Лекция
оптимизация баз данных - это важный процесс для улучшения производительности и эффективности работы баз данных. Существует несколько методов оптимизации баз данных, которые могут помочь в достижении этой цели.
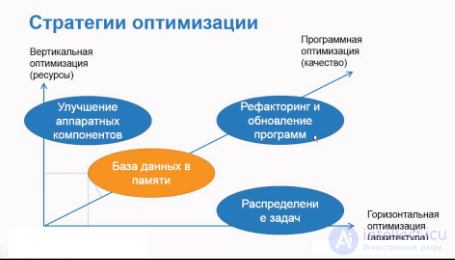
Все перечисленные ниже методы связаны с организацией и управлением данными в информационных системах и базах данных и больших высоконагруженных проектах (например мессенджерах, платежных системах и т.д.). Вот их общие черты и взаимосвязи:
Оптимизация баз данных: Все эти методы и техники используются для оптимизации хранения и обработки данных в базах данных или информационных системах.
Производительность и масштабируемость: Многие из этих методов, такие как индексы , буферные таблицы , шардирование и партиционирование, используются для увеличения производительности и масштабируемости баз данных, позволяя им обрабатывать большие объемы данных и запросов более эффективно.
Отказоустойчивость: Репликация данных и шардирование также связаны с обеспечением отказоустойчивости и доступности данных. Репликация позволяет иметь копии данных на разных серверах, а шардирование распределяет данные между разными узлами.
Управление структурой данных: денормализация , партицирование и шардирование могут влиять на структуру данных, так как они изменяют способ организации данных в базе данных.
Обработка больших данных: Многие из этих методов, такие как MapReduce и репликация данных, применяются в системах, обрабатывающих большие объемы данных, такие как системы анализа больших данных и хранилища данных.
Кэширование и оптимизация запросов: Индексы, буферные таблицы и ленивая загрузка используются для ускорения запросов к данным путем кэширования результатов запросов или создания индексов для быстрого поиска.
Цель улучшения производительности и доступности данных: Все эти методы имеют общую цель - улучшение производительности, доступности и управления данными в информационных системах.
Хотя каждый из этих методов решает определенные задачи и может применяться в разных контекстах, они в совокупности представляют собой инструменты и стратегии для эффективной работы с данными в различных информационных системах и базах данных.
Вот некоторые из способов оптимизации высоконагруженных систем:
Индексы:
Нормализация данных:
Оптимизация запросов:
Партиционирование:
Очистка и архивирование данных:
Использование кэша:
Оптимизация на уровне аппаратного обеспечения:
Мониторинг и настройка:
Важно заметить, что оптимизация баз данных - это непрерывный процесс, и не существует универсального рецепта для всех ситуаций. Конкретные методы оптимизации могут различаться в зависимости от конкретных требований и характеристик вашей базы данных.
Улучшение производительности запросов: Денормализация может уменьшить количество соединений таблиц, что может ускорить выполнение сложных запросов. Это особенно полезно в случаях, когда часто выполняются запросы на чтение данных.
Снижение нагрузки на сервер баз данных: Поскольку запросы становятся менее сложными при денормализации, это может уменьшить нагрузку на сервер баз данных и позволить ему обрабатывать больше запросов одновременно.
Уменьшение сложности кода приложения: Денормализация может упростить код приложения, так как нет необходимости в выполнении множества сложных запросов на объединение таблиц.
Однако денормализация также имеет свои недостатки:
Избыточность данных: При денормализации данные могут дублироваться в разных частях базы данных, что может привести к проблемам с целостностью данных.
Усложнение операций вставки, обновления и удаления данных: Денормализация делает операции вставки, обновления и удаления более сложными, так как данные могут храниться в нескольких местах.
Потеря гибкости: Денормализация усложняет изменение структуры данных, поскольку изменения могут потребовать обновления данных в нескольких местах.
Потеря нормализации: Денормализация может привести к потере преимуществ нормализации, таких как сэкономленное место для хранения данных и обеспечение целостности данных.
Денормализация следует использовать только после внимательного анализа и оценки конкретных требований и характеристик вашей базы данных. Это инструмент оптимизации, который следует использовать с осторожностью и в соответствии с конкретными потребностями вашего приложения.
Реляционные базы данных (RDBMS): Это наиболее распространенный тип хранилищ данных. Они используют структурированные таблицы и SQL-запросы для хранения и доступа к данным. Примеры таких СУБД включают MySQL, PostgreSQL и Microsoft SQL Server.
NoSQL-хранилища данных: NoSQL-базы данных предоставляют более гибкую схему данных и часто используются для хранения неструктурированных данных. К ним относятся MongoDB, Cassandra, и Redis.
Колоночные базы данных: Этот тип хранилищ данных оптимизирован для аналитики и обработки данных. Примеры включают Apache HBase и Apache Cassandra.
Графовые базы данных: Они предназначены для хранения и обработки данных в виде графов. Примерами являются Neo4j и Amazon Neptune.
Хранилища временных рядов: Эти базы данных предназначены для хранения временных рядов данных, таких как логи, метрики и события. Примеры включают InfluxDB и OpenTSDB.
Облачные хранилища данных: Это хранилища данных, предоставляемые облачными провайдерами, такими как Amazon Web Services (AWS) S3, Google Cloud Storage и Microsoft Azure Blob Storage.
XML- и JSON-хранилища: Они спроектированы для хранения и обработки данных в форматах XML и JSON. Примерами являются BaseX и CouchDB.
Объектно-ориентированные хранилища данных: Эти хранилища предоставляют механизм для хранения объектов, сохраняя связи между ними. Примеры включают db4o и Versant.
Оперативные хранилища данных (Data Warehouses): Эти системы предназначены для хранения и анализа данных, и они обычно используются для поддержки бизнес-аналитики. Примерами являются Amazon Redshift и Google BigQuery.
Другие специализированные хранилища данных: Существуют и другие специализированные хранилища данных, такие как временные базы данных, столбцовые магазины данных, и т. д.
Выбор определенного хранилища данных зависит от требований проекта, объема данных, скорости доступа, структуры данных и других факторов. Важно правильно выбрать хранилище данных, чтобы обеспечить эффективное управление и доступ к данным в вашем приложении или организации.
Кэширование данных: Буферные таблицы могут использоваться для кэширования часто запрашиваемых данных в оперативной памяти. Это позволяет уменьшить время доступа к данным, так как данные уже находятся в памяти и не требуется обращение к долгосрочному хранилищу данных.
Временное хранение промежуточных результатов: Буферные таблицы могут использоваться для временного хранения результатов запросов или промежуточных вычислений. Это позволяет оптимизировать сложные запросы или алгоритмы, ускоряя выполнение.
Оптимизация соединений: В случае выполнения соединений (JOIN) между несколькими таблицами, буферные таблицы могут содержать промежуточные результаты соединения, что может существенно ускорить выполнение запросов.
Минимизация обращений к долгосрочному хранилищу данных: Если часто выполняются запросы на чтение данных, буферные таблицы могут быть использованы для снижения нагрузки на долгосрочное хранилище данных, такое как реляционная база данных или файловая система.
Материализованные представления: Буферные таблицы могут быть использованы для создания материализованных представлений, что позволяет сохранять результаты запросов в виде таблиц для последующего быстрого доступа.
Буферные таблицы обычно создаются в оперативной памяти и имеют ограниченное время жизни. Они могут быть автоматически созданы и удалены или управляться программно в зависимости от конкретных потребностей системы. Их целью является повышение производительности и оптимизация запросов к данным, уменьшая нагрузку на постоянное хранилище данных, такое как жесткий диск или база данных.
Ленивая (lazy) и жадная (eager) загрузка - это два разных подхода к загрузке данных в информационных системах, таких как приложения, работающие с базами данных. Они используются для оптимизации доступа к данным и уменьшения издержек при выполнении запросов. Вот их основные характеристики:
Ленивая (Lazy) загрузка:
Жадная (Eager) загрузка:
Выбор между ленивой и жадной загрузкой зависит от конкретных требований приложения и сценариев использования данных. В некоторых случаях может быть полезно использовать комбинацию обоих методов для оптимизации производительности и экономии ресурсов. Важно правильно настроить загрузку данных, чтобы избежать лишней нагрузки на базу данных и ускорить выполнение операций при доступе к данным.
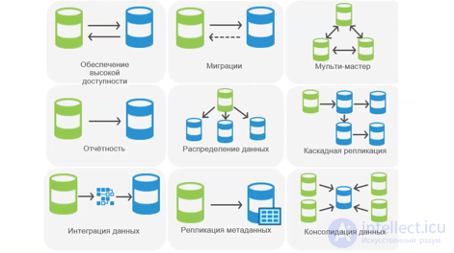
Репликация данных( реплицирование ) - это процесс создания и поддержания копий данных из одного источника данных (мастер-сервера) на один или несколько удаленных серверов (реплик) с целью обеспечения доступности данных, повышения производительности и обеспечения защиты от сбоев. Репликация данных является важной частью стратегии высокой доступности и отказоустойчивости в информационных системах. Вот некоторые ключевые аспекты репликации данных:
Модели репликации:
Мастер-слейв (Master-Slave): В этой модели один сервер (мастер) содержит основной источник данных, а один или несколько других серверов (слейвы) содержат его копии. Записи обычно выполняются на мастер-сервере, и данные реплицируются на слейвы для чтения. Это часто используется для распределения нагрузки и повышения производительности чтения.
Мастер-множество (Master-Master): В этой модели два или более сервера работают как мастеры и могут выполнять как операции записи, так и операции чтения. Это обеспечивает отказоустойчивость и распределение нагрузки, но требует более сложной синхронизации данных.
П2P (Peer-to-Peer): В модели P2P не существует мастера или слейвов. Каждый сервер имеет полные копии данных и может выполнять операции чтения и записи. Это предоставляет максимальную отказоустойчивость, но также требует более сложной синхронизации.
Синхронная и асинхронная репликация:
Синхронная репликация: В этом случае операции записи не завершаются, пока данные не будут реплицированы на все реплики. Это обеспечивает согласованность данных, но может замедлить операции записи.
Асинхронная репликация: Здесь операции записи завершаются независимо от репликации данных на реплики. Это увеличивает производительность операций записи, но может создавать небольшую задержку в согласованности данных между мастером и репликами.
Цели репликации:
Доступность: Репликация данных может обеспечить доступность данных даже в случае отказа мастер-сервера.
Производительность: Репликация может использоваться для распределения нагрузки и ускорения операций чтения.
Резервное копирование: Реплики могут использоваться для создания резервных копий данных.
Защита от сбоев: Репликация данных обеспечивает защиту от потери данных из-за отказа сервера, так как копии данных находятся на других серверах.
Конфликты данных: При использовании репликации, особенно в модели мастер-мастер, может возникнуть проблема конфликтов данных, которую необходимо управлять и разрешать.
Зачем это нужно
Распределение нагрузки
OLTP: на чтение ходим в реплики
OLAP: тяжелая аналитика на отдельной реплике
Снятие бэкапа с отдельной реплики
Фейловер / High Availability
Бывает ручной и автоматический
Отложенная репликация
Не заменяет резервное копирование!
Потоковая (или физическая) репликация
В сущности, заключается в передаче WAL по сети;
Асинхронная
Быстро, но можно потерять данные;
Синхронная
Медленнее (в рамках ДЦ не намного), но надежнее. Желательно иметь две реплики;
Бывает еще каскадной (надо же было упомянуть об этом на каком-то слайде)
Потоковая репликация:
Не работает между разными архитектурами;
Не работает между разными версиями PostgreSQL ;
Логическая репликация
Начиная с PostgreSQL 10 - из коробки;
Старые подходы: Slony, Londiste, pglogical;
Не рекомендуются, потому что медленные и/или плохо работают;
9 из 24
Зачем нужен еще один вид репликации?
Репликация части данных, не всего подряд;
Обновление без даунтайма;
На реплике можно использовать временные таблицы, да и вообще писать все что угодно, в т.ч. в реплицируемые таблицы;
Одна реплика может тянуть данные с двух мастеров;
В теории - можно изобразить multimaster;
И другие сценарии, когда физическая репликация не подошла;
Репликация данных является мощным инструментом для обеспечения доступности, производительности и отказоустойчивости данных. Однако ее настройка и управление могут быть сложными задачами, и требуется тщательное планирование и согласование с требованиями вашей системы.
Шардирование (sharding) - это стратегия горизонтального разделения данных, которая используется для улучшения производительности и масштабируемости баз данных. Вместо того, чтобы хранить все данные в одной базе данных, данные разделяются на небольшие фрагменты (шарды), которые хранятся на разных серверах или узлах. Это позволяет равномерно распределить нагрузку и увеличить способность базы данных обрабатывать большой объем данных и запросов. Вот некоторые ключевые аспекты шардирования:
Шарды:
Как выбирать шард:
Преимущества шардирования:
Недостатки шардирования:
Применение шардирования:
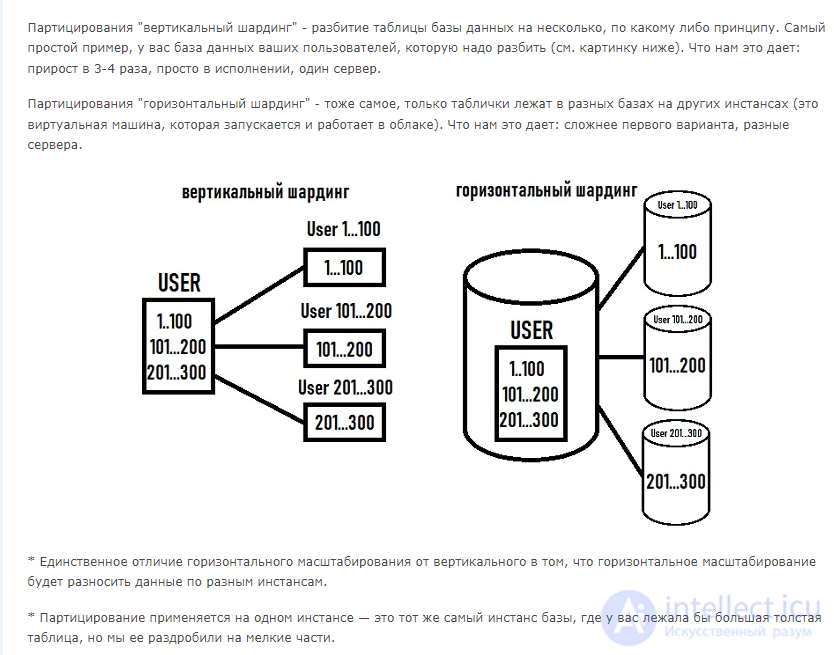
Шардирование - это мощный инструмент для оптимизации производительности и масштабируемости баз данных, но оно также требует тщательного проектирования и управления, чтобы избежать сложностей и проблем при согласовании данных между шардами.
MapReduce - это метод обработки и агрегации больших объемов данных на кластере серверов с целью распараллеливания и ускорения вычислений. Давайте объясним это простыми словами с примером:
Представьте, что у вас есть миллионы книг и вы хотите узнать, сколько раз каждое слово встречается в этих книгах. Это задача обработки больших данных, которую можно решить с помощью MapReduce.
Map (Отображение): В первом этапе каждый сервер (или "маппер") берет часть книг и разбивает ее на отдельные слова. Затем он подсчитывает, сколько раз каждое слово встречается в своей части. Например, сервер может обнаружить, что слово "apple" встречается 100 раз.
Shuffle and Sort (Сортировка и группировка): После того как все серверы завершили свою работу, результаты группируются и сортируются. Все вхождения слова "apple" объединяются вместе и сортируются.
Reduce (Уменьшение): В этом этапе другие серверы (или "редьюсеры") берут отсортированный список слов и подсчитывают общее количество вхождений каждого слова. Например, все упоминания слова "apple" подсчитываются, и вы узнаете, что оно встречается 1000 раз во всех книгах.
Итак, MapReduce разбивает большую задачу на множество маленьких задач, обрабатываемых параллельно на разных серверах, а затем собирает и агрегирует результаты. Этот подход позволяет эффективно обрабатывать и анализировать огромные объемы данных, что особенно важно в анализе больших данных и обработке данных в больших компаниях и проектах.
Предварительное нагрузочное тестирование базы данных - это процесс, в рамках которого база данных подвергается экспериментам и тестам с имитацией разного уровня нагрузки и трафика, чтобы выявить узкие места, проблемы производительности и оптимизировать ее работу до внедрения в продукцию. В контексте оптимизации базы данных нагрузочное тестирование играет важную роль:
Выявление узких мест и проблем производительности: нагрузочное тестирование помогает выявить, как база данных реагирует на разные уровни нагрузки и трафика. Это позволяет выявить узкие места, где производительность снижается, и проблемы, такие как медленные запросы, блокировки или конфликты.
Оптимизация структуры и индексации: На основе результатов нагрузочное тестирование можно оптимизировать структуру базы данных и индексы. Вы можете определить, какие таблицы, поля и индексы нуждаются в оптимизации, чтобы запросы выполнялись быстрее.
Настройка сервера базы данных: Выявленные во время нагрузочное тестирование проблемы с производительностью могут потребовать настройки сервера базы данных. Это может включать в себя изменение параметров сервера, оптимизацию буферов или распределение ресурсов.
Масштабирование базы данных: Если нагрузочное тестирование показывает, что база данных не может обрабатывать текущий уровень нагрузки, это может потребовать масштабирования базы данных, например, добавления реплик или шардирования.
Предотвращение сбоев и перегрузок: нагрузочное тестирование может помочь предотвратить сбои и перегрузки базы данных, что может привести к недоступности приложения. Он позволяет выявить, какая нагрузка базы данных может выдерживать, и планировать резервные меры.
Оценка производительности при изменениях: Если вы планируете внести изменения в структуру базы данных или запросы, нагрузочное тестирование позволяет оценить, как эти изменения повлияют на производительность перед их внедрением.
Таким образом нагрузочное тестирование является важным этапом в оптимизации базы данных, так как он позволяет выявить и устранить проблемы производительности до того, как они начнут влиять на работу приложения. Это позволяет обеспечить стабильную и высокую производительность базы данных и, как следствие, всего приложения.
Если вы знаете еще методы, методики, способы и приемы оптимизации работы баз данных, то пишите в комментариях.

Комментарии