Лекция
Привет, Вы узнаете о том , что такое модели данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое модели данных, ранние подходы к организации данных, организация данных , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
После этапа инфологического проектирования базы данных, на котором фактически определяется ее семантическое содержание в терминах сущностей, их свойств и связей, наступает этап проектирования датологической концептуальной модели данных. Теперь речь пойдет уже собственно о моделях данных, в которых в качестве объекта исследования выступают сами данные, их структурная организация, правила построения.
Говоря о моделях данных, обычно рассматривают три взаимосвязанные компоненты модели:
При рассмотрении различных моделей данных их сравнение между собой обычно проводят по тому, как в них реализованы эти три позиции.
В данном учебном курсе основное внимание уделяется рассмотрению систем, основанных на реляционной модели данных. В настоящее время эти системы являются доминирующими на рынке систем с базами данных, практически вытеснив системы, основанные на других подходах. Тем не менее, имеет смысл хотя бы коротко рассмотреть особенности систем, предшествующих реляционным, для правильного понимания причин перехода к реляционным системам. Кроме того, на использовании ранних подходов основаны многие низкоуровневые механизмы функционирования реляционных СУБД. Наиболее известными из таких дореляционных систем являются системы, основанные на инвертированных списках, иерархические базы данных и сетевые базы данных [1, 4]. Относительно этих систем можно отметить следующее.
Структура базы данных, организованная с помощью инвертированных списков, в определенной мере похожа на реляционную - данные хранятся в виде таблиц (рис. 5.1), но, в отличие от реляционной БД, хранимые таблицы данных и пути доступа к ним видны и доступны пользователю. При этом строки (записи) таблиц упорядочены системой в некоторой физической последовательности. Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
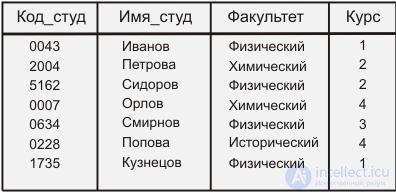
Рис. 5.1 Таблица базы данных, построенной на основе инвертированных списков
Манипулирование данными. Типичный набор операторов над адресуемыми записями:
Структуры данных. Используются упорядоченные структуры данных, организованные в виде «деревьев» (рис. 5.2). Такая древовидная структура состоит из одной корневой записи и упорядоченного набора подчиненных записей-потомков (ветвей дерева). Для корневой записи обязательно формирование значения ключа. Каждая запись-потомок имеет ссылку (указатель) на соответствующую родительскую запись, образуя иерархию подчинения от самого нижнего уровня записей – «листьев дерева» – до верхнего уровня, образуемого корневой записью.
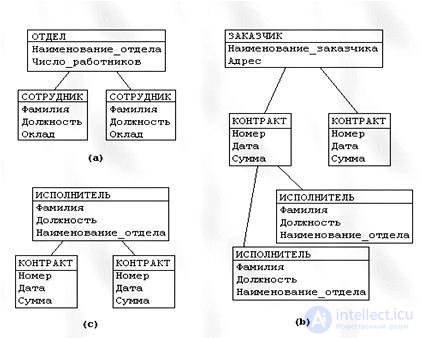
Рис. 5.2 Пример структуры данных в иерархической БД
Манипулирование данными. Операторы манипулирования данными осуществляют навигацию по иерархическим структурам, используя ссылки (указатели) для перехода от записей одного уровня к другому. Операции над данными:
Ограничения целостности. Из ограничений целостности автоматически поддерживается только целостность ссылок между записями-предками и записями-потомками (основное правило – никакой «потомок» не может существовать без своего «родителя»).
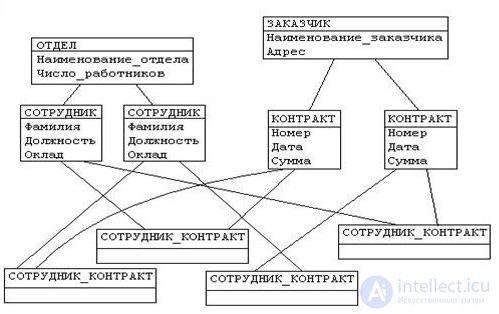
Общим для всех ранних дореляционных систем является то, что в их основе не лежат какие-либо абстрактные модели данных, подкрепленные соответствующим математическим аппаратом. Более того, само понятие модели данных применительно к системам с базами данных стало использоваться именно с появлением реляционного подхода, который во многом родился в результате анализа особенностей, достоинств и в большей степени недостатков существовавших систем управления данными.
В ранних системах доступ к данным в базе данных осуществлялся непосредственно на уровне записей. Навигация по базе данных, поиск, выборка и запись данных в этих системах осуществлялись пользователем с использованием обычных процедурных языков программирования, расширенных функциями работы сСУБД, требуя от пользователя при работе с данными понимания низкоуровневых особенностей хранения данных и связей между ними. Возможность интерактивного доступа к данным реализовывалась гораздо более ограничено, только путем создания соответствующих прикладных программных средств. Как уже говорилось, ранние системы имели достаточно слабые средства поддержания целостности данных.
Низкоуровневые средства навигации и манипулирования данными позволяли, тем не менее, в ранних системах обеспечивать высокую эффективность реализации этих функций прикладными программами, экономное использование памяти вычислительной системы. Это можно отнести к достоинствам таких систем, особенно учитывая уровень вычислительных систем того времени (1960-70-е гг.). Одним из следствий низкого уровня языковых средств, используемых в этих моделях для работы с данными, являлась сложность создания прикладных программных систем, необходимость знания при этом особенностей физического представления и хранения данных. В конечном итоге это приводило к большей сложности или даже невозможность выполнения комплекса требований к информационным системам с базами данных, рассмотренного в предыдущих разделах, например реализации требований многоаспектного использования данных, обеспечения независимости данных от логики использующих их программ и др.
В заключение, эта статья об модели данных подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое модели данных, ранние подходы к организации данных, организация данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Из статьи мы узнали кратко, но содержательно про модели данных
Комментарии