Лекция
Привет, Вы узнаете о том , что такое полнотекстовый поиск, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое полнотекстовый поиск, полнотекстовый индекс , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
полнотекстовый поиск (англ. Full text searching, фр. Recherche en texte integral) — автоматизированный поиск документов, при котором поиск ведется не по именам документов, а по их содержимому, всему или существенной части.Многие веб-сайты и прикладные программы (например, программы для обработки текстов) предоставляют возможности полнотекстового поиска. Некоторые системы веб-поиска, такие как AltaVista, используют методы полнотекстового поиска, в то время как другие индексируют только часть веб-страниц, проверенных их системами индексации.
В текстовом поиске полнотекстовый поиск относится к методам поиска отдельного документа , хранящегося на компьютере , или коллекции в полнотекстовой базе данных . Полнотекстовый поиск отличается от поиска, основанного на метаданных или частях исходных текстов, представленных в базах данных (например, названиях, рефератах, выбранных разделах или библиографических ссылках).
При полнотекстовом поиске поисковая система проверяет все слова в каждом сохраненном документе, пытаясь соответствовать критериям поиска (например, тексту, указанному пользователем). Методы полнотекстового поиска появились в 1960-х годах, например IBM STAIRS с 1969 года, и стали обычным явлением в онлайн- библиографических базах данных в 1990-х годах. Многие веб-сайты и прикладные программы (например, текстовые редакторы) предоставляют возможности полнотекстового поиска. Некоторые поисковые системы, такие как бывшая AltaVista , используют методы полнотекстового поиска, в то время как другие индексируют только часть веб-страниц, проверенных их системами индексировани
Первые версии программ полнотекстового поиска предполагали сканирование всего содержимого всех документов в поиске заданного слова или фразы. При использовании такой технологии поиск занимал очень много времени (в зависимости от размера базы), а в интернете был бы невыполним. Современные алгоритмы заранее формируют для поиска так называемый полнотекстовый индекс — словарь, в котором перечислены все слова и указано, в каких местах они встречаются. При наличии такого индекса достаточно осуществить поиск нужных слов в нем и тогда сразу же будет получен список документов, в которых они встречаются.
Полнотекстовые индексы в MySQL обозначаются как типом «FULLTEXT», который может применяться для столбцов типов «VARCHAR» и «TEXT». При массовом добавлении данных в таблицу с полями «FULLTEXT» индекс будет создаваться сразу, что замедлит работу, для избежания эффекта рекомендуется модернизировать поля уже после добавления.
Поиск выполняется с помощью функций MATCH() и AGAINST():
SELECT * FROM articles WHERE MATCH (title, body) AGAINST ('поиск');
При этом поисковая фраза должна быть написана слово в слово (то есть «поиска», «поисковик» — невалидные варианты для примера выше)
Результат (жирным выделены найденные соответствия):
| id | title | body |
|---|---|---|
| 5 | Регулярные выражения | В большинстве реализаций регулярных выражений есть способ производить поиск фрагмента текста … |
| 1 | Полнотекстовой поиск | Полнотекстовой поиск … |
При работе с небольшим количеством документов система полнотекстового поиска может напрямую сканировать содержимое документов при каждом запросе . Об этом говорит сайт https://intellect.icu . Такая стратегия называется « последовательным сканированием ». Это то, что делают некоторые инструменты, такие как grep , при поиске.
Однако когда количество документов, подлежащих поиску, потенциально велико или количество выполняемых поисковых запросов существенно, задачу полнотекстового поиска часто разделяют на две задачи: индексирование и поиск. На этапе индексирования сканируется текст всех документов и строится список поисковых запросов (часто называемый индексом , но правильнее называть согласованием ). На этапе поиска при выполнении конкретного запроса используется только индекс, а не текст исходных документов.
Индексатор делает запись в указателе для каждого термина или слова, найденного в документе, и, возможно, отмечает его относительное положение в документе. Обычно индексатор игнорирует стоп-слова (такие как «the» и «and»), которые являются общими и недостаточно значимыми, чтобы их можно было использовать при поиске. Некоторые индексаторы также используют специфическую для языка основу индексируемых слов. Например, слова «ездит», «возил» и «ехал» будут записаны в указателе под одним понятийным словом «драйв».
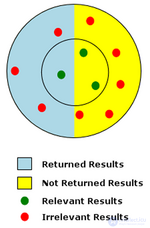
Схема поиска с низкой точностью и малой запоминаемостью
Напомним, что измеряется количество релевантных результатов, полученных в результате поиска, а точность — это мера качества возвращаемых результатов. Напомним, это отношение возвращаемых релевантных результатов ко всем релевантным результатам. Точность — это отношение количества возвращенных релевантных результатов к общему количеству возвращенных результатов.
Диаграмма справа представляет поиск с низкой точностью и малой запоминаемостью. На диаграмме красные и зеленые точки обозначают общую совокупность потенциальных результатов поиска для данного поиска. Красные точки представляют собой нерелевантные результаты, а зеленые точки — значимые результаты. Релевантность определяется близостью результатов поиска к центру внутреннего круга. Из всех возможных результатов те, которые действительно были получены в результате поиска, показаны на голубом фоне. В примере был возвращен только 1 релевантный результат из 3 возможных релевантных результатов, поэтому коэффициент отзыва очень низкий — 1/3, или 33%. Точность для примера составляет очень низкую 1/4, или 25%, поскольку только 1 из 4 возвращенных результатов был релевантным.
Из-за неоднозначности естественного языка системы полнотекстового поиска обычно включают в себя такие опции, как стоп-слова для повышения точности и основы для увеличения запоминаемости. Поиск по контролируемому словарю также помогает устранить проблемы с низкой точностью, помечая документы таким образом, чтобы исключить двусмысленность. Компромисс между точностью и полнотой прост: повышение точности может снизить общую полноту, а увеличение полноты снижает точность.
Полнотекстовый поиск, скорее всего, приведет к получению большого количества документов, которые не имеют отношения к заданному вопросу поиска. Такие документы называются ложными срабатываниями (см. ошибку I рода ). Поиск ненужных документов часто вызван присущей естественному языку двусмысленностью . На примере диаграммы справа ложноположительные результаты представлены нерелевантными результатами (красные точки), которые были возвращены поиском (на голубом фоне).
Методы кластеризации, основанные на байесовских алгоритмах, могут помочь уменьшить количество ложных срабатываний. По запросу «банк» можно использовать кластеризацию для категоризации совокупности документов/данных на «финансовое учреждение», «место для сидения», «место для хранения» и т. д. В зависимости от встречаемости слов, соответствующих категориям, Условия поиска или результаты поиска могут быть помещены в одну или несколько категорий. Этот метод широко применяется в сфере электронного обнаружения .
Недостатки полнотекстового поиска были устранены двумя способами: путем предоставления пользователям инструментов, которые позволяют им более точно формулировать свои поисковые вопросы, и путем разработки новых алгоритмов поиска, которые повышают точность поиска.
Алгоритм PageRank , разработанный Google, придает больше внимания документам, на которые ссылаются другие веб-страницы . Дополнительные примеры см. в разделе Поисковая система .
Исследование, описанное в статье про полнотекстовый поиск, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое полнотекстовый поиск, полнотекстовый индекс и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии