Лекция
Привет, Вы узнаете о том , что такое каппа-архитектура, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое каппа-архитектура , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Kappa Архитектура представляет собой архитектура программного обеспечения , используемая для обработки потоковых данных. Основная предпосылка архитектуры Kappa заключается в том, что вы можете выполнять как обработку в реальном времени, так и пакетную обработку, особенно для аналитики, с помощью единого технологического стека. Он основан на потоковой архитектуре, в которой входящая серия данных сначала сохраняется в механизме обмена сообщениями, таком как Apache Kafka. Отсюда движок потоковой обработки считывает данные и преобразует их в анализируемый формат, а затем сохраняет их в аналитической базе данных для запросов конечных пользователей.
Архитектура Kappa поддерживает аналитику (почти) в реальном времени, когда данные считываются и преобразуются сразу после их вставки в механизм обмена сообщениями. Это делает последние данные быстро доступными для запросов конечных пользователей. Он также поддерживает историческую аналитику, считывая сохраненные потоковые данные из механизма обмена сообщениями в более позднее время в пакетном режиме, чтобы создавать дополнительные анализируемые выходные данные для большего количества типов анализа.
Архитектура Kappa считается более простой альтернативой Lambda Architecture, поскольку в ней используется один и тот же технологический стек для обработки как потоковой обработки в реальном времени, так и исторической пакетной обработки. Обе архитектуры предполагают хранение исторических данных для проведения крупномасштабной аналитики. Обе архитектуры также полезны для решения проблемы «человеческой отказоустойчивости», когда проблемы с кодом обработки (либо ошибки, либо просто известные ограничения) могут быть преодолены путем обновления кода и его повторного запуска на исторических данных. Основное отличие от архитектуры Kappa заключается в том, что все данные обрабатываются как поток, поэтому механизм обработки потока действует как единственный механизм преобразования данных.
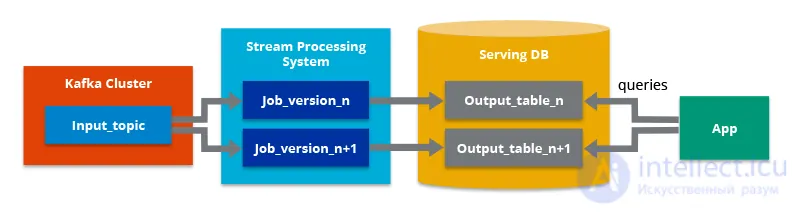
Архитектура Kappa обычно строится на основе Apache Kafka® вместе с высокоскоростным движком потоковой обработки.
При всех достоинствах Лямбда-архитектуры, главным недостатком этого подхода к проектированию Big Data систем считается его сложность из-за дублирования логики обработки данных в холодном и горячем путях. Поэтому в 2014 году была предложена Каппа – альтернативная модель, которая потребляет меньше ресурсов, но отлично подходит для обработки событий в режиме реального времени .
В отличие от лямбда, в Каппа-архитектуре потоковые данные проходят по одному пути. Все данные принимаются как поток событий в распределенном и отказоустойчивом едином журнале – логе событий. Там события упорядочиваются, и текущее состояние события изменяется только при добавлении нового события. Аналогично уровню ускорения лямбда-архитектуры, вся обработка событий выполняется во входном потоке и сохраняется как представление в режиме реального времени. Если необходимо повторно вычислить весь набор данных, как на пакетном уровне в лямбда-архитектуре, поток воспроизводится заново. Об этом говорит сайт https://intellect.icu . Для своевременного завершения вычислений используется параллелизм .
Функциональное уравнение, которое определяет запрос Big Data, в Каппа-архитектуре будет выглядеть так :
Query = K (New Data) = K (Live streaming data)
Это уравнение означает, что все запросы могут быть обработаны путем применения функции Каппа (К) к real-time потокам данных на скоростном уровне.
Таким образом, можно сказать, что каппа-архитектура – это упрощение Лямбда-подхода к проектированию Big Data систем, когда из модели удален уровень пакетной обработки данных. При этом каноническое хранилище данных представляет собой неизменяемый журнал только для добавления информации. Из журнала данные сразу передаются в систему потоковых вычислений, по необходимости обогащаясь данными из неканонического хранилища (сервисный уровень). Цель сервисного уровня – предоставить оптимизированные ответы на запросы. Однако эти хранилища не являются каноническими (неизменяемыми): их можно в любой момент стереть и восстановить из канонического Data Store .
Для реализации Каппа-архитектуры используются следующие технологии Big Data :
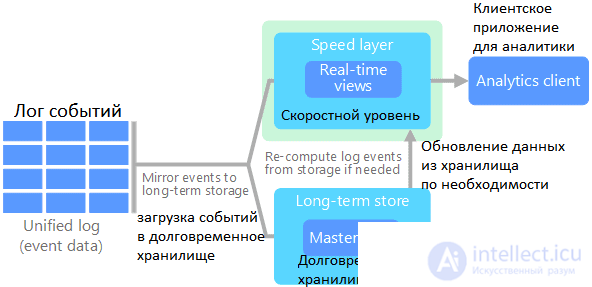
Каппа-архитектура для Big Data систем
Итак, Kappa-архитектура целесообразна для таких корпоративных моделей обработки данных, где :
Все эти сценарии отлично покрываются брокером сообщений Apache Kafka – быстрой, отказоустойчивой и горизонтально масштабируемой системой сбора и агрегации больших данных. Поэтому Каппа-архитектура на базе Kafka активно используется LinkedIn и другими Big Data проектами, где требуется сохранить большой объем данных для обслуживания запросов, которые являются простой копией друг друга .
Архитектура потоковой передачи - это определенный набор технологий, которые работают вместе для обработки потоковой обработки , то есть практики выполнения действий с серией данных во время их создания. Во многих современных развертываниях Apache Kafka действует как хранилище для потоковых данных, а затем несколько потоковых процессоров могут воздействовать на данные, хранящиеся в Kafka, для получения нескольких выходных данных. Некоторые потоковые архитектуры включают в себя рабочие процессы как для потоковой обработки, так и для пакетной обработки , что либо влечет за собой другие технологии для обработки крупномасштабной пакетной обработки, либо с использованием Kafka в качестве центрального хранилища, как указано в архитектуре Kappa.
Прежде всего отметим, что при общих целях построения надежной и быстрой системы обработки больших данных, подходы лямбда и каппа не конкурируют друг с другом, а могут использоваться вместе для разных случаев. В частности, для надежной работы с озером данных (Data Lake) на базе Apache Hadoop и моделями машинного обучения для прогнозирования будущих событий на основе исторических данных, следует выбрать Лямбда-подход. С другой стороны, если необходимо недорого развернуть Big Data систему для эффективной обработки уникальных событий в реальном времени без исторического анализа, Каппа-архитектура отлично справится с этой задачей. Каппа подходит для тех алгоритмов Machine Learning, которые обучаются в режиме онлайн и не нуждаются в пакетном уровне. Таким образом, для Kappa характерны следующие достоинства :
Тем не менее, отсутствие пакетного уровня может привести к ошибкам при обработке информации или при обновлении базы данных. Поэтому в Каппа-архитектуре возникает потребность в диспетчере исключений для повторной обработки данных или сверки .
Обе архитектуры обрабатывают аналитику в реальном времени и историческую аналитику в единой среде. Однако одним из основных преимуществ архитектуры Kappa над архитектурой Lambda является то, что она позволяет вам построить систему потоковой и пакетной обработки на основе единой технологии. Это означает, что вы можете создать приложение потоковой обработки для обработки данных в реальном времени, и, если вам нужно изменить вывод, вы обновляете свой код, а затем снова запускаете его над данными в механизме обмена сообщениями в пакетном режиме. Не существует отдельной технологии для обработки пакетной обработки, как это предлагается в Lambda Architecture.
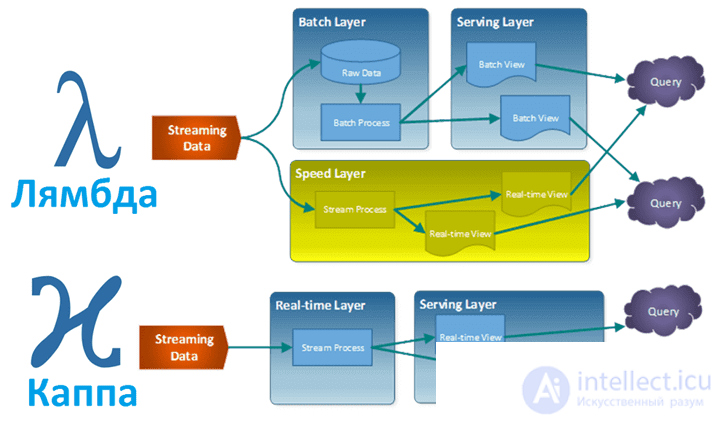
Отличия Каппа от Лямбда архитектур
С достаточно быстрым механизмом потоковой обработки (например, Hazelcast Jet ) вам может не понадобиться отдельная технология, оптимизированная для пакетной обработки. Вы просто читаете сохраненные потоковые данные параллельно (при условии, что данные в Kafka должным образом разделены на отдельные каналы или «разделы») и преобразовываете данные, как если бы они были из источника потоковой передачи. В некоторых средах вы потенциально можете создавать анализируемые выходные данные по запросу, поэтому, когда от конечного пользователя отправляется новый запрос, данные могут быть преобразованы специально для оптимального ответа на этот запрос. Опять же, это требует высокоскоростного механизма обработки потока, чтобы обеспечить малую задержку при обработке.
Хотя в Lambda Architecture не указаны технологии, которые необходимо использовать, компонент пакетной обработки часто выполняется на крупномасштабной платформе данных, такой как Apache Hadoop. Распределенная файловая система Hadoop (HDFS) может экономично хранить необработанные данные, которые затем могут быть преобразованы с помощью инструментов Hadoop в анализируемый формат. В то время как Hadoop используется для компонента пакетной обработки системы, отдельный механизм, предназначенный для потоковой обработки, используется для компонента аналитики в реальном времени. Однако одним из преимуществ лямбда-архитектуры является то, что гораздо большие наборы данных (в диапазоне петабайт) могут более эффективно храниться и обрабатываться в Hadoop для крупномасштабного исторического анализа.
Исследование, описанное в статье про каппа-архитектура, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое каппа-архитектура и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL

Комментарии