Лекция
Привет, Вы узнаете о том , что такое оптимизация многодиапазонного чтения, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое оптимизация многодиапазонного чтения, mrr , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Чтение строк с использованием сканирования диапазона во вторичном индексе может привести к множеству случайных обращений к диску к базовой таблице, когда таблица большая и не хранится в кэше механизма хранения. С оптимизацией Disk-Sweep Multi-Range Read (MRR) MySQL пытается уменьшить количество случайных обращений к диску для сканирования диапазона, сначала сканируя только индекс и собирая ключи для соответствующих строк. Затем ключи сортируются и, наконец, строки извлекаются из базовой таблицы в порядке первичного ключа. Мотивация для Disk-sweep MRR состоит в том, чтобы уменьшить количество случайных обращений к диску и вместо этого добиться более последовательного сканирования данных базовой таблицы.
оптимизация многодиапазонного чтения обеспечивает следующие преимущества:
MRR позволяет получать доступ к строкам данных последовательно, а не в случайном порядке, на основе кортежей индекса. Сервер получает набор индексных кортежей, удовлетворяющих условиям запроса, сортирует их в соответствии с порядком идентификаторов строк данных и использует отсортированные кортежи для получения строк данных по порядку. Это делает доступ к данным более эффективным и менее дорогим.
MRR позволяет выполнять пакетную обработку запросов на доступ к ключу для операций, требующих доступа к строкам данных через кортежи индекса, например сканирование индекса диапазона и эквивалентные соединения, которые используют индекс для атрибута соединения. MRR выполняет итерацию по последовательности диапазонов индексов для получения подходящих кортежей индексов. По мере накопления этих результатов они используются для доступа к соответствующим строкам данных. Нет необходимости получать все индексные кортежи перед началом чтения строк данных.
Следующие сценарии показывают, когда оптимизация MRR может быть выгодной:
Сценарий А: МРВ может быть использован для InnoDBи MyISAMтаблиц для сканирования диапазона индекса и оборудов-операции соединения.
Часть индексных кортежей накапливается в буфере.
Кортежи в буфере сортируются по идентификатору строки данных.
Доступ к строкам данных осуществляется в соответствии с упорядоченной последовательностью кортежей индекса.
Сценарий B: MRR можно использовать для NDB таблиц для сканирования индекса с несколькими диапазонами или при выполнении равномерного соединения по атрибуту.
Часть диапазонов, возможно, диапазонов с одним ключом, накапливается в буфере на центральном узле, куда отправляется запрос.
Диапазоны отправляются на исполнительные узлы, которые обращаются к строкам данных.
Доступные строки упаковываются в пакеты и отправляются обратно в центральный узел.
Полученные пакеты со строками данных помещаются в буфер.
Строки данных читаются из буфера.
Когда используется MRR, отображается Extraстолбец на EXPLAIN выходе Using MRR.
Для InnoDB и MyISAM не используйте MRR, если для получения результата запроса нет необходимости обращаться к полным строкам таблицы. Об этом говорит сайт https://intellect.icu . Это тот случай, если результаты могут быть получены полностью на основе информации в индексных кортежах (через покрывающий индекс ); MRR не дает никаких преимуществ.
Два optimizer_switch флага системных переменных предоставляют интерфейс для использования оптимизации MRR. В mrrуправлении флагом будь MRR включено. Если mrr включен ( on), mrr_cost_basedфлаг определяет, пытается ли оптимизатор сделать выбор на основе затрат между использованием и неиспользованием MRR ( on) или использует MRR, когда это возможно ( off). По умолчанию mrrесть onи mrr_cost_based есть on. См. «Переключаемые оптимизации» .
Для MRR подсистема хранения использует значение read_rnd_buffer_sizeсистемной переменной в качестве ориентира для определения того, сколько памяти он может выделить для своего буфера. Механизм использует до read_rnd_buffer_sizeбайтов и определяет количество диапазонов для обработки за один проход.
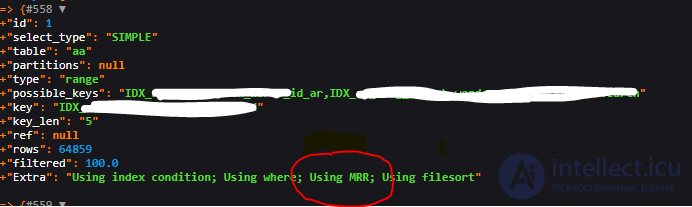
Рис Пример получение инфорации если Using MRR при EXPLAIN в MySQL
Вторичные индексы InnoDB, как известно, ссылаются на значение первичного ключа, а физически на дисках данные лежат рядом с первичным ключом и отсортированы по по этому самому первичному ключу. Значит, если в индексе написано, что вам нужны id 9, 6, 50, 8 и 7, выгоднее их читать с диска не в таком порядке, а пересортировать и прочитать двумя запросами: 6-9 и 50. Так получаем 2 запроса случайного чтения вместо 5. Это весьма полезно для HDD с медленной механикой, но еще и приносит свои, хоть и более скромные, дивиденды для SSD - они хоть и на порядки быстрее HDD в случайном чтении, но и им тоже удобнее последовательное, а не случайное чтение.
Вот MRR этим как раз и занимается. Сначала получает список необходимых ключей от индекса, сортирует этот список и запрашивает у диска не по одной записи в случайных местах, а более крупными последовательными блоками.
Замечу, что MRR вступает в дело, если надо много чего прочитать с диска. Т.е. холодное чтение, данных для этой выборки по большей части нет в памяти. Разумеется, это далеко не быстрая штука.
И еще момент: у вас в запросе нет order by, но есть limit - это значит, что вам все равно, какие именно строки выбрать. Mysql в таком случае будет возвращать любые подходящие строки в любом порядке на свое усмотрение.
Данная статья про оптимизация многодиапазонного чтения подтверждают значимость применения современных методик для изучения данных проблем. Надеюсь, что теперь ты понял что такое оптимизация многодиапазонного чтения, mrr и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Из статьи мы узнали кратко, но содержательно про оптимизация многодиапазонного чтения
Комментарии