /* указатель на последнюю запись */
struct address *find(char *);
void enter(void), search(void), save(void);
void load(void), list(void);
void mldelete(struct address **, struct address **);
void dls_store(struct address *i, struct address **start,
struct address **last);
void inputs(char *, char *, int), display(struct address *);
int menu_select(void);
int main(void)
{
start = last = NULL; /* инициализация указателей на начало и конец */
for(;;) {
switch(menu_select()) {
case 1: enter(); /* ввод адреса */
break;
case 2: mldelete(&start, &last); /* удаление адреса */
break;
case 3: list(); /* отображение списка */
break;
case 4: search(); /* поиск адреса */
break;
case 5: save(); /* запись списка в файл */
break;
case 6: load(); /* считывание с диска */
break;
case 7: exit(0);
}
}
return 0;
}
/* Выбор действия пользователя. */
int menu_select(void)
{
char s[80];
int c;
printf("1. Ввод имени\n");
printf("2. Удаление имени\n");
printf("3. Отображение содержимого списка\n");
printf("4. Поиск\n");
printf("5. Сохранить в файл\n");
printf("6. Загрузить из файла\n");
printf("7. Выход\n");
do {
printf("\nВаш выбор: ");
gets(s);
c = atoi(s);
} while(c<0 || c>7);
return c;
}
/* Ввод имени и адресов. */
void enter(void)
{
struct address *info;
for(;;) {
info = (struct address *)malloc(sizeof(struct address));
if(!info) {
printf("\nНет свободной памяти");
return;
}
inputs("Введите имя: ", info->name, 30);
if(!info->name ) break; /* завершить ввод */
inputs("Введите улицу: ", info->street, 40);
inputs("Введите город: ", info->city, 20);
inputs("Введите штат: ", info->state, 3);
inputs("Введите почтовый индекс: ", info->zip, 10);
dls_store(info, &start, &last);
} /* цикл ввода */
}
/* Следующая функция вводит с клавиатуры строку
длинной не больше count и предотвращает переполнение
строки. Кроме того, она выводит на экран подсказку. */
void inputs(char *prompt, char *s, int count)
{
char p[255];
do {
printf(prompt);
fgets(p, 254, stdin);
if(strlen(p) > count) printf("\nСлишком длинная строка\n");
} while(strlen(p) > count);
p[strlen(p)-1] = 0; /* удалить символ перевода строки */
strcpy(s, p);
}
/* Создание упорядоченного двусвязного списка. */
void dls_store(
struct address *i, /* новый элемент */
struct address **start, /* первый элемент списка */
struct address **last /* последний элемент списка */
)
{
struct address *old, *p;
if(*last==NULL) { /* первый элемент списка */
i->next = NULL;
i->prior = NULL;
*last = i;
*start = i;
return;
}
p = *start; /* начать с начала списка */
old = NULL;
while(p) {
if(strcmp(p->name, i->name)<0){
old = p;
p = p->next;
}
else {
if(p->prior) {
p->prior->next = i;
i->next = p;
i->prior = p->prior;
p->prior = i;
return;
}
i->next = p; /* новый первый элемент */
i->prior = NULL;
p->prior = i;
*start = i;
return;
}
}
old->next = i; /* вставка в конец */
i->next = NULL;
i->prior = old;
*last = i;
}
/* Удаление элемента из списка. */
void mldelete(struct address **start, struct address **last)
{
struct address *info;
char s[80];
inputs("Введите имя: ", s, 30);
info = find(s);
if(info) {
if(*start==info) {
*start=info->next;
if(*start) (*start)->prior = NULL;
else *last = NULL;
}
else {
info->prior->next = info->next;
if(info!=*last)
info->next->prior = info->prior;
else
*last = info->prior;
}
free(info); /* освободить память */
}
}
/* Поиск адреса. */
struct address *find( char *name)
{
struct address *info;
info = start;
while(info) {
if(!strcmp(name, info->name)) return info;
info = info->next; /* перейти к следующему адресу */
}
printf("Имя не найдено.\n");
return NULL; /* нет подходящего элемента */
}
/* Отобразить на экране весь список. */
void list(void)
{
struct address *info;
info = start;
while(info) {
display(info);
info = info->next; /* перейти к следующему адресу */
}
printf("\n\n");
}
/* Данная функция выполняет собственно вывод на экран
всех полей записи, содержащей адрес. */
void display(struct address *info)
{
printf("%s\n", info->name);
printf("%s\n", info->street);
printf("%s\n", info->city);
printf("%s\n", info->state);
printf("%s\n", info->zip);
printf("\n\n");
}
/* Поиск имени в списке. */
void search(void)
{
char name[40];
struct address *info;
printf("Введите имя: ");
gets(name);
info = find(name);
if(!info) printf("Не найдено\n");
else display(info);
}
/* Сохранить список в дисковом файле. */
void save(void)
{
struct address *info;
FILE *fp;
fp = fopen("mlist", "wb");
if(!fp) {
printf("Невозможно открыть файл.\n");
exit(1);
}
printf("\nСохранение в файл\n");
info = start;
while(info) {
fwrite(info, sizeof(struct address), 1, fp);
info = info->next; /* перейти к следующему адресу */
}
fclose(fp);
}
/* Загрузка адресов из файла. */
void load()
{
struct address *info;
FILE *fp;
fp = fopen("mlist", "rb");
if(!fp) {
printf("Невозможно открыть файл.\n");
exit(1);
}
/* освободить память, если в памяти уже есть список */
while(start) {
info = start->next;
free(info);
start = info;
}
/* сбросить указатели на начало и конец */
start = last = NULL;
printf("\nЗагрузка из файла\n");
while(!feof(fp)) {
info = (struct address *) malloc(sizeof(struct address));
if(!info) {
printf("Нет свободной памяти");
return;
}
if(1 != fread(info, sizeof(struct address), 1, fp)) break;
dls_store(info, &start, &last);
}
fclose(fp);
}
Исследование, описанное в статье про список , подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое список , односвязные списки, связанные списки, двусвязные списки, односвязный список, связанный список, двусвязный список и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных

Комментарии