Лекция
Привет, Вы узнаете о том , что такое хранилища данных и учет влияния транзакций, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое хранилища данных и учет влияния транзакций, хранилища данных и денормализация таблиц, горизонтальное разбиение таблиц, разбиение таблиц и ссылочная целостность, объединение таблиц базы данных, денормализация колонок, column denormalization , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Прежде чем обсуждать основные типы приложений баз данных, уточним термины транзакция (transaction) и запрос. В теории БД, вообще говоря, под транзакцией понимают одну из команд SQL — SELECT, INSERT, UPDATE, DELETE. Однако в зависимости от типа приложений термин " транзакция " трактуется более свободно, как элементарная логически завершенная единица работы (так называемая бизнес-транзакция ), которая может включать несколько команд вставки, удаления или модификации. В зависимости от того, какие команды SQL используются, транзакции разделяют на транзакции только для записи (write-only), только для модификации (modify-only), только для чтения (read-only), только для удаления (delete-only). Транзакции только для чтения называют запросом.
Исходя из такого деления транзакций по типам обработки с учетом частоты транзакций каждого типа, можно выделить три основных классических типа приложений БД.
Можно выделить еще несколько типов приложений, появившихся в последние два десятилетия.
Для анализа транзакций необходимо оценить тип приложений, для которых разрабатывается база данных. Это позволит оценить:
Напомним, транзакция БД – это логическая единица работы, которая переводит БД из одного завершенного состояния в другое завершенное состояние. Под завершенным состоянием БД здесь понимается такое состояние, которое не нарушает целостности этих данных, когда все данные в таблицах базы данных правильны, а ссылки между таблицами корректны. В дополнение транзакция группирует операции над данными таким образом, чтобы все обращения к БД были успешно завершены или, в случае сбоя, БД возвратилась в предыдущее завершенное состояние (откат транзакции ).
Поскольку любая операция изменения данных в БД несет в себе потенциальную возможность нарушения целостности данных, необходимо строго определять транзакции и идентифицировать информацию, которая обычно включается в определение транзакции.
Определение транзакции может иметь различные формы. Иногда для определения транзакций используется репозиторий данных CASE-средств проектирования базы данных. Очень часть определение транзакций выполняется посредством текстовых описаний. Независимо от выбранного подхода, любое хорошее определение транзакции включает несколько важных элементов. К таким элементам относятся:
Первым шагом в определении транзакций является уникальная идентификация каждой транзакции БД. Это можно сделать назначением имени и номера каждой транзакции БД. Имена транзакций должны позволять пользователям отличать их друг от друга. Описание включает перечень операций предметной области, которые выполняются транзакцией. Оно должно быть выполнено в терминах предметной области, понятных пользователю. Здесь нужно иметь в виду следующее:
Пример 19.1. Описание транзакции.
Имя транзакции: назначить работу служащему.
Описание транзакции. Транзакция проверяет, не назначена ли уже данная работа данному служащему, затем проверяет, располагает ли служащий рабочим временем для выполнения данной работы. Если результаты проверки положительны (данная работа не назначена данному служащему, и служащий располагает временем для ее выполнения), то происходит назначение данной работы данному служащему.
В OLTP-системах большинство транзакций известны заранее, поэтому между спецификацией транзакции и транзакцией БД существует взаимно однозначное соответствие. В DSS-системах транзакции часто неизвестны заранее, и, следовательно, невозможно в принципе описать их все. В этом случае спецификация лишь в общих чертах описывает транзакции БД, поэтому важно уметь предсказать тип транзакций, которые пользователь, вероятнее всего, будет выполнять в БД.
Для каждой транзакции может быть определен характер транзакции (онлайновая транзакция или пакетная транзакция ), а также указана ее сложность. Обычно сложность указывается в терминах "высокая", "средняя", "низкая". Эта информация нужна для оценки транзакций базы данных в целом. Количество транзакций той или иной сложности влияет на время проектирования физической модели базы данных: чем больше в базе данных транзакций высокой сложности, тем больше время проектирования физической модели. Сложность транзакции является условной мерой трудоемкости при достижении требований производительности базы данных.
Высокая сложность приписывается обычно транзакции, которая имеет две из следующих характеристик:
Низкая сложность приписывается транзакции с следующими характеристиками:
Транзакция со средней сложностью имеет характеристики между низкой и высокой сложностью.
Пример 19.2. Определение характеристик транзакции.
Характер транзакции: онлайновая транзакция.
Сложность: средняя.
Информация о частотах транзакций включает обычно два параметра — среднюю частоту транзакции (например, 50 тр/ч) и пиковую частоту транзакции (например, 70 тр/ч). Оценка частотных характеристик БД очень важна для проектирования физической модели данных ХД: настройка физической структуры БД для транзакций с высокой частотой существенно отличается от настройки ее для транзакции с низкой частотой использования.
Пример 19.3.
Средняя частота транзакции: до 10 в день.
Пиковая частота: 10 в час.
Если для модернизации существующих систем информация о частотах транзакций может быть представлена во входной документации на основе анализа статистики эксплуатации системы, то для создаваемых ХД такую информацию получить практически невозможно, и приходится пользоваться приблизительными оценками.
Спецификация транзакции должна включать требования по производительности. Производительность БД в целом складывается из производительности каждой транзакции в отдельности и их распределении во времени. Это очень важная информация для решения задачи настройки физической структуры ХД. Требования по производительности обычно задаются в виде параметра время реакции, т.е. количества секунд, требуемых для выполнения транзакции. Например, во многих банковских системах транзакция для снятия денег со счета клиента не должна занимать более 5 секунд.
Другой формой задания требования на производительность транзакций БД является указание их характера и сложности. Например,
Получение требований на производительность транзакций является одним из самых узких мест как в исходной документации, так и в проектировании физической модели ХД. На практике получить временные характеристики выполнения транзакций часто удается только на этапе опытной эксплуатации, а то и промышленной эксплуатации ХД.
Желательно в спецификации транзакции указать ее относительный приоритет, который показывает, насколько важна настоящая транзакция для предметной области по сравнению с другими. Относительный приоритет позволяет сгруппировать транзакции по этому параметру, что дает возможность последовательно оценить все транзакции БД и их вклад в производительность БД.
Выполнение какой-либо транзакции в БД с большим приоритетом отрицательно сказывается на производительности других транзакций. Ранжирование по относительному приоритету позволяет сбалансировать влияние транзакций друг на друга в целом.
Задание приоритета транзакций может иметь различные формы. Обычно такое действие сводится к субъективной оценке в виде числа от 1 до 10.
Каждая спецификация транзакции должна содержать команды SQL, которые задают операции с БД. Указание команд SQL в контексте создания физической модели ХД позволяет оценить время выполнения транзакций (execution time), т.е. фактическое количество секунд, необходимое для завершения транзакции в режиме эксплуатации ХД. Проектировщику ХД этот параметр важен еще и с точки зрения составления спецификаций модулей приложений ХД для разработчиков приложений.
Помимо собственно команды языка манипулирования данными, желательно включить некоторый комментарий к каждой команде, в котором указать: а) что команда делает, б) почему это требуется и в) количество строк в ХД, которое захватывается командой. Время выполнения команды SQL непосредственно зависит от числа обрабатываемых командой строк. Обычно время выполнения транзакций можно оценить на стадии опытной эксплуатации и тестирования базы данных.
Пример 19.4.
| Команда | Комментарий |
|---|---|
| Select works from project where empno=:1 and works=:2 | Возвращает информацию о назначении данной работы данному служащему. По крайней мере, одна строка возвращается. Число строк, которые могут обрабатываться командой, равно текущему размеру таблицы PROJECT |
| Select works from project where empno=:1 | Возвращает список работ данного служащего, чтобы оценить его загруженность. Число строк, которые могут обрабатываться командой, равно текущему размеру таблицы PROJECT |
| Insert into project empno, works values(:1, :2) | Назначает данного служащего на данную работу, если это необходимо |
Описание транзакций позволяет принимать или откладывать решение об изменении физической схемы ХД с целью исполнения требований по производительности базы данных.
Механизмы, с помощью которых можно обеспечить выполнение требований производительности, обсуждаются ниже, в предположении, что для создания ХД выбрана СУБД семейства MS SQL Server, за исключением одного примера, в котором используется диалект SQL СУБД семейства Oracle.
Начиная с этого раздела, мы будем рассматривать методики настройки физической структуры реляционной БД, используемой для реализации ХД, с целью удовлетворения требования к производительности ХД. Эти методики представляют собой набор рекомендаций и эвристических правил по изменению физической структуры БД, которая была получена в результате первой итерации создания физической модели данных ХД. Ясно, что применение этих методик носит рекомендательный характер.
В этом разделе будут описаны различные типы денормализации и методы ее реализации. Кроме того, мы рассмотрим, как при выполнении денормализации обеспечить целостность данных, не прибегая к созданию дополнительного кода.
Под денормализацией понимают процесс достижения компромиссов в нормализованных таблицах посредством намеренного введения избыточности в целях увеличения производительности.
В большинстве случаев необходимость денормализации становится очевидной лишь на этапе проектирования приложений ХД или его эксплуатации. Другими словами, нельзя принять решение о денормализации на основании одной только модели данных. Обычно стараются найти в приложениях ХД критичные процессы и принимать решения о денормализации в основном в пользу этих процессов. Критичные процессы, как правило, определяют по высокой частоте, большому объему, высокой изменчивости или явному приоритету. Качественное описание транзакций БД позволяет определить наличие таких критических процессов.
Заметим, что применять денормализацию только для упрощения SQL-запросов при обращении к ХД является неправильным решением. Если вы хотите упростить SQL-запросы на уровне приложения или пользователя, то, наверное, лучше использовать представления, а не вводить избыточность. Чтобы повысить производительность запроса, можно ввести индексы.
Как правило, денормализация уменьшает время запроса за счет DML-операций. Денормализацию следует рассматривать как расширение нормализованной модели данных, которое повышает производительность запросов. При приятии решения о денормализации следует определить, что является наиболее важным для приложения – избыточность данных или высокая производительность. Если ведется журнал проектирования (некоторый внутренний документ произвольной формы, в котором фиксируются все принятые в процессе проектирования ХД решения), то в него необходимо занести обоснованное решение о денормализации. Необходимо помнить, что кроме денормализации существуют и другие пути повышения производительности. Денормализацию таблиц можно выполнять как на уровне логической модели данных, так и на уровне физической модели.
Рассмотрим принципы денормализации на уровне физической модели данных. Нисходящая денормализация предлагает перенос колонки из одной (родительской) таблицы в подчиненную (дочернюю) таблицу.
На рис. 19.1 показаны две таблицы – "Покупатель" (Customer befor) и "Заказ" (Order befor) – физической модели данных до проведения денормализации, а на рис. 19.2 — эти же таблицы, "Покупатель" (Customer after) и "Заказ" (Order after), после выполнения нисходящей денормализации.

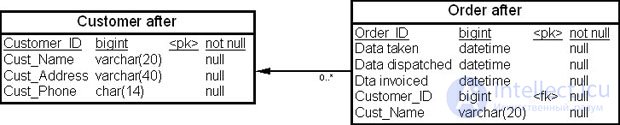
Из рисунков видно, что в денормализованной модели мы переместили колонку "Фамилия покупателя" (Cust_Name) из таблицы "Покупатель" (Customer after) в таблицу "Заказ" (Order after).
Что дает введение избыточности (перенос колонки) в данном случае? Единственный выигрыш заключается в том, что мы исключаем операцию соединения, если захотим вместе с заказом увидеть фамилию клиента.
Таким образом, нисходящая денормализация – это процесс введения избыточных колонок в подчиненных таблицах с целью устранения операций соединения.
Однако устранение соединений посредством нисходящей денормализации редко оправдывает затраты на сопровождение дублирующей колонки в таблице "Заказ" (Order). Такие соединения, как правило, не являются глобальной проблемой, а выполнение нисходящей денормализации может привести к возникновению дорогостоящих каскадных обновлений. Об этом говорит сайт https://intellect.icu . Например, если покупатель меняет фамилию, то приходится обновлять все заказы, чтобы отразить это изменение. А нужно ли это делать? Следует ли обновлять старые заказы, которые выполнены или закрыты? Если бы не была проведена денормализация, эти вопросы никогда и не возникли бы.
Нисходящая денормализация оправдана лишь в приложениях, где необходимо устранять операции соединения таблиц. Это имеет место в ХД большого объема. При этом проблем с каскадными обновлениями не возникает, потому что данные в ХД обладают свойством стабильности, т.е. не изменяются после занесения их в ХД.
Восходящая денормализация предлагает перенос колонки из подчиненной (дочерней) таблицы в родительскую таблицу, обычно в форме итоговых данных.
На рис. 19.3 показаны две таблицы – "Заказ" (Order befor) и "Позиция заказа" (Order item befor) – физической модели данных до проведения денормализации, а на рис. 19.4 — эти же таблицы "Заказ" (Order after) и "Позиция заказа" (Order item after) после выполнения восходящей денормализации.
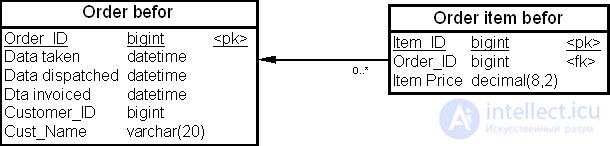
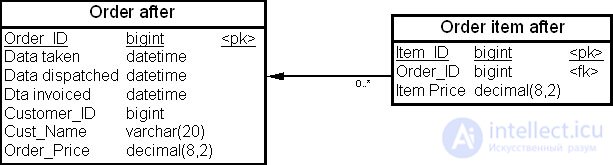
Например, если вычисление общей суммы заказа в системе обработки заказов (суммирование колонок "Цена позиции заказа" (Item_Price) в таблице "Позиции заказа" (Order Item)) приводит к снижению производительности, то мы можем повысить производительность этой операции, поместив сумму заказа в избыточной колонке "Сумма заказа" (Order Price) таблицы "Заказ" (Order after).
В нашем примере в избыточном столбце хранится сумма значений, но восходящая денормализация применима к максимальным, минимальным и средним значениям, а также к другим агрегатным показателям.
Таким образом, восходящая денормализация - это процесс введения избыточных колонок в родительских таблицах с целью устранения операций соединения с операциями агрегирования.
Чтобы представить результат введения денормализации, рассмотрим процедуру сопровождения денормализованных таблиц "Заказ" (Order after) и "Позиция заказа" (Order item after), которые сводятся к поддержке следующих бизнес-правил.
Поддержка перечисленных выше бизнес-правил создает дополнительную нагрузку на процессы, выполняющие DML-операции в таблице "Позиция заказа" (Order item after). Это и есть цена, которую приходится платить за повышение производительности запросов.
Внутритабличная денормализация выполняется в пределах одной таблицы, т.е. это процесс введения избыточных колонок в одной таблице с целью увеличения производительности запроса строки по производному значению. Например, если строка содержит две числовых колонки, X и Y, то значение Z, равное произведению X и Y (Z=X*Y), легко вычислить во время
продолжение следует...
Часть 1 Физическая модель хранилища данных: учет влияния транзакций, денормализация таблиц
Часть 2 Методы разбиения таблиц - Физическая модель хранилища данных: учет влияния
Часть 3 Резюме - Физическая модель хранилища данных: учет влияния транзакций, денормализация
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL