Лекция
Привет, Вы узнаете о том , что такое извлечение данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое извлечение данных, преобразование данных, загрузка данных, etl , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
ETL (от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка») — один из основных процессов в управлении хранилищами данных, который включает в себя:
С точки зрения процесса ETL, архитектуру хранилища данных можно представить в виде трех компонентов:
В вычислениях извлечение, преобразование загрузка ( ETL ) относится к процессу , в базе данных использования и особенно в хранилищах данных . Процесс ETL стал популярным понятием в 1970 - х годах. [1]Извлечение данных , где данные извлекаются из однородных или разнородных источников данных; преобразование данных , где данные преобразуются для хранения в надлежащем формате или структуры для целей выполнения запросов и анализа; загрузки данных , где данные загружаются в конечную целевую базу данных, более конкретно, операционный хранилище данных , витрины данных или хранилища данных.
Поскольку извлечение данных занимает много времени, он является общим для выполнения три фазы параллельно. В то время как данные извлекаются, другой процесс преобразования выполняет при обработке данных уже получили и готовит его для загрузки в то время как загрузка данных начинается без ожидания завершения предыдущих этапов.
ETL система обычно интеграции данных из нескольких приложений (систем), как правило, разработаны и поддерживаются различными продавцами или размещенных на отдельном компьютерном оборудовании. Разнородные системы, содержащие исходные данные часто управляются и разными сотрудниками. Например, система учета затрат может объединять данные из фонда заработной платы, продажи и покупки.
Первая часть процесса ETL предусматривает извлечение данных из системы источника. Во многих случаях это представляет собой наиболее важный аспект ETL, поскольку извлечение данных правильно устанавливает этап для успеха последующих процессов. Большинство данных складских проектов объединять данные из различных исходных систем. Каждая отдельная система может также использовать различные организации и / или данных формата . Форматы Общих данных источников включают реляционные базы данных , XML и плоские файлы , но могут также включать в себя реляционные структуры базов данных , такие как системы управления информации (IMS) или другие структуры данных , такие как метод Virtual Storage Access (VSAM) или индексированный последовательный метод доступа ( ISAM) , или даже форматов выбирается из посторонних источников с помощью таких средств , как веб - пауков или трафаретной соскоб . Потоковый извлеченного источника данных и загрузки на лету в целевую базу данных еще один способ выполнения ETL , когда не требуется никакого промежуточного хранения данных. В общем, фаза экстракции направлена на преобразование данных в единый формат , подходящий для обработки преобразования.
Внутренняя часть добычи включает в себя проверку данных для того чтобы подтвердить ли данные тянули из источников правильных / ожидаемых значения в данной области (например, как шаблон / по умолчанию или в списке значений). Если данные не удается правила проверки она отвергается полностью или частично. Отвергнутые данные идеально доложили исходную систему для дальнейшего анализа, чтобы выявить и исправить неверные записи. В некоторых случаях сам процесс экстракции, возможно, придется сделать правило проверки данных для того, чтобы принять данные и потока к следующему этапу.
На этапе преобразования данных, ряд правил или функций применяются к извлеченным данным для того, чтобы подготовить его к загрузке в конечной цель. Некоторые данные не требуют каких-либо преобразований вообще; такие данные известен как «прямой ход» или «проходит через» данные.
Важной функцией преобразования является очистка данных, которая стремится передать только «правильные» данные к цели. Проблема, когда различные системы взаимодействуют в соответствующих системах взаимодействующих и сообщающихся. Наборы символов, которые могут быть доступны в одной системе может быть не так в других.
В других случаях, когда одно или более из следующих типов преобразований может потребоваться для удовлетворения потребностей деловых и технических сервера или хранилища данных:
Фазы загрузка загружает данные в конечную цель, которая может быть простой разделителями плоский файл или хранилище данных . Об этом говорит сайт https://intellect.icu . В зависимости от требований организации, этот процесс варьируется в широких пределах. Некоторые хранилища данных могут перезаписать существующую информацию с накопленной информацией; обновление Извлеченные данные часто делается на ежедневной, еженедельной или ежемесячной основе. Другие хранилища данных (или даже другие части того же хранилища данных) может добавить новые данные в исторической форме через регулярные промежутки времени, например, ежечасно. Чтобы понять это, рассмотрим хранилище данных, которое требуется для поддержания продаж записей прошлого года. Это хранилище данных перезаписывает данные старше года с новыми данными. Тем не менее, ввод данных для любого один год окна выполнен в исторической манере. Время и возможности для замены или Append стратегические проектные решения , зависящие от времени , доступных и бизнес - потребностей. Более сложные системы могут поддерживать историю и аудит всех изменений в данных , загруженных в хранилище данных.
Поскольку фаза загрузка взаимодействует с базой данных, ограничения , определены в схеме базы данных - а также в триггерах активированными при загрузке данных - применить (например, уникальность, ссылочной целостности , обязательные для заполнения поля), которые также вносят вклад в общую производительность качества данных процесса ETL.
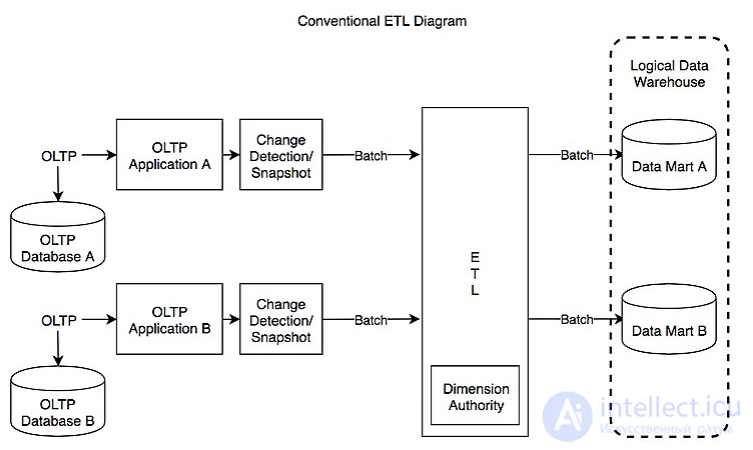
Рисунок Обычный ETL Diagram
Типичный реальные жизненный цикл ETL состоит из следующих этапов выполнения:
ETL-процессы могут включать в себя значительную сложность, а также значительные эксплуатационные проблемы могут возникнуть с неправильно спроектированных систем ETL.
Диапазон значений данных или качества данных в операционной системе может превзойти ожидания дизайнеров во время указаны правил проверки и преобразования. Профилирование данных из источника в процессе анализа данных можно определить условие данных , которые должны быть под управление преобразовывают спецификации правил, что приводит к поправке правил валидации явно и неявно , реализованным в процессе ETL.
Хранилища данных, как правило, собраны из различных источников данных с различными форматами и целями. Таким образом, ETL является ключевым процессом, чтобы привести все данные вместе в стандартной однородной среде.
Анализ Дизайн должен установить масштабируемость в системе ETL по жизни его использования --- включая понимание объемов данных , которые должны быть обработаны в рамках соглашений об уровне обслуживания . Время , доступное для извлечения из исходных систем могут меняться, что может означать то же самое количество данных , возможно , придется быть обработано за меньшее время. Некоторые системы ETL должны масштабировать обрабатывать терабайты данных для обновления хранилищ данных с десятками терабайт данных. Увеличение объемов данных может потребовать конструкции , которые можно масштабировать от ежедневной порции до нескольких дней микро партии к интеграции с очередями сообщений или в режиме реального время с изменением данных-захватом для непрерывного преобразования и обновления.
ETL-поставщиков эталонных их RECORD-системы при многократном ТБ (терабайт) в час (или ~ 1 Гб в секунду) с использованием мощных серверов с несколькими процессорами, несколько жестких дисков, нескольких гигабит сетевых соединений, а также большим объемом памяти.
В реальной жизни, самая медленная часть процесса ETL обычно происходит в фазе загрузки базы данных. Базы данных могут работать медленно, потому что они должны заботиться о параллельности, поддержание целостности и индексов. Таким образом, для более высокой производительности, может иметь смысл использовать:
Тем не менее, даже при использовании массовых операций, доступ к базе данных, как правило, является узким местом в процессе ETL. Некоторые общие методы, используемые для повышения производительности являются:
Независимо от того , чтобы делать определенные операции в базе данных или за ее пределами , может включать в себя компромисс. Например, удаление дубликатов , используя отчетливый может быть медленным в базе данных; Таким образом, имеет смысл сделать это снаружи. С другой стороны, при использовании отличаетсязначительно (х100) уменьшает количество строк , которые будут извлечены, то это имеет смысл , чтобы удалить дупликации как можно раньше , в базе данных перед разгрузкой.
Обычный источник проблем в ETL является большим числом зависимостей между заданиями ETL. Например, задание «B» не может начаться , пока задание «А» еще не закончена. Можно обычно достичь более высокой производительности, визуализируя все процессы на графике, и пытаются уменьшить график , делая максимальное использование параллелизма , и делают «цепочку» последовательной обработки как можно короче. Опять же , разделение больших таблиц и их индексов может реально помочь.
Другая общая проблема возникает, когда данные распределены между несколькими базами данных, и обработка выполняется в этих базах данных последовательно. Иногда репликация базы данных может быть вовлечена как способ копирования данных между БД - это может значительно замедлить весь процесс. Общее решение заключается в уменьшении граф обработки только три слоя:
Такой подход позволяет обрабатывать, чтобы максимально использовать преимущества параллелизма. Например, если вам необходимо загрузить данные на две базы данных, вы можете запустить загрузка параллельно (вместо загрузки в первый - и затем тиражирование во вторую).
Иногда обработка должна проходить последовательно. Например, трехмерные данные (ссылки) необходимы прежде , чем можно получить и проверить строки для основных таблиц «факт» .
Недавнее развитие в ETL программного обеспечения является реализацией параллельной обработки . Это позволило несколько методов для повышения общей производительности ETL при работе с большими объемами данных.
ETL приложений реализовать три основных типа параллелизма:
Все три типа параллелизма обычно работает объединен в одном задании.
Дополнительные трудности приходит с убедившись, что данные, загруженные относительно последовательны. Поскольку несколько баз данных источников может иметь различные циклы обновления (некоторые из них могут быть обновлены каждые несколько минут, в то время как другие могут занять несколько дней или недель), система ETL может потребоваться умалчивают некоторые данные, пока все источники не синхронизированы. Точно так же, где склад, возможно, придется быть согласован с содержанием в исходной системе или с общей бухгалтерской книгой, установление синхронизации и сверками точек становится необходимым.
Процедуры хранилищ данных, как правило, подразделяют большой процесс ETL на более мелкие кусочки, работающих последовательно или параллельно. Для того, чтобы следить за потоками данных, то имеет смысл помечать каждую строку данных с «ROW_ID», и помечать каждую часть процесса с «run_id». В случае выхода из строя, имея эти идентификаторы помогают откатить и перезапустить отказавший часть.
Наилучшая практика предусматривает также контрольно - пропускные пункты , которые являются государствами , когда определенные фазы процесса завершены. После того, как на контрольно - пропускном пункте, это хорошая идея , чтобы записать все на диск, очистить временные файлы, журнал состояние, и так далее.
По состоянию на 2010 , виртуализация данных начали продвигать обработку ETL. Применение виртуализации данных в ETL позволило решить наиболее распространенные задачи ETL по миграции данных и интеграции приложений для нескольких распределенных источников данных. Виртуальный ETL работает с рассеянным представлением объектов или лиц , собранными из различных реляционных, полуструктурированных, и неструктурированных источников. ETL инструменты могут использовать объектно-ориентированное моделирование и работу с изображениями сущностей постоянно хранящихся в центре города хаб и спицы архитектуры. Такой набор , который содержит представление сущностей или объектов , собранные из источников данных для обработки ETL называется хранилищем метаданных , и он может постоянно находиться в памяти [2] или быть стойкими. Используя постоянное хранилище метаданных, ETL инструменты могут переходить от разовых проектов к стойкому промежуточному слою, выполняя согласование данных и данные профилирования последовательно и в близком к реальному времени.
Уникальные ключи играют важную роль во всех реляционных базах данных, так как они связывают все вместе. Уникальный ключ представляет собой столбец , который идентифицирует данный объект, в то время как внешний ключ представляет собой столбец в другой таблице , которая относится к первичному ключу. Ключи могут содержать несколько столбцов, в этом случае они являются составными ключами. Во многих случаях, первичный ключ является автоматически генерируемый целое число , которое не имеет никакого значения для субъекта предпринимательской деятельности представлены, но только существует для реляционной базы данных - обычно называют суррогатным ключом .
Поскольку, как правило , больше , чем один источник данных получения загружено в хранилище, ключи являются важной задачей для рассмотрения. Например: клиенты могут быть представлены в нескольких источниках данных, их номера социального страхования в качестве первичного ключа в одном источнике, их номер телефона в другой, и суррогата в третьем. Тем не менее , хранилище данных может потребовать консолидации всей информации о клиенте в одном измерении .
Рекомендуемый способ справиться с беспокойством предполагает добавление хранилища суррогатного ключа, который используется в качестве внешнего ключа из таблицы фактов. [3]
Как правило, обновления происходят в исходных данных размерностью, которая, очевидно, должны быть отражены в хранилище данных.
Если первичный ключ исходных данных необходим для отчетности, размер уже содержит эту часть информации для каждой строки. Если источник данных использует суррогатный ключ, склад должен следить за ним , даже если он никогда не используется в запросах или отчетах; это делается путем создания таблицы подстановки , который содержит суррогатный ключ хранилища и ключ БЕРУЩЕГО. [4] Таким образом, размер не загрязняются суррогатами из различных исходных систем, в то время как возможность обновления сохраняются.
Таблица поиска используется различными способами в зависимости от характера исходных данных. Есть 5 типов , чтобы рассмотреть; [5] три включены здесь:
Тип 1
Размер строка просто обновляется в соответствии с текущим состоянием исходной системы; склад не отражает историю; поисковая таблица используется для идентификации размера строки, чтобы обновить или переписать
Тип 2
Новое измерение добавляется строка с новым состоянием исходной системы; новый суррогатный ключ назначается; Основной источник больше не является уникальной в таблице поиска
Полностью войти
Новое измерение добавляется строка с новым состоянием исходной системы, в то время как предыдущее измерение строка обновляется, чтобы отразить это больше не является активным и время дезактивации.
Используя установленную структуру ETL, один может увеличить свои шансы на прекращение с лучшей связью и масштабируемостью . [ Править ] Хороший инструмент ETL должен быть в состоянии общаться с многими различными реляционными базами данных и читать файлы различных форматов , используемых в организации. ETL инструменты начали мигрировать в Enterprise Application Integration , или даже Enterprise Service Bus , систем , которые в настоящее время охватывают гораздо больше , чем просто извлечения, преобразования и загрузки данных. Многие поставщики ETL теперь имеют профилирование данных , качество данных и метаданные возможности. Обычный пример использования ETL инструментов включает преобразование CSV файлы в форматы считываемых реляционных баз данных. Типичный перевод миллионов записей способствуют ETL инструментов , которые позволяют пользователям вводить каналы CSV-как данные / файлы и импортировать их в базу данных с минимальным количеством коды , как это возможно.
ETL инструменты, как правило, используется в широком круге специалистов - от студентов в области информатики, желающей быстро импортировать большие наборы данных для архитекторов база данных, ответственных за управление компанией счета, ETL инструменты стали удобным инструментом, который можно положиться, чтобы получить максимальную производительность , ETL инструменты в большинстве случаев содержат графический интерфейс, который помогает пользователям легко преобразовывать данные, с помощью визуального картографа данных, в отличие от написания больших программ для анализа файлов и редактирования типов данных.
В то время как ETL инструменты традиционно для разработчиков и ИТ - специалистов, новая тенденция заключается в предоставлении этих возможностей для бизнес - пользователей , так что они сами могут создавать связи и интеграции данных , когда это необходимо, а не собирается ИТ - персонала. [6] Gartner , относится к этим неопытным пользователям как Citizen интеграторы. [7]
Представленные результаты и исследования подтверждают, что применение искусственного интеллекта в области извлечение данных имеет потенциал для революции в различных связанных с данной темой сферах. Надеюсь, что теперь ты понял что такое извлечение данных, преобразование данных, загрузка данных, etl и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL