подходы к обработке больших данных в QlikView
Large Data Sets в QlikView – в данной статье описываются основные подходы к обработке больших данных в приложении QlikView (эта статья не относится к Big Data). Эта статья описывает лишь три основных подхода. Существуют другие подходы, но они будут рассмотрены позже. Qlik может обрабатывать очень большие наборы данных. Однако, для оптимизации работы пользователя и использования ресурсов оборудования, которое требуется для QlikView, Вы можете выполнить несколько вариантов работ.
Допустим, у Вас есть большой набор данных по заказам в размере 1 миллиарда строк. Вам необходимо обеспечить высокоуровневые показатели для высшего руководства, разработать инструменты для анализа тенденций для бизнес-аналитиков, а также предоставить детальную информацию для сотрудников, которые занимаются обработкой операционной информации по заказам. Существует несколько подходов к отображению данных. Рассмотрим три подхода.
Только детальная таблица фактов
использование только детальной таблицы фактов позволяет QlikView сделать всю работу для того, чтобы отобразить детальную информацию и суммарные показатели от низшего уровня детализации до высокоагрегированного уровня. Преимущества – простота. Это самое простое решение для реализации кода. Вы просто подключаетесь к низшему уровню таблице Orders (возможно, на уровне SKU) в модели данных, а затем проектируете все высокоуровневые метрики, диаграммы с трендами и детальные таблицы, и настраиваете выборки (фильтры) в документе QVW. Недостатки – QlikView будет необходимо агрегировать 1 миллиард строк детальной информации с каждым кликом по фильтрам. QlikView это может сделать, но производительность приложения будет не очень хорошая, а требуемые ресурсы потребуются значительные.
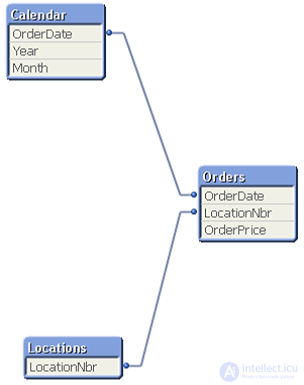

QlikView Document Chaining – что это такое?
Document Chaining ( метод цепного взаимодействия документов ) – это подход к построению взаимодействия двух документов QVW. Об этом говорит сайт https://intellect.icu . Первый документ имеет таблицу Orders с детальными данными (это основная таблица фактов), другой документ имеет предварительно агрегированную таблицу Orders (таблица фактов для второго документа). Предположим, что у нас есть только два этих документа QVW. Ниже приведена схема, которая показывает модель данных из “Summary QVW” и модель данных из “Detail QVW”. Обратите внимание, что значения измерений являются одинаковыми в этих двух моделях. Основное различие между документами заключается в таблице фактов. Пользователи могут начать работать с агрегированного документа, который показывает верхнеуровневую информацию.
Если пользователи хотят “просверлиться” в детальные данные, Вы можете воспользоваться подходом Document Chaining в QlikView, чтобы переместить выборки (фильтры) из одного QVW документа в другой QVW документ, а затем открыть второй документ. Пользователь будет видеть новые диаграммы, вкладки и ему не нужно будет знать как фильтры перемещаются из одного документа QVW в другой. Это означает, что Вы будете использовать таблицу фактов с 1 миллиардом строк, когда пользователям это нужно. Остальная работа по обработке данных будет вестись на предварительно агрегированной версии таблицы заказов, которая может быть значительно меньше, чем 100 миллионов строк. Document Chaining подробно описан в справочном руководстве QlikView и в ряде других документов QlikView.
Преимущества – данный подход оптимизирует использование аппаратных ресурсов и скорость реакции на запросы пользователей к навигации и диаграммам QlikView. Потому что выборки пользователей и навигация предоставляются для конкретных нужд, Вам не нужно тратить ресурсы процессора и оперативной памяти для постоянной обработки 1 миллиарда строк детальных данных, когда пользователь в этом не нуждается.
Недостатки – таблицы (QVDs) необходимо предварительно агрегировать и обеспечивать обслуживание для данного подхода. Этот подход намного сложнее, чем разработка приложения с одной таблицей фактов Orders.

Triggered Action – взаимосвязь таблиц через триггеры
“Triggered Action” подход – это использование предварительно агрегированной суммарной таблицы в дополнение к подробной таблице в одной модели данных QVW документа. На схеме, которая приведена ниже, показан один из способов использования предварительно агрегированной информации в той же модели данных (рядом с детализированной таблицей). В модель данных загружается предварительно агрегированная таблица в качестве data island (у данной таблицы отсутствуют взаимосвязи с другими таблицами модели данных). Затем, соответствующие выборки в детальной таблице фактов переносятся на предагрегированную таблицу фактов с помощью триггеров (triggered Action).
Преимущества – этот вариант не требует второго документа QVW и не требуется document chaining для того, чтобы использовать обе версии (детальной и суммарной) большой таблицы данных.
Недостатки – этот вариант потребует некоторых настроек в QVW, чтобы вызвать действия, которые передадут выборки из одной таблицы в другую. Так как QVW документ изменяется с течением времени, Вам придется отслеживать, куда и когда должны направлены быть действия триггера.

Пожалуйста, обратите внимание: Существует еще больше вариантов, с помощью которых Вы можете удовлетворить данные потребности, описанные в этой статье. Это всего лишь 3 метода, которые показывают особенности и возможности QlikView для управления очень большими наборами данных.
Ключевые факторы, которые влияют на модель:
- Уникальные колонки данных;
- Уникальные записи в ключевых полях.
Оба последних способа могут оказать влияние на размер памяти в модели данных и на использование приложений пользователями.
Вау!! 😲 Ты еще не читал? Это зря!
- big data , большие данные ,
- big data , парадигма mapreduce ,
- big data , hadoop ,
- big data , mapreduce ,
- big data , hbase ,
- big data , sql-движок hive ,
- big data , hive ,

Комментарии