Лекция
Привет, Вы узнаете о том , что такое структуры хранения данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое структуры хранения данных, методы доступа , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
В данном разделе рассматриваются некоторые вопросы, связанные с физическим хранением данных на внешних запоминающих устройствах прямого доступа, то есть, прежде всего, на дисковых запоминающих устройствах, и доступом к хранимым данным при выполнении информационных запросов пользователей.
Ранее в разделе 3 была рассмотрена трехуровневая архитектура систем с базами данных. Как уже говорилось выше, одной из причин введения нескольких уровней представления данных является обеспечение независимости прикладных программных систем от конкретных структур и способов организации данных при их хранении на физических носителях. Такая независимость позволяет при разработке прикладных информационных систем использовать более высокоуровневые и абстрактные формы (модели) представления данных, максимально приближенные к понятиям моделируемой предметной области. Это позволяет существенно облегчить процесс создания сложных информационных систем, не загружая его необходимостью оперирования деталями, связанными с представлением данных на более низких, в том числе и физическом, уровнях.
Однако на практике, к сожалению, обеспечить полную независимость и изолированность различных уровней представления данных при проектировании прикладных информационных систем не удается. Одной из главных причин является требование обеспечения доступа прикладной системы к хранимым данным эффективного с точки зрения минимизации времени доступа. Выбор же решений, наиболее эффективных с точки зрения времени выполнения запросов, предполагает знание особенностей выполнения реализующих их процессов, происходящих в подсистемах, представляющих более низкие уровни архитектуры информационной системы.
Например, при использовании для работы с данными языка SQL один и тот же результат может быть получен с помощью различных эквивалентных форм запросов. Реальное же время выполнения этих запросов может существенно различаться, особенно при большом объеме обрабатываемых данных. В связи с этим для выбора наиболее эффективного варианта грамотный разработчик уже на этапе формирования SQL-запроса должен понимать, в последовательность каких алгебраических операций будет преобразован конкретный запрос, при его исполнении подсистемой СУБД, и какие действия могут потребоваться от дисковой подсистемы для физического доступа к запрашиваемым данным на конкретном носителе.
Необходимость повышенного внимания к структурам хранимых данных и методам доступа к ним обусловлена тем, что реальное время доступа к данным в системах дисковой памяти существенно больше времени доступа к данным, размещенным в оперативной памяти компьютера.
Рассмотрим основные принципы, используемые для хранения отношений на дисковых запоминающих устройствах, и методы организации доступа к хранимым данным.
На рис.11.1 приведена схема взаимодействия СУБД с другими подсистемами, участвующими в процессах доступа к хранимым данным.
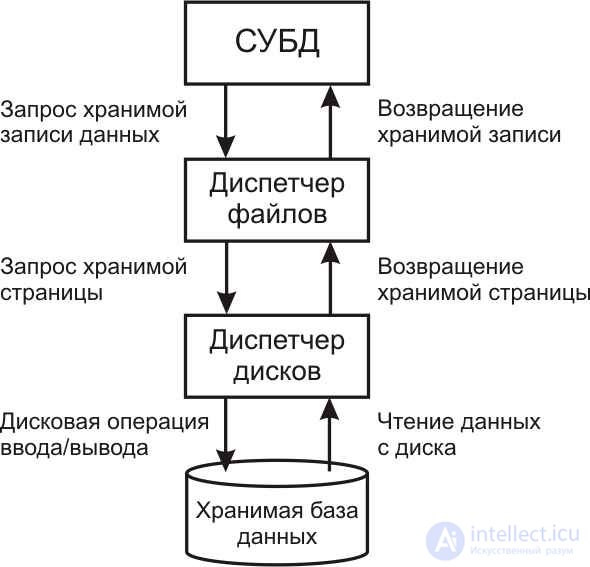
Рис.11.1. Схема взаимодействия СУБД, диспетчера файлов и диспетчера дисков при доступе к хранимым данным
Схематично, с точки зрения СУБД, отношения базы данных выглядят как набор записей файлов. Обычно записи файлов – это кортежи отношения. Каждая запись обладает уникальным системным идентификатором (RowID), который не изменяется во все время существования записи. Эти записи могут просматриваться с помощью диспетчера файлов. При выполнении запроса к данным СУБД обращается к файловой системе, которая является компонентом операционной системы и обеспечивает доступ к соответствующим записям файлов. В свою очередь с точки зрения файловой системы хранимая на внешней памяти и считываемая в оперативную память база данных выглядит как набор страниц данных. Дело в том, что современные запоминающие устройства функционируют таким образом, что минимальной «порцией» данных в операции ввода/вывода, является страница, содержащая определенное фиксированное число записей.
Обычно каждый картеж хранится во внешней памяти целиком на одной странице. Отсюда возникает, кстати, ограничение в СУБД на максимальную длину кортежа. Как правило, в одной странице хранят кортежи одного отношения, хотя возможны решения, когда в одной странице размещают кортежи разных логически связанных отношений (см. ниже про кластеризацию данных).
Реально страницы данных могут размещаться на дисках или дублироваться (кэшироваться) в оперативной памяти. Диспетчер файлов определяет страницу, на которой находится искомая запись, и формирует запрос для доступа к соответствующей странице хранимых данных к подсистеме диспетчера дисков.
Диспетчер дисков осуществляет все дисковые операции ввода/вывода. Он работает непосредственно с хранимыми на дисках данными – определяет физическое расположение искомой страницы на дисковом носителе (цилиндры, дорожки, секторы) и обеспечивает соответствующее управление аппаратными средствами для реализации процесса ввода/вывода данных конкретной страницы.
В этой многоступенчатой процедуре доступа к хранимым данным наиболее медленными являются операции по непосредственному чтению/записи данных на физическом носителе, так как они связаны с механическими операциями позиционирования головок чтения/записи на соответствующие цилиндры, дорожки и секторы дисковой подсистемы. При реальной работе информационных систем с базами данных в запросах к данным обычно фигурируют не одна, а множество записей данных. Об этом говорит сайт https://intellect.icu . Поэтому существенное влияние на время доступа к такому множеству данных оказывает то, насколько близко друг к другу они расположены на физическом носителе, размещены ли они в одной или в разных физических страницах. От этих факторов существенно зависит время, затрачиваемое дисковой подсистемой на позиционирование головок чтения/записи при переходе от одной записи к другой.
В связи со сказанным, следует упомянуть один из используемых в промышленных СУБД методов повышения скорости доступа к хранимым данным, известный как кластеризация данных. Идея кластеризации данных состоит в том, чтобы хранить логически связанные записи базы данных на физическом носителе таким образом, чтобы минимизировать время, требуемое для перемещения головок чтения/записи при переходе от одной записи к другой. При этом может рассматриваться как внутрифайловая кластеризация, когда речь идет о записях одной реляционной таблицы базы данных, так и межфайловая кластеризация, когда в непосредственной близости на одной странице размещаются, например, записи нескольких таблиц, связанных с помощью внешних ключей.
Очевидно, что физическое размещение записей базы данных в соответствии с их логической взаимосвязью с целью минимизации времени доступа к данным на практике далеко не всегда осуществимо. В особенности, когда речь идет о данных, динамически изменяющихся во времени. Кроме того, при поиске данных по каким-либо условиям, касающимся значений атрибутов, требования к оптимальному размещению записей таблицы для разных атрибутов могут оказаться (и, как правило, оказываются) противоречивыми. Например, нельзя упорядочить записи таблицы в алфавитном порядке одновременно по двум и более атрибутам.
Эффективным методом повышения скорости доступа к данным без использования их физического упорядочивания и близкого размещения на дисковом носителе является индексирование.
Рассмотрим в качестве примера таблицу с данными о студентах и запрос о выборе всех студентов из некоторого города N. Если не использовать никаких специальных ухищрений, и если записи отношения не упорядочены в соответствии с алфавитным порядком значений поля Город, то для решения данной задачи должны быть последовательно просмотрены все записи таблицы и из них отобраны те, у которых значения атрибута Город равны заданному в условии выборки значению «N». При этом реальное количество отобранных записей может быть существенно меньше общего числа просмотренных при выполнении запроса записей.
Выполнение описанной задачи может быть значительно ускорено, если создать, как это показано на рис.11.2, дополнительную структуру данных, так называемый индексный файл городов, или просто индекс (index – указатель). В этом файле представлены все значения поля файла, соответствующего таблицеГородСтудент, но уже физически упорядоченные по алфавиту, с указателями на соответствующие записи файла таблицы Студент. Поиск нужного города в индексном файле может быть осуществлен существенно быстрее, чем в исходной таблице. Во-первых, из-за упорядоченного по алфавиту расположения наименований городов, благодаря чему не нужно просматривать все до одной записи файла. Во-вторых, физические размеры индексного файла существенно меньше файла таблицы Студент, для его размещения требуется меньше физических страниц, поэтому чтение его записи с диска будет происходить существенно быстрее.
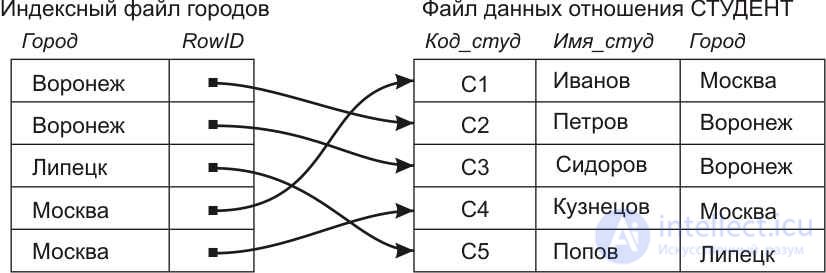
Рис.11.2. Использование индексирования для ускорения доступа к записям отношенияСТУДЕНТ
Индексы, приведенные на рис.11.2, иногда называют инвертированными списками. Если обычный файл отношения – это список указателей кортежа со значениями соответствующих полей, то индексный файл представляет собой список упорядоченных значений атрибута с указателями соответствующих записей-кортежей.
Для одного файла, представляющего отношение базы данных, могут формироваться одновременно несколько индексных файлов для разных его полей. Например, для приведенного на рис.11.2. файлаотношения СТУДЕНТ могут быть сформированы индексные файлы для полей КОД_СТУД и ИМЯ_СТУД. Более того, может быть сформирован индексный файл по составному атрибуту, то есть по комбинации полей. Комбинированный индекс по полю ГОРОД и полю ИМЯ_СТУД будет представлять собой список пар значений этих атрибутов, упорядоченный по значениям городов, а при одинаковых значениях поля ГОРОД– по именам студентов.
Недостатком рассмотренной выше и представленной на рис. 11.2 структуры индекса является то, что эффективность такого индекса будет падать с ростом числа записей индексируемого файла. В частности из-за того, что размер индексного файла также будет увеличиваться и, в конце концов, занимать не одну, а большее число страниц. В связи с этим в настоящее время для построения индексных файлов используется более сложная, но более эффективная иерархическая структура типа В-дерева (В-tree) («B» от англ. binary).
Причина использования для индексирования иерархических структур типа В-дерева заключается в желании избежать при поиске обязательного просмотра всех страниц индексного файла согласно его физической структуре. Этого можно достичь, если создать индекс следующего уровня уже для страниц самого индексного файла. Как мы знаем, страницы данных всегда считываются с диска в оперативную память целиком и, хотя в оперативной памяти нам все равно придется последовательно просматривать записи внутри загруженной страницы, это будет происходить гораздо быстрее, чем при поиске нужных записей на диске. Очевидно, что индекс следующего уровня будет содержать гораздо меньше записей, чем индекс первого уровня, что также способствует ускорению поиска. Такой индекс второго уровня называют неплотным индексом, в отличие от плотного, у которого число записей равно числу записей индексируемого файла.
Рассмотренная идея может быть развита дальше в направлении создания многоуровневой древовидной индексной структуры. Пример такой структуры, называемой В-деревом, приведен на рис.11.3.
C точки зрения внешнего логического представления В-дерево – это сбалансированное сильно ветвистое дерево во внешней памяти. Сбалансированность означает, что длина пути от корня дерева к любому его листу одна и та же. Ветвистость дерева – это свойство каждого узла дерева ссылаться на большое число узлов-потомков. Физическая организация В‑дерева представляется как мультисписочная структура страниц внешней памяти, т. е. каждому узлу дерева соответствует страница внешней памяти.
Индекс, построенный на основе В-дерева, состоит из двух частей. Первая – это набор страниц с последовательностями значений (ключей) с указателями на записи индексируемого файла с реальными данными (нижний ряд на рис.13.3). Вторая – набор неплотных индексов, обеспечивающих быстрый доступ к страницам набора последовательностей. Комбинация набора последовательностей и набора индексов называется В-плюс-деревом, или В+-деревом.
На самом верхнем уровне В+-дерева находится единственный элемент, так называемая корневая (root) страница, а на самом нижнем уровне дерева набор последовательностей с указанием на записи индексируемого файла, которые являются «листьями» дерева.

Рис.11.3. Пример структуры индекса типа В-дерева
Рассмотрим, например, как происходит поиск записи индексируемого файла, у которой индексируемое поле имеет значение Москва. Сравнение этого значения со значениями ключевой корневой страницы индексной структуры приводит по указателю ко второй странице следующего уровня дерева (так как Москва по алфавиту расположена ниже Липецка, но выше Ростова). Сравнение искомого значения со значениями ключей второй страницы среднего уровня приводит по указателю к четвертой странице нижнего (листового) уровня дерева (Москва по алфавиту выше Норильска), в которой находится сам указатель на соответствующую запись индексируемого файла данных.
Одним из недостатков обычных иерархических древовидных структур является нарушение их сбалансированности после операций удаления и вставки элементов дерева. Однако, достоинством В+-деревьев является то, что в них достаточно просто возможно автоматическое поддержание сбалансированности дерева, то есть поддержание более-менее равномерной заполненности страниц индексной структуры и одинаковой длины пути от корня до листа дерева для поиска любых значений не зависимо от их расположения в файле данных.
Рассмотрим алгоритм перестройки В-дерева при вставке в индексируемый файл новой записи.
В В-дереве производится поиск листовой страницы, соответствующей новому значению вводимой записи. Если в В-дереве даже не содержится ключа с заданным значением, то находится номер страницы, в которой он должен содержаться и координаты этого значения внутри страницы.
Листовая страница, в которую требуется занести запись, считывается в буфер оперативной памяти. Операция вставки записи осуществляется в этом буфере, при этом его размеры должны превышать размеры страницы внешней памяти.
Если после выполнения вставки записи в буфер размер используемой части буфера не превысил размера страницы, то на этом выполнение операции вставки записи заканчивается. Буфер может быть или немедленно выгружен во внешнюю память, или временно сохранен в оперативной памяти, в зависимости от политики управления буферами.
Если же возникло переполнение буфера (т. е. размер его используемой части превысил размер страницы), то выполняется расщепление страницы. Для этого запрашивается новая страница внешней памяти, используемая часть буфера разбивается пополам и вторая половина записывается во вновь выделенную страницу, а в старой странице модифицируется значение размера свободной памяти. Естественно, модифицируются ссылки по списку листовых страниц.
Чтобы обеспечить доступ от корня дерева к заново заведенной странице, необходимо соответствующим образом модифицировать внутреннюю страницу В-дерева, являющуюся предком ранее существовавшей (расщепленной) листовой страницы, т. е. вставить в нее соответствующее ключевое значение и ссылку на новую страницу. При выполнении этого действия, которое также осуществляется в буфере оперативной памяти, может снова произойти переполнение теперь уже внутренней страницы, и она будет расщеплена на две. В результате потребуется вставить новое ключевое значение и ссылку на новую страницу во внутреннюю страницу-предок выше по иерархии дерева и т. д.
Предельным случаем является переполнение корневой страницы В‑дерева. Эта страница также расщепляется на две, и заводится новая корневая страница дерева, т.е. его глубина увеличивается на единицу.
При удалении записи выполняются следующие действия.
Производится поиск записи в листовой странице по ключевому значению. Если запись не найдена, то, следовательно, удалять ничего не нужно.
Если запись найдена, то соответствующая ей листовая страница считывается в буфер оперативной памяти. В буфере производится реальное удаление записи.
Если после выполнения этой подоперации размер занятой в буфере области оказывается таковым, что его сумма с размером занятой области в листовых страницах, являющихся левым или правым «братом» данной страницы, больше, чем размер страницы, то операция завершается.
Если эта сумма оказывается меньше размера страницы, то производится слияние данной страницы с ее левым или правым «братом», т. е. в буфере формируется образ новой страницы, содержащей общую информацию из данной страницы и ее левого или правого «брата». Ставшая ненужной листовая страница заносится в список свободных страниц. При этом соответствующим образом корректируется список листовых страниц.
Чтобы устранить возможность доступа от корня к освобожденной странице, нужно удалить соответствующее ключевое значение и ссылку на освобожденную страницу из внутренней страницы В-дерева, являющейся предком освобожденной страницы. При этом из-за уменьшения занятой области этой страницы-предка может возникнуть потребность в ее слиянии уже с левым или правым ее «братьями» и т. д.
Предельным случаем является полное опустошение корневой страницы дерева, которое возможно после слияния последних двух потомков корня. В этом случае корневая страница освобождается.
Как видно из вышеизложенного, при выполнении операций вставки и удаления свойствосбалансированности В-дерева сохраняется, а внешняя память расходуется достаточно экономно, обеспечивая среднее заполнение страниц больше чем наполовину.
Говоря о повышении скорости доступа к данным при использовании индексирования полей, следует иметь в виду, что индексирование повышает эффективность именно операции выборки, т. е. чтения данных. Если же выполняется операция, связанная с изменением данных, т. е. вставка или удаление кортежа, изменение значения атрибута, по которому построен индексный файл, то наличие индексации приводит к замедлению операции. Дело в том, что каждое такое изменение приводит к необходимости соответствующей перестройки индексных файлов, относящихся к модифицируемым полям, что, очевидно, требует дополнительного времени.
В заключение, эта статья об структуры хранения данных подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое структуры хранения данных, методы доступа и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии