Лекция
Привет, Вы узнаете о том , что такое антипаттерны, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое антипаттерны, антипаттерн , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Использование LIKE против индексированных столбцов, и я почти испытываю желание просто сказать LIKE в целом.
Переработка сгенерированных SQL значений PK.
Использование множества слолбцов в одной бог-таблице. Ничто не говорит «органично», как 100 столбцов битовых флагов, больших строк и целых чисел.
Шаблон «Я скучаю по INI-файлам» : хранение CSV, серриализированных и json строк с разделителями каналов или других необходимых данных для анализа в больших текстовых полях.
А для MS SQL server использование курсоров вообще . Есть лучший способ сделать любую заданную задачу курсора.
Номер 1. Невозможность указать список полей. (Изменить: для предотвращения путаницы: это правило производственного кода. Оно не применяется к одноразовым сценариям анализа - если я не автор.)
SELECT * Insert Into blah SELECT *
должно быть
SELECT fieldlist Insert Into blah (fieldlist) SELECT fieldlist
Номер 2. Использование курсора и цикла while, когда будет использоваться цикл while с переменной цикла.
DECLARE @LoopVar int
SET @LoopVar = (SELECT MIN(TheKey) FROM TheTable)
WHILE @LoopVar is not null
BEGIN
-- Do Stuff with current value of @LoopVar
...
--Ok, done, now get the next value
SET @LoopVar = (SELECT MIN(TheKey) FROM TheTable
WHERE @LoopVar < TheKey)
END
Номер 3. DateLogic через строковые типы.
--Trim the time Convert(Convert(theDate, varchar(10), 121), datetime)
Должно быть
--Trim the time DateAdd(dd, DateDiff(dd, 0, theDate), 0)
Я видел недавний всплеск «Один запрос лучше, чем два, верно?»
SELECT * FROM blah WHERE (blah.Name = @name OR @name is null) AND (blah.Purpose = @Purpose OR @Purpose is null)
Этот запрос требует двух или трех разных планов выполнения в зависимости от значений параметров. Только один план выполнения генерируется и помещается в кеш для этого текста SQL. Этот план будет использоваться независимо от значения параметров. Это приводит к периодической низкой производительности. Гораздо лучше написать два запроса (по одному на каждый план выполнения)
Номер 4 Смешивать свою UI-логику на уровне доступа к данным:
SELECT
FirstName + ' ' + LastName as "Full Name",
case UserRole
when 2 then "Admin"
when 1 then "Moderator"
else "User"
end as "User's Role",
case SignedIn
when 0 then "Logged in"
else "Logged out"
end as "User signed in?",
Convert(varchar(10), LastSignOn, 101) as "Last Sign On",
DateDiff('d', LastSignOn, getDate()) as "Days since last sign on",
AddrLine1 + ' ' + AddrLine2 + ' ' + AddrLine3 + ' ' +
City + ', ' + State + ' ' + Zip as "Address",
'XXX-XX-' + Substring(
Convert(varchar(9), SSN), 6, 4) as "Social Security #"
FROM Users
Обычно программисты делают это, потому что они намерены привязать свой набор данных непосредственно к сетке, и просто удобно иметь формат SQL Server на стороне сервера, а не форматировать на клиенте.
Запросы, подобные показанному выше, чрезвычайно хрупкие, поскольку они тесно связывают уровень данных с уровнем пользовательского интерфейса. Кроме того, этот стиль программирования полностью предотвращает повторное использование хранимых процедур.
Периодически у разработчика возникает необходимость передать в запрос набор параметров или даже целую выборку «на вход». Иногда попадаются очень странные решения этой задачи.

Пойдем «от обратного» и посмотрим, как делать не стоит, почему, и как можно сделать лучше.
Выглядит обычно примерно так:
query = "SELECT * FROM tbl WHERE id = " + value
… или так:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)
Про этот способ сказано, написано и даже нарисовано предостаточно:
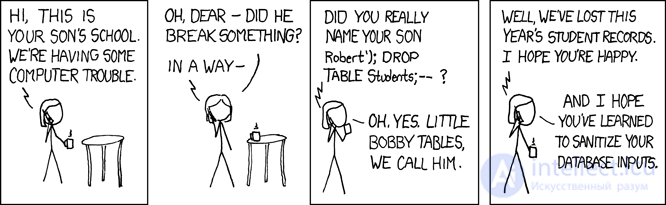
Почти всегда это — прямой путь к SQL-инъекциям и лишней нагрузке на бизнес-логику, которая вынуждена «клеить» строку вашего запроса.
Частично оправдан такой подход может быть только в случае необходимости использования секционирования в версиях PostgreSQL 10 и ниже для получения более эффективного плана. В этих версиях перечень сканируемых секций определяется еще без учета передаваемых параметров, только на основании тела запроса.
Использование плейсхолдеров параметров — это хорошо, оно позволяет использовать PREPARED STATEMENTS, снижая нагрузку как на бизнес-логику (строка запроса формируется и передается только один раз), так и на сервер БД (не требуется повторный разбор и планирование для каждого экземпляра запроса).
Переменное количество аргументов
Проблемы будут ждать нас, когда мы захотим передать заранее неизвестное количество аргументов:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...
Если оставить запрос в таком виде, то это хоть и убережет нас от потенциальных инъекций, но все равно приведет к необходимости склейки/разбора запроса для каждого варианта от количества аргументов. Уже лучше, чем делать это каждый раз, но можно обойтись и без этого.
Достаточно передать всего один параметр, содержащий сериализованное представление массива:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'
Единственное отличие — необходимость явно преобразовывать аргумент в нужный тип массива. Но это не вызывает проблем, поскольку мы и так заранее знаем, куда адресуемся.
Передача выборки (матрицы)
Обычно это всякие варианты передачи наборов данных для вставки в базу «за один запрос»:
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...
Помимо описанных выше проблем с «переклейкой» запроса, это нас может привести еще и к out of memory и падению сервера. Причина проста — под аргументы PG резервирует дополнительную память, а количество записей в наборе ограничивается только прикладными хотелками бизнес-логики. В особо клинических случаях приходилось видеть «номерные» аргументы больше $9000 — не надо так.
Перепишем запрос, применив уже «двухуровневую» сериализацию:
INSERT INTO tbl
SELECT
unnest ::text k
, unnest ::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Да, в случае «сложных» значений внутри массива, их требуется обрамлять кавычками.
Понятно, что таким способом можно «развернуть» выборку с произвольным количеством полей.
unnest, unnest, ...
Периодически встречаются варианты передачи вместо «массива массивов» нескольких «массивов столбцов», про которые я упоминал в прошлой статье:
SELECT unnest($1::text[]) k , unnest($2::integer[]) v;
При таком способе, ошибившись при генерации списков значений для разных столбцов, очень просто получить совсем неожиданные результаты, зависящие еще и от версии сервера:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |
Начиная еще с версии 9.3 в PostgreSQL появились полноценные функции для работы с типом json. Об этом говорит сайт https://intellect.icu . Поэтому, если определение входных параметров у вас происходит в браузере, вы можете прямо там и формировать json-объект для SQL-запроса:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'
Для предыдущих версий такой же способ можно использовать для each(hstore), но корректная «свертка» с экранированием сложных объектов в hstore может вызвать проблемы.
json_populate_recordset
Если вы заранее знаете, что данные из «входного» json-массива пойдут для заполнения какой-то таблицы, можно сильно сэкономить в «разыменовании» полей и приведении к нужным типам, воспользовавшись функцией json_populate_recordset:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);
json_to_recordset
А эта функция просто «развернет» переданный массив объектов в выборку, не опираясь на формат таблицы:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2
Но если объем данных в передаваемой выборке очень велик, то закинуть его в один сериализованный параметр — тяжело, а иногда и невозможно, поскольку требует разового выделения большого объема памяти. Например, вам необходимо долго-долго собирать большой пакет данных по событиям из внешней системы, а потом хотите разово его обработать на стороне БД.
В этом случае лучшим решением станет использование временных таблиц:
CREATE TEMPORARY TABLE tbl(k text, v integer); ... INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз ... -- тут делаем что-то полезное со всей этой таблицей целиком
Способ хорош именно для редкой передачи больших объемов данных.
С точки зрения описания структуры своих данных временная таблица отличается от «обычной» только лишь одним признаком в системной таблице pg_class, а в pg_type, pg_depend, pg_attribute, pg_attrdef, ... — так и вовсе ничем.
Поэтому в web-системах с большим количеством короткоживущих подключений для каждого из них такая таблица будет порождать новые системные записи каждый раз, которые удаляются с закрытием соединения с БД. В итоге, неконтролируемое использование TEMP TABLE приводит к «распуханию» таблиц в pg_catalog и замедлению многих операций, использующих их.
Конечно, с этим можно бороться с помощью периодического прохода VACUUM FULL по таблицам системного каталога.
Предположим, обработка данных из предыдущего случая достаточно сложна для одного SQL-запроса, но делать ее хочется достаточно часто. То есть мы хотим использовать процедурную обработку в DO-блоке, но использовать передачу данных через временные таблицы будет слишком накладно.
Использовать $n-параметры для передачи в анонимный блок мы тоже не сможем. Выйти из положения нам помогут переменные сессии и функция current_setting.
До версии 9.2 необходимо было предварительно сконфигурировать специальное пространство имен custom_variable_classes для «своих» переменных сессии. На актуальных же версиях можно писать примерно так:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3
На других поддерживаемых процедурных языках можно найти и другие решения.
Сегодня не будет никаких сложных кейсов и мудреных алгоритмов на SQL. Все будет очень просто, на уровне Капитана Очевидность — делаем просмотр реестра событий с сортировкой по времени.
То есть вот лежит в базе табличка events, а у нее поле ts — ровно то самое время, по которому мы хотим эти записи упорядоченно показывать:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
CREATE INDEX ON events(ts DESC);
Понятно, что записей у нас там будет не десяток, поэтому нам потребуется в каком-то виде постраничная навигация.
cur.execute("SELECT * FROM events;")
rows = cur.fetchall();
rows.sort(key=lambda row: row.ts, reverse=True);
limit = 26
print(rows[offset:offset+limit]);
Даже почти не шутка — редко, но встречается в дикой природе. Иногда после работы с ORM бывает тяжело перестроиться на «прямую» работу с SQL.
Но давайте перейдем к более распространенным и менее очевидным проблемам.
SELECT ... FROM events ORDER BY ts DESC LIMIT 26 OFFSET $1; -- 26 - записей на странице, $1 - начало страницы
Откуда тут взялось число 26? Это примерное количество записей для заполнения одного экрана. Точнее, 25 отображаемых записей, плюс 1, сигнализирующая, что дальше в выборке хоть что-то еще есть и имеет смысл двигаться дальше.
Конечно, это значение можно не «вшивать» в тело запроса, а передавать через параметр. Но в этом случае планировщик PostgreSQL не сможет опереться на знание, что записей должно оказаться относительно немного, — и запросто выберет неэффективный план.
И пока в интерфейсе приложения просмотр реестра реализован как переключение между визуальными «страницами», никто долго не замечает ничего подозрительного. Ровно до момента, когда в борьбе за удобство UI/UX не решают переделать интерфейс на «бесконечный скролл» — то есть все записи реестра рисуются единым списком, который пользователь может крутить вверх-вниз.
И вот, при очередном тестировании вас ловят на дублировании записей в реестре. Почему, ведь на таблице есть нормальный индекс (ts), на который опирается ваш запрос?
Ровно потому, что вы не учли, что ts не является уникальным ключом в этой таблице. Собственно, и значения у него не уникальны, как у любого «времени» в реальных условиях — поэтому одна и та же запись в двух соседних запросах легко «перескакивает» со страницы на страницу за счет другого конечного порядка в рамках сортировки одинакового значения ключа.
На самом деле, тут скрыта еще и вторая проблема, которую заметить много сложнее — некоторые записи не будут показаны вовсе! Ведь «сдублировавшиеся» записи заняли чье-то место. Подробное объяснение с красивыми картинками можно прочитать тут.
Расширяем индекс
Хитрый разработчик понимает — надо сделать ключ индекса уникальным, а самый простой способ — расширить его заведомо уникальным полем в качестве которого отлично подойдет PK:
CREATE UNIQUE INDEX ON events(ts DESC, id DESC);
А запрос мутирует:
SELECT ... ORDER BY ts DESC, id DESC LIMIT 26 OFFSET $1;
Некоторое время спустя к вам приходит DBA и «радует», что ваши запросы адски грузят сервер своими конскими OFFSET, и вообще, пора бы перейти на навигацию от последнего показанного значения. Ваш запрос мутирует снова:
SELECT ... WHERE (ts, id) < ($1, $2) -- последние полученные на предыдущем шаге значения ORDER BY ts DESC, id DESC LIMIT 26;
Вы облегченно вздохнули, пока не наступила…
Потому что однажды ваш DBA прочитал статью про поиск неэффективных индексов и понял, что «непоследний» timestamp — это нехорошо. И снова пришел к вам — теперь с мыслью, что вот тот индекс должен все-таки превратиться обратно в (ts DESC).
Но что же делать с первоначальной проблемой «скакания» записей между страницами?.. А все просто — надо выбирать блоки с нефиксированным количеством записей!
Вообще, кто нам запрещает читать не «ровно 26», а «не менее 26»? Например, так, чтобы в следующем блоке оказались записи с заведомо другими значениями ts — тогда ведь и проблемы с «перепрыгиванием» записей между блоками не будет!
Вот как этого добиться:
SELECT
...
WHERE
ts < $1 AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < $1
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;
Что здесь вообще происходит?
Или то же самое картинкой:
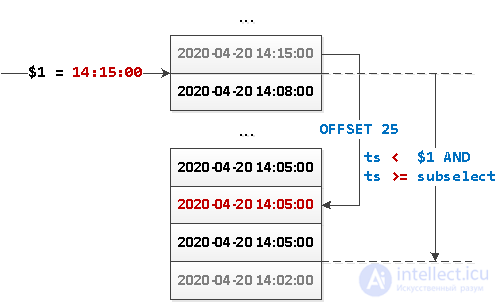
Поскольку теперь у нас выборка не имеет какого-то определенного «начала», то нам ничто не мешает «развернуть» этот запрос в обратную сторону и реализовать динамическую подгрузку блоков данных от «опорной точки» в обе стороны — как вниз, так и вверх.
Замечание
SQL — это не C++, и не JavaScript. Поэтому вычисление логических выражений происходит иначе, и вот это — совсем не одно и то же:
WHERE fncondX() AND fncondY()
= fncondX() && fncondY()
В процессе оптимизации плана исполнения запроса PostgreSQL может произвольным образом «переставлять» эквивалентные условия, не вычислять какие-то из них для отдельных записей, относить к условию применяемого индекса… Короче, проще всего считать, что вы заранее не можете управлять тем, в каком порядке будут (и будут ли вообще) вычисляться равноправные условия.
Поэтому если управлять приоритетом все-таки хочется, надо структурно сделать эти условия неравными с помощью условных выражений и операторов.
Данные и работа с ними — основа нашего комплекса СБИС, поэтому нам очень важно, чтобы операции над ними выполнялись не только корректно, но и эффективно. Давайте посмотрим на конкретных примерах, где могут быть допущены ошибки вычисления выражений, а где стоит улучшить их эффективность.
Стартовый пример из документации:
Когда порядок вычисления важен, его можно зафиксировать с помощью конструкции CASE. Например, такой способ избежать деления на ноль в предложении WHERE ненадежен:SELECT ... WHERE x > 0 AND y/x > 1.5;
Безопасный вариант:SELECT ... WHERE CASE WHEN x > 0 THEN y/x > 1.5 ELSE false END;
Применяемая так конструкция CASE защищает выражение от оптимизации, поэтому использовать ее нужно только при необходимости.
BEGIN
IF cond(NEW.fld) AND EXISTS(SELECT ...) THEN
...
END IF;
RETURN NEW;
END;
Вроде все выглядит хорошо, но… Никто не обещает, что вложенный SELECT не будет выполняться при ложности первого условия. Поправим с помощью вложенных IF:
BEGIN
IF cond(NEW.fld) THEN
IF EXISTS(SELECT ...) THEN
...
END IF;
END IF;
RETURN NEW;
END;
Теперь посмотрим внимательно — все тело триггерной функции оказалось «завернуто» в IF. А это значит, что нам ничто не мешает вынести это условие из процедуры с помощью WHEN-условия:
BEGIN
IF EXISTS(SELECT ...) THEN
...
END IF;
RETURN NEW;
END;
...
CREATE TRIGGER ...
WHEN cond(NEW.fld);
Такой подход позволяет гарантированно сэкономить ресурсы сервера при ложности условия.
SELECT ... WHERE EXISTS(... A) OR EXISTS(... B)
В неприятном случае можно получить, что оба EXISTS будут «истинными», но оба и выполнятся.
Но если мы точно знаем, что один из них бывает «истинным» много чаще (или «ложным» — для AND-цепочки) — нельзя ли как-то «повысить его приоритет», чтобы второй не выполнялся лишний раз?
Оказывается, можно — алгоритмически подход близок к теме статьи PostgreSQL Antipatterns: редкая запись долетит до середины JOIN.
Давайте просто «засунем под CASE» оба эти условия:
SELECT ...
WHERE
CASE
WHEN EXISTS(... A) THEN TRUE
WHEN EXISTS(... B) THEN TRUE
END
В данном случае мы не определяли ELSE-значение, то есть в случае ложности обоих условий CASE вернет NULL, что трактуется как FALSE в WHERE-условии.
Данный пример можно скомбинировать и иначе — на вкус и цвет:
SELECT ...
WHERE
CASE
WHEN NOT EXISTS(... A) THEN EXISTS(... B)
ELSE TRUE
END
На разбор причин «странной» сработки этого триггера мы потратили два дня — давайте посмотрим, почему.
Исходник:
IF( NEW."Документ_" is null or NEW."Документ_" = (select '"Комплект"'::regclass::oid) or NEW."Документ_" = (select to_regclass('"ДокументПоЗарплате"')::oid)
AND ( OLD."ДокументНашаОрганизация" <> NEW."ДокументНашаОрганизация"
OR OLD."Удален" <> NEW."Удален"
OR OLD."Дата" <> NEW."Дата"
OR OLD."Время" <> NEW."Время"
OR OLD."ЛицоСоздал" <> NEW."ЛицоСоздал" ) ) THEN ...
Проблема №1: неравенство не учитывает NULL
Представим, что все OLD-поля имели значение NULL. Что получится?
SELECT NULL <> 1 OR NULL <> 2; -- NULL
А с точки зрения отработки условия NULL эквивалентен FALSE, как было упомянуто выше.
Решение: используйте оператор IS DISTINCT FROM от ROW-оператора, сравнивая сразу целые записи:
SELECT (NULL, NULL) IS DISTINCT FROM (1, 2); -- TRUE
Проблема №2: разная реализация одинакового функционала
Сравним:
NEW."Документ_" = (select '"Комплект"'::regclass::oid)
NEW."Документ_" = (select to_regclass('"ДокументПоЗарплате"')::oid)
Зачем тут лишние вложенные SELECT? А функция to_regclass? А по-разному-то почему?..
Исправим:
NEW."Документ_" = '"Комплект"'::regclass::oid NEW."Документ_" = '"ДокументПоЗарплате"'::regclass::oid
Проблема №3: приоритет bool-операций
Отформатируем исходник:
{... IS NULL} OR
{... Комплект} OR
{... ДокументПоЗарплате} AND
( {... неравенства} )
Упс… По факту, получилось, что в случае истинности любого из двух первых условий, все условие целиком обращается в TRUE, без учета неравенств. А это совсем не то, чего мы хотели.
Исправим:
(
{... IS NULL} OR
{... Комплект} OR
{... ДокументПоЗарплате}
) AND
( {... неравенства} )
Проблема №4 (маленькая): сложное OR-условие для одного поля
Собственно, проблемы в №3 у нас возникли ровно потому, что условий было три. Но вместо них можно обойтись одним, с помощью механизма coalesce ... IN:
coalesce(NEW."Документ_"::text, '') IN ('', '"Комплект"', '"ДокументПоЗарплате"')
Так мы и NULL «поймаем», и сложных OR со скобками городить не придется.
Итого
Зафиксируем то, что у нас получилось:
IF (
coalesce(NEW."Документ_"::text, '') IN ('', '"Комплект"', '"ДокументПоЗарплате"') AND
(
OLD."ДокументНашаОрганизация"
, OLD."Удален"
, OLD."Дата"
, OLD."Время"
, OLD."ЛицоСоздал"
) IS DISTINCT FROM (
NEW."ДокументНашаОрганизация"
, NEW."Удален"
, NEW."Дата"
, NEW."Время"
, NEW."ЛицоСоздал"
)
) THEN ...
А если учесть, что эта триггерная функция может применяться только в UPDATE-триггере из-за наличия OLD/NEW в условии верхнего уровня, то это условие можно вообще вынести в WHEN-условие, как было показано в #1…
Исследование, описанное в статье про антипаттерны, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое антипаттерны, антипаттерн и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL