Лекция
Привет, Вы узнаете о том , что такое персистентные структуры данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое персистентные структуры данных , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
персистентные структуры данных (англ. persistent data structure) — это структуры данных, которые при внесении в них каких-то изменений сохраняют все свои предыдущие состояния и доступ к этим состояниям.
Есть несколько уровней персистентности:
В частично персистентных структурах данных к каждой версии можно делать запросы, но изменять можно только последнюю версию структуры данных.
В полностью персистентных структурах данных можно менять не только последнюю, но и любую версию структур данных, также к любой версии можно делать запросы.
Конфлюэнтные структуры данных позволяют объединять две структуры данных в одну (деревья поиска, которые можно сливать).
Функциональные структуры данных полностью персистентны по определению, так как в них запрещаются уничтожающие присваивания, т.е. любой переменной значение может быть присвоено только один раз и изменять значения переменных нельзя. Если структура данных функциональна, то она и конфлюэнтна, если конфлюэнтна, то и полностью персистентна, если полностью персистентна, то и частично персистентна. Однако бывают структуры данных не функциональные, но конфлюэнтные.
Есть несколько способов сделать любую структуру персистентной:
Рассмотрим для начала частичную персистентность. Для наглядности занумеруем разные версии структур данных. История изменений структуры данных линейна, в любой момент времени можно обратиться к любой версии структуры данных, но поменять возможно только последнюю версию (на рисунке она выделена синим цветом).

Сформулируем, что такое структура данных. В нашем понимании структурой данных будет называться набор узлов, в которых хранятся какие-то данные, и эти узлы связаны ссылками. Пример структуры данных — дерево. Рассмотрим, как методом копирования пути превратить дерево в персистентное.
Пусть есть сбалансированное дерево поиска. Все операции в нем делаются за 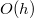 , где
, где 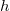 — высота дерева, а высота дерева
— высота дерева, а высота дерева 
 , где
, где 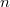 — количество вершин. Пусть необходимо сделать какое-то обновление в этом сбалансированном дереве, например, добавить очередной элемент, но при этом нужно не потерять старое дерево. Возьмем узел, в который нужно добавить нового ребенка. Вместо того чтобы добавлять нового ребенка, скопируем этот узел, к копии добавим нового ребенка, также скопируем все узлы вплоть до корня, из которых достижим первый скопированный узел вместе со всеми указателями. Все вершины, из которых измененный узел не достижим, мы не трогаем. Количество новых узлов всегда будет порядка логарифма. В результате имеем доступ к обоим версиям дерева.
— количество вершин. Пусть необходимо сделать какое-то обновление в этом сбалансированном дереве, например, добавить очередной элемент, но при этом нужно не потерять старое дерево. Возьмем узел, в который нужно добавить нового ребенка. Вместо того чтобы добавлять нового ребенка, скопируем этот узел, к копии добавим нового ребенка, также скопируем все узлы вплоть до корня, из которых достижим первый скопированный узел вместе со всеми указателями. Все вершины, из которых измененный узел не достижим, мы не трогаем. Количество новых узлов всегда будет порядка логарифма. В результате имеем доступ к обоим версиям дерева.
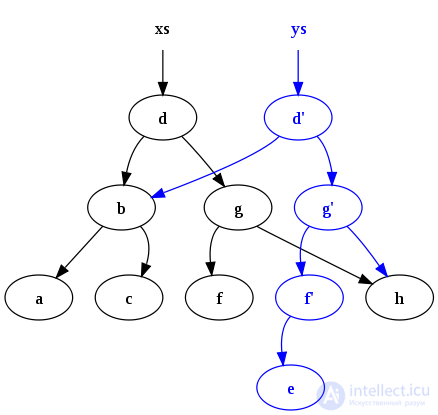
Так как рассматривается сбалансированное дерево поиска, то поднимая вершину вверх при балансировке, нужно делать копии всех вершин, участвующих во вращениях, у которых изменились ссылки на детей. Таких всегда не более трех, поэтому ассимптотика  не пострадает. Когда балансировка закончится, нужно дойти вверх до корня, делая копии вершин на пути.
не пострадает. Когда балансировка закончится, нужно дойти вверх до корня, делая копии вершин на пути.
Этот метод хорошо работает на стеке, двоичных (декартовых, красно-черных) деревьях. Но в случае преобразования очереди в персистентную операция добавления будет очень дорогой, так как элемент добавляется в хвост очереди, который достижим из всех остальных элементов. Также не выгодно применять этот метод и в случае, когда в структуре данных имеются ссылки на родителя.
Реализация на основе дерева отрезков
На основе дерева отрезков можно построить полностью персистентную структуру данных.
Для реализации персистентного дерева отрезков удобно несколько изменить структуру дерева. Для этого будем использовать явные указатели  и
и 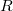 для дочерних элементов. Кроме того, заведем массив
для дочерних элементов. Кроме того, заведем массив  , в котором
, в котором  указывает на корень дерева отрезков версии
указывает на корень дерева отрезков версии 
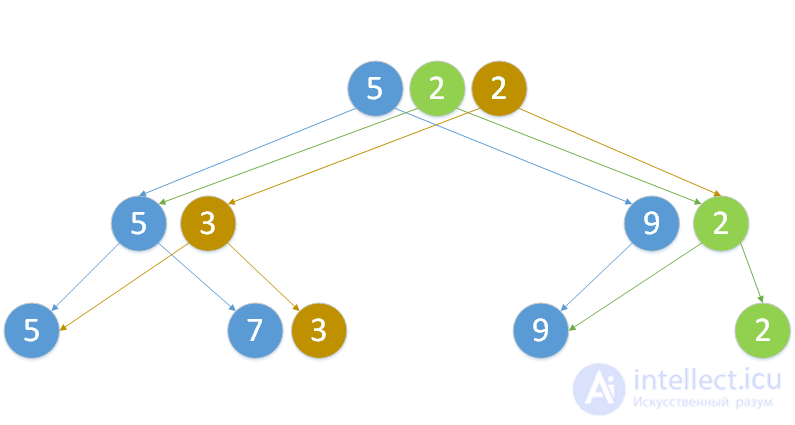
Для построения персистентного дерева отрезков из элементов необходимо применить раз операцию добавления элемента к последней версии дерева. Для того, чтобы добавить новый элемент к  -ой версии дерева, необходимо проверить, является ли оно полным бинарным. Если да, то создадим новый корень, левым сыном сделаем
-ой версии дерева, необходимо проверить, является ли оно полным бинарным. Если да, то создадим новый корень, левым сыном сделаем 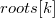 . Иначе, сделаем копию корня исходной версии. Добавим корень в конец массива корней. Далее, спускаясь от корня к первому свободному листу, будем создавать несуществующие узлы и клонировать существующие. После этого в новой ветке необходимо обновить значение функции и некоторые указатели дочерних элементов. Поэтому, возвращаясь из рекурсии, будем менять один указатель на только что созданную или скопированную вершину, а также обновим значение функции, для которой строилось дерево. После этой операции в дереве появится новая версия, содержащая вставленный элемент.
. Иначе, сделаем копию корня исходной версии. Добавим корень в конец массива корней. Далее, спускаясь от корня к первому свободному листу, будем создавать несуществующие узлы и клонировать существующие. После этого в новой ветке необходимо обновить значение функции и некоторые указатели дочерних элементов. Поэтому, возвращаясь из рекурсии, будем менять один указатель на только что созданную или скопированную вершину, а также обновим значение функции, для которой строилось дерево. После этой операции в дереве появится новая версия, содержащая вставленный элемент.
Для того, чтобы изменить элемент в персистентном дереве отрезков, необходимо сделать следующие действия: спустимся в дереве от корня нужной версии до требуемого элемента, скопируем его, изменим значение, и, поднимаясь по дереву, будем клонировать узлы. При этом необходимо менять указатель на одного из детей на узел, созданный при предыдущем клонировании. После копирования корня, добавим новый корень в конец массива корней.
Здесь изображено персистентное дерево отрезков с операцией минимум, в котором изначально было 3 вершины. Сперва к нему была добавлена вершина со значением 2, а потом изменена вершина со значением 7. Цвет ребер и вершин соответствует времени их появления. Синий цвет элементов означает, что они были изначально, зеленый - что они появились после добавления, а оранжевый - что они появились после изменения элемента.
Пусть в структуре данных есть узел, в котором нужно сделать изменения (например, на рисунке ниже в первой версии структуры данных в узле  есть поле
есть поле  , а во второй версии это поле должно быть равно
, а во второй версии это поле должно быть равно  ), но при этом нужно сохранить доступ к старой версии узла и не нужно экономить время. Об этом говорит сайт https://intellect.icu . В таком случае можно хранить обе версии узла в большом комбинированном узле.
), но при этом нужно сохранить доступ к старой версии узла и не нужно экономить время. Об этом говорит сайт https://intellect.icu . В таком случае можно хранить обе версии узла в большом комбинированном узле.

В примере выше в этом «толстом» узле будет храниться первая версия  , у которой и вторая версия
, у которой и вторая версия  , у которой
, у которой  . Если далее последуют еще какие-то изменения (например, поле
. Если далее последуют еще какие-то изменения (например, поле 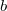 узла станет равно
узла станет равно  ) добавим в толстый узел еще одну версию —
) добавим в толстый узел еще одну версию —  .
.

Пусть нужно сделать запрос ко второй версии структуры данных (на рисунке выше это запрос  . Чтобы сделать этот запрос, нужно зайти в узел и найти в списке версий максимальную версию, которая меньше или равна версии запроса (в примере на рисунке это версия
. Чтобы сделать этот запрос, нужно зайти в узел и найти в списке версий максимальную версию, которая меньше или равна версии запроса (в примере на рисунке это версия  ), и в этой версии узла найти значение поля
), и в этой версии узла найти значение поля  (в примере ). Чтобы быстро найти нужную версию в списке версий, хранящихся в «толстом» узле, нужно хранить их в виде дерева. Тогда мы сможем за логарифм найти нужную версию и к ней обратиться. Значит, все операции, которые будут производиться на этой структуре данных, будут домножаться на логарифм от числа версий.
(в примере ). Чтобы быстро найти нужную версию в списке версий, хранящихся в «толстом» узле, нужно хранить их в виде дерева. Тогда мы сможем за логарифм найти нужную версию и к ней обратиться. Значит, все операции, которые будут производиться на этой структуре данных, будут домножаться на логарифм от числа версий.
Структура толстого узла может быть и другой: к каждой вершине можно хранить лог ее изменений, в который записывается версия, в которой произошло изменение, а также само изменение. Такая структура толстого узла рассмотрена ниже, в разделах об общих методах получения частично и полностью персистентных структур данных. Лог может быть организован по-разному. Обычно делают отдельный лог для каждого поля вершины. Когда что-то меняется в вершине, то в лог соответствующего поля записывается это изменение и номер версии, с которой данное изменение произошло. Когда нужно обратиться к старой версии, то двоичным поиском ищут в логе последнее изменение до этой версии и находят нужное значение. Метод fat node дает замедление  , где
, где  — число изменений структуры данных; памяти требуется
— число изменений структуры данных; памяти требуется  , где — число вершин в структуре данных.
, где — число вершин в структуре данных.
Если скомбинировать методы path copiyng и fat node, то получим универсальный метод, который позволит преобразовывать структуры данных в частично персистентные без дополнительного логарифма памяти и времени. Пусть мы имеем двусвязный список и хотим внести в него какое-то изменение, например, добавить узел  между узлами и
между узлами и  , то есть при переходе из версии
, то есть при переходе из версии  в версию добавим в двусвязный список узел . Применим метод «толстых» узлов. Для этого в узлы и добавим вторую версию и изменим ссылку, следующую из , и предыдущую перед , как показано на рисунке. Этот алгоритм работает следующим образом. Например, текущая первая версия. Идем по списку слева направо от первого узла к узлу , а затем нужно перейти к следующему узлу. В «толстом» узле выбираем нужную (первую) версию и далее следуем по ссылкам.
в версию добавим в двусвязный список узел . Применим метод «толстых» узлов. Для этого в узлы и добавим вторую версию и изменим ссылку, следующую из , и предыдущую перед , как показано на рисунке. Этот алгоритм работает следующим образом. Например, текущая первая версия. Идем по списку слева направо от первого узла к узлу , а затем нужно перейти к следующему узлу. В «толстом» узле выбираем нужную (первую) версию и далее следуем по ссылкам.

Пусть мы хотим добавить еще один элемент между узлами и , но проблема в том, что у и уже есть вторая версия, если будем добавлять еще новые версии, то получим дополнительный логарифм времени при обращении к узлу, как в рассмотренном выше методе "толстых" узлов. Поэтому более двух версий добавлять не будем. Используем метод копирования пути. Скопируем узлы и , начиная с их третьей версии, и свяжем новые узлы с исходным списком. Для этого добавим вторые версии предыдущему перед и последующему после узлам и свяжем эти узлы соответствующими ссылками. Так все версии остаются доступными.

Будем называть узел полным, если у него есть вторая версия. Если мы хотим вставить новый элемент в середину списка (на рисунке ниже он обозначен зеленым цветом), мы должны склонировать все полные узлы слева и справа от места добавления нового узла, дойти до ближайших элементов, у которых нет второй версии и добавить им вторую версию.

Оценим амортизационное время работы такого алгоритма. У нас частично персистентная структура данных, изменять можно только ее последнюю версию. Примем функцию потенциала  равной числу полных узлов в последней версии.
равной числу полных узлов в последней версии.
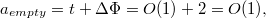 так как если добавление узла не задевает полных узлов, то узел добавляется за константное время, а количество полных узлов увеличивается на .
так как если добавление узла не задевает полных узлов, то узел добавляется за константное время, а количество полных узлов увеличивается на . так как если узел влечет изменения полных узлов, то сначала потратится времени на копирование этих полных узлов, и в то же время потенциал уменьшится на , а потом увеличится максимум на .
так как если узел влечет изменения полных узлов, то сначала потратится времени на копирование этих полных узлов, и в то же время потенциал уменьшится на , а потом увеличится максимум на . так как полных узлов не больше общего количества узлов в списке.
так как полных узлов не больше общего количества узлов в списке.Таким образом, по теореме о методе потенциалов, амортизационное время работы по добавлению элемента будет 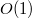 .
.

Пунктирные линии — обратные ссылки,
— исходный узел, актуальный до версии  ,
,
 — склонированный узел, актуальный с версии
— склонированный узел, актуальный с версии 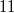 , с пустым списком изменений
, с пустым списком изменений
Применим методы, описанные выше, в общем случае для абстрактной структуры данных.
Пусть есть структура данных, у каждого узла которой количество указателей на этот узел не больше некоторой константы 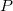 . При клонировании узла важно знать, откуда на этот узел идут указатели, чтобы затем их переставить. Поэтому необходимо в каждом узле хранить обратные ссылки на те узлы, которые ссылаются на клонируемый узел. Все узлы будут храниться в виде «толстых» узлов, в которых содержится начальная версия этого узла и список внесенных в него изменений (англ. change log) длиной не больше
. При клонировании узла важно знать, откуда на этот узел идут указатели, чтобы затем их переставить. Поэтому необходимо в каждом узле хранить обратные ссылки на те узлы, которые ссылаются на клонируемый узел. Все узлы будут храниться в виде «толстых» узлов, в которых содержится начальная версия этого узла и список внесенных в него изменений (англ. change log) длиной не больше  .
.
Пусть нужно внести изменение в структуру данных в узел . Если есть место в списке изменений, просто вносим туда изменение: записываем номер версии, с которой начинается это изменение, в какое поле узла вносится изменение и какое именно. Если change log заполнен, то клонируем узел : берем стартовую версию узла, производим в ней все изменения, записанные в change log, добавляем последнее изменение и делаем версию со свободным списком изменений. Затем пройдем по обратным ссылкам от и в change log каждого узла, ссылающегося на , добавим изменение указателя начиная с этой версии структуры данных с на .
Оценим время работы этого алгоритма. Введем функцию потенциала, которая будет равна суммарному размеру всех списков изменений в последней версии. Посмотрим, как меняется суммарный размер списков изменений, когда мы совершаем одно изменение. Если change log был не полный, то мы просто добавляем туда один элемент, потенциал увеличится на единицу. Если change log был полный, то потенциал уменьшается на его размер, так как мы склонировали узел с пустым списком изменений. После этого мы пошли по обратным ссылкам (их было штук) и добавили в узлов по одному значению. Таким образом амортизированное время работы будет .
Для полностью персистентных структур данных применить описанный выше метод преобразования не получится, так как история создания версий не линейна и нельзя отсортировать изменения по версиям, как в частично персистентных структурах данных. Пусть мы храним историю изменения версий в виде дерева. Сделаем обход этого дерева в глубину. В порядке этого обхода запишем, когда мы входим, а когда выходим из каждой версии. Эта последовательность действий полностью задает дерево, сделаем из нее список. Когда после какой-то версии (на рисунке ниже это версия  ) добавляется новая версия структуры данных (на рисунке версия
) добавляется новая версия структуры данных (на рисунке версия  ), мы вставляем два элемента в список (на рисунке это
), мы вставляем два элемента в список (на рисунке это 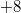 и
и  ) после входа, но до выхода из той версии, когда произошло изменение (то есть между элементами
) после входа, но до выхода из той версии, когда произошло изменение (то есть между элементами 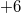 и
и  ). Первый элемент вносит изменение, а второй будет возвращать обратно значение предыдущей версии. Таким образом, каждая операция разбивается на две: первая делает изменение, а вторая его откатывает.
). Первый элемент вносит изменение, а второй будет возвращать обратно значение предыдущей версии. Таким образом, каждая операция разбивается на две: первая делает изменение, а вторая его откатывает.

Для реализации описанного в предыдущем пункте метода преобразования структур данных в полностью персистентные нам нужен такой список, который поддерживает операции 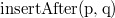 (вставить
(вставить  после
после  ) и
) и 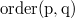 (должен уметь отвечать на запросы вида " лежит в этом списке до "). возвращает , если лежит до и
(должен уметь отвечать на запросы вида " лежит в этом списке до "). возвращает , если лежит до и  иначе. Это список с поддержкой запроса о порядке List Order Maintenance, который обе эти операции делает за .
иначе. Это список с поддержкой запроса о порядке List Order Maintenance, который обе эти операции делает за .
В change log «толстого» узла теперь будем добавлять два события: одно указывает на изменение, произошедшее в соответствующей версии, а другое на его отмену. События будут добавляться в change log не по номерам версий, а по их порядку в списке версий List Order Maintenance.
Когда есть запрос к какой-то версии, то нужно найти в списке версий такую, после входа в которую, но до выхода из которой лежит версия запроса, а среди таких максимальную. Например, если приходит запрос к версии на рисунке выше, то мы видим, что она в списке версий лежит после входа, но до выхода в версии , и . Необходимо найти наибольшую из них. Список List Order Maintenance позволяет делать это за с помощью операции . В примере это версия . Так как change log каждого узла имеет константный размер, то поиск нужной версии в нем происходит за .
В какой-то момент change log «толстого» узла переполнится. Тогда нужно клонировать этот узел и нижнюю половину изменений перенести в change log склонированного узла. Первую половину изменений применяем к исходной версии узла и сохраняем в качестве исходной в склонированном узле.

Получится два узла: первый отвечает за отрезок версий до операции последнего изменения, а второй — после нее. Дальнейший порядок действий аналогичен тому, который использовался в общем методе построения частично персистентных структур данных.
Оценим амортизационное время работы этого алгоритма. Введем функцию потенциала, равную числу полных узлов. Когда узел раздваивается, функция потенциала уменьшается на единицу, затем мы переставляем ссылок, потенциал увеличивается на , значит, амортизационное время работы — .
Персистентные структуры данных используются при решении геометрических задач. Примером может служить Point location problem — задача о местоположении точки. Задачи такого рода решаются в offline и online. В offline-задачах все запросы даны заранее и можно обрабатывать их одновременно. В online-задачах следующий запрос можно узнать только после того, как найден ответ на предыдущий.
При решении offline-задачи данный планарный граф разбивается на полосы вертикальными прямыми, проходящими через вершины многоугольников. Затем в этих полосах при помощи техники заметающей прямой (scane line) ищется местоположение точки-запроса. При переходе из одной полосы в другую изменяется сбалансированное дерево поиска. Если использовать частично персистентную структуру данных, то для каждой полосы будет своя версия дерева и сохранится возможность делать к ней запросы. Тогда Point location problem может быть решена в online.
Анализ данных, представленных в статье про персистентные структуры данных, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое персистентные структуры данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL

Комментарии