Лекция
Привет, Вы узнаете о том , что такое проблема с запросом n + 1, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое проблема с запросом n + 1, select n + 1 , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
проблема с запросом n + 1 ( select n + 1 ) возникает, когда система к данным выполняет N дополнительных операторов SQL для извлечения тех же данных, которые могли быть получены при выполнении основного запроса SQL.
Чем больше значение N, тем больше запросов будет выполнено, тем больше влияние на производительность. И, в отличие от журнала медленных запросов, который может помочь вам найти медленно выполняющиеся запросы, проблема N + 1 не будет очевидной, потому что каждый отдельный дополнительный запрос выполняется достаточно быстро, чтобы не запускать журнал медленных запросов.
Проблема заключается в выполнении большого количества дополнительных запросов, которые в целом занимают достаточно времени, чтобы замедлить время ответа.
Давайте рассмотрим, что у нас есть следующие таблицы базы данных post и post_comments, которые образуют отношение таблиц один-ко-многим:
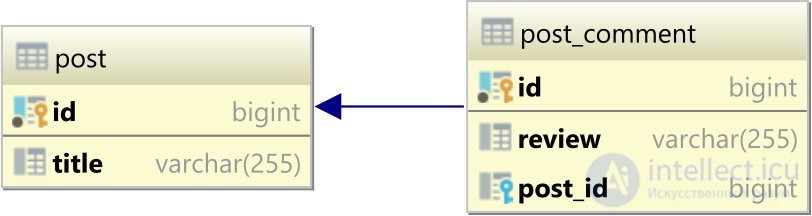
Мы собираемся создать следующие 4 postряда:
И мы также создадим 4 post_commentдочерних записи:
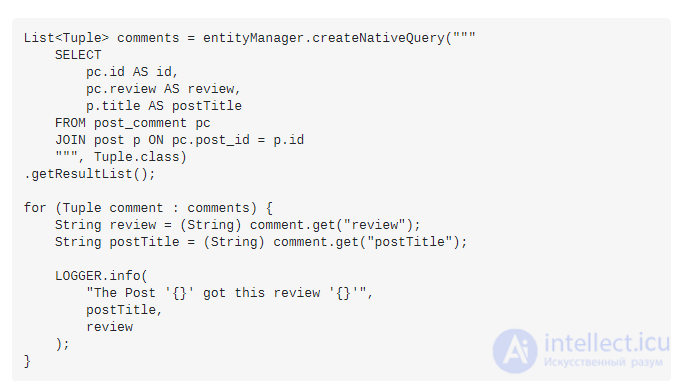
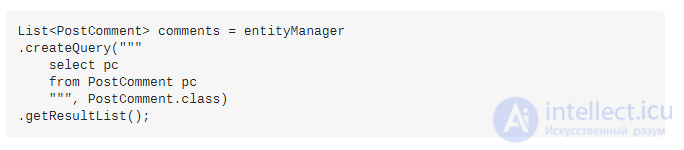
Если вы выберете post_commentsиспользование этого SQL-запроса:
И позже вы решаете получить связанные post titleдля каждого post_comment:
Вы собираетесь вызвать проблему запроса N + 1, потому что вместо одного запроса SQL вы выполнили 5 (1 + 4):
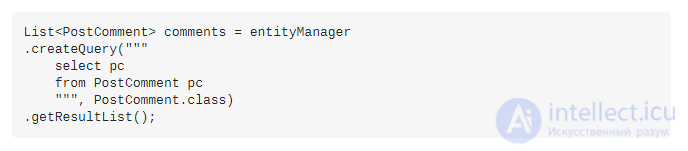
Исправить проблему с запросом N + 1 очень просто. Все, что вам нужно сделать, это извлечь все данные, которые вам нужны в исходном SQL-запросе, например:
На этот раз выполняется только один SQL-запрос для извлечения всех данных, которые мы в дальнейшем хотим использовать.
При использовании JPA и Hibernate есть несколько способов вызвать проблему с запросом N + 1, поэтому очень важно знать, как избежать таких ситуаций.
В течение следующих примеров мы рассмотрим КАРТОГРАФИРОВАНИЕ postи post_commentsтаблиц для следующих лиц:
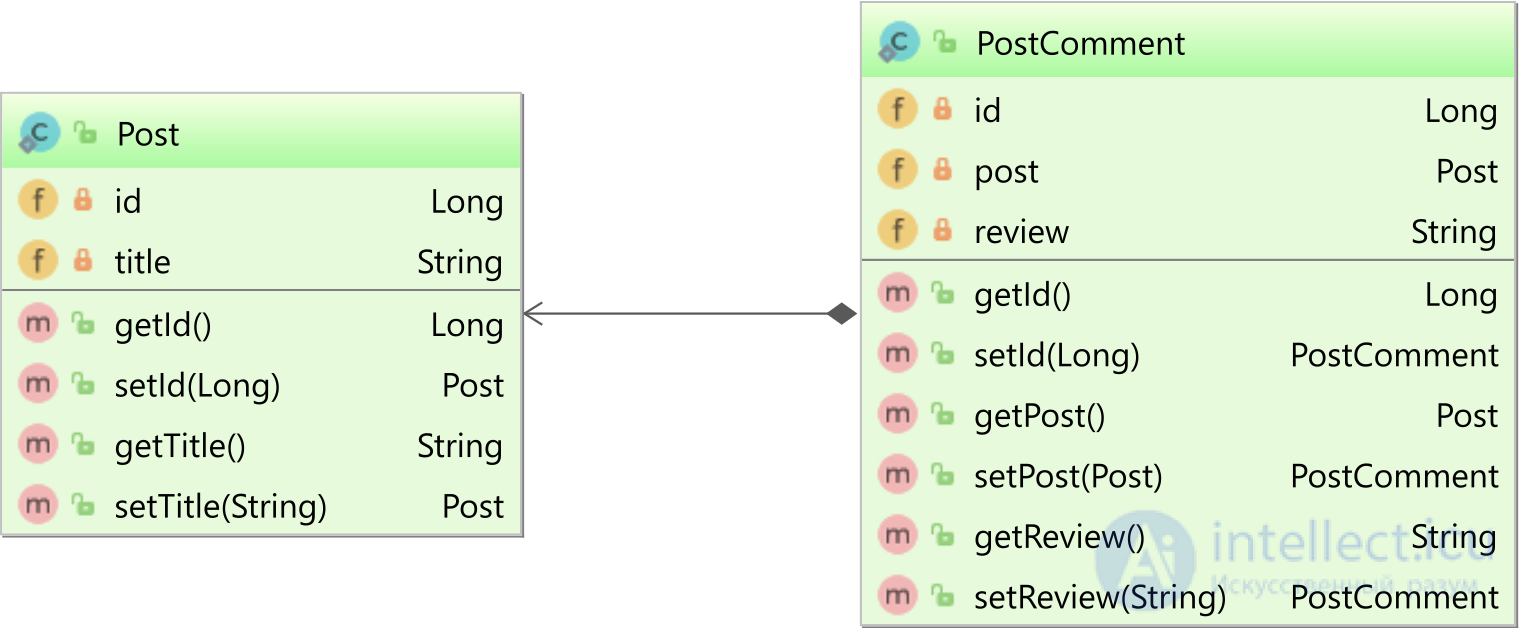
Сопоставления JPA выглядят так:
FetchType.EAGERИспользование FetchType.EAGERнеявно или явно для ваших ассоциаций JPA - плохая идея, потому что вы собираетесь получить гораздо больше данных, которые вам нужны. Более того, эта FetchType.EAGERстратегия также подвержена проблемам с запросом N + 1.
К сожалению, @ManyToOneи @OneToOneассоциации используют FetchType.EAGERпо умолчанию, поэтому , если ваши отображения выглядеть следующим образом :
@ManyToOne
private Post post;
Вы используете FetchType.EAGERстратегию, и каждый раз, когда вы забываете использовать ее JOIN FETCHпри загрузке некоторых PostCommentсущностей с помощью запроса JPQL или Criteria API:
Вы собираетесь вызвать проблему с запросом N + 1:
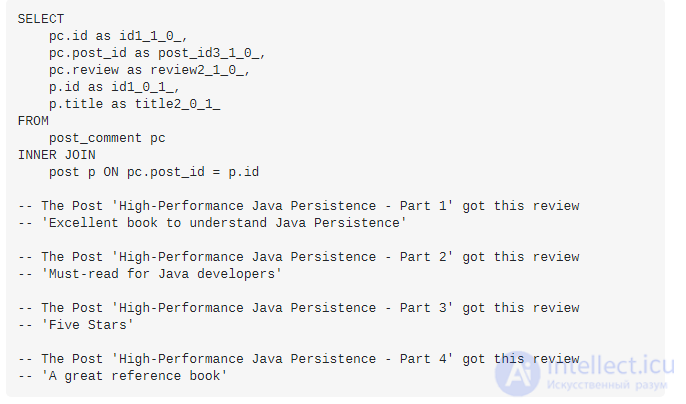
Обратите внимание на дополнительном ЗЕЬЕСТ, которые выполняются , потому что postассоциация должна быть извлечены до возвращения Listиз PostCommentсубъектов.
В отличие от плана выборки по умолчанию, который вы используете при вызове findметода EnrityManager, запрос JPQL или Criteria API определяет явный план, который Hibernate не может изменить, автоматически вводя JOIN FETCH. Об этом говорит сайт https://intellect.icu . Значит, делать это нужно вручную.
Если вам вообще не нужна postассоциация, вам не повезло с ее использованием, FetchType.EAGER потому что нет способа избежать ее получения. Поэтому лучше использовать FetchType.LAZYпо умолчанию.
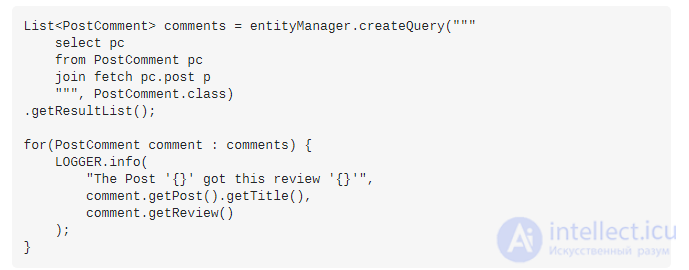
Но, если вы хотите использовать postассоциацию, вы можете использовать, JOIN FETCHчтобы избежать проблемы с запросом N + 1:
На этот раз Hibernate выполнит один оператор SQL:
FetchType.LAZYДаже если вы переключитесь на использование FetchType.LAZYявно для всех ассоциаций, вы все равно можете столкнуться с проблемой N + 1.
На этот раз postассоциация отображается следующим образом:
@ManyToOne(fetch = FetchType.LAZY)
private Post post;
Теперь, когда вы получаете PostCommentобъекты:
Hibernate выполнит один оператор SQL:
Но, если после этого вы собираетесь ссылаться на postассоциацию с отложенной загрузкой :
Вы получите проблему с запросом N + 1:
Поскольку postассоциация выбирается лениво, при доступе к ленивой ассоциации будет выполняться вторичный оператор SQL, чтобы создать сообщение журнала.
Опять же, исправление заключается в добавлении JOIN FETCHпредложения в запрос JPQL:
И, как и в FetchType.EAGERпримере, этот запрос JPQL сгенерирует один оператор SQL.
Даже если вы используете
FetchType.LAZYи не ссылаетесь на дочернюю ассоциацию двунаправленного@OneToOneотношения JPA, вы все равно можете вызвать проблему запроса N + 1.
Если вы хотите автоматически обнаруживать проблему с запросом N + 1 на уровне доступа к данным, вы можете использовать проект с db-utilоткрытым исходным кодом.
Во-первых, вам нужно добавить следующую зависимость Maven:
После этого вам просто нужно использовать SQLStatementCountValidatorутилиту для утверждения генерируемых базовых операторов SQL:
Если вы используете FetchType.EAGERи запускаете вышеуказанный тестовый пример, вы получите следующий сбой тестового примера:
Одна из основных проблем разработчиков, когда они создают приложение с ORM — это N+1 запрос в их приложениях. Проблема N+1 запроса — это не эффективный способ обращения к базе данных, когда приложение генерирует запрос на каждый вызов объекта. Эта проблема обычно возникает, когда мы получаем список данных из базы данных без использования ленивой или жадной загрузки (lazy load, eager load). К счастью, Laravel с его ORM Eloquent предоставляет инструменты, для удобной работы, но они имеют некоторые недостатки.
В этой статье рассмотрим проблему N+1, способы ее решения и оптимизации потребления памяти.
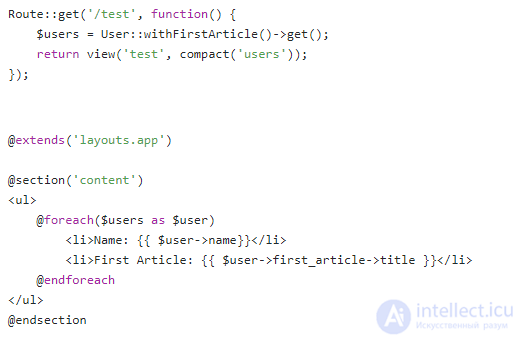
Давайте рассмотрим простой пример, как использовать eager loading в Laravel. Допустим, у нас есть простое веб-приложение, которое показывает список заголовков первых статей пользователей приложения. Тогда связь между нашими моделями может быть вроде такой:

и тогда простое действие получения данных из базы данных и передачи в шаблон может выглядеть таким образом:

Простой шаблон test.blade.php для отображения списка пользователей с соответствующими заголовками их первой статьи:
И когда мы откроем нашу тестовую страницу в браузере, мы увидим нечто подобное:
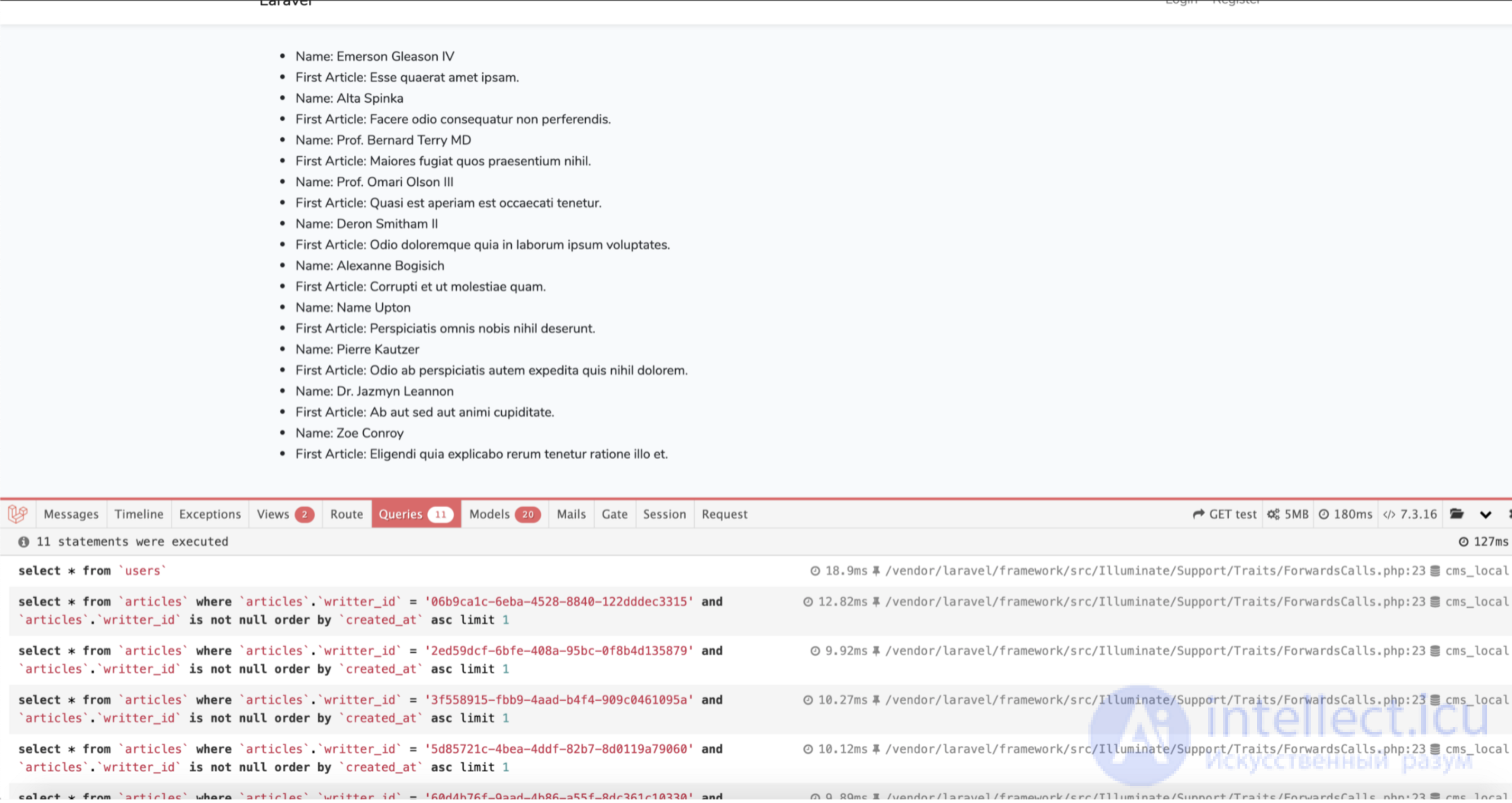
Я использую debugbar (https://github.com/barryvdh/laravel-debugbar), чтобы показать, как выполняется наша тестовая страница. Для отображения этой страницы вызывается 11 запросов в БД. Один запрос для получения всей информации о пользователях и 10 запросов, чтобы показать заголовок их первой статьи. Видно, что 10 пользователей создают 10 запросов в базу данных к таблице статей. Это называется проблемой N+1 запроса.
Вам может показаться, что это не проблема производительности вашего приложения в целом. Но что, если мы хотим показать больше чем 10 элементов? И часто, нам также приходится иметь дело с более сложной логикой, состоящего из более чем одного N+1 запроса на странице. Это условие может привести к более чем 11 запросам или даже к экспоненциально растущему количеству запросов.
Итак, как мы это решаем? Есть один общий ответ на это:
Eager load
Eager load (жадная загрузка) — это процесс, при котором запрос для одного типа объекта также загружает связанные объекты в рамках одного запроса к базе данных. В Laravel мы можем загружать данные связанных моделей используя метод with(). В нашем примере мы должны изменить код следующим образом:

И, наконец, уменьшить количество наших запросов до двух:
Также мы можем создать связь hasOne, с соответствующим запросом для получения первой статьи пользователя:
Теперь мы можем загрузить ее вместе с пользователями:
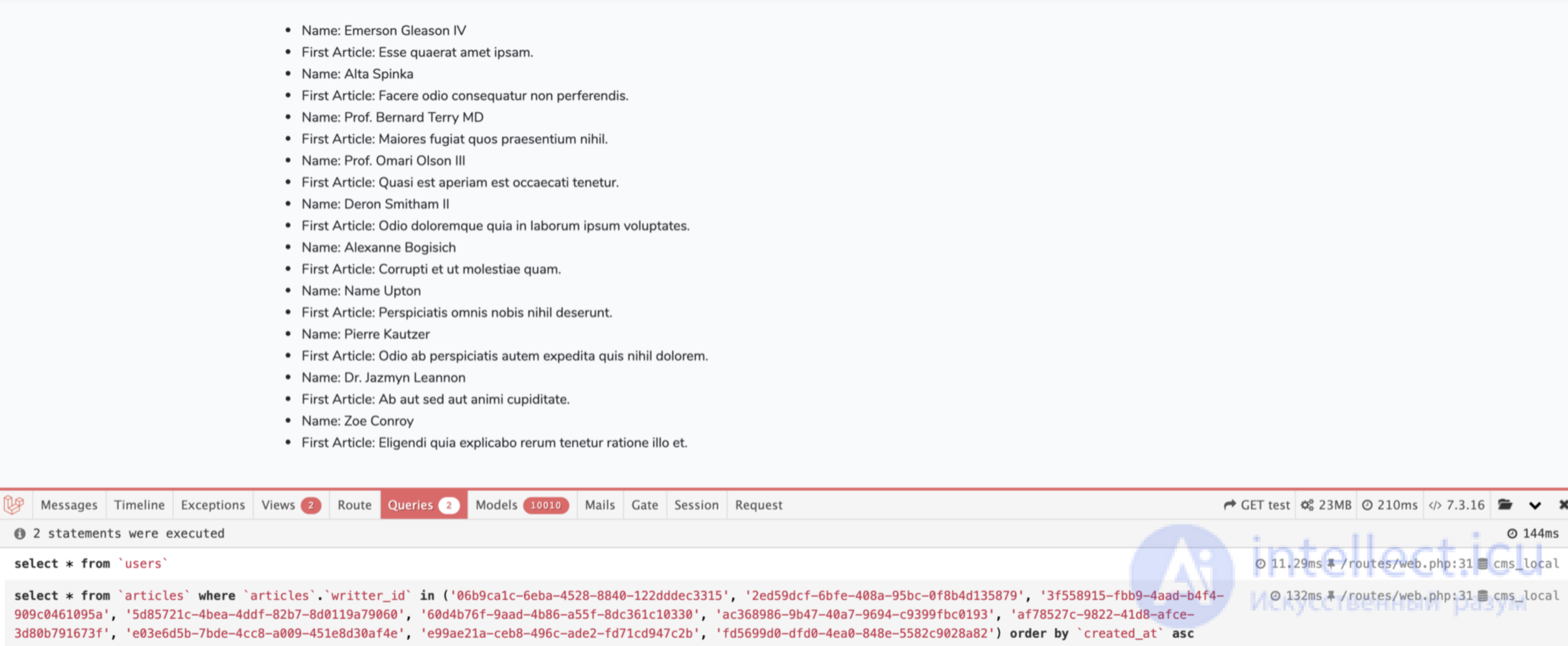
Результат теперь выглядит следующим образом:
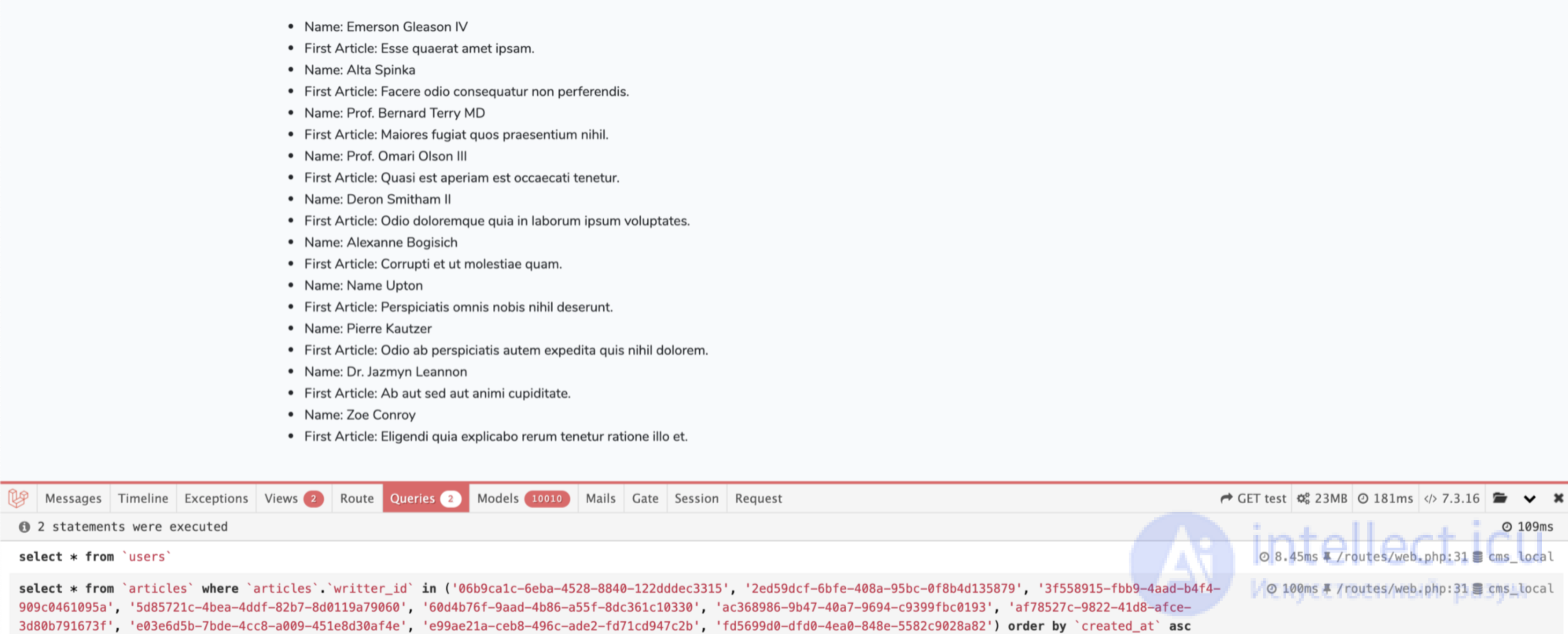
Итого, мы можем уменьшить количество наших запросов и решить проблему N+1 запроса. Но хорошо ли мы улучшили нашу производительность? Ответом может быть "нет"! Это правда, что мы уменьшили количество запросов и решили проблемы N+1 запроса, но на самое деле мы добавили новую неприятную проблему. Как вы видите, мы уменьшили количество запросов с 11 до 2, но мы также увеличили количество загружаемых моделей с 20 до 10010. Это означает, чтобы показать 10 пользователей и 10 заголовков статей мы загружаем 10010 объектов Eloquent в память. Если у вас не ограничена память, то это не проблема. Иначе вы можете положить ваше приложение.
Должно быть 2 цели при разработке приложения:
В нашем примере, мы не смогли свести к минимуму потребление памяти, в то время, как мы уменьшили наши запросы до минимального количества. Во многих случаях разработчики также хорошо достигают первой цели, но проваливают вторую. В этом случае мы можем использовать подход жадной загрузки динамических отношений через подзапрос, чтобы достичь обеих целей.
Для реализации динамических отношений, мы будем напрямую использовать primary key вместо его foreign key. Мы также должны использовать подзапрос в связанной таблице, чтобы получить соответствующий идентификатор. Подзапрос будет размещен в select на основе отфильтрованных данных связанной таблицы.
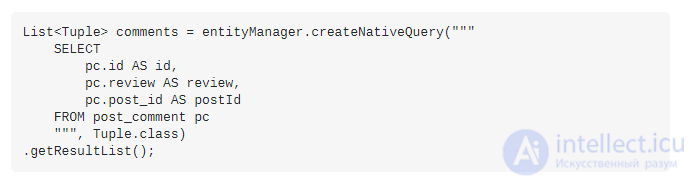
Пример получения пользователей и id их первых статей через подзапрос:

Мы можем получить такой запрос, если добавим select в подзапрос в нашем query builder. С использованием Eloquent это можно написать следующим образом:
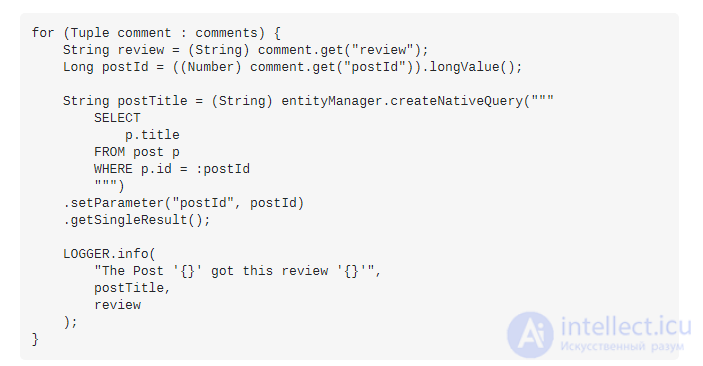
Этот код генерирует такой же sql запрос, что и в примере выше. После этого мы сможем использовать связь "first_article_id" для получения первых статей пользователя. Чтобы сделать наш код чище, мы можем использовать query scope Eloquent, чтобы упаковать наш код и выполнить жадную загрузку для получения первой статьи. Таким образом, мы должны добавить следующий код в класс модели User:
И наконец, давайте изменим наш контроллер и шаблон. Мы должны использовать scope в нашем контроллере для жадной загрузки первой статьи. И мы можем напрямую обращаться к переменной first_article в нашем шаблоне:
Ниже результат производительности страницы после внесения этих изменений:
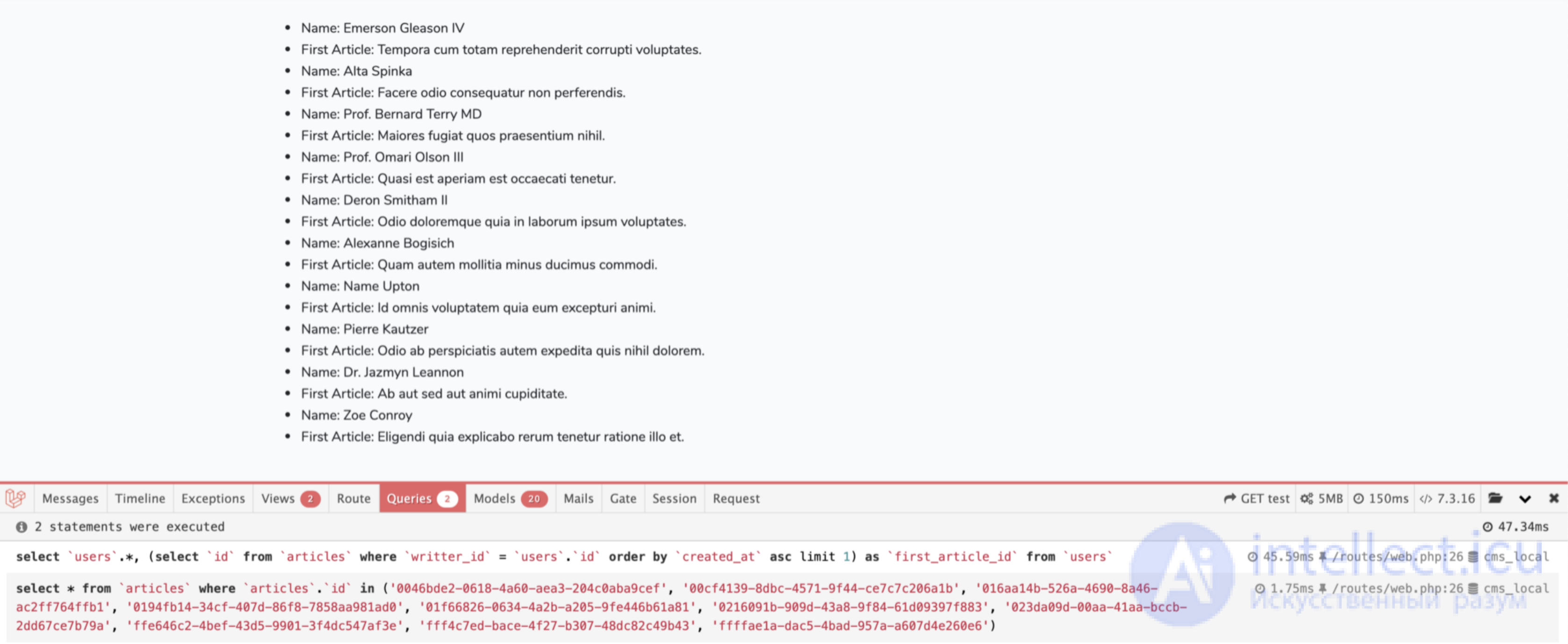
Теперь наша страница содержит всего 2 запроса и загружает 20 моделей. Мы достигли обеих целей оптимизации количества запросов к БД и минимизации потребления памяти.
Наша динамическая связь не будет работать хорошо автоматически. Сначала мы должны загрузить подзапрос для создания этой связи. Что, если мы хотим использовать ленивую подгрузку первых статей пользователя в одном месте и иметь жадную загрузку статей в другом месте?
Для этого нам нужно добавить небольшой хинт в наш ход, добавив accessor для свойства первой статьи:
В действительности, мы не реализовывали ленивую загрузку для динамической связи. Мы просто назначили результат выполнения запроса получения первой статьи пользователя. Это должно работать одинаково хорошо при обращении к свойству first_article как для жадной загрузки, так и для ленивой загрузки.
К сожалению, наше решение применимо только к Laravel 6 и выше. Laravel 6 и предыдущие версии используется разная реализация addSelect. Для использования в более старых версиях фреймворка мы должны изменить наш код. Мы должны использовать selectSub для выполнения подзапроса:
Исследование, описанное в статье про проблема с запросом n + 1, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое проблема с запросом n + 1, select n + 1 и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL




















Комментарии