Привет, Вы узнаете о том , что такое индексы в mysql, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
индексы в mysql, индекс, explain, оптимизация запросов, план запроса, red-метод для анализа производительности , настоятельно рекомендую прочитать все из категории Базы данных - MySql (Maria DB).
индекс ы в mysql (Mysql indexes) — отличный инструмент для оптимизации SQL запросов. Чтобы понять, как они работают, посмотрим на работу с данными без них.
Когда вы выполняете какой-нибудь запрос, оптимизатор запросов MySQL пытается придумать оптимальный план выполнения этого запроса. Вы можете посмотреть этот самый план используя запрос с ключевым словом EXPLAIN. EXPLAIN – это один из самых мощных инструментов, предоставленных в ваше распоряжение для понимания MySQL-запросов и их оптимизации, но печальным фактом является то, что многие разработчики редко его используют. В данной статье вы узнаете о том, какие данные предлагает EXPLAIN на выходе и ознакомитесь с примером того, как использовать его для оптимизации запросов.

1. Чтение данных с диска
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок.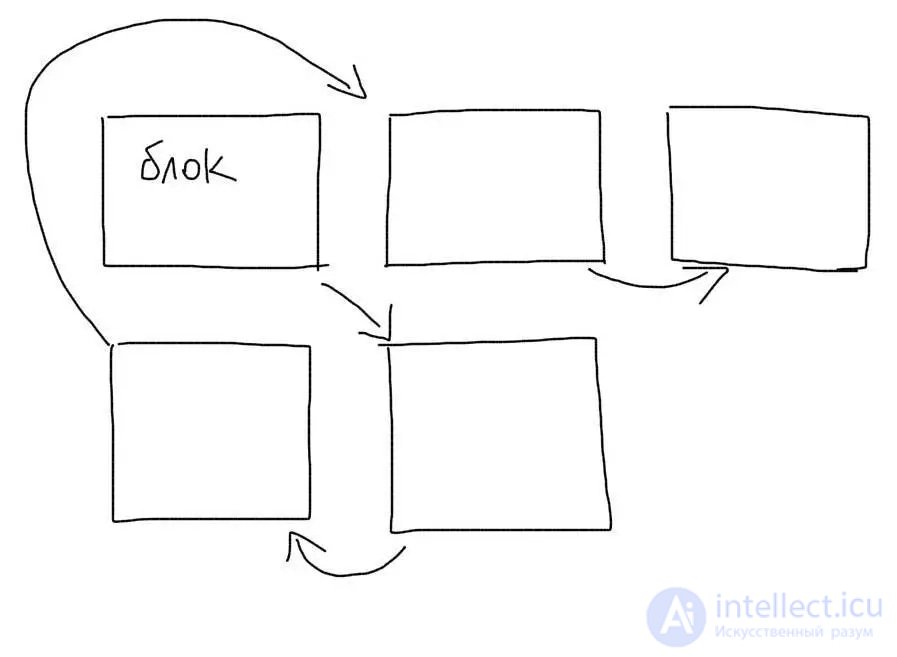
При чтении файла, мы по очереди проходимся по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, т.к. понадобится прыгать разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
2. Поиск данных в MySQL
Таблицы MySQL — это обычные файлы. Выполним запрос такого вида:
SELECT * FROM users WHERE age = 19
MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицы со значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них с озрастом 19 и отберет только подходящие данные: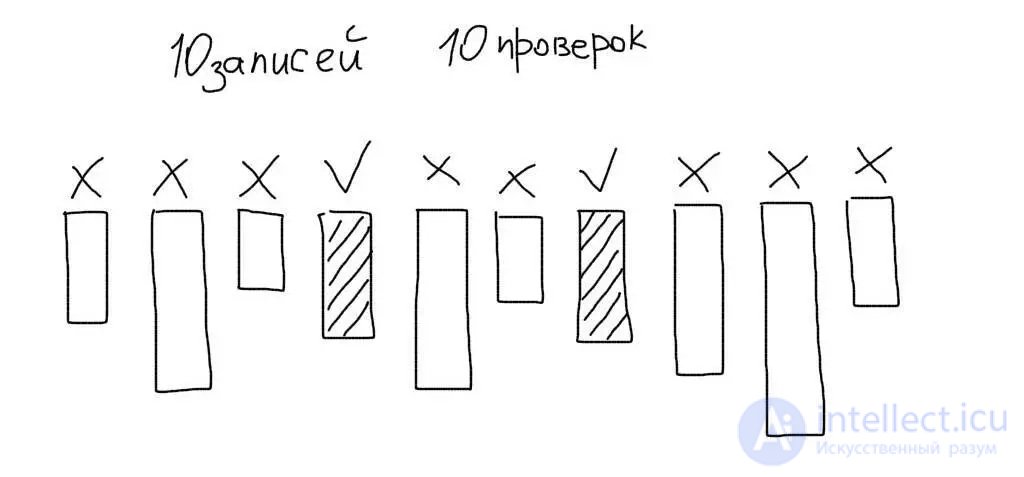
Итак, есть две проблемы при чтении данных:
- Низкая скорость чтения файлов из-за расположения блоков в разных частях диска (фрагментация).
- Большое количество операций сравнения для поиска нужных данных.
3. Сортировка данных
Представим, что мы отсортировали наши 10 записей по убыванию. Тогда используя алгоритм бинарного поиска, мы могли бы максимум за 4 операции отобрать нужные нам значения: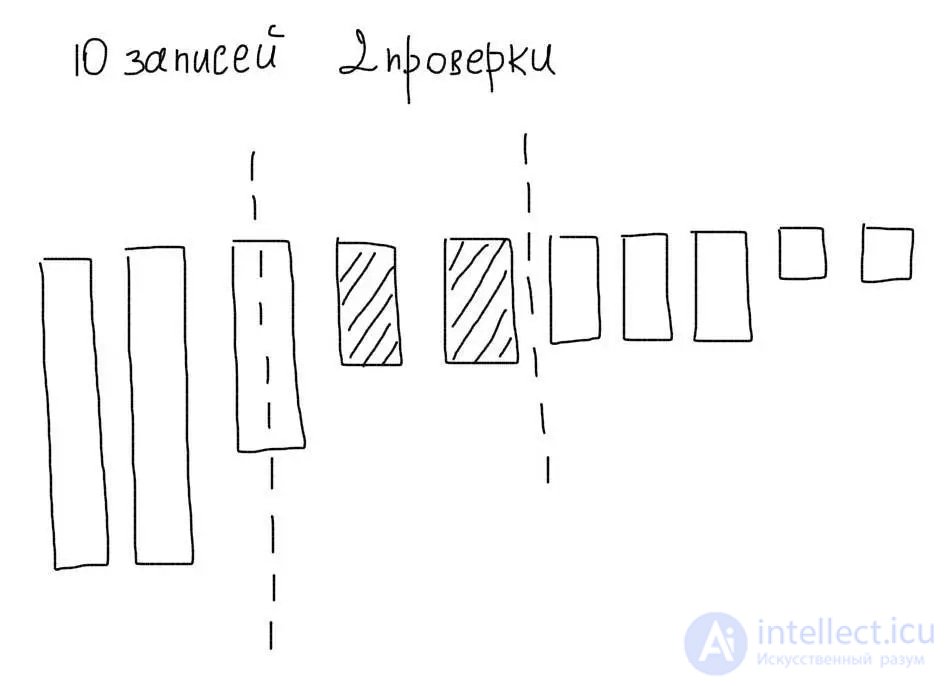
Кроме меньшего количества операций сравнения, мы сэкономили бы на чтении ненужных записей.
Индекс — это и есть отсортированный набор значений. В MySQL индексы всегда строятся для какой-то конкретной колонки. Например, мы могли бы построить индекс для колонки age из примера.
4. Выбор индексов в MySQL
В самом простом случае, индекс необходимо создавать для тех колонок, которые присутствуют в условии WHERE.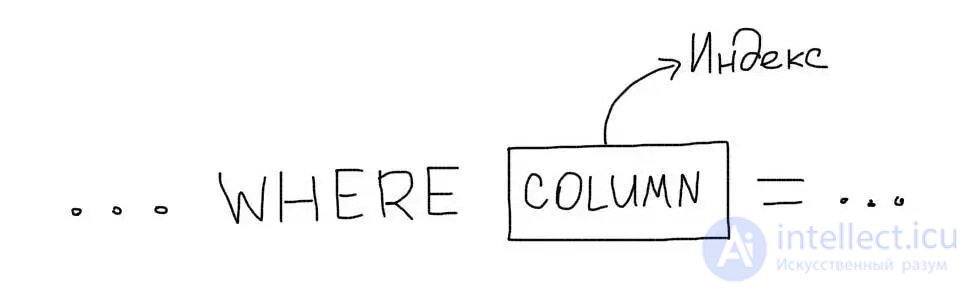
Рассмотрим запрос из примера:
SELECT * FROM users WHERE age = 29
Нам необходимо создать индекс на колонку age:
CREATE INDEX age ON users(age);
После этой операции MySQL начнет использовать индекс age для выполнения подобных запросов. Индекс будет использоваться и для выборок по диапазонам значений этой колонки:
SELECT * FROM users WHERE age < 19
Сортировка
Для запросов такого вида:
SELECT * FROM users ORDER BY register_date
действует такое же правило — создаем индекс на колонку, по которой происходит сортировка:
CREATE INDEX register_date ON users(register_date);
Внутренности хранения индексов
Представим, что наша таблица выглядит так:
id | name | age
1 | Den | 19
2 | Alyona | 15
3 | Putin | 89
4 | Petro | 12
После создания индекса на колонку age, MySQL сохранит все ее значения в отсортированном виде:
age index
12
15
29
89
Кроме этого, будет сохранена связь между значением в индексе и записью, которой соответствует это значение. Обычно для этого используется первичный ключ:
age index и связь с записями
12: 4
15: 2
29: 1
89: 3
Уникальные индексы
MySQL поддерживает уникальные индексы. Это удобно для колонок, значения в которых должны быть уникальными по всей таблице. Такие индексы улучшают эффективность выборки для уникальных значений. Например:
SELECT * FROM users WHERE email = 'info@intellect.icu';
На колонку email необходимо создать уникальный индекс:
CREATE UNIQUE INDEX email ON users(email)
Тогда при поиске данных, MySQL остановится после обнаружения первого соответствия. В случае обычного индекса будет обязательно проведена еще одна проверка (следующего значения в индексе).
5. Составные индексы
MySQL может использовать только один индекс для запроса. Поэтому, для запросов, в которых используется несколько колонок, необходимо использовать составные индексы.
Рассмотрим такой запрос:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
Нам следует создать составной индекс на обе колонки:
CREATE INDEX age_gender ON users(age, gender);
Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значений всех входящих колонок сразу. Для таблицы с такими данными:
id | name | age | gender
1 | Den | 29 | male
2 | Alyona | 15 | female
3 | Putin | 89 | tsar
4 | Petro | 12 | male
значения составного индекса будут такими:
age_gender
12male
15female
29male
89tsar
Это означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
SELECT * FROM users WHERE age <= 29 AND gender = 'male'
Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
age_gender
12male
15female
29male
89tsar
Сначала будут отфильтрованы все данные, которые подходят под условие age <= 29. Затем, поиск по значению "male" будет произведен без использования индекса.
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
SELECT * FROM users WHERE gender = 'male' ORDER BY age
В этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
CREATE INDEX gender_age ON users(gender, age);
Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
SELECT * FROM users WHERE gender = 'male' AND country = 'UA' ORDER BY age, register_time
В этом случае следует создать такой индекс:
CREATE INDEX gender_country_age_register ON users(gender, country, age, register_time);
6. Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:

Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 331 запись).
Как видим, в примере не используется ни один индекс. После создания индекса:

Прочитана всего одна запись, т.к. был использован индекс.
Проверка длинны составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):

Значение key_len показывает используемую длину индекса. В нашем случае 24 байта — длинна всего индекса (5 байт age + 19 байт gender).
Если мы выполним изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:

Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:

В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
Рассмотрим воможости опаратора EXPLAIN, изучим планы выполнения запросов
Использовать оператор EXPLAIN просто. Его необходимо добавлять в запросы перед оператором SELECT. Давайте проанализируем вывод, чтобы познакомиться с информацией, возвращаемой командой.
EXPLAIN SELECT * FROM USERS
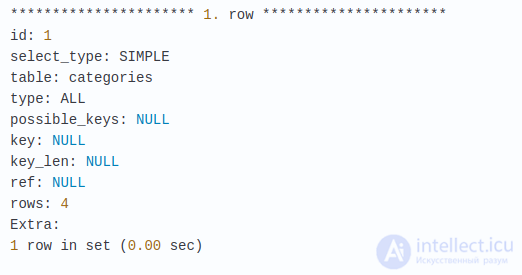
Вывод может иметь немного другой вид, однако, в нем будут содержаться те же 10 столбцов. Что же это за возвращаемые столбцы?
- id – порядковый номер для каждого SELECT’а внутри запроса (когда имеется несколько подзапросов)
- select_type – тип запроса SELECT.
- SIMPLE — Простой запрос SELECT без подзапросов или UNION’ов
- PRIMARY – данный SELECT – самый внешний запрос в JOIN’е
- DERIVED – данный SELECT является частью подзапроса внутри FROM
- SUBQUERY – первый SELECT в подзапросе
- DEPENDENT SUBQUERY – подзапрос, который зависит от внешнего запроса
- UNCACHABLE SUBQUERY – не кешируемый подзапрос (существуют определенные условия для того, чтобы запрос кешировался)
- UNION – второй или последующий SELECT в UNION’е
- DEPENDENT UNION – второй или последующий SELECT в UNION’е, зависимый от внешнего запроса
- UNION RESULT – результат UNION’а
- Table – таблица, к которой относится выводимая строка
- Type — указывает на то, как MySQL связывает используемые таблицы. Это одно из наиболее полезных полей в выводе потому, что может сообщать об отсутствующих индексах или почему написанный запрос должен быть пересмотрен и переписан. В следующем списке описаны типы соединений, отсортированные от лучшего к худшему :
- System – таблица имеет только одну строку
- Const – таблица имеет только одну соответствующую строку, которая проиндексирована. Это наиболее быстрый тип соединения потому, что таблица читается только один раз и значение строки может восприниматься при дальнейших соединениях как константа.
- Eq_ref – все части индекса используются для связывания. Используемые индексы: PRIMARY KEY или UNIQUE NOT NULL. Это еще один наилучший возможный тип связывания.
- Ref – все соответствующие строки индексного столбца считываются для каждой комбинации строк из предыдущей таблицы. Этот тип соединения для индексированных столбцов выглядит как использование операторов = или < = > Все строки с совпадающими значениями индекса считываются из этой таблицы для каждой комбинации строк из предыдущих таблиц. ref используется, если в соединении используется только крайний левый префикс ключа или если ключ не является индексом
PRIMARY KEYили UNIQUE(другими словами, если объединение не может выбрать одну строку на основе значения ключа). Если используемый ключ соответствует только нескольким строкам, это хороший тип соединения.
- Fulltext – соединение использует полнотекстовый индекс таблицы
- Ref_or_null – то же самое, что и ref, но также содержит строки со значением null для столбца
- Index_merge – соединение использует список индексов для получения результирующего набора. Столбец key вывода команды EXPLAIN будет содержать список использованных индексов.
- Unique_subquery – подзапрос IN возвращает только один результат из таблицы и использует первичный ключ.
- Index_subquery – тоже, что и предыдущий, но возвращает более одного результата.
- Range – индекс, использованный для нахождения соответствующей строки в определенном диапазоне, обычно, когда ключевой столбец сравнивается с константой, используя операторы вроде: BETWEEN, IN, >, >=, etc.
Извлекаются только строки, которые находятся в заданном диапазоне, с использованием индекса для выбора строк. Ключевой столбец в выходной строке указывает, какой индекс используется. Key_len содержит самую длинную ключевую часть, которая использовалась. Столбец ref предназначен NULLдля этого типа.
Диапазон можно использовать, когда ключевой столбец сравнивается с константой с помощью любого из =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() операторов (см. подробнее MRR)
- Index – сканируется все дерево индексов для нахождения соответствующих строк.
- All – Для нахождения соответствующих строк используются сканирование всей таблицы. Это наихудший тип соединения и обычно указывает на отсутствие подходящих индексов в таблице.
- Возможные значения:
- Possible_keys – показывает индексы, которые могут быть использованы для нахождения строк в таблице. На практике они могут использоваться, а могут и не использоваться. Фактически, этот столбец может сослужить добрую службу в деле оптимизации запросов, т.к значение NULL указывает на то, что не найдено ни одного подходящего индекса .
- Key– указывает на использованный индекс. Этот столбец может содержать индекс, не указанный в столбце possible_keys. В процессе соединения таблиц оптимизатор ищет наилучшие варианты и может найти ключи, которые не отображены в possible_keys, но являются более оптимальными для использования.
- Key_len – длина индекса, которую оптимизатор MySQL выбрал для использования. Например, значение key_len, равное 4, означает, что памяти требуется для хранения 4 знаков. На эту тему вот cсылка
- Ref – указываются столбцы или константы, которые сравниваются с индексом, указанным в поле key. Об этом говорит сайт https://intellect.icu . MySQL выберет либо значение константы для сравнения, либо само поле, основываясь на плане выполнения запроса.
- Rows – отображает число записей, обработанных для получения выходных данных. Это еще одно очень важное поле, которое дает повод оптимизировать запросы, особенно те, которые используют JOIN’ы и подзапросы.
- Extra – содержит дополнительную информацию, относящуюся к плану выполнения запроса. Такие значения как “Using temporary”, “Using filesort” и т.д могут быть индикатором проблемного запроса. С полным списком возможных значений вы можете ознакомиться здесь
После EXPLAIN в запросе вы можете использовать ключевое слово EXTENDED и MySQL покажет вам дополнительную информацию о том, как выполняется запрос. Чтобы увидеть эту информацию, вам нужно сразу после запроса с EXTENDED выполнить запрос SHOW WARNINGS. Наиболее полезно смотреть эту информацию о запросе, который выполнялся после каких-либо изменений сделанных оптимизатором запросов.


SHOW WARNINGS

Поиск и устранение проблем с производительностью с помощью EXPLAIN.
Теперь давайте посмотрим на то, как мы может оптимизировать не очень шустрый запрос, анализируя вывод команды EXPLAIN. Несомненно, что в действующих рабочих приложениях существует ряд таблиц со многими связями между ними, но иногда сложно предвидеть наиболее оптимальный способ написания запроса.
Если создать тестовую базу данных для приложения электронной торговли, которая не имеет никаких индексов или первичных ключей, и продемонстрирую влияние такого не очень хорошего способа создания таблиц при помощи “страшных” запросов.

Если вы посмотрите на результат (на него вам придется посмотреть только в примере ниже, по ссылке выше лежит дамп с уже добавленными ключами), то увидите все симптомы плохого запроса.
Но даже если я напишу запрос получше, результат будет тем же самым, пока я не добавлю индексов. Указанный тип соединения ALL (худший), что означает, что MySQL не смог определить ни одного ключа, который бы мог использоваться при соединении. Отсюда следует и то, что possible_keys и key имеют значение NULL. Самым важным является то, что поле rows показывает, что MySQL сканирует все записи каждой таблицы для запроса. Это означает, что она просканирует 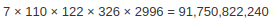 записей, чтобы найти подходящие четыре (уберите из запроса EXPLAIN, проверьте сами). Это очень нехорошо и количество этих записей будет экспоненциально увеличиваться по мере роста базы данных.
записей, чтобы найти подходящие четыре (уберите из запроса EXPLAIN, проверьте сами). Это очень нехорошо и количество этих записей будет экспоненциально увеличиваться по мере роста базы данных.
Теперь давайте добавим очевидные индексы, такие, как первичный ключ для каждой таблицы, и выполним запрос еще раз. Взяв это за основное правило, в качестве кандидатов для добавления ключей вы можете использовать те столбцы которые используются в JOIN’ах, т.к. MySQL всегда сканирует их для нахождения соответствующих записей.

Давайте выполним наш прежний запрос после добавления индексов. Вы увидите это:


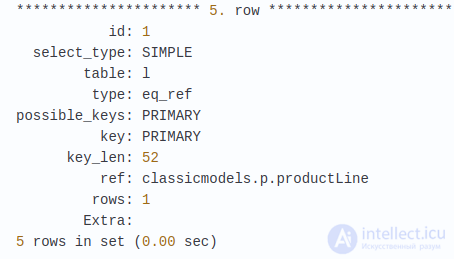
После добавления индексов, число считанных записей упало до 1 × 1 × 4 × 1 × 1 = 4 Для каждой записи order_number = 10101 в таблице orderdetails – это значит, что MySQL смогла найти соответствующие записи во всех других таблицах с использованием индексов и не стала прибегать к полному сканированию таблицы.
В первом выводе вы можете что использован тип соединения – “const”, который является самым быстрым типом соединения для таблиц с более, чем одной записью. MySQL смогла использовать PRIMARY KEY как индекс. В поле “ref” отображается “const”, что есть ни что иное, как значение 10101, указанное в запросе после ключевого слова WHERE.
Смотрим на еще один запрос. В нем мы выбираем объединение двух таблиц, products и productvariants, каждая объединена с productline. productvariants, которая состоит из разных вариантов продуктов с полем productCode – ссылкой на их цены.



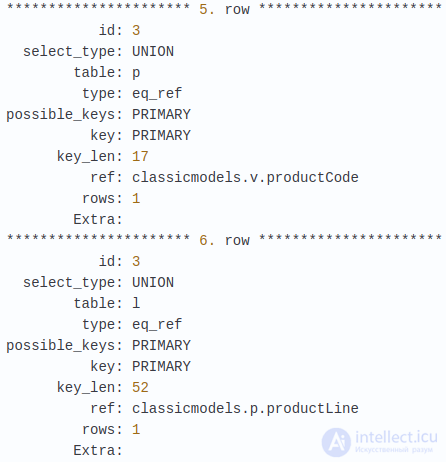
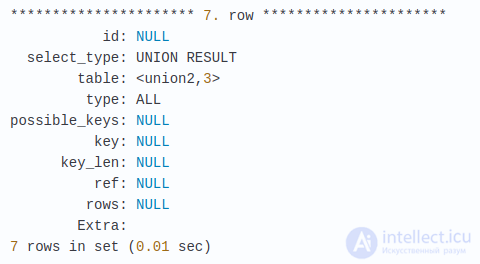
Вы можете заметить ряд проблем в этом запросе. Он сканирует все записи в products и productvarians. Т.к. в этих таблицах нет индексов для столбцов productLine и buyPrice, в полях possible_keys и key отображаются значения NULL. Статус таблиц products и productlines проверяется после UNION’а, поэтому перемещение их внутри UNION’а уменьшит число записей. Добавим индексы.
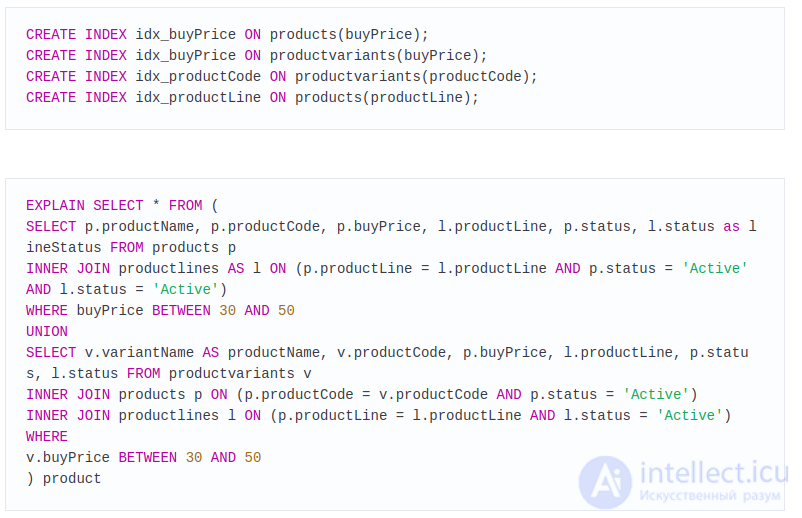

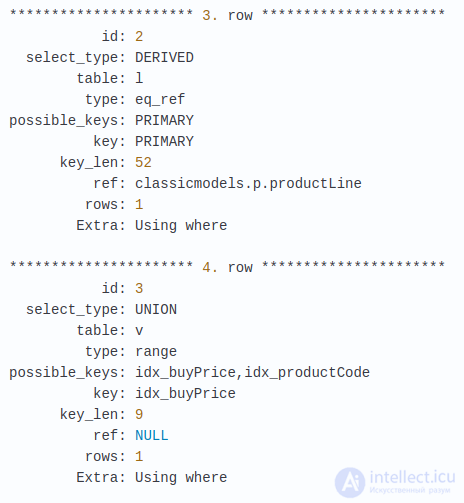

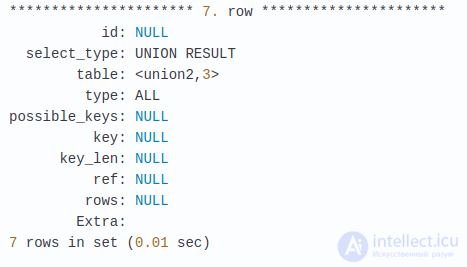
Как вы видите, в результате количество сканированных строк уменьшилось с 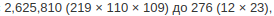 , что является отличным приобретением в производительности. Если вы выполните этот же запрос без предыдущих перестановок в запросе сразу после добавления индексов, вы не увидите такого уменьшения просканированных строк. MySQL не способна использовать индексы, когда в производном результате используется WHERE. После помещения этих условий внутри UNION становится возможных использование индексов. Это значит, что добавления индексов не всегда достаточно. MySQL не сможет их использовать до тех пор, пока вы не будете писать подходящие запросы.
, что является отличным приобретением в производительности. Если вы выполните этот же запрос без предыдущих перестановок в запросе сразу после добавления индексов, вы не увидите такого уменьшения просканированных строк. MySQL не способна использовать индексы, когда в производном результате используется WHERE. После помещения этих условий внутри UNION становится возможных использование индексов. Это значит, что добавления индексов не всегда достаточно. MySQL не сможет их использовать до тех пор, пока вы не будете писать подходящие запросы.
7. Селективность индексов
Вернемся к запросу:
SELECT * FROM users WHERE age = 29 AND gender = 'male'
Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
mysql> select age, count(*) from users group by age;
+------+----------+
| age | count(*) |
+------+----------+
| 15 | 160 |
| 16 | 250 |
| ... |
| 76 | 210 |
| 85 | 230 |
+------+----------+
68 rows in set (0.00 sec)
mysql> select gender, count(*) from users group by gender;
+--------+----------+
| gender | count(*) |
+--------+----------+
| female | 8740 |
| male | 4500 |
+--------+----------+
2 rows in set (0.00 sec)
Эта информация говорит нам вот о чем:
- Любое значение колонки age обычно содержит около 200 записей.
- Любое значение колонки gender — около 6000 записей.
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age.
Селективность колонки определяется количеством записей в таблице с одинаковыми значениями. Когда записей с одинаковым значением мало — селективность высокая. Такие колонки необходимо использовать первыми в составных индексах.
8. Первичные ключи
Первичный ключ (Primary Key) — это особый тип индекса, который является идентификатором записей в таблице. Он обязательно уникальный и указывается при создании таблиц:
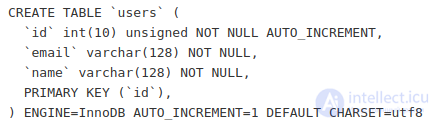
При использовании таблиц InnoDB всегда определяйте первичные ключи. Если первичного ключа нет, MySQL все равно создаст виртуальный скрытый ключ.
Кластерные индексы
Обычные индексы являются некластерными. Это означает, что сам индекс хранит только ссылки на записи таблицы. Когда происходит работа с индексом, определяется только список записей (точнее список их первичных ключей), подходящих под запрос. После этого происходит еще один запрос — для получения данных каждой записи из этого списка.
Кластерные индексы сохраняют данные записей целиком, а не ссылки на них. При работе с таким индексом не требуется дополнительной операции чтения данных.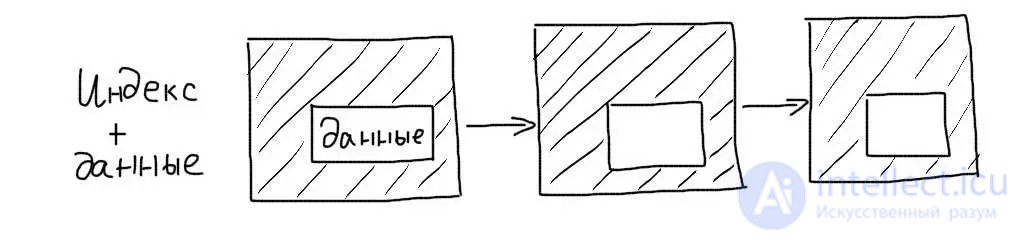
Первичные ключи таблиц InnoDB являются кластерными. Поэтому выборки по ним происходят очень эффективно.
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе.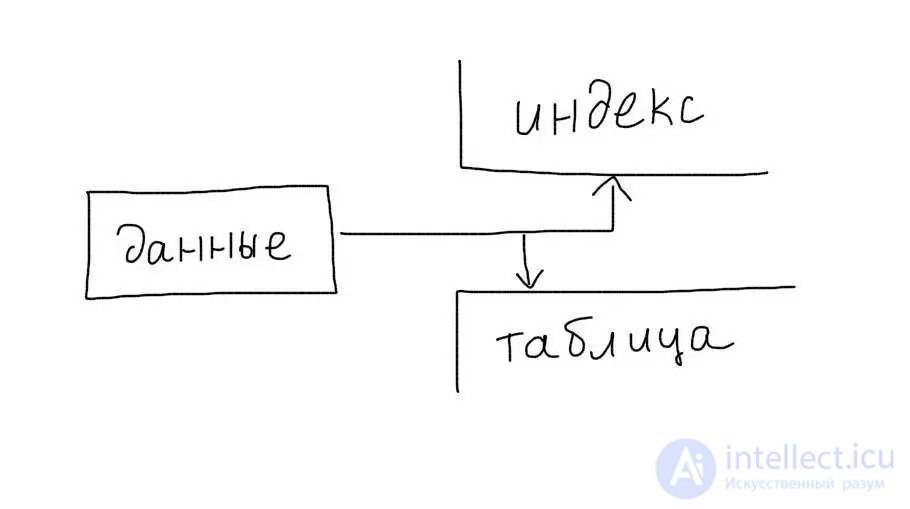
Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
mysql> show table status;
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+
| Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment |
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+
...
| users | InnoDB | 10 | Compact | 314 | 208 | 65536 | 0 | 16384 | 0 | 355 | 2014-07-11 01:12:17 | NULL | NULL | utf8_general_ci | NULL | | |
+-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+
18 rows in set (0.06 sec)
Когда создавать индексы?
- Индексы следует создавать по мере обнаружения медленных запросов. В этом поможет slow log в MySQL. Запросы, которые выполняются более 1 секунды являются первыми кандидатами на оптимизацию.
- Начинайте создание индексов с самых частых запросов. Запрос, выполняющийся секунду, но 1000 раз в день наносит больше ущерба, чем 10-секундный запрос, который выполняется несколько раз в день.
- Не создавайте индексы на таблицах, число записей в которых меньше нескольких тысяч. Для таких размеров выигрыш от использования индекса будет почти незаметен.
- Не создавайте индексы заранее, например, в среде разработки. Индексы должны устанавливаться исключительно под форму и тип нагрузки работающей системы.
- Удаляйте неиспользуемые индексы.
Самое важное
Выделяйте достаточно времени на анализ и организацию индексов в MySQL (и других базах данных). На это может уйти намного больше времени, чем на проектирование структуры базы данных. Удобно будет организовать тестовую среду с копией реальных данных и проверять там разные структуры индексов.
Не создавайте индексы на каждую колонку, которая есть в запросе, MySQL так не работает. Используйте уникальные индексы, где необходимо. Всегда устанавливайте первичные ключи.
Работа с индексами в Mysql — это фундаментальная задача для построения систем с высокой производительностью. В этой статье разберемся с тем, как Mysql использует индексы в JOIN запросах.
Вводные
Представим, что у нас есть простая система подсчета статистики просмотров статей. Данные о статьях мы храним в одной таблице:
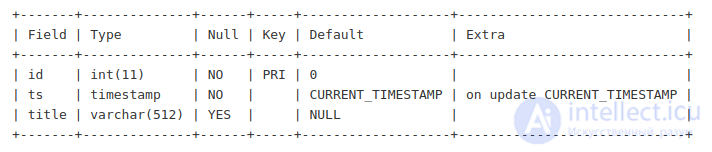
Данные со статистикой хранятся в другой таблице с такой структурой:
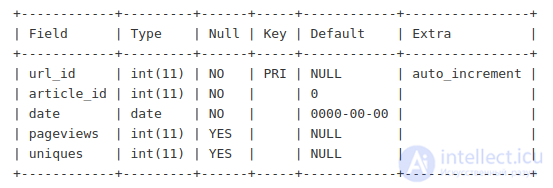
Обратите внимание, что во второй таблице первичный ключ — это url_id. Это идентификатор ссылки на статью. Т.е. у одной статьи может быть несколько разных ссылок, и для каждой из них мы будем собирать статистику. Колонка article_id соответствует колонке id из первой таблицы. Сама статистика очень простая — количество просмотров и уникальных посетителей в день.
Выборка статистики для одной статьи
Сделаем выбор статистики для одной статьи:

На выходе получим просмотры и уникальных посетителей для этой статьи за каждый день:

Запрос отработал за 0.37 секунд, что довольно медленно. Посмотрим на EXPLAIN:
+----+-------------+-------+-------+---------------+---------+---------+-------+--------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+--------+----------------------------------------------+
| 1 | SIMPLE | a | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | s | ALL | NULL | NULL | NULL | NULL | 616786 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+-------+--------+----------------------------------------------+
EXPLAIN показывает две записи — по одной для каждой таблицы из нашего запроса:
- Для первой таблицы Mysql выбрал индекс PRIMARY и эффективно его использовал.
- Для второй таблицы Mysql не смог найти подходящих индексов и ему пришлось проверить почти 700 тыс. записей, чтобы сгенерировать результат.
В JOIN запросах Mysql будет использовать индекс, который позволит отфильтровать больше всего записей из одной из таблиц
Поэтому нам необходимо убедиться, что Mysql будет быстро выполнять запрос такого вида:
SELECT article_id, date, SUM(pageviews), SUM(uniques) FROM articles_stats WHERE article_id = 4 GROUP BY date
Согласно логике выбора индексов построим индекс по колонке article_id:
CREATE INDEX article_id on articles_stats(article_id);
Проверим использование индексов в нашем первом запросе:
EXPLAIN SELECT s.article_id, s.date, SUM(s.pageviews), SUM(s.uniques) from articles a join articles_stats s on (s.article_id = a.id) where a.id = 4 group by s.date;
И увидим, что Mysql теперь использует индексы для двух таблиц:
+----+-------------+-------+-------+---------------+------------+---------+-------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------------+---------+-------+------+----------------------------------------------+
| 1 | SIMPLE | a | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index; Using temporary; Using filesort |
| 1 | SIMPLE | s | ref | article_id | article_id | 4 | const | 637 | Using where |
+----+-------------+-------+-------+---------------+------------+---------+-------+------+----------------------------------------------+
Это значительно ускорит запрос (ведь Mysql во втором случае обрабатывает в 1000 раз меньше данных).
Агрегационные запросы
Предыдущий пример носит более лабораторный характер. Более приближенный к практике запрос — это выборка статистики сразу по нескольким статьям:

Однако в этом случае Mysql будет вести себя точно также. Он оценит какие индексы можно использовать из каждой таблицы. EXPLAIN покажет:
+----+-------------+-------+--------+---------------+------------+---------+-------------------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+------------+---------+-------------------+------+----------------------------------------------+
| 1 | SIMPLE | s | range | article_id | article_id | 4 | NULL | 2130 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | Using index |
+----+-------------+-------+--------+---------------+------------+---------+-------------------+------+----------------------------------------------+
Таблицы будут обработаны в другом порядке. Сначала будет сделана выборка всех подходящих значений из таблицы статистики. А затем из таблицы с названиями.
Mysql решил, что сначала выбрав статистику по всем нужным статьям, он затем быстрее сделает выборку из таблицы articles. Порядок в этом случае не имеет особого значения, ведь в таблице articles выборка происходит по первичному ключу.
Дополнительные фильтры
На практике приходится иметь дело с дополнительными фильтрами в запросах. Например, выборка статистики только за определенную дату:

В этом случае, Mysql снова не сможет подобрать индекс для таблицы статистики:

Логика выбора индекса тут такая же, как и в предыдущем примере. Необходимо подобрать индекс, который позволит быстро отфильтровать таблицу статистики по дате:
CREATE INDEX date ON articles_stats(date);
Теперь запрос будет использовать индексы на обе таблицы:
+----+-------------+-------+--------+-----------------+---------+---------+-------------------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+-----------------+---------+---------+-------------------+------+----------------------------------------------+
| 1 | SIMPLE | s | ref | article_id,date | date | 4 | const | 2196 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | |
+----+-------------+-------+--------+-----------------+---------+---------+-------------------+------+----------------------------------------------+
Сложные фильтры и сортировки
В еще более сложных случаях выборки включают дополнительные фильтры либо сортировки. Допустим, мы хотим выбрать все статьи, созданные не позднее месяца назад. А статистику показать для них только за последний день. Только для тех публикаций, у которых набрано более 15 тыс. уникальных посещений. И результат отсортировать по просмотрам:

# Запрос отработает за 0.15 секунд, что довольно медленно
Mysql будет искать индексы, которые позволят отфильтровать максимум значений из каждой исходной таблицы. В нашем случае это будут:
+----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+
| 1 | SIMPLE | s | range | date | date | 4 | NULL | 21384 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.s.article_id | 1 | Using where |
+----+-------------+-------+--------+---------------+---------+---------+-------------------+-------+----------------------------------------------+
Индекс date позволит отфильтровать таблицу статистики до 26 тыс. записей. Каждую из которых придется проверить на соответствие другим условиям (количество уникальных посетителей более 25 тыс.).
Сортировку по просмотрам Mysql будет в любом случае делать самостоятельно. Индексы тут не помогут, т.к. сортируем динамические значения (результат операции GROUP BY).
Поэтому наша задача — выбрать индекс, который позволит максимально сократить выборку по таблице articles_stats используя фильтр s.date = '2027-05-14' AND s.uniques > 25000.
Создадим индекс на обе колонки из первого пункта:
CREATE INDEX date_uniques ON articles_stats(date,uniques);
Тогда Mysql сможет использовать этот индекс для фильтрации таблицы статистики:
+----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+
| 1 | SIMPLE | s | range | date_uniques | date_uniques | 9 | NULL | 1281 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | a | eq_ref | PRIMARY,ts_id | PRIMARY | 4 | test.s.article_id | 1 | Using where |
+----+-------------+-------+--------+---------------+--------------+---------+-------------------+------+----------------------------------------------+
# При таком индексе Mysql обработает в 10 раз меньше записей для выборки
Другие стратегии ускорения JOIN
В ситуациях, когда невозможно выбрать подходящий индекс, следует подумать о денормализации. В этом случае стоит пользоваться правилом:
Лучше много легких записей, чем много тяжелых чтений
Следует создать таблицу, оптимизированную под запрос и синхронно ее обновлять. Однако убедитесь, что ваш сервер хорошо настроен. В качестве срочных мер рассмотрите возможность кешировать результаты тяжелых запросов.
8.9.3 Индексные подсказки
Указатели индекса дают информацию оптимизатора о том, как выбирать индексы во время обработки запросов. Указания индекса применяются только к SELECTоператорам. (Они принимаются парсером для UPDATE операторов, но игнорируются и не действуют).
Индексные подсказки указываются после имени таблицы. (Общий синтаксис для указания таблиц в SELECTинструкции см. В разделе 13.2.9.2, «JOIN Syntax» .) Синтаксис для обращения к отдельной таблице, включая подсказки индекса, выглядит следующим образом:
tbl_name [[AS] alias] [index_hint_list]
index_hint_list:
index_hint [index_hint] ...
index_hint:
USE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] ([index_list])
| IGNORE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] (index_list)
| FORCE {INDEX|KEY}
[FOR {JOIN|ORDER BY|GROUP BY}] (index_list)
index_list:
index_name [, index_name] ...
Совет подсказывает MySQL использовать только один из названных индексов для поиска строк в таблице. Альтернативный синтаксис говорит MySQL не использовать какой-либо определенный индекс или индексы. Эти подсказки полезны, если показано, что MySQL использует неверный индекс из списка возможных индексов. USE INDEX (index_list)IGNORE INDEX (index_list)EXPLAIN
FORCE INDEXНамек действует как с добавлением , что сканирование таблицы считается очень дорогим. Другими словами, сканирование таблицы используется только в том случае, если нет способа использовать один из названных индексов для поиска строк в таблице. USE INDEX (index_list)
Каждому подсказку нужны имена индексов, а не имена столбцов. Чтобы обратиться к первичному ключу, используйте имя PRIMARY. Чтобы увидеть имена индексов для таблицы, используйте SHOW INDEXоператор или INFORMATION_SCHEMA.STATISTICS таблицу.
index_nameЗначение не должно быть полное имя индекса. Это может быть однозначный префикс имени индекса. Если префикс неоднозначен, возникает ошибка.
Примеры:
SELECT * FROM table1 USE INDEX (col1_index,col2_index)
WHERE col1=1 AND col2=2 AND col3=3;
SELECT * FROM table1 IGNORE INDEX (col3_index)
WHERE col1=1 AND col2=2 AND col3=3;
Синтаксис для подсказок индекса имеет следующие характеристики:
-
Это синтаксически правильным опустить index_listдля USE INDEX, что означает « использовать не индексов. » Опуская index_listдля FORCE INDEXили IGNORE INDEXошибка синтаксиса.
-
Вы можете указать область подсказки индекса, добавив FORпредложение к подсказке. Это обеспечивает более тонкий контроль над выбором оптимизатора плана выполнения для различных этапов обработки запросов. Чтобы повлиять только на индексы, используемые, когда MySQL решает, как найти строки в таблице и как обрабатывать соединения, используйте FOR JOIN. Чтобы влиять на использование индекса для сортировки или группировки строк, используйте FOR ORDER BYили FOR GROUP BY.
-
Вы можете указать несколько подсказок для индекса:
SELECT * FROM t1 USE INDEX (i1) IGNORE INDEX FOR ORDER BY (i2) ORDER BY a;
Нельзя назвать один и тот же индекс несколькими подсказками (даже в пределах одного и того же намека):
SELECT * FROM t1 USE INDEX (i1) USE INDEX (i1,i1);
Тем не менее, это ошибка для смешивания USE INDEX и FORCE INDEXдля одной и той же таблицы:
SELECT * FROM t1 USE INDEX FOR JOIN (i1) FORCE INDEX FOR JOIN (i2);
Если подсказка индекса не содержит FORпредложения, объем подсказки должен применяться ко всем частям оператора. Например, этот намек:
IGNORE INDEX (i1)
эквивалентно этой комбинации подсказок:
IGNORE INDEX FOR JOIN (i1)
IGNORE INDEX FOR ORDER BY (i1)
IGNORE INDEX FOR GROUP BY (i1)
В MySQL 5.0 область подсказок без FORпредложения заключалась в применении только для поиска строк. Чтобы заставить сервер использовать это более старое поведение, когда нет FORпредложения, включите oldсистемную переменную при запуске сервера. Позаботьтесь о включении этой переменной в настройку репликации. При двоичном протоколировании, основанном на операторах, наличие разных режимов для ведущего устройства и ведомых устройств может привести к ошибкам репликации.
Когда индекс подсказка обрабатываются, они собраны в одном списке по типу ( USE, FORCE, IGNORE) и объемом ( FOR JOIN, FOR ORDER BY, FOR GROUP BY). Например:
SELECT * FROM t1
USE INDEX () IGNORE INDEX (i2) USE INDEX (i1) USE INDEX (i2);
эквивалентно:
SELECT * FROM t1
USE INDEX (i1,i2) IGNORE INDEX (i2);
Затем подсказки индекса применяются для каждой области в следующем порядке:
-
{USE|FORCE} INDEXприменяется, если присутствует. (Если нет, используется набор индексов с оптимизатором).
-
IGNORE INDEXприменяется в результате предыдущего шага. Например, следующие два запроса эквивалентны:
SELECT * FROM t1 USE INDEX (i1) IGNORE INDEX (i2) USE INDEX (i2);
SELECT * FROM t1 USE INDEX (i1);
Для FULLTEXTпоисков подсказки индексов работают следующим образом:
-
Для поиска в режиме естественного языка подсказки индекса молча игнорируются. Например, IGNORE INDEX(i1)игнорируется без предупреждения и индекс все еще используется.
-
Для поиска в булевом режиме индексированные подсказки с FOR ORDER BYили FOR GROUP BYмолча игнорируются. Индексные подсказки с модификатором FOR JOINили без него FORвыполняются. В отличие от того, как подсказки применяются для не- FULLTEXTпоиска, подсказка используется для всех этапов выполнения запроса (поиск строк и поиск, группировка и упорядочение). Это справедливо, даже если подсказка указана для неиндекс FULLTEXT.
Например, следующие два запроса эквивалентны:
SELECT * FROM t
USE INDEX (index1)
IGNORE INDEX (index1) FOR ORDER BY
IGNORE INDEX (index1) FOR GROUP BY
WHERE ... IN BOOLEAN MODE ... ;
SELECT * FROM t
USE INDEX (index1)
WHERE ... IN BOOLEAN MODE ... ;
Анализатор запросов не является идеальным. Оптимизатор, который выбирает неправильный план, может вызвать серьезные проблемы с производительностью.
Однако это НЕ означает, что вы всегда должны использовать подсказку индекса силы.
red-метод для анализа производительности MySQL
Метод RED (Rate, Errors, Duration) является одним из популярных подходов к мониторингу производительности. Он часто применяется для мониторинга микросервисов, хотя ничего не мешает использовать его для баз данных, таких как MySQL.
В Percona Monitoring and Management (PMM) v2 вся необходимая информация собирается в базу данных ClickHouse, и дальше уже дело техники с помощью встроенного источника данных ClickHouse создать дашборд для визуализации метрик.
При создании дашборда помимо панелей для RED были добавлены несколько дополнительных панелей, чтобы показать некоторые интересные вещи, которые можно сделать с Grafana + ClickHouse в качестве источника данных и информацией, которую мы храним о производительности запросов MySQL.
Давайте посмотрим на дашборд внимательнее.
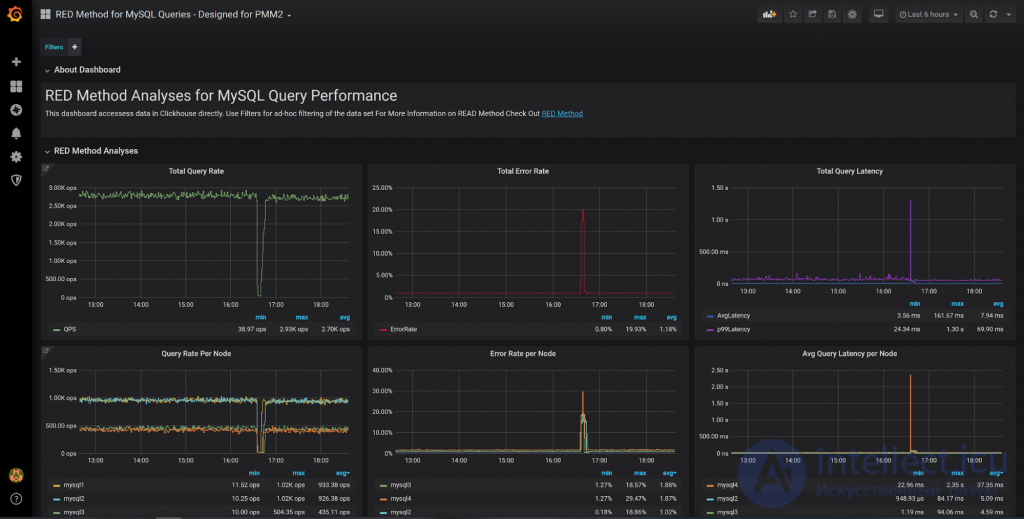
Мы видим классические панели RED-метода, показывающие Query Rate (количество запросов в секунду), Error Rate (количество ошибок), а также среднее значение и 99ый процентиль Query Latency (время выполнения запросов) для всех узлов системы. На панелях ниже отображается информация по конкретным узлам, что очень полезно для сравнения их производительности. Если один из узлов начнет работать не так, как остальные аналогичные узлы, то это повод для расследования.
С помощью фильтров (“Filters” в верхней части дашборда) вы можете просматривать только нужные вам данные. Например, можно выбрать только запросы схемы “sbtest” для хостов, расположенных в регионе “datacenter4”:
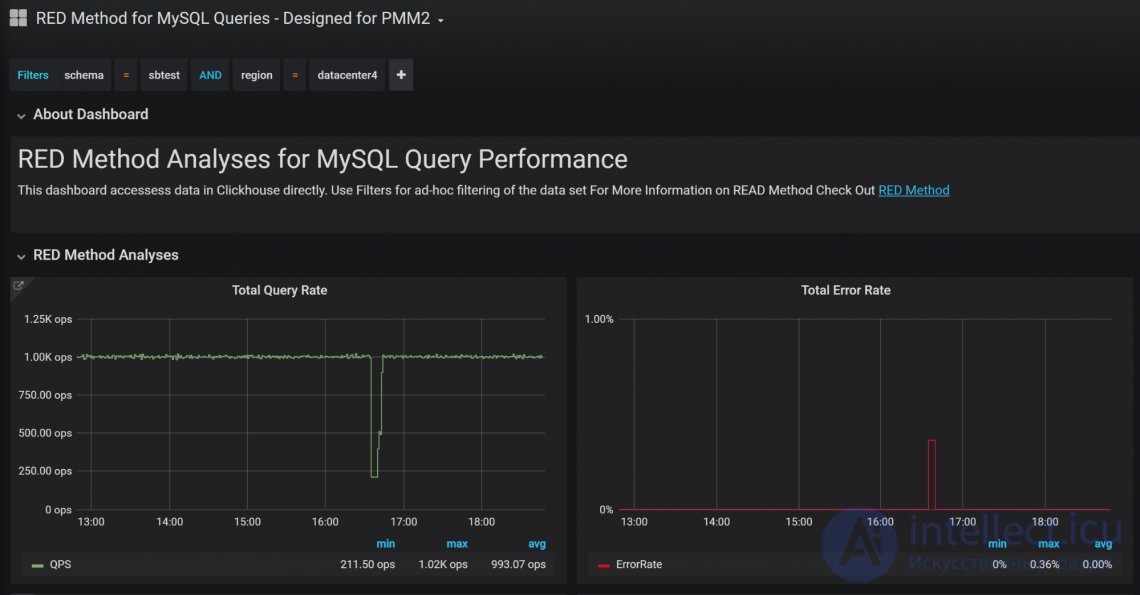
Такая ad-hoc фильтрация очень удобна. Вы можете использовать в фильтрах регулярные выражения, искать по конкретному QueryID, анализировать запросы от конкретных клиентских хостов и т. д. Описание колонок, доступных в ClickHouse, есть в посте Advanced Query Analysis in Percona Monitoring and Management with Direct ClickHouse Access.
Из большинства панелей вы можете быстро перейти в Query Analytics (анализ запросов) для просмотра подробной информации о производительности запросов, или, если вы заметили у одного из хостов что-то необычное, то через “Data Links” можете посмотреть запросы этого хоста — нажмите на график и перейдите по выделенной ссылке:
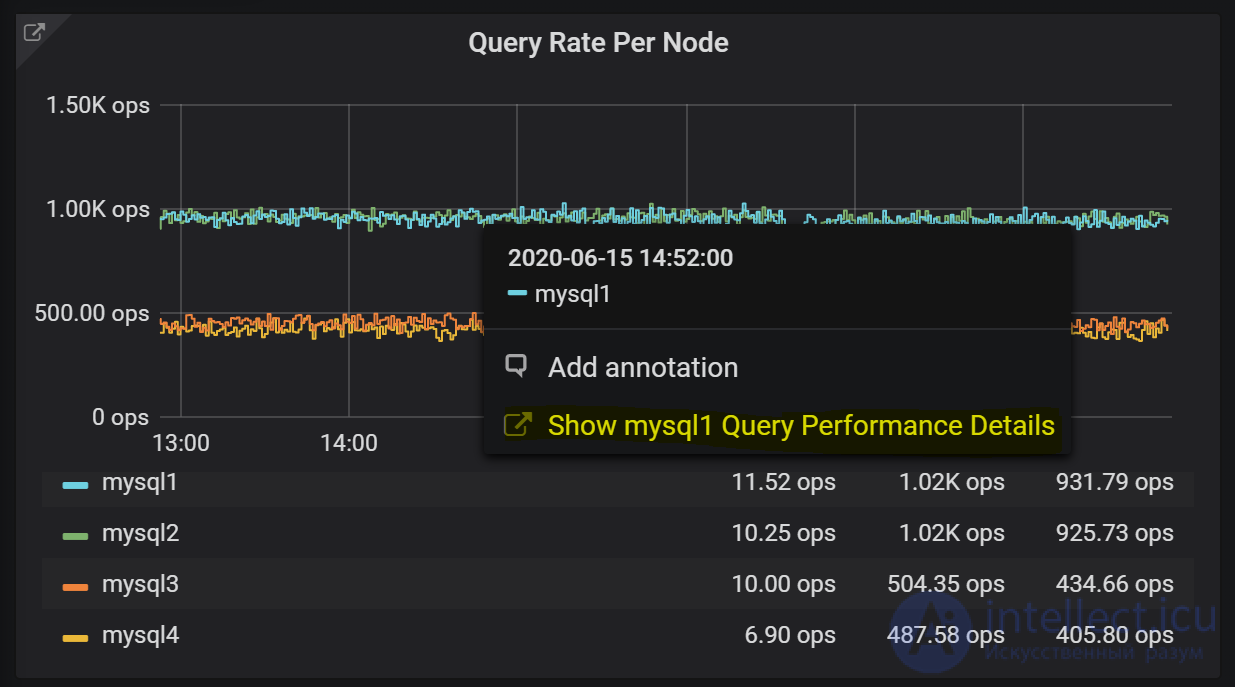
Для каждой из систем в отдельности вы можете смотреть те же RED-метрики, что и для всей системы в целом. По умолчанию я бы оставлял эти панели свернутыми, особенно если вы мониторите много хостов.
Мы познакомились с панелями RED-метода. Теперь давайте посмотрим на дополнительные панели (Additional Dashboards) в этом дашборде.

Row Based Efficiency (эффективность на основе строк) показывает, сколько строк было проанализировано на каждую возвращенную или измененную строку. Как правило, значения больше 100 указывают на плохие индексы или на очень сложные запросы, которые считывают много данных, а возвращают только несколько строк. Оба этих случая требуют анализа.
Time-Based Efficiency (эффективность на основе времени) основана на той же математике, но смотрит на время выполнения запроса, а не на количество сканированных строк. Это позволяет выявлять проблемы, связанные с медленным диском или конфликтующими запросами. Как правило, от высокопроизводительной системы следует ожидать доли миллисекунды на отправку строки клиенту или на ее изменение. Запросы, которые возвращают или изменяют много строк, будут иметь более низкое значение.
Queries Per Host (количество запросов по хостам) говорит само за себя и рядом с ним очень полезно видеть Query Load Per Host (нагрузку по хостам), которая показывает количество одновременных активных запросов. Здесь мы можем видеть, что несмотря на то, что у mysql4 не самое большое количество запросов (query rate), но у него самая большая нагрузка и наибольшее среднее количество активных запросов.
Размышляя о том, какие еще метрики могут быть полезны, я добавил следующие дополнительные панели:
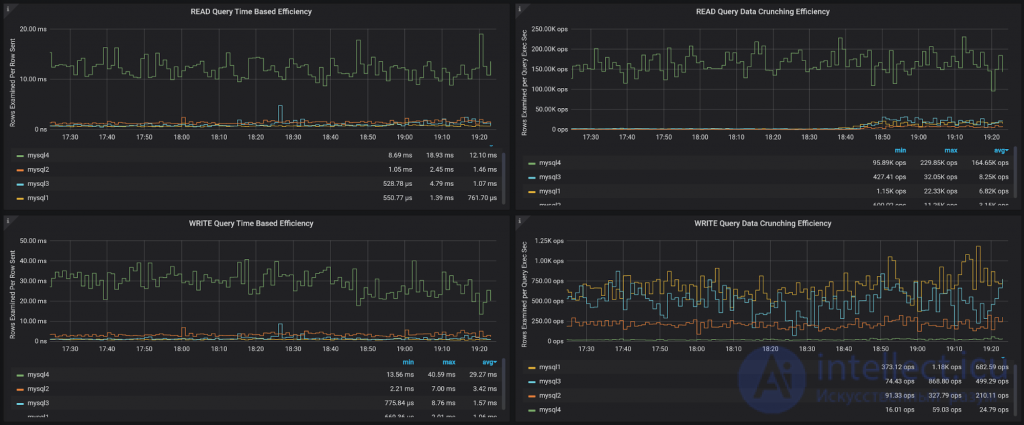
Эти панели разделяют Query Processing Efficiency на READ-запросы (которые возвращают строки) и WRITE-запросы (у которых есть row_affected).
QueryTime Based Efficiency — это то же самое, что описано выше, только с акцентом на определенные виды запросов.
Data Crunching Efficiency (эффективность обработки данных) — это несколько другой взгляд на те же данные. Здесь показано сколько строк анализируется (examined) запросом в сравнении с временем выполнения запроса. Это, с одной стороны, показывает вычислительную мощность системы. Система с большим количеством ядер, имеющая все данные в памяти, может обрабатывать миллионы строк в секунду и выполнять много работы. Но это не говорит об эффективности запросов. На самом деле, системы, которые быстро обрабатывают много данных, часто выполняют много операций полного сканирования таблиц.
Наконец, есть несколько списков с запросами.
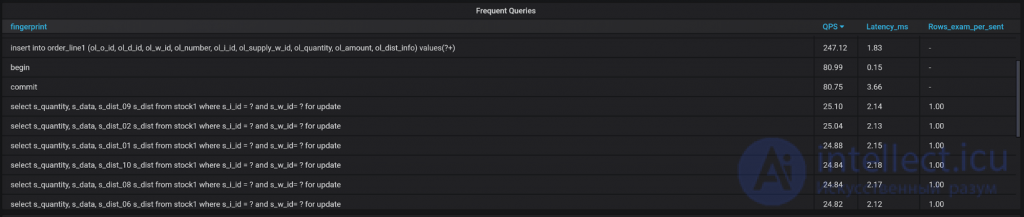
Частые запросы, самые медленные запросы (по среднему времени выполнения), запросы, вызывающие наибольшую нагрузку, и запросы, которые завершились с ошибкой или предупреждением. Вы также можете увидеть эти запросы и в Query Analytics, но я хотел показать их здесь для примера.
Выводы
В статье рассмотрено ключевое слово EXPLAIN, информация на выводе и примеры того, как вы можете использовать вывод команды для улучшения запросов. В реальном мире данная команда может быть более полезна, чем в рассмотренных сценариях. Почти всегда вы будете соединять ряд таблиц вместе, используя сложные конструкции с WHERE. При этом, просто добавленные индексы к таблицам не всегда приведут к нужному результату. В таком случае нужно пересмотреть ваши запросы.
- Используйте те же правила создания индексов, что и для обычных запросов — индекс для колонок в WHERE.
- В сложных выборках выбирайте индексы (перебором), которые позволят уменьшить число "rows" в EXPLAIN запроса.
- В особо сложных случаях — денормализация и кеширование.
Вау!! 😲 Ты еще не читал? Это зря!
Анализ данных, представленных в статье про индексы в mysql, подтверждает эффективность применения современных
технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое индексы в mysql, индекс, explain, оптимизация запросов, план запроса, red-метод для анализа производительности
и для чего все это нужно, а если не понял, или есть замечания,
то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Базы данных - MySql (Maria DB)
Комментарии
Оставить комментарий
Базы данных - MySql (Maria DB)
Термины: Базы данных - MySql (Maria DB)