Лекция
Привет, Вы узнаете о том , что такое теория синхронизации, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое теория синхронизации, синхронизация данных, синхронизация потоков , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Синхронизация (от др.-греч. σύγχρονος — одновременный) в информатике обозначает одно из двух: синхронизацию процессов, либо синхронизацию данных. В информатике , синхронизация относится к одной из двух различных, но взаимосвязанных концепций: синхронизации процессов и синхронизации данных . Синхронизация процессов относится к идее, что несколько процессов должны объединиться или рукопожатие в определенный момент, чтобы достичь соглашения или выполнить определенную последовательность действий. синхронизация данных относится к идее сохранения нескольких копий набора данных во взаимосвязи друг с другом или для поддержания целостности данных . Примитивы синхронизации процессов обычно используются для реализации синхронизации данных.
Синхронизация процессов — приведение двух или нескольких процессов к такому их протеканию, когда определенные стадии разных процессов совершаются в определенном порядке, либо одновременно.
Синхронизация необходима в любых случаях, когда параллельно протекающим процессам необходимо взаимодействовать. Для ее организации используются средства межпроцессного взаимодействия. Среди наиболее часто используемых средств — сигналы и сообщения, семафоры и мьютексы, каналы (англ. pipe), совместно используемая память.
Синхронизация данных — ликвидация различий между двумя копиями данных. Предполагается, что ранее эти копии были одинаковы, а затем одна из них, либо обе были независимо изменены.
Способ синхронизации данных зависит от делаемых дополнительных предположений. Главной проблемой тут является то, что независимо сделанные изменения могут быть несовместимы друг с другом (так называемый «конфликт правок»), и даже теоретически не существует общего способа разрешения подобных ситуаций.
Тем не менее, есть ряд частных способов, применимых в тех или иных случаях:
Одним из механизмов синхронизации данных является репликация, которая в частности находит применение для синхронизации содержимого баз данных.
Своевременное получение актуальной информации является необходимым условием для принятия обоснованных решений. Естественно, находясь в офисе перед экраном компьютера, получить необходимую информацию — не проблема. Но все становится намного сложнее, если компьютер у вас не один, а как минимум два; если вы отправились в командировку или дела требуют вашего вмешательства даже на отдыхе; если вам регулярно приходится скачивать обновленные версии файлов с сервера компании; если вы работаете над одним проектом с группой сотрудников и вынуждены регулярно просматривать свежие версии документов из общей для всех папки данного проекта, хранящейся на удаленном сервере, и т.д.
Во всех этих случаях речь идет об одном и том же — о синхронизации данных. Под этим термином понимается синхронизация родственных папок с файлами и вложенными подпапками, находящихся как на одном, так и на разных компьютерах. Во время синхронизации специализированные программы сканируют файлы с одинаковыми именами в родственных папках и сравнивают их по нескольким признакам: по дате файла — обычно это основной критерий, а также по размеру и контрольным суммам — это дополнительные критерии, которые поддерживаются не всеми программами синхронизации. Найденные таким образом последние копии файлов отсылаются в родственную папку для обновления старых копий. То же самое происходит с вновь появившимися файлами, которых изначально не было в родственной папке. Результатом синхронизации становится полная идентичность родственных папок — иными словами, после синхронизации все файлы и вложенные папки в них будут одинаковыми.
Необходимость в синхронизации возникает не только в многопроцессорных системах, но и в любых параллельных процессах; даже в однопроцессорных системах. Ниже перечислены некоторые из основных потребностей синхронизации:
Разветвления и объединения : когда задание достигает точки разветвления, оно разбивается на N подзадач, которые затем обслуживаются n задачами. После обслуживания каждое подзадание ожидает, пока все остальные подзадачи не будут обработаны. Затем они снова присоединяются и покидают систему. Таким образом, параллельное программирование требует синхронизации, поскольку все параллельные процессы ожидают выполнения нескольких других процессов.
Производитель-Потребитель: В отношениях производитель-потребитель процесс потребителя зависит от процесса производителя до тех пор, пока не будут произведены необходимые данные.
Эксклюзивное использование ресурсов: когда несколько процессов зависят от ресурса и им требуется доступ к нему одновременно, операционная система должна гарантировать, что только один процессор обращается к нему в данный момент времени. Это снижает параллелизм.
Обычно синхронизация производится между родственными папками, находящимися на разных компьютерах. Компьютеры могут быть соединены между собой непосредственно через локальную сеть, инфракрасный порт или Интернет. Это наиболее быстрый и удобный вариант, так как синхронизация данных производится в один этап — как правило, для этого достаточно нажатия одной кнопки в окне программы.
Если непосредственного соединения нет, то данные могут быть синхронизированы с помощью устройства-посредника (Intermediate Storage Device, ISD), которое используется для переноса информации между двумя компьютерами во время процедуры синхронизации. Таким устройством может быть дискета, съемный жесткий диск, папка на FTP-сервере, USB Flash drive и др. В этом случае данные синхронизируются в несколько этапов: сначала с одного компьютера файлы упаковываются и отсылаются на устройство-посредник, а затем на другом компьютере они принимаются, благодаря чему и осуществляется синхронизация. Так выглядит однонаправленная синхронизация. Если необходимо осуществить двунаправленную синхронизацию, то названные операции повторяются, но уже в обратном порядке.
При необходимости, например, синхронизации больших объемов данных часть файлов можно игнорировать — в этом случае для каждой локальной папки определяется условие фильтрации файлов, задаваемое в виде маски файлов в общем виде. Игнорировать при синхронизации можно не только файлы, но и вложенные папки — как все, так и некоторые выбранные.
Процесс синхронизации, учитывая периодический характер проведения данной операции, удобнее автоматизировать с помощью встроенного планировщика, обычно поддерживаемого соответствующими программами. Можно, например, производить регулярную синхронизацию файлов в назначенное время, по определенным дням недели, при загрузке Windows, при появлении обновлений в синхронизируемых папках и т.д.
Синхронизация данных — задача, которая довольно часто встает как перед обычными пользователями, так и перед системными администраторами, руководителями проектов, менеджерами и прочими сотрудниками компаний.
Многим пользователям сегодня приходится работать не на одном, а на двух и даже на большем количестве компьютеров. Понятно, что, переходя с одного компьютера на другой, не хочется каждый раз думать о том, какие файлы и папки были изменены, и копировать их с одного компьютера на другой. Намного проще создать для основных папок соответствующие задачи синхронизации и запускать их в автоматическом режиме, например при включении компьютера.
Для мобильных пользователей актуальной является задача синхронизации данных ноутбука с рабочим компьютером, например до, после и во время командировки. Стационарным пользователям совершенно необходима синхронизация данных между рабочим и домашним компьютерами. И тем и другим нелишней будет возможность в любой момент синхронизировать данные своего компьютера с сервером компании и т.п.
Сегодня практически во всех компаниях используются компьютеры. Обычно они объединены в локальную сеть, хотя вполне возможно наличие удаленных компьютеров, связанных через Интернет. В любом случае довольно часто возникает необходимость централизованного обновления информации на всех компьютерах (или на компьютерах конкретного отдела и т.п.). Так, время от времени на каждый из компьютеров приходится копировать новые версии каких-то документов. Обычно эту операцию осуществляют либо путем рассылки их всем сотрудникам по электронной почте, либо ручным копированием файлов в общие папки каждого компьютера. Однако есть способ получше — можно создать соответствующие задачи синхронизации, которые и будут обновлять данные на всех компьютерах, например, с сервера компании. Плюсы такого подхода налицо: не потребуется вмешательство ответственного за данную операцию сотрудника, так как все будет происходить в автоматическом режиме, и будут полностью исключены ситуации, когда какой-то сотрудник не получит нужную информацию. Этот же прием может быть использован и для централизованного обновления программного обеспечения на всех компьютерах, в частности для обновления антивирусных баз и т.п.
Наличие регулярных обновлений, например, на Web-сайте компании — явное свидетельство того, что он поддерживается и развивается и что на нем всегда представлена актуальная информация. Несмотря на огромное количество самого разного ПО, предназначенного для размещения и обновления данных на сайте (обычно в этих целях используют FTP-клиент или файловый менеджер), синхронизация Web-сервера с рабочими папками на локальном компьютере — самый быстрый способ обновления, так как программа синхронизации сама определяет изменившиеся файлы и копирует на сайт только их.
Кроме того, операция обновления в таком случае происходит совершенно незаметно для посетителей сайта и при правильной настройке исключает возможность потери файлов. Дело в том, что обычно при таком варианте синхронизации файлы передаются с ложными именами и переименовываются после завершения синхронизации, поэтому посетители, зашедшие на сайт в момент обновления, не заметят никаких сбоев в работе. Для большей надежности файлы во время синхронизации блокируются, что позволяет избежать возможных потерь данных при изменении файла другим сотрудником компании, имеющим доступ к редактированию сайта.
К тому же такая синхронизация обычно проводится в автоматическом режиме, что избавляет исполнителей от трудоемкой, длительной и однотипной работы.
Резервное копирование данных подразумевает периодическое, как правило, ежедневное создание копий нужной информации, которые обычно хранятся на каких-либо съемных носителях и регулярно перезаписываются. Для резервирования данных имеется различное специализированное ПО; возможность резервирования предоставляет также большинство программ для синхронизации данных.
Вместе с тем для создания резервных копий можно использовать и однонаправленную синхронизацию, при которой производится копирование обновленных файлов только в одном направлении. Это очень удобно, поскольку автоматически позволяет избежать повторного копирования неизмененных файлов, в то время как при обычном резервировании создается сжатая копия всех (как изменившихся, так и неизменившихся) папок и файлов. В итоге резервирование в виде однонаправленной синхронизации требует намного меньше времени, что особенно важно в тех случаях, когда данные резервируются не только на внешний носитель — на другой жесткий диск, CD- или DVD-диск и т.п., но и на удаленный сервер через FTP. Дублирование на внешний носитель и на удаленный сервер на порядок повышает надежность сохранения данных, так как даже в критических случаях, когда одновременно выходят из строя рабочий жесткий диск и внешний носитель информации, данные все равно можно будет восстановить благодаря наличию резервной копии в Интернете.
Сравнивать различные модификации файлов приходится очень часто. Об этом говорит сайт https://intellect.icu . Одни пользователи вынуждены сравнивать обычные Word-документы, например предположительно разные версии договора на предмет наличия в них изменений, другие — прайс-листы или иные документы Excel с целью выяснить, были ли туда внесены какие-то поправки. Многим приходится искать изменения в подготовленных для конкретного проекта изображениях, внесенные другими сотрудниками, работающими над проектом, и т.п. Если таких документов много, то сравнить даты у соответствующих файлов вручную — долгое дело, а программы синхронизации в считанные секунды просмотрят сотни файлов и сообщат о том, в каких из них имеются изменения.
Сравнение файлов бывает необходимо и при различных аварийных ситуациях. Например, если в момент копирования большого объема данных неожиданно отключилось электричество или просто в силу каких-то обстоятельств пользователю пришлось прервать данный процесс, то, сравнив потом папку-источник и папку-приемник при помощи программы синхронизации, можно быстро скопировать недостающие данные.
Синхронизация персональной информации: адресных книг, почтовых баз, избранного, баз ICQ и т.п. — не менее актуальна. Все это, и в первую очередь почтовые базы, приходится регулярно переносить, например, с рабочего компьютера на домашний или со стационарного на ноутбук (персональную информацию нужно синхронизировать и с различными мобильными устройствами, в первую очередь с мобильным телефоном, но это тема для отдельной статьи). Вручную копировать и переносить файлы в несколько сотен мегабайт — занятие не из приятных. Кроме того, подавляющая часть информации не меняется, поэтому копировать ее с одного компьютера на другой совершенно бессмысленно. Помочь могут программы для синхронизации данных. Конечно, основное назначение программ данного класса — синхронизация папок и файлов, но некоторые из них поддерживают и синхронизацию персональной информации. Если же явно программа такой возможностью не обладает, то в большинстве случаев ее все равно будет несложно настроить на проведение данной операции, указав соответствующие папки с данными, и тогда синхронизация будет производиться четко и аккуратно. Но при этом стоит иметь в виду, что не все программы благосклонно воспринимают файлы, полученные таким путем, и не исключено, что после синхронизации соответствующий файл, например почтовую базу, придется подключать путем импорта. Но это все равно на порядок быстрее и проще.
С развитием индустрии информационных технологий, растет количество видов электронных помощников для человека. К электронным помощникам в наше время можно отнести: настольные компьютеры, ноутбуки, карманные помощники, мобильные телефоны и другие портативные электронно-вычислительные устройства.
С каждым годом количество электронных помощников, принадлежащих одному пользователю, растет. В связи, с чем появляется проблема синхронизации устройств между собой. Что в свою очередь ставит задачу создания программного обеспечения, которое могло бы предоставить:
В данной работе будут предложены варианты решения, выше перечисленных проблемы, за счет использования программного решения синхронизации данных и управления удаленным ЭВМ на основе веб технологий.
Архитектура программного решения синхронизации данных и управления удаленным ЭВМ на основе веб технологий
Программное решение синхронизации данных и управления удаленным ЭВМ на основе веб технологий состоит из нескольких программных решений:
1. Программное решение «Базовое» совмещает в себе возможности сервера и клиента и представляет собой полноценную операционную систему, построенную на базе проекта ReactOS.
В основе лежит модифицированная операционная система ReactOS. При запуске после загрузки основных модулей операционной системы, запускается сервер Apache, далее следует загрузка оболочки использующей фреймворк WebKit для вывода интерфейса программного решения синхронизации данных и управления удаленным ЭВМ на основе веб технологий. На рисунке 1 показана схема архитектуры программного решения «Базовое».
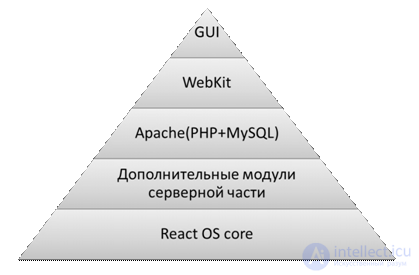
Рис.1. Архитектура программного решения «Базовое»
2. Программное решение «Дополнение», аналогично программному решению «Базовое», убран проект ReactOS из архитектуры программного решения синхронизации данных и управления удаленным ЭВМ на основе веб технологий. В основе архитектуры программного решения «Дополнение» используется модуль, состоящий из приложений и драйверов, для операционной системы предустановленной на устройстве пользователя, что дает возможность программному решению «Дополнение» устанавливаться поверх предустановленной операционной системы. На рисунке 2 показана схема архитектуры программного решения «Дополнение».

Рис. 2. Архитектура программного решения «Дополнение»
3. Программное решение «Клиент», отличается от программного решения «Базовое» и программного решения «Дополнение». Состоит из нативного приложения-клиента позволяющего устройству-клиенту получать информацию от устройства с предустановленным программным решением «Базовое» и «Дополнение».
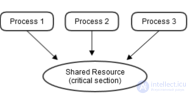
Рисунок 1 : Три процесса одновременно обращаются к общему ресурсу (критический раздел ).
Синхронизация потоков определяется как механизм, обеспечивающий два или более параллельных процесса или потоков не выполняют одновременно некоторый конкретный программный сегмент, известный как критический раздел . Доступ процессов к критическому участку контролируется с помощью методов синхронизации. Когда один поток начинает выполнение критического раздела (сериализованный сегмент программы), другой поток должен дождаться завершения первого потока. Если надлежащие методы синхронизации не применяются, это может вызвать состояние гонки , при котором значения переменных могут быть непредсказуемыми и изменяться в зависимости от времени переключения контекста процессов или потоков.
Например, предположим, что существует три процесса, а именно 1, 2 и 3. Все три из них выполняются одновременно, и им необходимо совместно использовать общий ресурс (критический раздел), как показано на рисунке 1. Здесь следует использовать синхронизацию, чтобы избежать конфликтов при доступе к этому общему ресурсу. Следовательно, когда процессы 1 и 2 оба пытаются получить доступ к этому ресурсу, он должен быть назначен только одному процессу за раз. Если он назначен процессу 1, другой процесс (процесс 2) должен дождаться, пока процесс 1 освободит этот ресурс (как показано на рисунке 2).
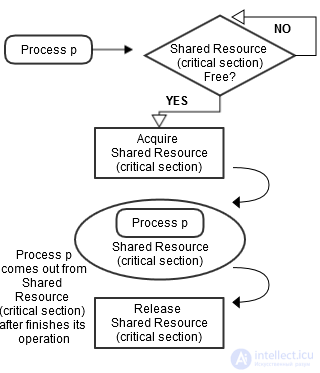
Рисунок 2 : Процесс, обращающийся к общему ресурсу, если он доступен, на основе некоторой техники синхронизации.
Еще одно требование синхронизации, которое необходимо учитывать, - это порядок, в котором должны выполняться определенные процессы или потоки. Например, нельзя сесть в самолет до покупки билета. Точно так же нельзя проверить электронную почту до подтверждения соответствующих учетных данных (например, имени пользователя и пароля). Точно так же банкомат не будет предоставлять никаких услуг, пока не получит правильный PIN-код.
Помимо взаимного исключения, синхронизация также имеет дело со следующим:
тупик , который возникает, когда многие процессы ожидают общий ресурс (критический раздел), который удерживается каким-либо другим процессом. В этом случае процессы просто продолжают ждать и больше не выполняются;
голодание , которое происходит, когда процесс ожидает входа в критическую секцию, но другие процессы монополизируют критическую секцию, и первый процесс вынужден ждать бесконечно;
инверсия приоритета , которая возникает, когда высокоприоритетный процесс находится в критической секции и прерывается процессом со средним приоритетом. Это нарушение правил приоритета может произойти при определенных обстоятельствах и может привести к серьезным последствиям в системах реального времени;
ожидание занятости , которое происходит, когда процесс часто опрашивает, чтобы определить, есть ли у него доступ к критическому разделу. Этот частый опрос отнимает время обработки у других процессов.
Минимизация синхронизации
Одной из проблем при разработке алгоритма экзадачи является минимизация или уменьшение синхронизации. Синхронизация занимает больше времени, чем вычисления, особенно в распределенных вычислениях. Снижение синхронизации привлекало внимание компьютерных ученых на протяжении десятилетий. Принимая во внимание, что в последнее время это становится все более серьезной проблемой, поскольку разрыв между улучшением вычислений и задержкой увеличивается. Эксперименты показали, что (глобальные) коммуникации из-за синхронизации на распределенных компьютерах занимают доминирующую долю в разреженном итеративном решателе. Эта проблема привлекает все большее внимание после появления нового эталонного показателя, High Performance Conjugate Gradient (HPCG), для ранжирования 500 лучших суперкомпьютеров.
Проблема производителя и потребителя (также называемая проблемой ограниченного буфера);
Читатели –Задача писателей ;
Проблема обедающих философов .
Эти задачи используются для тестирования почти каждой вновь предложенной схемы синхронизации или примитива.
Аппаратная синхронизация
Многие системы обеспечивают аппаратную поддержку кода критического раздела .
Однопроцессорная или однопроцессорная система может отключать прерывания , выполняя текущий код без приоритетного прерывания , что очень неэффективно на многопроцессорной системы. «Ключевая способность, которая нам требуется для реализации синхронизации в многопроцессоре, - это набор аппаратных примитивов с возможностью атомарного чтения и изменения области памяти. Без такой возможности стоимость создания базовых примитивов синхронизации будет слишком высока и будет увеличиваться по мере того, как количество процессоров увеличивается. Существует ряд альтернативных формулировок основных аппаратных примитивов, каждый из которых обеспечивает возможность атомарного чтения и изменения местоположения, вместе с некоторым способом определить, выполнялись ли чтение и запись атомарно. Эти аппаратные примитивы являются основными строительными блоками, которые используются для создания широкого спектра операций синхронизации на уровне пользователя, включая такие вещи, как блокировки и барьеры . В целом архитекторы не ожидают, что пользователи будут использовать базовые аппаратные примитивы, но вместо этого ожидайте, что примитивы будут использоваться системными программистами для создания библиотеки синхронизации - процесса, который часто бывает сложным и запутанным ». Многие современные аппаратные средства предоставляют специальные атомарные аппаратные инструкции посредством проверки и установки слова памяти или сравнения и замены содержимого двух слов памяти.
Стратегии синхронизации в языках программирования
В Java , чтобы предотвратить вмешательство потоков и ошибки согласованности памяти, блоки кода упаковываются в synchronized (lock_object ) разделы. Это заставляет любой поток получить указанный объект блокировки, прежде чем он сможет выполнить блок. Блокировка автоматически снимается, когда поток, который получил блокировку и затем выполняет блок, покидает блок или переходит в состояние ожидания внутри блока. Любые обновления переменных, сделанные потоком в синхронизированном блоке, становятся видимыми для других потоков, когда они аналогичным образом получают блокировку и выполняют блок.
Синхронизированные блоки Java, помимо включения взаимного исключения и согласованности памяти, включают сигнализацию, т. Е. Отправку событий от потоков, которые получили блокировку и выполняют блок кода тем, кто ожидает блокировки в пределах блок. Это означает, что синхронизированные разделы Java сочетают в себе функции мьютексов и событий. Такой примитив известен как монитор синхронизации .
. Любой объект может использоваться в качестве блокировки / монитора в Java. Объявляемый объект является объектом блокировки, когда весь метод помечен как synchronized.
.NET Framework имеет примитивы синхронизации. «Синхронизация предназначена для совместной работы, требуя, чтобы каждый поток или процесс следовал механизму синхронизации перед доступом к защищенным ресурсам (критический раздел) для получения согласованных результатов». В .NET блокировка, сигнализация, упрощенные типы синхронизации, спин-ожидание и взаимосвязанные операции являются одними из механизмов, связанных с синхронизацией.
Реализация синхронизации
Spinlock
Другой эффективный способ реализация синхронизации осуществляется с помощью спин-блокировок. Перед доступом к любому общему ресурсу или фрагменту кода каждый процессор проверяет флаг. Если флаг сброшен, процессор устанавливает флаг и продолжает выполнение потока. Но если флаг установлен (заблокирован), потоки будут продолжать вращаться в цикле и проверять, установлен ли флаг или нет. Но спин-блокировки эффективны только в том случае, если флаг сброшен для более низких циклов, в противном случае это может привести к проблемам с производительностью, поскольку тратит много циклов процессора на ожидание.
Барьеры
Барьеры просты в реализации и обеспечивают хорошее ответная реакция. Они основаны на концепции реализации циклов ожидания для обеспечения синхронизации. Рассмотрим три потока, работающих одновременно, начиная с барьера 1. По истечении времени t поток 1 достигает барьера 2, но ему все еще приходится ждать, пока потоки 2 и 3 достигнут барьера 2, поскольку он не имеет правильных данных. Как только все потоки достигают барьера 2, все они запускаются снова. По истечении времени t поток 1 достигает барьера 3, но ему придется снова ждать потоков 2 и 3 и правильных данных.
Таким образом, при барьерной синхронизации нескольких потоков всегда будет несколько потоков, которые в конечном итоге будут ждать других потоков, как в приведенном выше примере поток 1 продолжает ждать поток 2 и 3. Это приводит к серьезной деградации производительность процесса.
Функция ожидания синхронизации барьера для потока i может быть представлена как:
(Wbarrier) i = f ((Tbarrier) i, (Rthread) i)
Где Wbarrier - это время ожидания для потока, Tbarrier - это количество прибывших потоков, а Rthread - это скорость прибытия потоков.
Эксперименты показывают, что 34% общего времени выполнения тратится на ожидание для других более медленных потоков.
Семафоры
Семафоры - это механизмы сигнализации, которые могут позволить одному или нескольким потокам / процессорам получить доступ к разделу. Семафор имеет флаг, с которым связано определенное фиксированное значение, и каждый раз, когда поток желает получить доступ к разделу, он уменьшает флаг. Точно так же, когда поток покидает раздел, флаг увеличивается. Если флаг равен нулю, поток не может получить доступ к разделу и блокируется, если он выбирает подождать.
Некоторые семафоры допускают только один поток или процесс в секции кода. Такие семафоры называются двоичными семафорами и очень похожи на Mutex. Здесь, если значение семафора равно 1, потоку разрешен доступ, а если значение равно 0, доступ запрещен.
Математические основы
Первоначально синхронизация была концепцией, основанной на процессах посредством чего объект может быть заблокирован. Его основное использование было в базах данных. Существует два типа (файл) блокировки ; только для чтения и чтения-записи. Блокировки только для чтения могут быть получены многими процессами или потоками. Блокировки чтения-записи являются исключительными, так как они могут использоваться только одним процессом / потоком одновременно.
Хотя блокировки были получены для файловых баз данных, данные также распределяются в памяти между процессами и потоками. Иногда одновременно блокируется более одного объекта (или файла). Если они не заблокированы одновременно, они могут перекрываться, вызывая исключение взаимоблокировки.
Java и Ada имеют только исключительные блокировки, потому что они основаны на потоках и полагаются на команду процессора сравнения и замены .
Абстрактную математическую основу для примитивов синхронизации дает моноид истории . Существует также много теоретических устройств более высокого уровня, таких как вычисление процессов и сети Петри , которые могут быть построены на основе исторического моноида.
Примеры синхронизации
Ниже приведены некоторые примеры синхронизации для разных платформ.
Синхронизация в Windows
Windows предоставляет:
маски прерываний , которые защищают доступ к глобальным ресурсам (критическая секция) в однопроцессорных системах;
спин-блокировки , которые предотвращают вытеснение потока спин-блокировки в многопроцессорных системах;
диспетчеры , которые действуют как мьютексы , семафоры , события и таймеры .
Синхронизация в Linux
Linux предоставляет:
блокировка чтения – записи для более длинной части кодов, к которым обращаются очень часто, но не очень часто.
Чтение-копирование-обновление (RCU)
Включение и выключение вытеснения ядра заменяет спин-блокировки в однопроцессорных системах. До версии ядра 2.6 Linux отключал прерывание для реализации коротких критических секций. Начиная с версии 2.6 и новее, Linux полностью вытеснен.
Синхронизация в Solaris
Solaris предоставляет:
семафоры ;
условные переменные ;
, двоичные семафоры, которые реализуются по-разному в зависимости от условий;
считыватели– блокировка записи:
турникеты , очередь потоков, ожидающих полученной блокировки.
Синхронизация потоков Pthreads
Pthreads - платформенно-независимый API , который обеспечивает:
мьютексы;
переменные состояния;
блокировки чтения и записи;
спин-блокировки;
барьеры .
Синхронизация данных
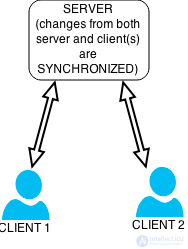
Рисунок 3: Изменения и от сервера, и от клиента (ов) синхронизируются.
Совершенно другая (но связанная) концепция - это концепция синхронизации данных . Это относится к необходимости поддерживать согласованность нескольких копий набора данных друг с другом или поддерживать целостность данных , рисунок 3. Например, репликация базы данных используется для сохранения нескольких копий данных, синхронизированных с серверами баз данных. которые хранят данные в разных местах.
Примеры включают:
Синхронизация файлов , например синхронизация портативного MP3-плеера с настольным компьютером;
Кластерные файловые системы , которые являются файловыми системами , которые поддерживают данные или индексы согласованным образом во всем вычислительном кластере ;
Когерентность кэша , поддерживая синхронизацию нескольких копий данных в нескольких кэшах ;
RAID , где данные записываются с избыточностью на несколько дисков, так что потеря одного диска не приводит к потере данных;
Репликация базы данных , где копии данных в базе данных синхронизируются, несмотря на возможное большое географическое разделение;
ведение журнала , метод, используемый многими современными файловыми системами, чтобы гарантировать, что метаданные файлов обновляются на диске согласованным и согласованным образом.
Проблемы в синхронизация данных
Некоторые проблемы, с которыми пользователь может столкнуться при синхронизации данных:
сложность форматов данных;
оперативность;
данные se curity;
качество данных;
производительность.
Сложность форматов данных
Форматы данных имеют тенденцию становиться более сложными со временем по мере роста и развития организации. Это приводит не только к созданию простых интерфейсов между двумя приложениями (исходным и целевым), но и к необходимости преобразовывать данные при их передаче в целевое приложение. Инструменты ETL (загрузка с преобразованием извлечения) могут быть полезны на этом этапе для управления сложностями формата данных.
Оперативность
В системах реального времени клиенты хотят видеть текущий статус своего заказа в интернет-магазине, текущий статус доставки посылки - отслеживание посылки в реальном времени - , текущий баланс на их счете и т. д. Это показывает необходимость системы реального времени, которая также обновляется, чтобы обеспечить бесперебойный производственный процесс в режиме реального времени, например, заказ материалов, когда на предприятии заканчиваются запасы, синхронизация клиентов заказы с производственным процессом и т. д. Из реальной жизни существует очень много примеров, когда обработка в реальном времени дает успешное и конкурентное преимущество.
Безопасность данных
Не существует фиксированных правил и политик для обеспечения безопасности данных. Это может варьироваться в зависимости от используемой вами системы. Несмотря на то, что безопасность поддерживается правильно в исходной системе, которая собирает данные, привилегии безопасности и доступа к информации должны быть реализованы и в целевых системах, чтобы предотвратить любое возможное неправильное использование информации. Это серьезная проблема, особенно когда дело касается обработки секретной, конфиденциальной и личной информации. Поэтому из-за секретности и конфиденциальности передача данных и вся промежуточная информация должна быть зашифрована.
Качество данных
Качество данных - еще одно серьезное ограничение. Для лучшего управления и поддержания хорошего качества данных обычной практикой является хранение данных в одном месте и совместное использование с разными людьми и разными системами и / или приложениями из разных мест. Это помогает предотвратить несогласованность данных.
Производительность
Процесс синхронизации данных включает пять различных этапов:
извлечение данных из исходной (или главной, или главной) системы;
передача данных ;
преобразование данных ;
загрузка данных в целевую систему.
обновление данных
Каждый из этих шагов является критическим. В случае больших объемов данных необходимо тщательно спланировать и выполнить процесс синхронизации, чтобы избежать негативного влияния на производительность.
В настоящее время для управления удаленным компьютером, применяются системы удаленного доступа, в большинстве построенные на базе протокола RFB (“remote framebuffer”) или аналогичном.
При применении систем удаленного доступа возникают следующие проблемы, которые пытается решить разработанное программное решение.
Клиенты систем удаленного доступа, передают данные несущие в себе всю информацию, выводящуюся на экран компьютера-сервера, что не позволяет использовать данные приложения при низкой скорости соединении и на устройствах с маленьким экраном и не адаптированным интерфейсами управления (Например, управление оконным интерфейсом Windows, используя планшетный компьютер). Как следствие неудобство управления удаленным ЭВМ с помощью мобильного устройства.
При разработке программного решения синхронизации данных и управления удаленным ЭВМ на основе веб технологий, разработаны два способа передачи информации с экрана сервера.
1. На стороне сервера создается скриншот содержимого рабочего окна и передается устройству-клиенту. На устройстве-клиенте вся принятая графическая информация встраивается в окно интерфейса графической оболочки программного решения управления удаленным ЭВМ. Так же возможно полностью, заместить интерфейс программного решения синхронизации данных и управления удаленным ЭВМ на основе веб технологий, графической информацией полученной с сервера. Данный метод позволяет уменьшить размер передаваемой графической информации, за счет размера передаваемой картинки.
2. На стороне сервера по указанию клиента запускается, консольное приложение, принимающее информации от клиента и отправляющее текстовую информацию обратно. Далее в программе клиенте текстовая информация встраивается в окно.
Данный метод позволяет уменьшить размер передаваемой информации, за счет отказа от передачи излишней графической информации, и позволяет адаптировать интерфейс транслируемого приложения под устройство, на котором программа будет выведена на экран. На рисунках 3 и 4 показана разница одного приложения запущенного на десктопе и на мобильном телефоне.
Отчетливо различных (но связанных) является понятие синхронизации данных . Это относится к необходимости держать несколько копий набора данных когерентной друг с другом или для поддержания целостности данных , Рисунок 3. Например, репликация базы данных используется , чтобы держать несколько копий данных , синхронизированных с серверами баз данных , в которых хранятся данные в разных местах ,
Примеры включают в себя:
Некоторые из проблем , с которыми пользователь может столкнуться в синхронизации данных: [ 8 ]
Когда мы начинаем делать что - то, данные , которые мы имеем , как правило , находится в очень простом формате. Она меняется с течением времени по мере роста организации и развивается , и результаты не только в создании простой интерфейс между двумя приложениями (источник и цель), но и в необходимости преобразования данных при переходе их в целевое приложение. ETL (преобразование экстракции загрузка) инструменты могут быть очень полезны на данном этапе для управления сложности формата данных.
Это эра систем реального времени. Клиенты хотят, чтобы увидеть текущее состояние своего заказа в интернет-магазине, текущий статус доставки-посылку в реальном масштабе времени посылки Отслеживание-, текущий баланс на их счету и т.д. Это свидетельствует о необходимости в режиме реального времени системы, который обновляется, а также для обеспечения плавного процесса производства в режиме реального времени, например, заказ материалов, когда предприятие работает вне шток, синхронизация заказов клиентов с производственного процесса и т.д. из реальной жизни, существует очень много примеров, когда обработка в реальном масштабе времени дает успешное и конкурентное преимущество.
Там нет фиксированных правил и политик для обеспечения безопасности данных. Она может варьироваться в зависимости от системы, которую вы используете. Даже если ценная бумага правильно сохраняется в исходной системе, которая фиксирует данные, привилегии доступа к безопасности и информации должны быть приведено в исполнение на целевых системах, а также в целях предотвращения возможных злоупотреблений информацией. Это серьезная проблема, и особенно, когда речь идет для обработки секретной, конфиденциальной и личной информации. Таким образом, из-за чувствительности и конфиденциальности, передачи данных и все в промежутках информации должны быть зашифрованы.
Качество данных является еще одним серьезным сдерживающим фактором. Для лучшего управления и для поддержания хорошего качества данных, обычной практикой является хранение данных в одном месте и совместно с различными людьми и различными системами и / или приложений из разных мест. Это помогает в предотвращении несоответствий в данных.
Есть пять различных фаз, участвующих в процессе синхронизации данных:
Каждый из этих этапов имеет очень важное значение. В случае больших объемов данных, процесс синхронизации должен быть тщательно спланирована и проведена, чтобы избежать негативного влияния на производительность.
Синхронизация была первоначально концепция процесса на основе посредством чего замок может быть получен на объекте. Ее основное назначение было в базах данных. Есть два типа (файла) замка ; только для чтения и чтения-записи. Только для чтения замки могут быть получены различными способами , которые или нитей.Читатели-писатель замки являются исключительными, так как они могут быть использованы только одним процессом / потоком одновременно.
Хотя замки были получены для файловых баз, данные разделяют также в памяти между процессами и потоками. Иногда более одного объекта (или файл) заблокирован, в то время. Если они не блокируются одновременно они могут перекрываться, вызывая исключение тупиковой.
Java и Ada имеют только эксклюзивные замки , потому что они основаны нити и полагаться на сравнение с обменом инструкции процессора.
Абстрактной математической основой для примитивов синхронизации задается историей моноиде . Есть также много теоретических устройствами более высокого уровня, такие как процесс исчислений и сетей Петри , которые могут быть построены на вершине истории моноиде.
В заключение, эта статья об теория синхронизации подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое теория синхронизации, синхронизация данных, синхронизация потоков и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL