Лекция
Привет, сегодня поговорим про от структуры данных к алгоритму, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое от структуры данных к алгоритму , настоятельно рекомендую прочитать все из категории Структуры данных.
" Таблица Умножения Достойна Уважения " C.Я. Маршак
" Покажите мне блок-схемы, не показывая таблиц, и я останусь в заблуждении. Покажите мне ваши таблицы, и блок-схемы, скорее всего, не понадобятся: они будут очевидны. "
Фредерик Брукс
Вновь обратимся к нашему модельному объекту - таблице умножения. Очевидно, что стандартные размеры этой структуры - 10×10 - продиктованы используемой системой счисления. Переход к другому основанию, скажем, к 16-теричной системе, потребует, во-первых, расширения таблицы в двух направлениях, во-вторых, инициализации новых элементов (разумеется, если воспользоваться старой таблицей).
Возникает проблема распределения места в памяти под структуру. Ну как, спрашивается, добавить 6 строк к таблице на рис. A4-3 Если текст на бумаге, то, как говорится, "написанное пером...". То же самое можно сказать и о структуре данных в программе, если описанием заданы фиксированные размеры. Вывод таков: перспективу расширения жизненного пространства для программы планировать надо заранее, на этапе конструирования алгоритма. Не зря печальный опыт истории свидетельствует, что большинство войн начиналось по причине территориальных споров.

К счастью, алгоритмика и, вслед за нею, архитектура компьютера предусматривают возможность увеличивать/уменьшать размеры определенных структур в период run-time цикла их жизни. Стpуктуpы данных, которые допускают подобные манипуляции, называют динамическими, противопоставляя их неизменяемым, - разумеется, только по размерам, а не содержанию, -статическим структурам. В постановке задачи не обязательно наличие прямого указания, какой тип структуры предпочтителен, и выбор остается за алгоритмистом.
Упражнение 1 Если читателю не пришлось до сих пор сталкиваться с динамическими структурами в своей программистской практике, то желательно этот пробел ликвидировать и познакомиться с соответствующими конструкциями языка программирования.
Иногда случается в книгах по информатике прочесть о вставке элементов в статическую таблицу, но принимать это за чистую монету не стоит. Речь идет либо о замещении значений элементов в заполненных позициях таблицы, либо об инициализации позиций незаполненных.
Так, предвидя обращение к задаче "15×26", вместо обычной таблицы умножения можно заранее выделить место под таблицу, соответствующую алгоритму A4-4 (рис. A4-4), а инициализацию провести только для стандартного размера, то есть левого верхнего угла 10×10. В этой ситуации размеры заранее установлены "с запасом", и остается инициализировать остальную часть. Более трудоемким грозит стать процесс "вставки" строки между ранее размещенными. Он потребует перемещения ряда строк вниз, что означает, собственно говоря, просто переписывание элементов в новые позиции, и лишь затем - инициализацию элементов "вставляемой" строки. Что собой представляет, в том же контексте, "удаление" элементов статической структуры, читатель легко догадается сам.
Совершенно иначе, и гораздо эффективней, работают алгоритмы вставки и алгоритмы удаления для динамических структур. Их обсуждению посвящена часть Главы D, и ею дело не ограничится.
Упражнение 2
Какова трудоемкость "удаления" k нижних строк при статическом размещении таблицы умножения m×n?
А теперь представим снова таблицу умножения стандартных размеров, но нестандартного содержания. Скажем, мы "рассыпали" строки обычной таблицы, а потом "собрали" их в случайном порядке.
Как, технически, инициализировать случайный порядок строк, - в нашем случае, натуральных чисел от 1 до 9? Языки программирования, как правило, предоставляют встроенные средства для этого, вроде известной читателю функции Random. Можно назвать немало задач, решение которых основано на использовании последовательностей случайных чисел, например, некоторые проблемы криптографии, где возможность (или невозможность) воспроизвести последовательность, которая использовалась при шифровании сообщения, стоит в центре внимания алгоритмиста. Другой пример описан в следующем упражнении.
В Уроке A3 вы уже познакомились с приближенными методами вычисления интеграла. Идею метода Монте-Карло, конкурирующего с описанными там механизмами, сейчас проиллюстрируем тем же примером вычисления площади Sfigureфигуры, ограниченной сверху - графиком конечной, непрерывной и неотрицательной функции f(x), снизу - конечным интервалом оси абсцисс [a, b], по бокам - ординатами на концах интервала (рис. A5-1). Интересующую нас фигуру можно целиком поместить внутрь прямоугольника, чья площадь ограничена тем же интервалом, теми же ординатами и некоторым значением y0, мажорирующим заданную функцию. Теперь будем поочередно запускать "достаточно большое число раз" (N) датчики случайных чисел для генерации точек с координатами из интервала [a, b] и интервала [0, y0]. Соответственно, можно следить за тем, сколько точек (Ninside) "попали" внутрь фигуры, и сколько остались за ее пределами, но, естественно, внутри прямоугольника. По завершении эксперимента, чем больше N и "качественнее" датчик, тем ближе к равенству приближенное соотношение Ninside/N≈ Sfigure/Srectangle. Об этом говорит сайт https://intellect.icu . Читателю предлагается написать соответствующую программу и протестировать ее для "табличных" функций, сравнивая результаты со значениями, вычисленными по таблице интегралов. Также представляет интерес сравнительный анализ результатов вычисления по методу Монте-Карло и методами прямоугольников (трапеций и подобными) (рис. A5-1).
Упражнение 3
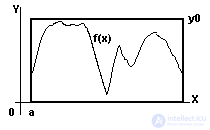
Рис. 1
Итак, возможность быстрого получения чисел, составляющих некоторую случайную (правильнее говорить: псевдослучайную) последовательность, вполне актуальна. Обычно подобные наборы не хранятся в системе программирования, - тем более, в операционной системе, - и, при необходимости, прибегают к специальным алгоритмам генерации случайных чисел. Пример построения такого набора мы включили в следующее упражнение.
Упражнение 4 Выбирается произвольное двузначное число и назначается первым элементом n1 последовательности псевдослучайных чисел, а затем каждый очередной элемент ni+1 получается из предыдущего элемента ni. Для этого ni возводится в квадрат, и из полученного четырехзначного результата отбрасываются левая и правая цифры. Например: ni=25⇒ni=0625⇒ ni+1=62. Поскольку различных чисел в такой последовательности конечное число, то, рано или поздно, она начнет самовоспроизводиться начиная с некоторого места. Поэтому алгоритм генерирует именно псевдослучайные числа. Напишите программу, генерирующую такую последовательность по заданному входному значению n1. Найдите место первого повтора ранее полученного элемента.
Вернемся к задаче об "испорченной" таблице умножения. Предположим для определенности, что вариант хранения данных оказался таким, как представленный на рис. A5-2. Учтите, что столбцы, согласно условию, "не пострадали". Как искать произведение 5×6 в "испорченной" таблице (рис. A5-2)?
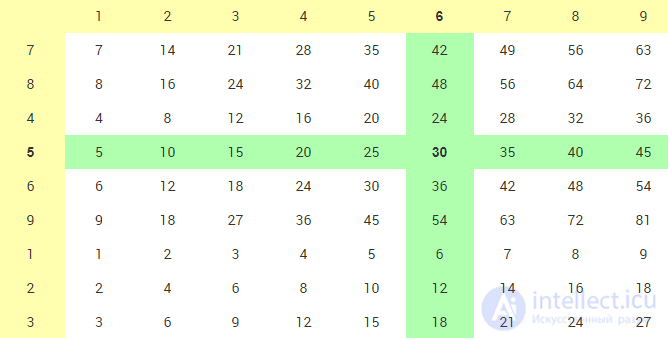
Рис. 2
Обратиться - по индексу - непосредственно к нужной нам строке, бывшей 5-й, нельзя, поскольку она могла переместиться. Приходится перебирать строки последовательно, проще всего - сверху вниз. Отличить искомую строку от остальных позволяет ее ключ, расположенный в левом столбце. Сопоставив значение ключа с первым из сомножителей, только при их совпадении можно далее двигаться вправо по найденной строке. Если же перетасовать и столбцы, то задача рискует стать неразрешимой.
Упражнение 5
Системные оболочки Norton Commander, Far, Windows Commander предоставляют возможность, в зависимости от цели использования, менять порядок расположения имен каталогов и файлов в панелях Left и Right, выводимых ими на экран. Информация на эти панели попадает из соответствующих каталогов операционной системы. Вспомните (или выясните), как организованы каталоги, из каких записей состоят, какие поля играют роль ключей.
Что произойдет, если из второй, "испорченной" таблицы изъять столбец и строку с ключами, как на рис. A5-3? Сохранится ли возможность поиска все того же произведения 5×6?
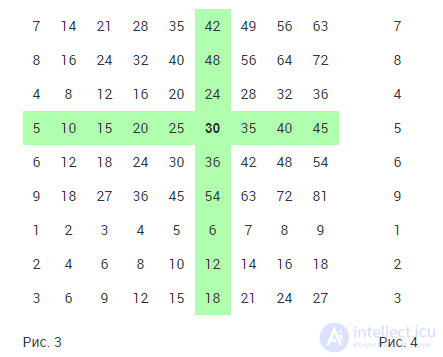
Да, и более того - можно продолжить эксперименты с таблицей, и "испортить" ее настолько, что в ней вообще останется только первый столбец (рис. A5-4), но при этом возможность полного ее восстановления сохранится. Это так, поскольку соседние элементы внутри каждой строки представляют нарастающие суммы повторяющегося слагаемого (вспомните алгоритм A4-1 и рис. A4-1), причем у каждой строки ее собственное слагаемое содержится в ней - в качестве первого элемента.
Иначе говоря, мы имеем дело с зависимостью si,j+1=si,j+si,1, где i - номер строки на рис. A5-3 и A5-4, j - номер столбца на рис. A5-3, si,j - элемент таблицы на пересечении i-й строки и j-го столбца. Соотношения подобного вида принято называтьрекуррентными. Применение они находят в разнообразных задачах, в том числе, связанных с обработкой таблиц. Методы и задачи, возникающие в этой связи, относят к т.н. динамическому программированию. Им посвящена Глава G.
Альтернативой методам динамического программирования, основанным на использовании таблиц в явном виде, является применение рекурсивных механизмов. Об использовании рекурсии в ряде задач и необходимой для этого механизма структуре данных - стеке - речь пойдет в Главе J.
И вновь возвращаемся к обычному виду таблицы умножения. Вполне естественной выглядит обратная задача, связанная с установлением "адреса" в ней по заданному значению элемента: "для натурального числа n выяснить, на пересечении каких строки и столбца оно записано". Кстати, если элемента нет в таблице, то адрес так и не найдется.
Приходит на ум аналогия из некомпьютерной тематики, связанная с установлением хозяина ключей, найденных вблизи многоквартирного дома. Скорее всего, поиск квартиры и владельца придется вести последовательно: от подъезда (столбца таблицы) к подъезду, и внутри очередного подъезда - по этажам (строкам). Если дом велик, то процесс, трудоемкость которого сопоставима с количеством квартир, может затянуться, и энтузиазм иссякнет.
К счастью, для решения нашей задачи можно предложить более экономичные алгоритмы, а именно: разлагать входное значение на всевозможные пары сомножителей и проверять их. Так, для n = 30 найдется несколько пар-претендентов: (1, 30), (2, 15), (3, 10),(5, 6), (6, 5), (10, 3), (15, 2) и (30, 1). Сразу отсеиваются пары, включающие числа, большие 9. Соответственно, остаются только (5, 6)и (6, 5). Иначе говоря, вместо алгоритма поиска используется некоторый вычислительный механизм.
В данном примере, когда разрешенный диапазон ограничен узкими рамками нашей таблицы, задача элементарно решается "в уме". Но с ростом n проблема усложняется и желательно прибегнуть к какому-нибудь эффективному механизму. Частично нас выручит - вероятно, знакомый вам - алгоритм Евклида. Ему и некоторым сопутствующим примерам уделено внимание в Главе C.
Попутно воспользуемся ситуацией и вновь напомним читателю о "нехороших" задачах, для решения которых алгоритмы полиномиальной сложности не найдены. Такова, к сожалению, и задача разложения натурального числа на простые множители. Впрочем, может быть, и "к счастью", вопрос - как посмотреть. Задачи подобной тематики находят приложение в криптографии, и, с точки зрения владельца секретного кода - это хорошо, шпион же думает иначе.
В наших рассуждениях мы уже несколько раз меняли структуру данных, предназначенную для представления таблиц умножения. Чаще всего это диктовалось желанием уменьшить емкостную сложность алгоритма, выделив меньше места для хранения данных. Если при этом ставить целью не терять данные, - именно так стоял вопрос при переходе от представления нарис. A5-3 к рис. A5-4, - то возможным подходом будет установление взаимно однозначного (поэлементного) соответствия между различными представлениями. Тогда от одной структуры к другой мы можем переходить без ущерба для содержимого набора данных. Примерно по такой схеме осуществляется квартирный обмен.
Удобно, если переход от одной структуры к другой удается описать одной формулой. Но часто подобные преобразования реализуются многошаговым алгоритмом. Следовательно, при замене "структуры пользователя" на структуру данных в программе для ЭВМ, следует учесть накладные расходы - машинное время - на реализацию алгоритма преобразования. Заметим, что временнАя сложность такого преобразования в одну сторону может заметно отличаться при обратном преобразовании.
Мы уже убедились, что место, занимаемое таблицей умножения избыточно, и вполне можно экономить его, используя альтернативные структуры. Вот еще одна из возможностей, реализуемая многошаговым алгоритмом:
Таблица симметрична относительно главной диагонали (диагонали, идущей из верхнего левого угла к правому нижнему). Следовательно, можно без ущерба для содержимого отказаться от выделения места под левый нижний треугольник исходной квадратной матрицы.
Затем, строка за строкой, перепишем то, что осталось, в линейный массив. Отличие нового представления от обычного хранения двумерного массива в оперативной памяти определяется тем, что усеченные строки имеют разную длину.
Таким образом, мы осуществили упаковку исходной таблицы в линейный массив, уменьшив емкостную сложность примерно вдвое.
Упражнение 6 Постройте формулу для прямой адресации к элементу упакованного представления таблицы по заданному адресу исходного представления, то есть по паре (номер_строки, номер_столбца).
Упражнение 7 Постройте формулу для обратной адресации.
Задача 1. Таблица умножения (Отправить)
| Имя входного файла | input.txt |
| Имя выходного файла | output.txt |
| Максимальное время работы на одном тесте | 2 секунды |
Напишите программу, которая по заданному на входе размеру N умножения N×N выводит содержимое упакованной в линейный массив верхней треугольной матрицы, не формируя промежуточный набор - саму таблицу.
Формат входных данных
Первая строка входного файла содержит единственное число -- N (1<=N<=1000)
Формат выходных данных
Выходной файл должен содержать полученный массив. Числа должны быть разделены пробелами или переводами строк.
| Пример входного файла | Пример выходного файла |
2 |
1 2 4 |
Задача 2. Обратная таблица умножения (Отправить)
| Имя входного файла | input.txt |
| Имя выходного файла | output.txt |
| Максимальное время работы на одном тесте | 2 секунды |
Напишите программу, осуществляющую преобразование, обратное к предыдущей задаче.
Формат входных данных
Первая строка входного файла содержит линейный массив. Числа разделены пробелами и/или переводами строк. Количество чисел не превосходит 1000.
Формат выходных данных
Выходной файл должен содержать полученное число.
| Пример входного файла | Пример выходного файла |
1 2 4 |
2 |
Возможность упаковки, к которой мы прибегли в рассмотренных случаях, определялась тем, что данные в таблице подчинены приведенному выше рекуррентному соотношению. Провести подобные манипуляции с таблицей, которую мы использовали для "изучения английских числительных" (Урок A4) будет трудно, если выделять для названий ровно столько места, сколько занимает каждая символьная строка, не выравнивая их представления по длине. Однако проблема разрешима, если применить для упаковки строк один из известных алгоритмов сжатия текста.
Более широкая постановка задачи кодирования и сжатия данных представлена в Главе N. В частности, нам предстоит рассмотреть разнообразные коды: постоянной длины и переменной длины, и, в связи с последними, целое семейство алгоритмов Хаффмена.
Сразу обращаем внимание искушенного читателя, что мы ограничиваемся в нашем курсе алгоритмами сжатия без потерь и искать в указанной главе описание современных алгоритмов упаковки видео и аудио файлов не стоит. А менее искушенному - поясним, что речь пойдет только о такой упаковке информации, когда обратное преобразование позволяет восстановить "все, как было".
К сожалению, в одной статье не просто дать все знания про от структуры данных к алгоритму. Но я - старался. Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое от структуры данных к алгоритму и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных

Комментарии