Лекция
Привет, Вы узнаете о том , что такое big data, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое big data, hbase , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Наконец-то долгожданная четвертая статья нашего цикла о больших данных. В этой статье мы поговорим про такой замечательный инструмент как Hbase, который в последнее время завоевал большую популярность: например Facebook использует его в качестве основы своей системы обмена сообщений, а мы в data-centric alliance используем hbase в качестве основного хранилища сырых данных для нашей платформы управления данными Facetz.DCA
В статье будет рассказано про концепцию Big Table и ее свободную реализацию, особенности работы и отличие как от классических реляционных баз данных (таких как MySQL и Oracle), так и key-value хранилищ, таких как Redis, Aerospike и memcached.
Заинтересовало? Добро пожаловать под кат.
Как обычно — начнем с истории вопроса. Как и многие другие проекты из области BigData, Hbase зародилась из концепции которая была разработана в компании Google. Принципы лежащие в основе Hbase, были описаны в статье «Bigtable: A Distributed Storage System for Structured Data».
Как мы рассматривали в прошлых статьях — обычные файлы довольно неплохо подходят для пакетной обработки данных, с использованием парадигмы MapReduce.
С другой стороны информацию хранящуюся в файлах довольно неудобно обновлять; Файлы также лишены возможности произвольного доступа. Для быстрой и удобной работы с произвольным доступом есть класс nosql-систем типа key-value storage, таких как Aerospike, Redis, Couchbase, Memcached. Однако в обычно в этих системах очень неудобна пакетная обработка данных. Hbase представляет из себя попытку объединения удобства пакетной обработки и удобства обновления и произвольного доступа.

Hbase — это распределенная, колоночно-ориентированная, мультиверсионная база типа «ключ-значение».
Данные организованы в таблицы, проиндексированные первичным ключом, который в Hbase называется RowKey.
Для каждого RowKey ключа может храниться неограниченны набор атрибутов (или колонок).
Колонки организованны в группы колонок, называемые Column Family. Как правило в одну Column Family объединяют колонки, для которых одинаковы паттерн использования и хранения.
Для каждого аттрибута может храниться несколько различных версий. Разные версии имеют разный timestamp.
Записи физически хранятся в отсортированном по RowKey порядке. При этом данные соответствующие разным Column Family хранятся отдельно, что позволяет при необходимости читать данные только из нужного семейства колонок.
При удалении определенного атрибута физически он сразу не удаляется, а лишь маркируется специальным флажком tombstone. Физическое удаление данных произойдет позже, при выполнении операции Major Compaction.
Атрибуты, принадлежащие одной группе колонок и соответствующие одному ключу физически хранятся как отсортированный список. Любой атрибут может отсутствовать или присутствовать для каждого ключа, при этом если атрибут отсутствует — это не вызывает накладных расходов на хранение пустых значений.
Список и названия групп колонок фиксирован и имеет четкую схему. На уровне группы колонок задаются такие параметры как time to live (TTL) и максимальное количество хранимых версий. Если разница между timestamp для определенно версии и текущим временем больше TTL — запись помечается к удалению. Если количество версий для определенного атрибута превысило максимальное количество версий — запись также помечается к удалению.

Модель данных Hbase можно запомнить как соответствие ключ значение:
<table, RowKey, Column Family, Column, timestamp> -> Value
Список поддерживаемых операций в hbase весьма прост. Поддерживаются 4 основные операции:
— Put: добавить новую запись в hbase. Timestamp этой записи может быть задан руками, в противном случае он будет установлен автоматически как текущее время.
— Get: получить данные по определенному RowKey. Можно указать Column Family, из которой будем брать данные и количество версий которые хотим прочитать.
— Scan: читать записи по очереди. Можно указать запись с которой начинаем читать, запись до которой читать, количество записей которые необходимо считать, Column Family из которой будет производиться чтение и максимальное количество версий для каждой записи.
— Delete: пометить определенную версию к удалению. Физического удаления при этом не произойдет, оно будет отложено до следующего Major Compaction (см. ниже).
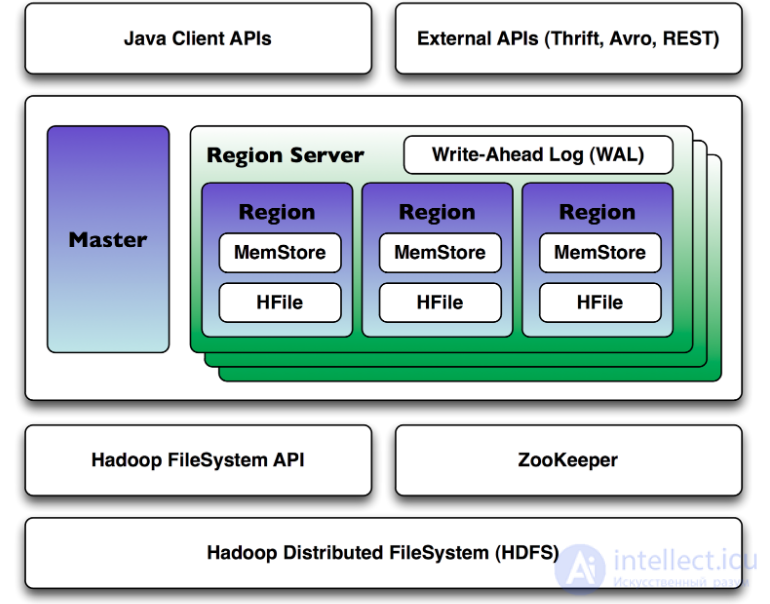
Hbase является распределенной базой данных, которая может работать на десятках и сотнях физических серверов, обеспечивая бесперебойную работу даже при выходе из строя некоторых из них. Поэтому архитектура hbase довольна сложна по сравнению с классическими реляционными базами данных.
Hbase для своей работы использует два основных процесса:
1. Region Server — обслуживает один или несколько регионов. Регион — это диапазон записей соответствующих определенному диапазону подряд идущих RowKey. Каждый регион содержит:
2. Master Server — главный сервер в кластере hbase. Master управляет распределением регионов по Region Server’ам, ведет реестр регионов, управляет запусками регулярных задач и делает другую полезную работу.
Для координации действий между сервисами Hbase использует Apache ZooKeeper, специальный сервис предназначенный для управления конфигурациями и синхронизацией сервисов.
При увеличении количества данных в регионе и достижении им определенного размера Hbase запускает split, операцию разбивающую регион на 2. Для того чтобы избежать постоянных делений регионов — можно заранее задать границы регионов и увеличить их максимальный размер.
Так как данные по одному региону могут храниться в нескольких HFile, для ускорения работы Hbase периодически их сливает воедино. Эта операция в Hbase называется compaction. Compaction’ы бывают двух видов:
Самый простой способ начать работу с Hbase — воспользоваться утилитой hbase shell. Она доступна сразу после установки hbase на любой ноде кластера hbase.

Hbase shell представляет из себя jruby-консоль c встроенной поддержкой всех основных операций по работе с Hbase. Ниже приведен пример создания таблицы users с двумя column family, выполнения некоторых манипуляций с ней и удаление таблицы в конце на языке hbase shell:
create 'users', {NAME => 'user_profile', VERSIONS => 5}, {NAME => 'user_posts', VERSIONS => 1231231231}
put 'users', 'id1', 'user_profile:name', 'alexander'
put 'users', 'id1', 'user_profile:second_name', 'alexander'
get 'users', 'id1'
put 'users', 'id1', 'user_profile:second_name', 'kuznetsov'
get 'users', 'id1'
get 'users', 'id1', {COLUMN => 'user_profile:second_name', VERSIONS => 5}
put 'users', 'id2', 'user_profile:name', 'vasiliy'
put 'users', 'id2', 'user_profile:second_name', 'ivanov'
scan 'users', {COLUMN => 'user_profile:second_name', VERSIONS => 5}
delete 'users', 'id1', 'user_profile:second_name'
get 'users', 'id1'
disable 'users'
drop 'users'
Как и большинство других hadoop-related проектов hbase реализован на языке java, поэтому и нативный api доступен для языке java. Native API довольно неплохо задокументирован на официальном сайте. Вот пример использования Hbase API взятый оттуда же:
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
// Class that has nothing but a main.
// Does a Put, Get and a Scan against an hbase table.
// The API described here is since HBase 1.0.
public class MyLittleHBaseClient {
public static void main(String[] args) throws IOException {
// You need a configuration object to tell the client where to connect.
// When you create a HBaseConfiguration, it reads in whatever you've set
// into your hbase-site.xml and in hbase-default.xml, as long as these can
// be found on the CLASSPATH
Configuration config = HBaseConfiguration.create();
// Next you need a Connection to the cluster. Create one. When done with it,
// close it. A try/finally is a good way to ensure it gets closed or use
// the jdk7 idiom, try-with-resources: see
// https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html
//
// Connections are heavyweight. Create one once and keep it around. From a Connection
// you get a Table instance to access Tables, an Admin instance to administer the cluster,
// and RegionLocator to find where regions are out on the cluster. As opposed to Connections,
// Table, Admin and RegionLocator instances are lightweight; create as you need them and then
// close when done.
//
Connection connection = ConnectionFactory.createConnection(config);
try {
// The below instantiates a Table object that connects you to the "myLittleHBaseTable" table
// (TableName.valueOf turns String into a TableName instance).
// When done with it, close it (Should start a try/finally after this creation so it gets
// closed for sure the jdk7 idiom, try-with-resources: see
// https://docs.oracle.com/javase/tutorial/essential/exceptions/tryResourceClose.html)
Table table = connection.getTable(TableName.valueOf("myLittleHBaseTable"));
try {
// To add to a row, use Put. A Put constructor takes the name of the row
// you want to insert into as a byte array. In HBase, the Bytes class has
// utility for converting all kinds of java types to byte arrays. In the
// below, we are converting the String "myLittleRow" into a byte array to
// use as a row key for our update. Once you have a Put instance, you can
// adorn it by setting the names of columns you want to update on the row,
// the timestamp to use in your update, etc. If no timestamp, the server
// applies current time to the edits.
Put p = new Put(Bytes.toBytes("myLittleRow"));
// To set the value you'd like to update in the row 'myLittleRow', specify
// the column family, column qualifier, and value of the table cell you'd
// like to update. The column family must already exist in your table
// schema. The qualifier can be anything. All must be specified as byte
// arrays as hbase is all about byte arrays. Lets pretend the table
// 'myLittleHBaseTable' was created with a family 'myLittleFamily'.
p.add(Bytes.toBytes("myLittleFamily"), Bytes.toBytes("someQualifier"),
Bytes.toBytes("Some Value"));
// Once you've adorned your Put instance with all the updates you want to
// make, to commit it do the following (The HTable#put method takes the
// Put instance you've been building and pushes the changes you made into
// hbase)
table.put(p);
// Now, to retrieve the data we just wrote. The values that come back are
// Result instances. Generally, a Result is an object that will package up
// the hbase return into the form you find most palatable.
Get g = new Get(Bytes.toBytes("myLittleRow"));
Result r = table.get(g);
byte [] value = r.getValue(Bytes.toBytes("myLittleFamily"),
Bytes.toBytes("someQualifier"));
// If we convert the value bytes, we should get back 'Some Value', the
// value we inserted at this location.
String valueStr = Bytes.toString(value);
System.out.println("GET: " + valueStr);
// Sometimes, you won't know the row you're looking for. In this case, you
// use a Scanner. This will give you cursor-like interface to the contents
// of the table. To set up a Scanner, do like you did above making a Put
// and a Get, create a Scan. Adorn it with column names, etc.
Scan s = new Scan();
s.addColumn(Bytes.toBytes("myLittleFamily"), Bytes.toBytes("someQualifier"));
ResultScanner scanner = table.getScanner(s);
try {
// Scanners return Result instances.
// Now, for the actual iteration. One way is to use a while loop like so:
for (Result rr = scanner.next(); rr != null; rr = scanner.next()) {
// print out the row we found and the columns we were looking for
System.out.println("Found row: " + rr);
}
// The other approach is to use a foreach loop. Scanners are iterable!
// for (Result rr : scanner) {
// System.out.println("Found row: " + rr);
// }
} finally {
// Make sure you close your scanners when you are done!
// Thats why we have it inside a try/finally clause
scanner.close();
}
// Close your table and cluster connection.
} finally {
if (table != null) table.close();
}
} finally {
connection.close();
}
}
}
Для работы из других языков программирования Hbase предоставляет Thrift API и Rest API. На базе них построены клиенты для всех основных языков программирования: python, PHP, Java Script и тд.
1. Hbase «из коробки» интегрируется с MapReduce, и может быть использована в качестве входных и выходных данных с помощью специальных TableInputFormat и TableOutputFormat.
2. Очень важно правильно выбрать RowKey. RowKey должен обеспечивать хорошее равномерное распределение по регионам, в противном случае есть риск возникновения так называемых «горячих регионов» — регионов которые используются гораздо чаще остальных, что приводит к неэффективному использованию ресурсов системы.
3. Если данные заливаются не единично, а сразу большими пачками — Hbase поддерживает специальный механизм BulkLoad, который позволяет заливать данные намного быстрее чем используя единичные Put’ы. BulkLoad по сути представляет из себя двухшаговую операцию:
— Формирование HFile без участия put’ов при помощи специального MapReduce job’a
— Подкладывание этих файликов напрямую в Hbase.
4. Hbase поддерживает вывод своих метрик в сервер мониторинга Ganglia. Это может быть очень полезно при администрировании Hbase для понимания сути происходящих с hbase проблем.
В качестве примера можем рассмотреть основную таблицу с данными, которая у нас в Data-Centric Aliance используется для хранения информации о поведении пользователей в интернете.
В качестве RowKey используется идентификатор пользователя, в качестве которого используется GUUID, строчка специально генерируемая таким образом, чтобы быть уникальной во всем мире. GUUID’ы распределены равномерно, что дает хорошее распределение данных по серверам.
В нашем хранилище используются две column family:
— Data. В этой группе колонок хранятся данные, которые теряют свою актуальность для рекламных целей, такие как факты посещения пользователем определенных URL. TTL на эту Column Family установлен в размере 2 месяца, ограничение по количеству версий — 2000.
— LongData. В этой группе колонок хранятся данные, которые не теряют свою актуальность в течение долгого времени, такие как пол, дата рождения и другие «вечные» характеристики пользователя
Каждый тип фактов о пользователе хранится в отдельной колонке. Например в колонке Data:_v хранятся URL, посещенные пользователем, а в колонке LongData:gender — пол пользователя.
В качестве timestamp хранится время регистрации этого факта. Например в колонке Data:_v — в качестве timestamp используется время захода пользователем на определенный URL.
Такая структура хранения пользовательских данных очень хорошо ложится на наш паттерн использования и позволяет быстро обновлять данные о пользователях, быстро доставать всю необходимую информацию о пользователях, и, используя MapReduce, быстро обрабатывать данные о всех пользователях сразу.
Hbase довольно сложна в администрировании и использовании, поэтому прежде чем использовать hbase есть смысл обратить внимание на альтернативы:
Использование Hbase оправдано когда:
— Данных много и они не влезают на один компьютер
— Данные часто обновляются и удаляются
— В данных присутствует явный «ключ» по к которому удобно привязывать все остальное
— Нужна пакетная обработка данных
— Нужен произвольный доступ к данным по определенным ключам
В данной статье мы рассмотрели Hbase — мощное средство для хранения и обновления данных в экосистеме hadoop, показали модель данных Hbase, ее архитектуру и особенности работы с ней.
В следующих статьях речь пойдет о средствах, упрощающих работу с MapReduce, таких как Apache Hive и Apache Pig.
Прочтение данной статьи про big data позволяет сделать вывод о значимости данной информации для обеспечения качества и оптимальности процессов. Надеюсь, что теперь ты понял что такое big data, hbase и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL