Лекция
Привет, Вы узнаете о том , что такое дерево, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое дерево, дерево b+ , настоятельно рекомендую прочитать все из категории Структуры данных.
2-3 дерево (англ. 2-3 tree) — структура данных, представляющая собой сбалансированное дерево поиска, такое что из каждого узла может выходить две или три ветви и глубина всех листьев одинакова. Является частным случаем B+ дерева.
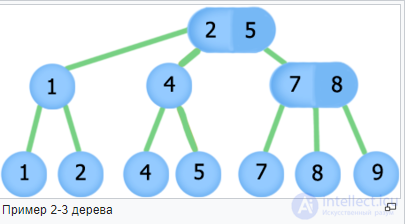
2-3 дерево — сбалансированное дерево поиска, обладающее следующими свойствами:
Узел имеющий 2 сына называется двухместным. Узел имеющий три сына называется трехместным.
Высота 2-3 дерева, содержащего n узлов, не может быть больше [log(n+1) - 1] (целая часть).
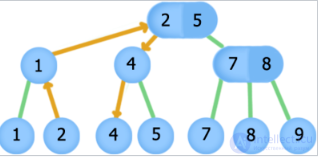
2-3 дерево поиска.
Ключи размещаются в соответствии со следующими правилами:
1 Двухместный внутренний узел имеет двух сыновей. Ключ двухместного узла должен быть больше, чем ключи левого поддерева и меньше, чем ключи правого поддерева.
2 Трехместный узел имеет трех сыновей. Должен содержать два элемента данных. Ключ S больше TL, но меньше TM, а ключ L больше, чем TM, но меньше TR.

3 Лист может содержать один или два элемента данных.
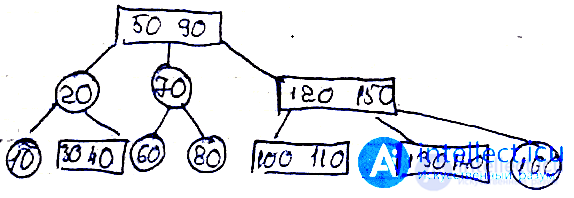
Введем следующие обозначения:
Каждый узел дерева обладает полями:
Изначально t=root. Будем просматривать ключи в узлах, пока узел не является листом. Рассмотрим два случая:
T search(T x):
Node t = root
while (t не является листом)
if (t.length == 2)
if (t.keys < x)
t = t.sons
else
t = t.sons
else if (t.keys < x)
t = t.sons
else if (t.keys < x)
t = t.sons
else
t = t.sons
return t.keys
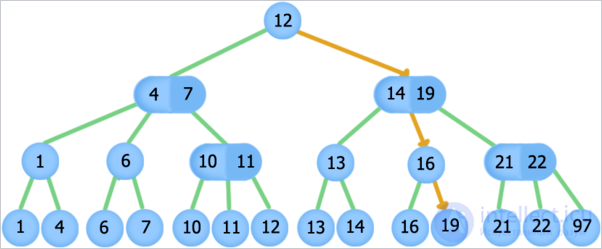
Поиск элемента 19, оранжевые стрелки обозначают путь по дереву при поиске
Если корня не существует — дерево пустое, то новый элемент и будет корнем (одновременно и листом). Иначе поступим следующим образом:
Найдем сперва, где бы находился элемент, применив search(x) Далее проверим есть ли у этого узла родитель, если его нет, то в дереве всего один элемент — лист. Возьмем этот лист и новый узел, и создадим для них родителя, лист и новый узел расположим в порядке возрастания.
Если родитель существует, то подвесим к нему еще одного сына. Если сыновей стало 4, то разделим родителя на два узла, и повторим разделение теперь для его родителя, ведь у него тоже могло быть уже 3 сына, а мы разделили и у него стало на 1 сына больше. (перед разделением обновим ключи).
function splitParent(Node t):
if (t.length > 3)
Node a = Node(sons = {t.sons , t.sons }, keys = {t.keys }, parent = t.parent, length = 2)
t.sons .parent = a
t.sons .parent = a
t.length = 2
t.sons = null
t.sons = null
if (t.parent != null)
t.parent[t.length] = a
t.length++
сортируем сыновей у t.parent
splitParent(t.parent)
else // мы расщепили корень, надо подвесить его к общему родителю, который будет новым корнем
Node t = root
root.sons = t
root.sons = a
t.parent = root
a.parent = root
root.length = 2
сортируем сыновей у root
Если сыновей стало 33, то ничего не делаем. Далее необходимо восстановить ключи на пути от новой вершины до корня:
function updateKeys(Node t):
Node a = t.parent
while (a != null)
for i = 0 .. a.length - 1
a.keys[i] = max(a.sons[i]) // max — возвращает максимальное значение в поддереве.
a = a.parent // Примечание: max легко находить, если хранить максимум
// правого поддерева в каждом узле — это значение и будет max(a.sons[i])
updateKeysupdateKeys необходимо запускать от нового узла. Добавление элемента:
function insert(T x):
Node n = Node(x)
if (root == null)
root = n
return
Node a = searchNode(x)
if (a.parent == null)
Node t = root
root.sons = t
root.sons = n
t.parent = root
n.parent = root
root.length = 2
сортируем сыновей у root
else
Node p = a.parent
p.sons[p.length] = n
p.length++
n.parent = p
сортируем сыновей у p
updateKeys(n)
split(n)
updateKeys(n)
Так как мы спускаемся один раз, и поднимаемся вверх при расщеплении родителей не более одного раза, то insertinsert работает за O(logn)O(logn).
Примеры добавления:
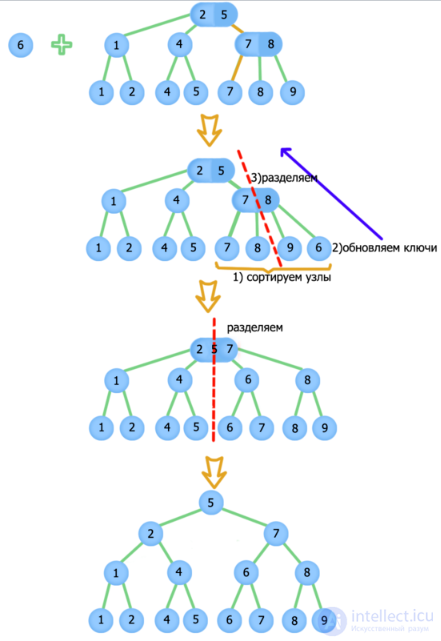
Добавление элемента с ключом 6
Пусть изначально t=searchNode(x) — узел, где находится xx.
Если у tt не существует родителя, то это корень (одновременно и единственный элемент в дереве). Удалим его.
Если pp существует, и у него строго больше 2 сыновей, то просто удалим t, а у p уменьшим количество детей.
Если у родителя tt два сына, рассмотрим возможные случаи (сперва везде удаляем t):
Обобщим алгоритм при удалении когда у родителя tt два сына:
В результате мы получаем корректное по структуре 2-3 дерево, но у нас есть нарушение в ключах в узлах, исправим их с помощью updateKeys() , запустившись от b.

Удаление элемента с ключом 2
В силу того, что наши узлы отсортированы по максимуму в поддереве, то следующий объект — это соседний лист справа. Попасть туда можно следующим образом: будем подниматься вверх, пока у нас не появится первой возможности свернуть направо вниз. Как только мы свернули направо вниз, будем идти всегда влево. Таким образом, мы окажемся в соседнем листе. Если мы не смогли ни разу свернуть направо вниз, и пришли в корень, то следующего объекта не существует. Случай с предыдущим симметричен.
T next(T x):
Node t = searchNode(x)
if (t.keys > x) //x не было в дереве, и мы нашли следующий сразу
return t.keys
while (t != null)
t = t.parent
if (можно свернуть направо вниз)
в t помещаем вершину, в которую свернули
while (пока t — не лист)
t = t.sons
return t
return t.keys
Путь при поиске следующего элемента после 2
B+ деревья, поддерживают операцию findfind, которая позволяет находить m следующих элементов. Наивная реализация выглядит следующим образом: будем вызывать mm раз поиск следующего элемента, такое решение работает за O(mlogn) . Но 2-3 деревья, позволяют находить m следующих элементов за O(m+logn) , что значительно ускоряет поиск при больших m. По построению, все листья у нас отсортированы в порядке возрастания, воспользуемся этим для нахождения m элементов. Нам необходимо связать листья, для этого модифицируем insert и delete Добавим к узлам следующие поля:
Пусть tt — добавленный узел. Изменим insert следующим образом: в самом конце, после того как мы уже обновили все ключи, найдем next(t) и запишем ссылку на него в t.rightt.right. Аналогично с левым.
Пусть t — удаляемый узел. Изменим delete следующим образом: в самом начале, до удаления tt, найдем следующий nextnext и запишем в next.left правый лист относительно t. С левым поступим аналогично.
В итоге, мы имеем двусвязный список в листьях, и чтобы нам вывести mm элементов, нам достаточно один раз найти нужный элемент и пробежаться вправо на mm элементов.

Анализ данных, представленных в статье про дерево, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое дерево, дерево b+ и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных
Комментарии
Оставить комментарий
Структуры данных
Термины: Структуры данных