Лекция
Привет, Вы узнаете о том , что такое nosql, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое nosql , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
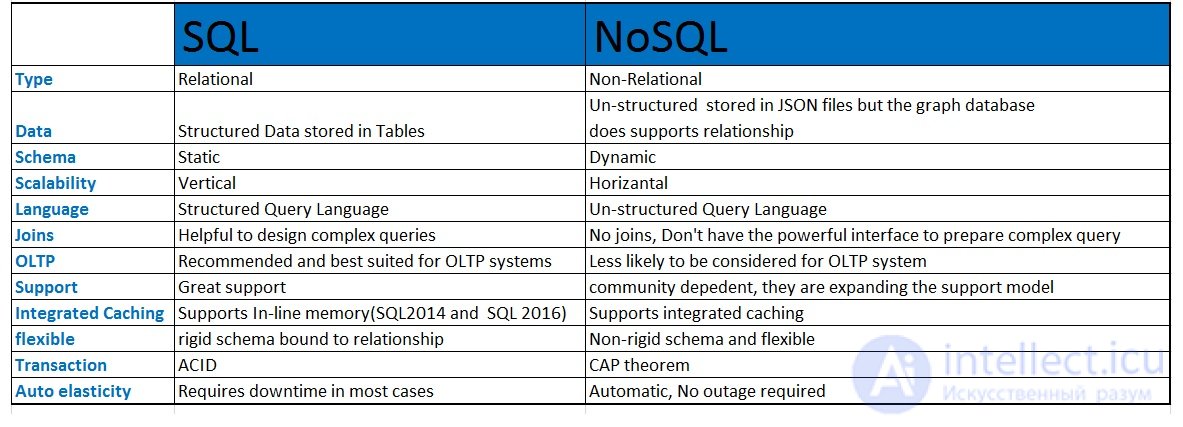
NoSQL (от англ. not only SQL — не только SQL) — обозначение широкого класса разнородных систем управления базами данных, появившихся в конце 2000-х — начале 2010-х годов, существенно отличающихся от традиционных реляционных СУБД с доступом к данным средствами языка SQL. Применяется к системам, в которых делается попытка решить проблемы масштабируемости и доступности за счет полного или частичного отказа от требований атомарности и согласованности данных .
NoSQL (первоначально со ссылкой на «не - SQL » или «не-реляционный») база данных обеспечивает механизм для хранения и извлечения данных , которые смоделированы в других , чем табличные отношениях , используемых в средствах реляционных баз данных . Такие базы данных существуют с конца 1960-х годов, но название «NoSQL» было придумано только в начале 21 века , вызванное потребностями компаний Web 2.0 . Базы данных NoSQL все чаще используются в больших данных и веб- приложениях реального времени . Системы NoSQL также иногда называют «Не только SQL» , чтобы подчеркнуть , что они могут поддерживать SQL - подобные языкам запросов или сидеть рядом с базами данных SQL в разноязычных-стойких архитектурах.
Мотивы для этого подхода включают: простоту дизайна , более простое «горизонтальное» масштабирование до кластеров машин (что является проблемой для реляционных баз данных), более тонкий контроль над доступностью и ограничение объектно-реляционного несоответствия импеданса . Структуры данных, используемые базами данных NoSQL (например, пара ключ-значение , широкий столбец , граф или документ.) отличаются от тех, которые используются по умолчанию в реляционных базах данных, что ускоряет некоторые операции в NoSQL. Конкретная пригодность данной базы данных NoSQL зависит от проблемы, которую она должна решить. Иногда структуры данных, используемые базами данных NoSQL, также рассматриваются как «более гибкие», чем таблицы реляционных баз данных.
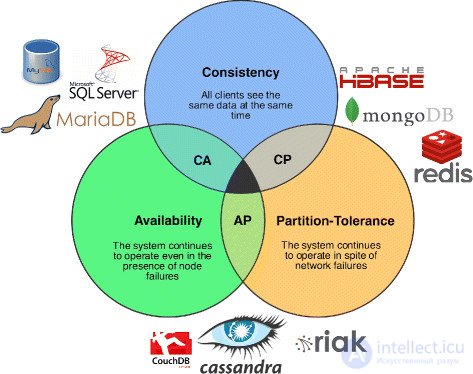
Многие хранилища NoSQL ставят под угрозу согласованность (в смысле теоремы CAP ) в пользу доступности, устойчивости к разделам и скорости. Барьеры для более широкого внедрения хранилищ NoSQL включают использование низкоуровневых языков запросов (например, вместо SQL), отсутствие возможности выполнять специальные соединения между таблицами, отсутствие стандартизованных интерфейсов и огромные предыдущие инвестиции в существующие реляционные базы данных. . [10] В большинстве хранилищ NoSQL отсутствуют настоящие ACID- транзакции, хотя некоторые базы данных сделали их центральными в своих проектах.
Вместо этого большинство баз данных NoSQL предлагают концепцию « конечной согласованности », при которой изменения базы данных распространяются на все узлы «в конечном итоге» (обычно в пределах миллисекунд), поэтому запросы данных могут не возвращать обновленные данные немедленно или могут привести к чтению данных, которые неточно, проблема известна как устаревшие чтения. Кроме того, в некоторых системах NoSQL могут наблюдаться потери записи и другие формы потери данных . Некоторые системы NoSQL предоставляют такие концепции, как ведение журнала с упреждающей записью, чтобы избежать потери данных. Для распределенной обработки транзакцийв нескольких базах данных согласованность данных - еще большая проблема, которая сложна как для NoSQL, так и для реляционных баз данных. Реляционные базы данных «не позволяют ограничениям ссылочной целостности охватывать базы данных». Немногие системы поддерживают как транзакции ACID, так и стандарты X / Open XA для распределенной обработки транзакций.Интерактивные реляционные базы данных имеют общие методы конформационного релейного анализа. Ограничения в интерфейсной среде преодолеваются с помощью протоколов семантической виртуализации, так что службы NoSQL доступны для большинства операционных систем.
Изначально слово NoSQL являлось акронимом из двух слов английского языка: No («Не») и SQL (сокращение от англ. Structured Query Language — «структурированный язык запросов»), что дает термину смысл «отрицающий SQL». Возможно, что первые, кто стал употреблять этот термин, хотели сказать «No RDBMS» («не реляционная СУБД») или «no relational» («не реляционный»), но NoSQL звучало лучше и в итоге прижилось (в качестве альтернативы предлагалось также NonRel). Позднее для NoSQL было придумано объяснение «Not Only SQL» («не только SQL»). NoSQL стал общим термином для различных баз данных и хранилищ, но он не обозначает какую-либо одну конкретную технологию или продукт .
Сама по себе идея нереляционных баз данных не нова, а использование нереляционных хранилищ началось еще во времена первых компьютеров. Нереляционные базы данных процветали во времена мэйнфреймов, а позднее, во времена доминирования реляционных СУБД, нашли применение в специализированных хранилищах, например, иерархических службах каталогов. Появление же нереляционных СУБД нового поколения произошло из-за необходимости создания параллельных распределенных систем для высокомасштабируемых интернет-приложений, таких как поисковые системы .
В начале 2000-х годов Google построил свою высокомасштабируемую поисковую систему и приложения: GMail, Google Maps, Google Earth и т. п., решая проблемы масштабируемости и параллельной обработки больших объемов данных. В результате была создана распределенная файловая система и распределенная система координации, хранилище семейств колонок (англ. column family store), среда выполнения, основанная на алгоритме MapReduce. Публикация компанией Google описаний этих технологий привела к всплеску интереса среди разработчиков открытого программного обеспечения, в результате чего был создан Hadoop и запущены связанные с ним проекты, призванные создать подобные Google технологии. Через год, в 2007 году, примеру Google последовал Amazon.com, опубликовав статьи о высокодоступной базе данных Amazon DynamoDB .
Поддержка гигантов индустрии менее чем за пять лет привела к широкому распространению технологий NoSQL (и подобных) для управления «большими данными», а к делу присоединились другие большие и маленькие компании, такие как: IBM, Facebook, Netflix, eBay, Hulu, Yahoo!, со своими проприетарными и открытыми решениями .
Традиционные СУБД ориентируются на требования ACID к транзакционной системе: атомарность (англ. atomicity), согласованность (англ. consistency), изолированность (англ. isolation), долговечность(англ. durability), тогда как в NoSQL вместо ACID может рассматриваться набор свойств BASE :
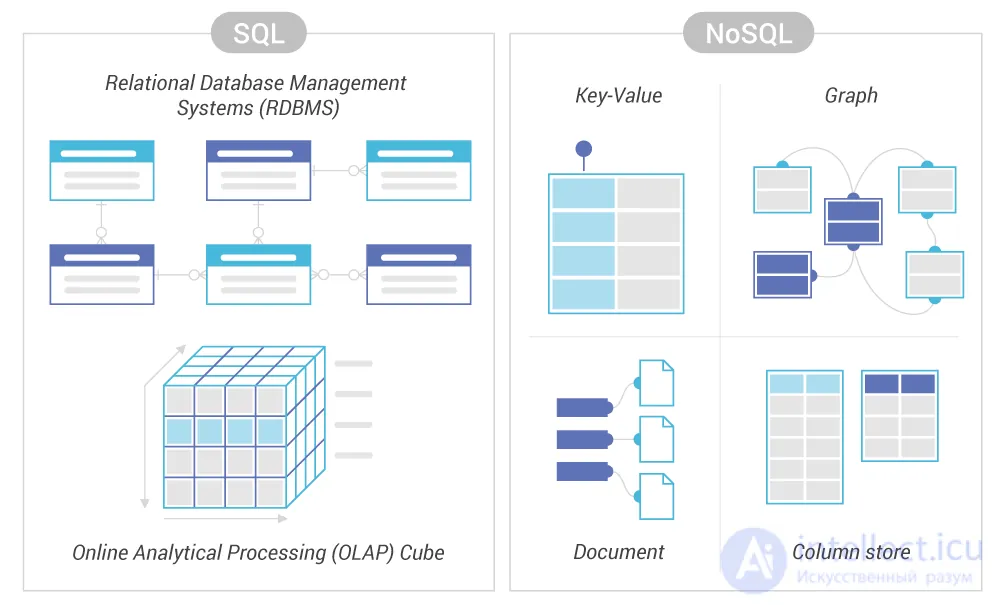
Термин «BASE» был предложен Эриком Брюером, автором теоремы CAP, согласно которой в распределенных вычислениях можно обеспечить только два из трех свойств: согласованность данных, доступность или устойчивость к разделению .
Разумеется, системы на основе BASE не могут использоваться в любых приложениях: для функционирования биржевых и банковских систем использование транзакций является необходимостью. В то же время, свойства ACID, какими бы желанными они ни были, практически невозможно обеспечить в системах с многомиллионной веб-аудиторией, вроде amazon.com . Таким образом, проектировщики NoSQL-систем жертвуют согласованностью данных ради достижения двух других свойств из теоремы CAP . Некоторые СУБД, например, Riak, позволяют настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов путем задания количества узлов, необходимых для подтверждения успеха транзакции.
Решения NoSQL отличаются не только проектированием с учетом масштабирования. Другими характерными чертами NoSQL-решений являются :
Описание схемы данных в случае использования NoSQL-решений может осуществляться через использование различных структур данных: хеш-таблиц, деревьев и других.
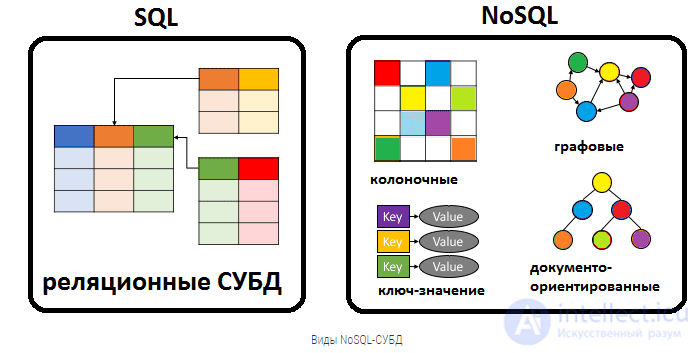
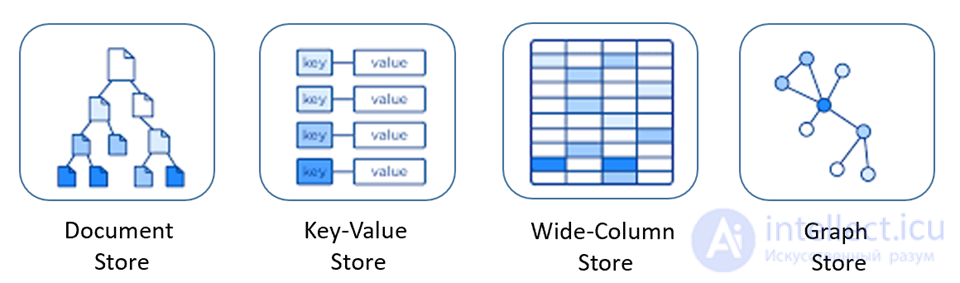
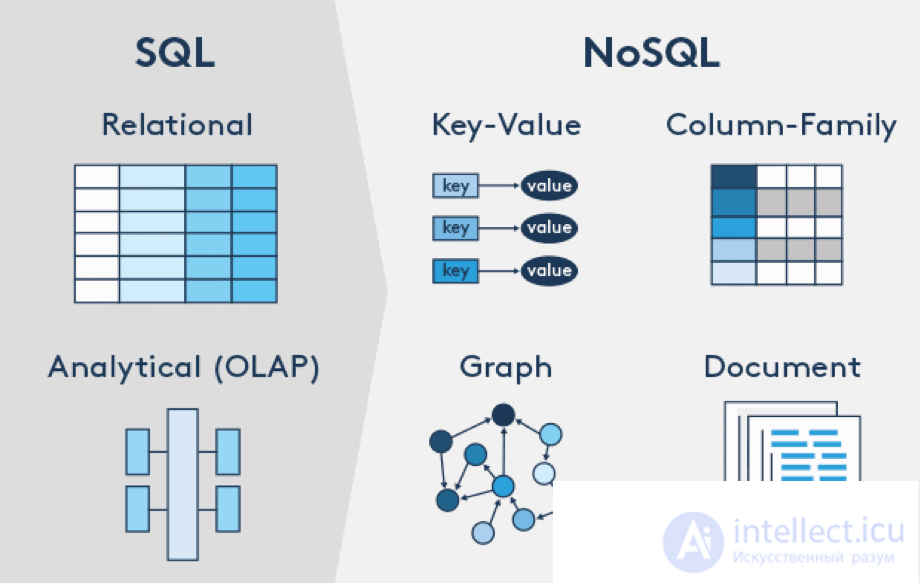
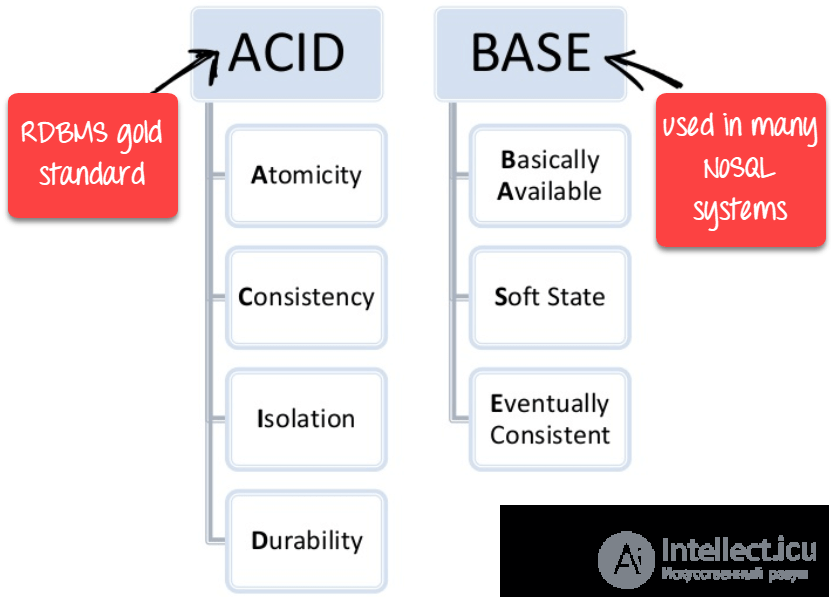
В зависимости от модели данных и подходов к распределенности и репликации в NoSQL-движении выделяются четыре основных типа систем: «ключ — значение» (англ. key-value store), документоориентированные (document store), «семейство столбцов» (column-family store), графовые.
Модель «ключ — значение» является простейшим вариантом, использующим ключ для доступа к значению. Об этом говорит сайт https://intellect.icu . Такие системы используются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в системах, спроектированных с прицелом на масштабируемость. Примеры таких хранилищ — Berkeley DB, MemcacheDB[en], Redis, Riak, Amazon DynamoDB .
Другой тип систем — «семейство столбцов», прародитель этого типа — система Google BigTable. В таких системах данные хранятся в виде разреженной матрицы, строки и столбцы которой используются как ключи. Типичным применением этого типа СУБД является веб-индексирование, а также задачи, связанные с большими данными, с пониженными требованиями к согласованности. Примерами СУБД данного типа являются: Apache HBase, Apache Cassandra, ScyllaDB[en], Apache Accumulo , Hypertable
Системы типа «семейство столбцов» и документно-ориентированные системы имеют близкие сценарии использования: системы управления содержимым, блоги, регистрация событий. Использование временных меток позволяет использовать этот вид систем для организации счетчиков, а также регистрации и обработки различных данных, связанных со временем .
В отличие от столбцового хранения (англ. column-oriented DBMS), применяемого в некоторых реляционных СУБД, хранящих данные по столбцам в сжатом виде для эффективности в OLAP-сценариях, модель «семейство столбцов» хранит данные построчно, и обеспечивает высокую производительность, прежде всего, в оперативных сценариях, тогда как для запросов, требующих обхода большого объема данных с агрегацией результатов, как правило, неэффективна .
Документоориентированные СУБД служат для хранения иерархических структур данных. Находят свое применение в системах управления содержимым, издательском деле, документальном поиске. Примеры СУБД данного типа — CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML .
Графовые СУБД применяются для задач, в которых данные имеют большое количество связей, например, социальные сети, выявление мошенничества. Примеры: Neo4j, OrientDB, AllegroGraph[en], Blazegraph[10], InfiniteGraph, FlockDB, Titan .
Так как ребра графа материализованы (англ. materialized), то есть, являются хранимыми, обход графа не требует дополнительных вычислений (как соединение в SQL), но для нахождения начальной вершины обхода требуется наличие индексов. Графовые СУБД как правило поддерживают ACID, а также поддерживают специализированные языки запросов, такие как Gremlin, Cypher, SPARQL, GraphQL[en].
В июле 2011 компания Couchbase, разработчик CouchDB, Memcached и Membase, анонсировала создание нового SQL-подобного языка запросов — UnQL (Unstructured Data Query Language). Работы по созданию нового языка выполнили создатель SQLite Ричард Гипп (англ. Richard Hipp) и основатель проекта CouchDB Дэмиен Кац (англ. Damien Katz). Разработка передана сообществу на правах общественного достояния
Термин NoSQL был использован Карло Строцци в 1998 году для обозначения своей облегченной реляционной базы данных с открытым исходным кодом Strozzi NoSQL, которая не предоставляла стандартный интерфейс языка структурированных запросов (SQL), но по-прежнему оставалась реляционной. [18] Его СУБД NoSQL отличается от общей концепции баз данных NoSQL 2009 года. Строцци предполагает, что, поскольку текущее движение NoSQL «полностью отходит от реляционной модели, его следовало бы назвать более подходящим« NoREL »» [19], имея в виду «нереляционный ».
Йохан Оскарссон, в то время разработчик Last.fm , повторно ввел термин NoSQL в начале 2009 года, когда организовал мероприятие для обсуждения « распределенных нереляционных баз данных с открытым исходным кодом ». [20] Название было попыткой обозначить появление растущего числа нереляционных распределенных хранилищ данных, включая клоны Bigtable / MapReduce от Google и DynamoDB от Amazon .
Существуют различные способы классификации баз данных NoSQL с различными категориями и подкатегориями, некоторые из которых частично совпадают. Ниже приводится базовая классификация по моделям данных с примерами:
Ниже приводится более подробная классификация, основанная на предложении Стивена Йена: [21] [22]
| Тип | Известные примеры этого типа |
|---|---|
| Кэш "ключ-значение" | Apache Ignite , Couchbase , Coherence , eXtreme Scale , Hazelcast , Infinispan , Memcached , Redis , Velocity |
| Хранилище "ключ-значение" | Azure Cosmos DB , ArangoDB , Aerospike , Couchbase , Redis |
| Хранилище "ключ-значение" (в конечном итоге согласованное) | Azure Cosmos DB , база данных Oracle NoSQL , Dynamo , Riak , Voldemort |
| Хранилище "ключ-значение" (в порядке) | FoundationDB , InfinityDB , LMDB , MemcacheDB |
| Магазин кортежей | Река Апачей , GigaSpaces |
| База данных объектов | Объективность / DB , Прест , ZopeDB |
| Хранилище документов | Azure Cosmos DB , ArangoDB , BaseX , Clusterpoint , Couchbase , CouchDB , DocumentDB , eXist-db , IBM Domino , MarkLogic , MongoDB , Qizx , RethinkDB , Elasticsearch |
| Магазин с широкой колонной | Azure Cosmos DB , Amazon DynamoDB , Bigtable , Cassandra , Google Cloud Datastore , HBase , Hypertable , Scylla |
| Родная многомодельная база данных | ArangoDB , Azure Cosmos DB , OrientDB , MarkLogic |
Базы данных корреляции не зависят от модели и вместо хранилища на основе строк или столбцов используют хранилище на основе значений.
Хранилища типа "ключ-значение" (KV) используют ассоциативный массив (также называемый картой или словарем) в качестве своей фундаментальной модели данных. В этой модели данные представлены как набор пар ключ-значение, так что каждый возможный ключ появляется в коллекции не более одного раза. [23] [24]
Модель «ключ – значение» - одна из простейших нетривиальных моделей данных, и более обширные модели данных часто реализуются как ее расширение. Модель "ключ-значение" может быть расширена до дискретно упорядоченной модели, которая поддерживает ключи в лексикографическом порядке . Это расширение является мощным в вычислительном отношении, поскольку оно может эффективно извлекать выборочные диапазоны ключей . [25]
Хранилища "ключ-значение" могут использовать модели согласованности, начиная от согласованности в конечном итоге до сериализуемости . Некоторые базы данных поддерживают порядок ключей. Существуют различные аппаратные реализации, и некоторые пользователи хранят данные в памяти (RAM), а другие - на твердотельных накопителях (SSD) или вращающихся дисках (также известных как жесткий диск (HDD)).
Центральным понятием хранилища документов является понятие «документ». Хотя детали этого определения различаются для документно-ориентированных баз данных, все они предполагают, что документы инкапсулируют и кодируют данные (или информацию) в некоторых стандартных форматах или кодировках. Используемые кодировки включают XML, YAML и JSON, а также двоичные формы, такие как BSON . Документы адресуются в базе данных с помощью уникального ключа, который представляет этот документ. Другой определяющей характеристикой документно-ориентированной базы данных является API или язык запросов для извлечения документов на основе их содержимого.
Различные реализации предлагают разные способы организации и / или группировки документов:
По сравнению с реляционными базами данных коллекции можно считать аналогами таблиц и документов, аналогичных записям. Но они разные: каждая запись в таблице имеет одинаковую последовательность полей, а документы в коллекции могут иметь совершенно разные поля.
Графические базы данных предназначены для данных, отношения которых хорошо представлены в виде графа, состоящего из элементов, соединенных конечным числом отношений. Примеры данных включают социальные отношения, маршруты общественного транспорта, дорожные карты, топологии сети и т. Д.
Графические базы данных и их язык запросов
| Имя | Язык (и) | Примечания |
|---|---|---|
| АллегроГраф | SPARQL | RDF тройной магазин |
| Амазонка Нептун | Гремлин , SPARQL | База данных графиков |
| ArangoDB | AQL, JavaScript , GraphQL | Документ многомодельной СУБД , база данных графиков и хранилище ключей и значений |
| Azure Cosmos DB | Гремлин | База данных графиков |
| DEX / Sparksee | C ++ , Java , C # , Python | База данных графиков |
| FlockDB | Scala | База данных графиков |
| IBM DB2 | SPARQL | В DB2 10 добавлено тройное хранилище RDF |
| InfiniteGraph | Ява | База данных графиков |
| MarkLogic | Java , JavaScript , SPARQL , XQuery | Multi-модель база данных документов и RDF тройной магазин |
| Neo4j | Сайфер | База данных графиков |
| OpenLink Virtuoso | C ++ , C # , Java , SPARQL | Гибрид промежуточного программного обеспечения и ядра СУБД |
| Oracle | SPARQL 1.1 | Тройной магазин RDF добавлен в 11g |
| OrientDB | Java , SQL | База данных многомодельных документов и графиков |
| OWLIM | Java , SPARQL 1.1 | RDF тройной магазин |
| Profium Sense | Java , SPARQL | RDF тройной магазин |
| Sqrrl Enterprise | Ява | База данных графиков |
Бен Скофилд оценил различные категории баз данных NoSQL следующим образом: [28]
| Модель данных | Спектакль | Масштабируемость | Гибкость | Сложность | Функциональность |
|---|---|---|---|---|---|
| Хранилище "ключ-значение" | высоко | высоко | высоко | никто | переменная (нет) |
| Колонный магазин | высоко | высоко | умеренный | низкий | минимальный |
| Документально-ориентированный магазин | высоко | переменная (высокая) | высоко | низкий | переменная (низкая) |
| База данных графиков | Переменная | Переменная | высоко | высоко | теория графов |
| Реляционная база данных | Переменная | Переменная | низкий | умеренный | реляционная алгебра |
Сравнение производительности и масштабируемости иногда выполняется с помощью теста YCSB .
Поскольку в большинстве баз данных NoSQL отсутствует возможность объединений в запросах, схему базы данных обычно нужно разрабатывать по-другому. Существует три основных метода обработки реляционных данных в базе данных NoSQL. (См. Таблицу Поддержка соединений и ACID для баз данных NoSQL, поддерживающих соединения.)
Вместо получения всех данных одним запросом обычно выполняется несколько запросов для получения желаемых данных. Запросы NoSQL часто быстрее традиционных запросов SQL, поэтому стоимость дополнительных запросов может быть приемлемой. Если потребуется чрезмерное количество запросов, более подходящим будет один из двух других подходов.
Вместо хранения только внешних ключей обычно хранятся фактические внешние значения вместе с данными модели. Например, каждый комментарий блога может включать имя пользователя в дополнение к идентификатору пользователя, что обеспечивает легкий доступ к имени пользователя без необходимости повторного поиска. Однако при изменении имени пользователя его нужно будет изменить во многих местах базы данных. Таким образом, этот подход работает лучше, когда операции чтения выполняются гораздо чаще, чем записи.
В документных базах данных, таких как MongoDB, обычно помещают больше данных в меньшее количество коллекций. Например, в приложении для ведения блога можно выбрать хранение комментариев в документе сообщения блога, чтобы при однократном извлечении можно было получить все комментарии. Таким образом, при таком подходе один документ содержит все данные, необходимые для конкретной задачи.
База данных помечается как поддерживающая свойства ACID (атомарность, согласованность, изоляция, долговечность) или операции соединения, если в документации к базе данных содержится такое утверждение. Однако это не обязательно означает, что эта возможность полностью поддерживается аналогично большинству баз данных SQL.
| База данных | КИСЛОТА | Присоединяется |
|---|---|---|
| Aerospike | да | Нет |
| Apache Ignite | да | да |
| ArangoDB | да | да |
| Диван | да | да |
| CouchDB | да | да |
| Db2 | да | да |
| InfinityDB | да | Нет |
| LMDB | да | Нет |
| MarkLogic | да | Да [nb 1] |
| MongoDB | да | Да [nb 2] |
| OrientDB | да | Да [№ 3] |
Данная статья про nosql подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое nosql и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL

Комментарии