Лекция
Это продолжение увлекательной статьи про хранилища данных и учет влияния транзакций.
...
выполнения.
Предположим, что есть запросы, в которых необходимо осуществить поиск по Z (например, Z принадлежит диапазону от 10 до 20). Сохранив избыточные значения Z в столбце, можно построить индекс по Z, и запросы будут использовать этот индекс. Если индекс по Z строить не надо, то решение о его хранении в отдельном столбце зависит от того, что является более приемлемым — увеличение времени загрузки, вызванное необходимостью постоянно пересчитывать Z, или увеличение времени сканирования, обусловленное удлинением строк таблицы за счет хранения дополнительной колонки.
Приведем еще один часто встречающийся пример внутритабличной нормализации. Допустим, что одинаковый текст хранится в двух видах: с символами в верхнем и в нижнем регистре — для отображения в отчетах и на экране, и с символами в верхнем регистре — для обеспечения работы ускоренных запросов без учета регистра.
Отметим, что обеспечить приемлемую производительность для таблиц умеренного размера (до 10000 строк) в последнем случае можно и без внутритабличной нормализации, переработав запрос с применением встроенной функции UPPER.
Внутритабличная нормализация редко используется при проектировании ХД.
Денормализация методом "разделяй и властвуй" – это процесс разбиения нормализованной таблицы на две таблицы и более и создание между ними отношения "один к одному" с целью устранения дополнительных операций ввода-вывода или по техническим причинам.
Использование этого приема обычно носит причины технического характера. Как правило, этот метод применяется для денормализации таблиц, содержащих колонки с данными типа text или varbinary (max), размер которых может составлять 64К и более.
Иногда лучше вынести такую колонку в отдельную таблицу. Рассмотрим таблицу, строки которой содержат в начале ключевые колонки, потом неключевые колонки, а в конце – колонку типа varbinary (max). Предположим, что в большинстве строк колонка типа varbinary (max) содержит данные. Если нет индексов по неключевым столбцам, то при выполнении запросов по любому из этих столбцов СУБД обычно будет осуществлять полное сканирование таблицы. При этом из-за наличия в таблице колонки типа varbinary (max) понадобятся дополнительные операции ввода-вывода.
Чтобы устранить эту проблему, необходимо разделить таблицу так, как показано на рис. 19.5.

В некоторых СУБД таблица не может иметь более 254 столбцов, и если для представления данных нужна таблица с большим числом столбцов, то также возникнет причина для разделения такой таблицы на две. Как правило, такие таблицы возникают в следующих случаях;
Согласно мнению известного специалиста в области проектирования реляционных БД Д. Энсора, "хорошей мерой степени нормализации является число столбцов на таблицу. Эмпирическое правило гласит, что "очень немногие первичные ключи имеют более двадцати действительно зависимых от них атрибутов".
Денормализация методом слияния таблиц – это процесс объединения двух или более нормализованных таблиц с целью устранения операций соединений или уменьшения в некоторых случаях числа операций вставки.
Возникает резонный вопрос: зачем после того, как вложено столько сил в нормализацию структур данных и разбивку сущностей, предлагается начать слияние таблиц? Фактически, слияние оправдано в очень немногих случаях.
Один из примеров обоснованного применения слияния — наличие повторяющейся группы, которая гарантированно состоит из фиксированного числа элементов. Хорошими кандидатами на такое объединение являются таблицы со строкой для каждого месяца года или каждого дня недели. Единственный случай, когда фиксированные группы надежны,— это когда они соответствуют абсолютно постоянным вещам, например, дням недели.
Будет ли какое-либо преимущество от такого слияния, заранее сказать трудно. Подход к денормализации должен определяться требованиями к обработке данных.
Альтернатива данному способу денормализации – физическое размещение таблиц в кластере БД (как например, в СУБД семейства Oracle). Это позволяет хранить рядом строки логически связанных отдельных таблиц.
Таким образом, на практике денормализация представляет собой набор приемов преобразования таблиц с целью повышения производительности обработки запросов. С точки зрения реляционной теории, мы как бы не принимаем в рассмотрение вынесение некоторых функциональных зависимостей в отдельные сущности-таблицы. Основным критерием проведения денормализации нормализованных таблиц являются требования к обработке данных. В реляционных БД следует избегать неоправданной денормализации таблиц.
Разбиение таблиц (splitting partition) является одним из общих методов денормализации, который применяется в физическом проектировании ХД. Разбиение таблиц бывает двух видов – вертикальное разбиение и горизонтальное разбиение.
Вертикальное разбиение (vertically partition) является процессом перемещения некоторых колонок таблицы в другую новую таблицу, которая имеет тот же первичный ключ, что и исходная таблица.
Горизонтальное разбиение (horizontally partition) является процессом перемещения некоторых строк одной таблицы в другую новую таблицу, которая имеет такую же внутреннюю структуру, что и исходная таблица.
Основные причины разбиения таблицы: либо существуют определенные проблемы с производительностью запросов на этой таблице, либо непересекающиеся подмножества строк таблицы имеют значительное различие в производительности обработки, т.е. подмножества строк таблицы редко встречаются в одном и том же запросе.
Проблемы с производительностью выполнения запросов на длинных строках таблицы являются наиболее частой причиной для выполнения вертикального разбиения таблицы. Критериями того, что строка считается длинной, может быть следующее:
Рассмотрим случай, когда длина строки больше размера физической страницы БД. Здесь либо таблица имеет слишком много колонок, либо некоторые колонки имеют большую длину. В этом случае СУБД при вставке строки в таблицу будет использовать одну или более дополнительных физических страниц для сохранения строки. Следовательно, при выборке строки из таблицы потребуется больше операций ввода-вывода на число дополнительных физических страниц. Производительность запроса при этом будет ухудшаться. Для увеличения производительности выборки можно разбить таблицу на одну или несколько таблиц с длиной строки подходящего размера.
Метод вертикального разбиения принципиально прост, если вспомнить, что разбиение эквивалентно реляционной операции проекции на таблице. Ясно, что некоторые колонки просто переносятся в новую таблицу так, чтобы длина оставшейся строки была подходящей (< 1 КБ). Разбиение не должно нарушать функциональных зависимостей между колонками. Поскольку мы предполагаем, что исходная таблица нормализована (в частности, все неключевые колонки функционально полно зависят от первичного ключа), первичный ключ новой таблицы является точной копией первичного ключа исходной таблицы.
Критичным вопросом является вопрос, какие колонки следует переносить в новую таблицу. При разбиении таблицы увеличение производительности будет достигаться только при раздельном доступе к полученным таблицам. При соединении полученных таблиц производительность такого запроса может быть ниже, чем с тем же запросом к исходной таблице, из-за дополнительного ввода-вывода. Поэтому, до того как принять решение о разбиении таблицы, необходимо проанализировать все транзакции к исходной таблице с высоким приоритетом и при разнесении колонок по таблицам руководствоваться принципом: частота совместного использования колонок в запросах, размещенных в каждой таблице разбиения, должна быть достаточно высока.
Пример 19.5.
Предположим, что в таблице "Служащие" (EMPLOYEE) необходимо дополнительно сохранять фотографию сотрудника и его автобиографию ( рис. 19.6). Эти два новых поля имеют достаточно большой размер, и длина строки таблицы заведомо превысит 1 КБ.

Далее предположим, что существует 60 транзакций, которые обращаются к этой таблице. Только четыре из них обращаются ко всем колонкам: при вводе данных о сотруднике при приеме на работу, при внесении изменений, при удалении информации о сотруднике в связи с его увольнением и запрос руководителя, который имеет высокий приоритет. Все транзакции, кроме одной, указанной выше, имеют средний и низкий приоритеты. Частота транзакции с высоким приоритетом ожидается не превышающей 2 раз в неделю. Поэтому разбиение таблицы на две не сильно повлияет на производительность транзакций с высоким приоритетом в базе данных в целом.
Частота использования полей в транзакциях приведена в табл. 19.1.
| № | Наименование атрибута | Наименование колонки | Частота использования полей в транзакциях |
|---|---|---|---|
| 1 | Номер личной карточки | EMPNO (PK) | 60 |
| 2 | Фамилия | ENAME | 60 |
| 3 | Имя | LNAME | 50 |
| 4 | Номер подразделения | DEPNO | 50 |
| 5 | Должность | JOB | 20 |
| 6 | Дата рождения | AGE | 4 |
| 7 | Стаж | HIREDATE | 4 |
| 8 | Доплаты | COMM | 50 |
| 9 | Зарплата | SAL | 50 |
| 10 | Штрафы | FINE | 50 |
| 11 | Автобиография | Biog | 4 |
| 12 | Фотография | Foto | 4 |
Табл. 19.1 не содержит частоты совместного использования колонок в транзакциях, но из частот использования полей в транзакциях можно сделать вывод о совместном использовании колонок. Вероятнее всего, колонки, имеющие близкие значения частот использования, используются и совместно.
Таким образом, имеется основание для принятия решения о разбиении таблицы "Служащие" (EMPLOYEE) на две — скажем, "Служащие" (EMPLOYEE_BASE) и "Дополнительные данные" (ADD_EMPL), как показано на рис. 19.7.
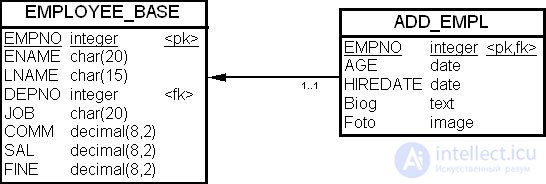
Последовательность команд SQL для создания вертикального разбиения таблицы "Служащие" приведена ниже.
create table ADD_EMPL (
EMPNO integer not null,
AGE date null,
HIREDATE date not null with default,
Biog text null,
Foto image null,
constraint PK_ADD_EMPL primary key (EMPNO)
)
go
create table EMPLOYEE_BASE (
EMPNO integer not null,
ENAME char(20) null,
LNAME char(15) null,
DEPNO integer null,
JOB char(20) null,
COMM decimal(8,2) null,
SAL decimal(8,2) null,
FINE decimal(8,2) null,
constraint PK_EMPLOYEE_BASE primary key (EMPNO)
)
go
alter table ADD_EMPL
add constraint FK_ADD_EMPL_REFERENCE_EMPLOYEE foreign key (EMPNO)
references EMPLOYEE_BASE (EMPNO)
go
alter table EMPLOYEE_BASE
add constraint FK_EMPLOYEE_REFERENCE_DEPARTAMENT (DEPNO)
references DEPARTAMENT (DEPNO)
go
Мы определили ограничение ссылочной целостности между таблицами "Служащие" (EMPLOYEE_BASE) и "Дополнительные данные" (ADD_EMPL) с помощью команды ALTER TABLE, поэтому она будет поддерживаться встроенными механизмами СУБД MS SQL Server 2008.
Помимо повышения производительности операций выборки в качестве обоснования вертикального разбиения таблиц следует указать на повышение производительности при операциях вставки и удаления, а также при операциях резервного копирования и восстановления БД или ХД.
Во многих реляционных СУБД поддерживаются так называемые хеш-кластерные индексы (clustered hashed index). Такие объекты правильнее называть таблицами хеширования, а не индексами. Таблица хеширования представляет собой таблицу реляционной БД, доступ к строкам которой осуществляется с помощью преобразования ключа. Значения колонок, которые объявлены ключевыми, преобразуются в позиции строк таблицы (и при их вставке там и размещаются) – хешируются. Такую функцию называют хеш-функцией. Ключ таблицы, который подвергается преобразованию, называется хеш-ключом.
Данные, которые обрабатываются таким образом, размещаются в специальных таблицах, называемых еще хеш-кластерами или просто хеш-таблицами. В настоящей лекции предполагается, что проектировщику известны общие методы организации физического доступа к данным, поэтому мы не будем детально обсуждать вопрос, как устроены такие таблицы.
Отметим, что хеширование является очень эффективным методом доступа по первичному ключу к записи за один доступ. Если значения ключа равномерно распределены, то в среднем это будет так. В противном случае производительность доступа будет резко падать из-за коллизий — случаев, когда для двух различных значений первичного ключа хеш-функция дает одинаковые числа, т.е. позиции записи. В худшем случае придется просканировать всю таблицу, чтобы получить одну запись.
Несмотря на то, что построены динамические таблицы хеширования (изменяющие свой размер во время существования), в большинстве СУБД поддерживаются статические таблицы хеширования, размер которых определяется при их создании. В большинстве случаев таблица хеширования формируется случайным образом по отношению к порядку следования значений ключа, хотя известны функции преобразования ключа, которые поддерживают лексикографический порядок на значении ключа таблицы.
Хеш-индекс обычно применяется, если ключ полностью представлен в предложении WHERE и используется операция равенства для колонок ключа.
Нас интересует проблема увеличения производительности в хеш-таблицах, когда длина строки превышает размер физической страницы на жестком диске. Чтобы лучше понять проблему, рассмотрим, как определяется хеш-таблица в SQL.
Такая таблица создается при помощи команды, например (как в СУБД SQLBase):
CREATE CLUSTERED HASHES INDEX CHXNAME ON EMPLOYEE (EMPNO) SIZE 2000 ROWS;
Предложение SIZE задает вероятное количество строк в индексе, а ROWS определяет число строк для хранения индекса. Размер можно задавать в блоках ( BUCKETS ). Таким образом, по значению первичного ключа адресуется блок, содержащий целое число строк, или строка, если ее размер сопоставим с размером физического блока. В последнем случае считается, что блок содержит одну строку.
Для таблицы хеширования определяется параметр "число строк на странице" (rows per page), или кластеризация страницы (page clustering)), или коэффициент блокировки, равный

Как видно из определения таблицы хеширования, размер строки и размер физического блока должны быть согласованы. Проблема длинной строки в таблице хеширования состоит в том, что если строка занимает несколько блоков, то возрастает частота коллизий и вместо одного физического доступа для получения строки требуется 4-6, что уже сопоставимо с использованием индексов другого типа.
Цель разбиения таблицы хеширования состоит в том, чтобы попытаться достигнуть такого значения коэффициента блокировки ( blocking factor ), при котором таблица содержала бы как можно больше строк, выбирающихся вместе в большинстве транзакций к этой таблице.
Поскольку в современных СУБД размер физического блока фиксирован для каждой операционной платформы, единственным способом влияния на величину этого параметра является подгонка размера строки. Если нельзя пересмотреть спецификацию типов колонок таблицы и свести их размеры до минимума, то единственной возможностью выбрать подходящий коэффициент блокировки является разбиение таблицы хеширования.
В СУБД семейства MS SQL Server таблицы хеширования не поддерживаются в явном виде. Однако они могут быть созданы с помощью функции CHECKSUM() и вычисляемой колонки в индексе. Индекс должен быть неуникальным, чтобы было возможно разрешать коллизии хеш-функции.
На практике горизонтальное разбиение (horizontally partition) применяется для изоляции одной группы строк таблицы от другой, когда использование этих групп строк в транзакциях почти не пересекается. Типичный пример — изоляция текущих данных от архивных данных.
Рассмотрим систему обработки заказов. Менеджеры и продавцы работают с текущими заказами. Обработка выполненных заказов (архивные данные) выполняется при подготовке разного рода отчетов (в частности, путем создания киоска данных). Даже если готовится ежедневный отчет с обращением к архивным данным, то в организациях среднего размера частота использования текущих данных все равно превышает частоту использования архивных данных на 2-3 порядка, а отношение объема текущих данных к архивным данным может составлять менее 0.001.
Одним из практических критериев в данном случае может служить классическое правило 80-20. Если активно работают с 20-ю процентами данных, то вероятнее всего, остальные 80% можно перенести в архивную таблицу.
Пример 19.6.
Таблицей – кандидатом на горизонтальное разбиение является таблица "Проект" (PROJECT), структура которой показана на рис. 19.8. В этой таблице хранятся архивные данные – выполненные проекты.
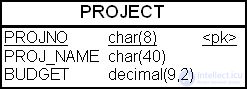
Предположим, что число выполненных проектов в год в организации где-то около 1000. Данные в таблицы нужно хранить 10 лет (10000 записей). Средняя продолжительность проекта равна двум месяцам, т. е. число незавершенных проектов в данный момент времени не превышает 200. Через 5 лет отношение числа текущих проектов к архивным проектам достигнет 0.04.
Следовательно, можно рассмотреть вопрос о горизонтальном разбиении этой таблицы и выполнить его, как показано на рис. 19.9.

Мы разбили таблицу "Проект" (PROJECT) горизонтально на две таблицы — "Текущие проекты" (PROJECT_CUR) и "Архивные проекты" (PROJECT_OLD). Последовательность команд для создания таблиц разбиения приведена ниже.
create table PROJECT_CUR ( PROJNO char(8) not null, PROJ_NAME char(40) not null, BUDGET decimal(9,2) not null, constraint PK_PROJECT_CUR primary key (PROJNO) ) go create table PROJECT_OLD ( PROJNO char(8) not null, PROJ_NAME char(40) not null, BUDGET decimal(9,2) not null, constraint PK_PROJECT_OLD primary key (PROJNO) ) go
Для совместного использования двух этих таблиц можно предусмотреть представление "Все проекты" ( ALL_PROJECT ), которое показано на рис. 19.10.

Команда SQL для создания представления "Все проекты" ( ALL_PROJECT ) приведена ниже.
CREATE VIEW ALL_PROJECT AS SELECT PROJNO, PROJ_NAME, BUDGET FROM PROJECT_CUR UNION SELECT PROJNO, PROJ_NAME, BUDGET FROM PROJECT_OLD;
Заметим, что далее по тексту под исходной таблицей понимается и сама таблица, и то, во что она превратилась после разбиения.
Если до разбиения таблица была нормализована, то первичные ключи будут идентичны для таблиц, полученных в результате разбиения. Следовательно, взаимосвязи новых таблиц с другими таблицами базы данных могут остаться такими же, как и с первоначальной таблицей. Однако необходимо рассмотреть и действие правил удаления для исходной таблицы, и участие новой таблицы в существующих взаимоотношениях ссылочной целостности, когда будет решаться вопрос об определении поддержки ссылочной целостности в новых таблицах.
В некоторых случаях может быть проще не определять ссылочную целостность вовсе, так как фактическое удаление строк из новой таблицы будет поддерживаться параллельно с исходной таблицей каким-либо программным способом в приложении БД (например, с
продолжение следует...
Часть 1 Физическая модель хранилища данных: учет влияния транзакций, денормализация таблиц
Часть 2 Методы разбиения таблиц - Физическая модель хранилища данных: учет влияния
Часть 3 Резюме - Физическая модель хранилища данных: учет влияния транзакций, денормализация
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL