Лекция
Привет, Вы узнаете о том , что такое денормализация, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое денормализация, реализация денормализации , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
денормализация (англ. denormalization) — намеренное приведение структуры базы данных в состояние, не соответствующее критериям нормализации, обычно проводимое с целью ускорения операций чтения из базы за счет добавления избыточных данных.
Устранение аномалий данных в соответствии с теорией реляционных баз данных требует, чтобы любая база данных была нормализована, то есть соответствовала требованиям нормальных форм. Соответствие требованиям нормализации минимизирует избыточность данных в базе данных и обеспечивает отсутствие многих видов логических ошибок обновления и выборки данных.
Однако при запросах большого количества данных операция соединения нормализованных отношений выполняется неприемлемо долго. Вследствие этого в ситуациях, когда производительность таких запросов невозможно повысить иными средствами, может проводиться денормализация — композиция нескольких отношений (таблиц) в одну, которая, как правило, находится во второй, но не в третьей нормальной форме. Новое отношение фактически является хранимым результатом операции соединения исходных отношений.
За счет такого перепроектирования операция соединения при выборке становится ненужной и запросы выборки, которые ранее требовали соединения, работают быстрее.
Следует помнить, что денормализация всегда выполняется за счет повышения риска нарушения целостности данных при операциях модификации. Поэтому денормализацию следует проводить в крайнем случае, если другие меры повышения производительности невозможны. Идеально, если денормализованная БД используется только на чтение.
Кроме того, следует учесть, что ускорение одних запросов на денормализованной БД может сопровождаться замедлением других запросов, которые ранее выполнялись отдельно на нормализованных отношениях.
Существует два основных подхода при денормализации данных:
Допустим у нас есть таблицы такой структуры:
Вставка нового пользователя будет выглядеть так:
Для выборки названия города или страны пользователя нам понадобится делать два запроса либо один JOIN:
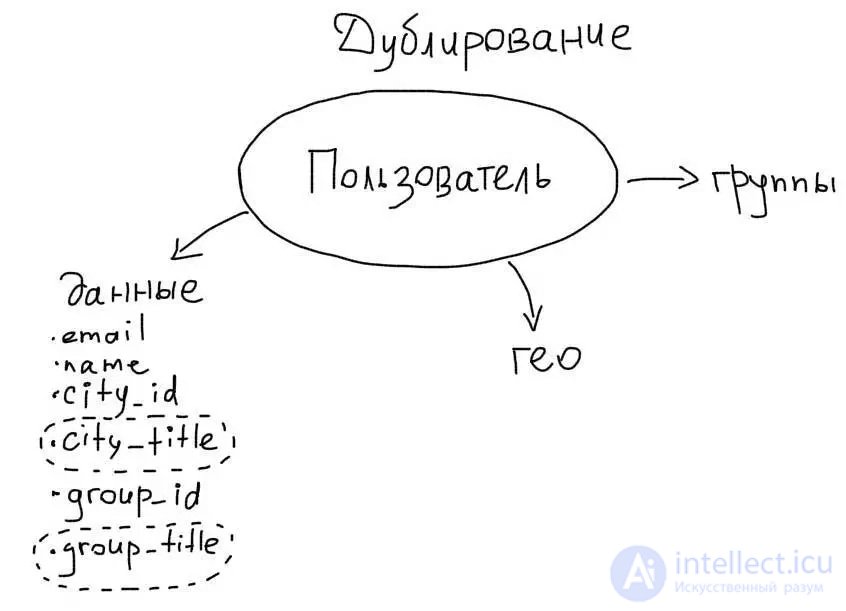
Для того, чтобы использовать преимущество дублирования, нам понадобится добавить колонку city_title в таблицу users:
Во время вставки пользователя, в эту колонку нужно будет сохранять название города. Теперь вставка нового пользователя будет выглядеть так:
В результате, мы сможем выбрать данные пользователя сразу с названием города за один простой запрос:
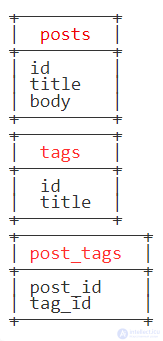
Связи один ко многим также можно оптимизировать используя дублирование. Представим в качестве примера таблицы постов с метками в блоге:
Для выборки меток поста нам понадобится сделать два отдельных запроса (или один JOIN):
Вместо этого мы могли бы сохранить список меток в отдельной текстовой колонке через запятую:
posts
id
title
body
tags
Тогда при выводе постов не будет необходимости делать дополнительные запросы для получения списка меток.
2. Предварительная подготовка данныхАгрегатные запросы обычно наиболее тяжелые. Например, получение количества записей по определенному условию:
Кроме дублирования данных из одних таблиц в другие, можно также сохранять данные, которые рассчитываются. Тогда можно будет избежать тяжелых агрегатных выборок.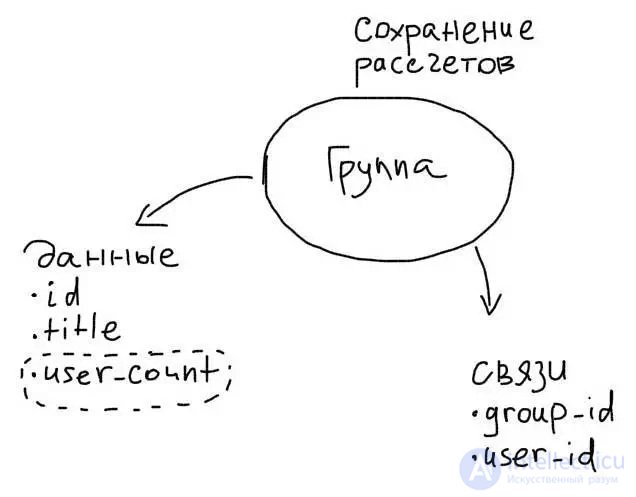
Например, для хранения количества пользователей в группе, необходимо добавить дополнительную колонку:
groups
id
title
user_count
Тогда, при каждом добавлении пользователя, необходимо будет увеличивать значение в колонке user_count на 1:
Такая схема хранения данных обычно называется факты + измерения:

При этом у нас есть таблицы с основными данными (факты) и таблицы измерений, где сохраняются расчетные данные.
Вертикальная структура использует строки таблицы для хранения названия полей и их значений.
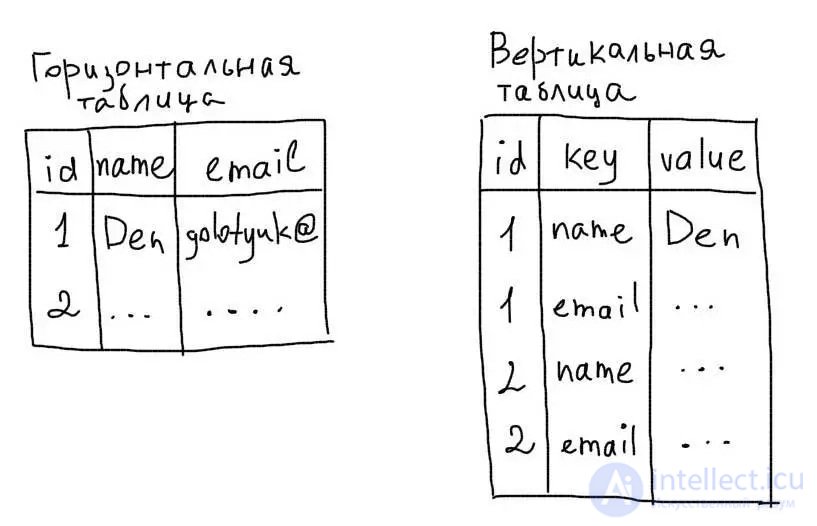
Преимуществом хранения данных в таком виде является возможность удобного шардинга. Об этом говорит сайт https://intellect.icu . Кроме это будет возможность добавлять новые поля без изменения структуры таблицы.
Вертикальная структура хорошо подойдет для таблиц, в которых могут меняться колонки.
Аналогичной структурой и преимуществами обладают Key-Value базы данных.
Рассмотрим некоторые распространенные ситуации, в которых денормализация может оказаться полезна.
В запросах к полностью нормализованной базе нередко приходится соединять до десятка, а то и больше, таблиц. А каждое соединение — операция весьма ресурсоемкая. Как следствие, такие запросы кушают ресурсы сервера и выполняются медленно.
В такой ситуации может помочь:
Зачастую медленно выполняются и потребляют много ресурсов запросы, в которых производятся какие-то сложные вычисления, особенно при использовании группировок и агрегатных функций (Sum, Max и т.п.). Иногда имеет смысл добавить в таблицу 1-2 дополнительных столбца, содержащих часто используемые (и сложно вычисляемые) расчетные данные.
Предположим, что необходимо определить общую стоимость каждого заказа. Для этого сначала следует определить стоимость каждого продукта (по формуле «количество единиц продукта» * «цена единицы продукта» – скидка). После этого необходимо сгруппировать стоимости по заказам.
Выполнение этого запроса является достаточно сложным и, если в базе данных хранятся сведения о большом количестве заказов, может занять много времени. Вместо выполнения такого запроса можно на этапе размещения заказа определить его стоимость и сохранить ее в отдельном столбце таблицы заказов. В этом случае для получения требуемого результата достаточно извлечь из данного столбца предварительно рассчитанные значения.
Создание столбца, содержащего предварительно рассчитываемые значения, позволяет значительно сэкономить время при выполнении запроса, однако требует своевременного изменения данных в этом столбце.
Если у нас в базе данных есть большие таблицы, содержащие длинные поля (Blob, Long и т.п.), то серьезно ускорить выполнение запросов к такой таблице мы сможем, если вынесем длинные поля в отдельную таблицу. Хотим мы, скажем, создать в базе каталог фотографий, в том числе хранить в blob-полях и сами фотографии (профессионального качества, с высоким разрешением, и соответствующего размера). С точки зрения нормализации абсолютно правильной будет такая структура таблицы:
ID фотографии
ID автора
ID модели фотоаппарата
сама фотография (blob-поле).
А сейчас представим, сколько времени будет работать запрос, подсчитывающий количество фотографий, сделанных каким-либо автором…
Правильным решением (хотя и нарушающим принципы нормализации) в такой ситуации будет создать еще одну таблицу, состоящую всего из двух полей — ID фотографии и blob-поле с самой фотографией. Тогда выборки из основной таблицы (в которой огромного blob-поля сейчас уже нет) будут идти моментально, ну а когда захотим посмотреть саму фотографию — что ж, подождем…
Один из способов определить, насколько оправданны те или иные шаги, — провести анализ в терминах затрат и возможных выгод. Во сколько обойдется денормализованной моделью данных?
Определить требования (чего хотим достичь) -> определить требования к данным (что нужно соблюдать) -> найти минимальный шаг, удовлетворяющий эти требования -> подсчитать затраты на реализацию -> реализовать.
Затраты включают в себя физические аспекты, такие как дисковое пространство, ресурсы, необходимые для управления этой структурой, и утраченные возможности из-за временных задержек, связанных с обслуживанием этого процесса. За денормализацию нужно платить. В денормализованной базе данных повышается избыточность данных, что может повысить производительность, но потребует больше усилий для контроля за связанными данными. Усложнится процесс создания приложений, поскольку данные будут повторяться и их труднее будет отслеживать. Кроме того, осуществление ссылочной целостности оказывается не простым делом — связанные данные оказываются разделенными по разным таблицам.
К преимуществам относится более высокая производительность при выполнении запроса и возможность получить при этом более быстрый ответ. Кроме того, можно получить и другие преимущества, в том числе увеличение пропускной способности, уровня удовлетворенности клиентов и производительности, а также более эффективное использование инструментария внешних разработчиков.
Например, 72% из тысячи запросов, ежедневно генерируемых предприятием, представляют собой запросы уровня сводных, а не детальных данных. При использовании таблицы сводных данных запросы выполняются примерно за 6 секунд вместо 4 минут, т.е. время обработки меньше на 3000 минут. Даже с поправкой на те 100 минут, которые необходимо еженедельно тратить на поддержку таблиц сводных данных, в итоге экономится 2500 минут в неделю, что полностью оправдывает создание таблицы сводных данных. Со временем может случиться так, что большая часть запросов будет обращена не к сводным данным, а к детальным данным. Чем меньше число запросов, использующих таблицу сводных данных, тем проще от нее отказаться, не затрагивая другие процессы.
Чтобы не ограничивать возможности базы данных, важные для бизнеса, необходимо придерживаться стратегии сосуществования, а не замены, т.е. сохранить детальные таблицы для глубинного анализа, добавив к ним денормализованные структуры. Например, счетчик посещений. Для бизнеса необходимо знать количество посещений веб-станицы. Но для анализа (по периодам, по странам …) нам очень вероятно понадобятся детальные данные – таблица с информацией о каждом посещении.
Можно денормализовать структуру базы данных и при этом продолжать пользоваться преимуществами нормализации, если пользоваться триггерами баз данных для сохранения целостности (integrity) информации, идентичности дублирующихся данных.
К примеру, при добавлении вычисляемого поля на каждый из столбцов, от которых вычисляемое поле зависит, вешается триггер, вызывающий единую хранимую процедуру (это важно!), которая и записывает нужные данные в вычисляемое поле. Надо только не пропустить ни один из столбцов, от которых зависит вычисляемое поле.
если не использовать встроенные триггеры и хранимых процедуры, то заботиться об обеспечении непротиворечивости данных в денормализованной базе должны разработчики приложений.
По аналогии с триггерами, должна быть одна функция, обновляющая все поля, зависящие от изменяемого поля.
При денормализации важно сохранить баланс между повышением скорости работы базы и увеличением риска появления противоречивых данных, между облегчением жизни программистам, пишущим Select'ы, и усложнением задачи тех, кто обеспечивает наполнение базы и обновление данных. Поэтому проводить денормализацию базы надо очень аккуратно, очень выборочно, только там, где без этого никак не обойтись.
Если заранее нельзя подсчитать плюсы и минусы денормализации, то изначально необходимо реализовать модель с нормализованными таблицами, и лишь затем, для оптимизации проблемных запросов проводить денормализацию.
Денормализацию важно внедрять постепенно и только для тех случаев, когда присутствуют повторные выборки связанных данных с разных таблиц. Помните, при дублировании данных вырастит количество записей, но уменьшится количество чтений. Рассчитываемые данные также удобно сохранять в колонках, чтобы избежать ненужных агрегатных выборок.
Вообще чобы изучить БД программист должен знать и уметь пользоваться
| Концепции |
|
|---|---|
| Объекты |
|
| Ключи |
|
| SQL |
|
| СУБД |
|
| Компоненты | |
Анализ данных, представленных в статье про денормализация, подтверждает эффективность применения современных технологий для обеспечения инновационного развития и улучшения качества жизни в различных сферах. Надеюсь, что теперь ты понял что такое денормализация, реализация денормализации и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL







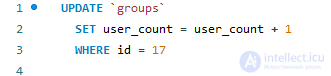
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL