Лекция
Сразу хочу сказать, что здесь никакой воды про базы данных, и только нужная информация. Для того чтобы лучше понимать что такое базы данных, базы данных и знаний, виды баз данных, реляционные, не реляционные, субд, озера данных, сети данных, болото данных , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью компьютера.
Многие специалисты указывают на распространенную ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий.
В литературе предлагается множество определений понятия «база данных», отражающих скорее субъективное мнение тех или иных авторов, однако общепризнанная единая формулировка отсутствует.
Определения из международных стандартов:
Определения из авторитетных монографий:
В определениях наиболее часто (явно или неявно) присутствуют следующие отличительные признаки :
Из перечисленных признаков только первый является строгим, а другие допускают различные трактовки и различные степени оценки. Можно лишь установить некоторую степень соответствия требованиям к БД.
В такой ситуации не последнюю роль играет общепринятая практика. В соответствии с ней, например, не называют базами данных файловые архивы, Интернет-порталы или электронные таблицы, несмотря на то, что они в некоторой степени обладают признаками БД. Принято считать, что эта степень в большинстве случаев недостаточна (хотя могут быть исключения).
Современные авторы часто употребляют термины «банк данных» и «база данных» как синонимы, однако в общеотраслевых руководящих материалах по созданию банков данных Государственного комитета по науке и технике (ГКНТ), изданных в 1982 г., эти понятия различаются. Там приводятся следующие определения банка данных, базы данных и субд .
Банк данных (БнД) — это система специальным образом организованных данных — баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
База данных (БД) — именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Четкие определения сложны для восприятия, но эти определения четко разграничивают назначение всех трех базовых понятий, и мы можем принять их за основу.
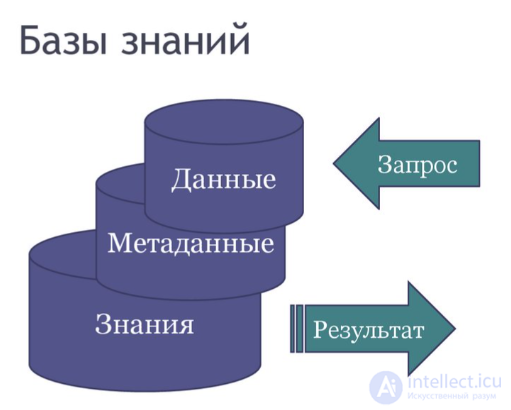
Кроме того, существуют понятия база знаний и хранилища данных.
База знаний (БЗ; англ. knowledge base, KB) — база данных, содержащая правила вывода и информацию о человеческом опыте и знаниях в некоторой предметной области (ISO/IEC/IEEE 24765-2010 , ISO/IEC 2382-1:1993). В самообучающихся системах база знаний также содержит информацию, являющуюся результатом решения предыдущих задач
Хранилище данных (англ. Data Warehouse) — предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчетов и бизнес-анализа с целью поддержки принятия решений в организации. Строится на базе систем управления базами данных и систем поддержки принятия решений. Данные, поступающие в хранилище данных, как правило, доступны только для чтения.
Программы, с помощью которых пользователи работают с базой данных, называются приложениями. В общем случае с одной базой данных могут работать множество различных приложений. Например, если база данных моделирует некоторое предприятие, то для работы с ней может быть создано приложение, которое обслуживает подсистему учета кадров, другое приложение может быть посвящено работе подсистемы расчета заработной платы сотрудников, третье приложение работает как подсистема складского учета, четвертое приложение посвящено планированию производственного процесса. При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями
История возникновения и развития технологий баз данных может рассматриваться как в широком, так и в узком аспекте.
В широком смысле понятие истории баз данных обобщается до истории любых средств, с помощью которых человечество хранило и обрабатывало данные. В таком контексте упоминаются, например, средства учета царской казны и налогов в древнем Шумере (4000 г. до н. э.), узелковая письменность инков — кипу, клинописи, содержащие документы Ассирийского царства и т. п. Следует помнить, что недостатком этого подхода является размывание понятия «база данных» и фактическое его слияние с понятиями «архив» и даже «письменность».
История баз данных в узком смысле рассматривает базы данных в традиционном (современном) понимании. Эта история начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты.
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
В это же время в сообществе баз данных COBOL была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Эдгара Ф. Кодда. Работы Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой. За свой вклад в теорию и практику Эдгар Ф. Кодд также получил премию Тьюринга.
Сам термин база данных (англ. database) появился в начале 1960-х годов, и был введен в употребление на симпозиумах, организованных компанией SDC в 1964 и1965 годах, хотя понимался сначала в довольно узком смысле, в контексте систем искусственного интеллекта. В широкое употребление в современном понимании термин вошел лишь в 1970-е годы.
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных», по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация - разделение множества на подмножества по неформально предложенному признаку. В силу многогранности баз данных и СУБД (комплекса технических и программных средств, для хранения, поиска, защиты и использования данных) имеется множество классификационных признаков. Классификация БД по основным признакам приведена на рис. 1.
Классификация баз данных
В мире существует множество СУБД. Несмотря на их различие, все они опираются на единый устоявшийся комплекс основных понятий.
СУБД носит централизованный характер. Что предполагает необходимость существования некоторого лица (группы лиц), на которое возлагаются функции администрирования данными, хранимыми в базе.
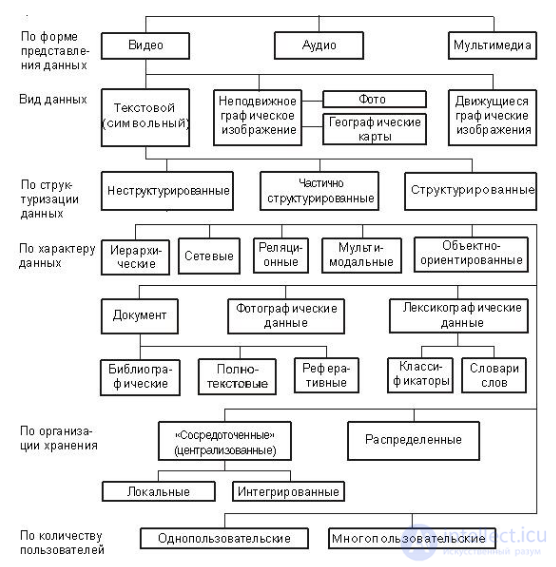
Рис. 1. Классификация баз данных
Примеры:

болото данных — это озеро данных, в котором навели недостаточно порядка. Данные туда складывают, но ими трудно пользоваться.
Сеть данных — это подход, при котором разные команды отвечают за свои «продукты данных». Например, команда маркетинга отвечает за маркетинговые данные, команда продаж — за данные продаж, команда логистики — за данные доставки.

Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Петров Николай Степанович, $30 и т. д. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, т. е. осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но тем не менее, можно выделить нечто общее в этих определениях.
Модель данных — это некоторая абстракция, которая, будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, т. е. сведения, содержащие не только данные, но и взаимосвязь между ними.
На рис. 1.10 представлена классификация моделей данных.
В соответствии с рассмотренной ранее трехуровневой архитектурой мы сталкиваемся с понятием модели данных по отношению к каждому уровню. И действительно, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах — это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хэширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
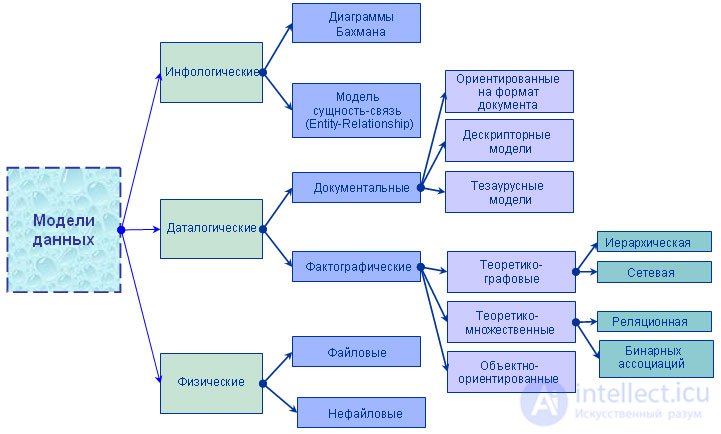
Рис. 1.10. Классификация моделей данных
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
Кроме трех рассмотренных уровней абстракции, определенных в ANSI-архитектуре, при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а даталогические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х гг. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экран программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять этот язык для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и одновременно удобный язык XML. В чем же заключаются его достоинства?
XML (Extensible Markup Language) — это язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов, т. е. сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, т. е. по тем параметрам, которые характеризовали патент, а не сам текст патента.
Сверхбольшая база данных (англ. Very Large Database, VLDB) — это база данных, которая занимает чрезвычайно большой объем на устройстве физического хранения. Термин подразумевает максимально возможные объемы БД, которые определяются последними достижениями в технологиях физического хранения данных и в технологиях программного оперирования данными.
Количественное определение понятия «чрезвычайно большой объем» меняется во времени; в настоящее время считается, что это объем, измеряемый по меньшей мере петабайтами. Для сравнения, в 2005 г. самыми крупными в мире считались базы данных с объемом хранилища порядка 100 терабайт.
Специалисты отмечают необходимость особых подходов к проектированию сверхбольших БД. Для их создания нередко выполняются специальные проекты с целью поиска таких системотехнических решений, которые позволили бы хоть как-то работать с такими большими объемами данных. Как правило, необходимы специальные решения для дисковой подсистемы, специальные версии операционной среды и специальные механизмы обращения СУБД к данным.
Исследования в области хранения и обработки сверхбольших баз данных VLDB всегда находятся на острие теории и практики баз данных. В частности, с 1975 годапроходит ежегодная конференция International Conference on Very Large Data Bases («Международная конференция по сверхбольшим базам данных»). Большинство исследований проводится под эгидой некоммерческой организации VLDB Endowment (Фонд целевого капитала «VLDB»), которая обеспечивает продвижение научных работ и обмен информацией в области сверхбольших БД и смежных областях.
В последнее время термин “NoSQL” стал очень модным и популярным, активно развиваются и продвигаются всевозможные программные решения под этой вывеской. Синонимом NoSQL стали огромные объемы данных, линейная масштабируемость, кластеры, отказоустойчивость, нереляционность. Однако, мало у кого есть четкое понимание, что же такое NoSQL хранилища, как появился этот термин и какими общими характеристиками они обладают. Попробуем устранить этот пробел.

Самое интересное в термине, что при том, что впервые он стал использоваться в конце 90-х, реальный смысл в том виде, как он используется сейчас, приобрел только в середине 2009. Изначально так называлась опенсорсная база данных, созданная Карло Строззи, которая хранила все данные как ASCII файлы и использовала шелловские скрипты вместо SQL для доступа к данным. С “NoSQL” в его нынешнем виде она ничего общего не имела.
В июне 2009 в Сан-Франциско Йоханом Оскарссоном была организована встреча, на которой планировалось обсудить новые веяния на ИТ рынке хранения и обработки данных. Главным стимулом для встречи стали новые опенсорсные продукты наподобие BigTable и Dynamo. Для яркой вывески для встречи требовалось найти емкий и лаконичный термин, который отлично укладывался бы в Твиттеровский хэштег. Один из таких терминов предложил Эрик Эванс из RackSpace — «NoSQL». Термин планировался лишь на одну встречу и не имел под собой глубокой смысловой нагрузки, но так получилось, что он распространился по мировой сети наподобие вирусной рекламы и стал де-факто названием целого направления в ИТ-индустрии. На конференции, к слову, выступали Voldemort (клон Amazon Dynamo), Cassandra, Hbase (аналоги Google BigTable), Hypertable, CouchDB, MongoDB.
Стоит еще раз подчеркнуть, что термин “NoSQL” имеет абсолютно стихийное происхождение и не имеет общепризнанного определения или научного учреждения за спиной. Это название скорее характеризует вектор развития ИТ в сторону от реляционных баз данных. Расшифровывается как Not Only SQL, хотя есть сторонники и прямого определения No SQL. Сгруппировать и систематизировать знания о NoSQL мире попытались сделать Прамод Садаладж и Мартин Фаулер в своей недавней книге “NoSQL Distilled”.
Общих характеристик для всех NoSQL немного, так как под лэйблом NoSQL сейчас скрывается множество разнородных систем (самый полный, пожалуй, список можно найти на сайте http://nosql-database.org/). Многие характеристики свойственны только определенным NoSQL базам, это я обязательно упомяну при перечислении.
1. Не используется SQL
Имеется в виду ANSI SQL DML, так как многие базы пытаются использовать query languages похожие на общеизвестный любимый синтаксис, но полностью его реализовать не удалось никому и вряд ли удастся. Хотя по слухам есть стартапы, которые пытаются реализовать SQL, например, в хадупе (http://www.drawntoscalehq.com/ и http://www.hadapt.com/ )
2. Неструктурированные (schemaless)
Смысл таков, что в NoSQL базах в отличие от реляционных структура данных не регламентирована (или слабо типизированна, если проводить аналогии с языками прогаммирования) — в отдельной строке или документе можно добавить произвольное поле без предварительного декларативного изменения структуры всей таблицы. Таким образом, если появляется необходимость поменять модель данных, то единственное достаточное действие — отразить изменение в коде приложения.
Например, при переименовании поля в MongoDB:
BasicDBObject order = new BasicDBObject(); order.put(“date”, orderDate); // это поле было давно order.put(“totalSum”, total); // раньше мы использовали просто “sum”
Если мы меняем логику приложения, значит мы ожидаем новое поле также и при чтении. Но в силу отсутствия схемы данных поле totalSum отсутствует у других уже существующих объектов Order. В этой ситуации есть два варианта дальнейших действий. Первый — обойти все документы и обновить это поле во всех существующих документах. В силу объемов данных этот процесс происходит без каких-либо блокировок (сравним с командой alter table rename column), поэтому во время обновления уже существующие данные могут считываться другими процессами. Поэтому второй вариант — проверка в коде приложения — неизбежен:
BasicDBObject order = new BasicDBObject();
Double totalSum = order.getDouble(“sum”); // Это старая модель
if (totalSum == null)
totalSum = order.getDouble(“totalSum”); // Это обновленная модель
А уже при повторной записи мы запишем это поле в базу в новом формате.
Приятное следствие отсутствия схемы — эффективность работы с разреженными (sparse) данными. Если в одном документе есть поле date_published, а во втором — нет, значит никакого пустого поля date_published для второго создано не будет. Это, в принципе, логично, но менее очевидный пример — column-family NoSQL базы данных, в которых используются знакомые понятия таблиц/колонок. Однако в силу отсутствия схемы, колонки не объявляются декларативно и могут меняться/добавляться во время пользовательской сессии работы с базой. Это позволяет в частности использовать динамические колонки для реализации списков.
У неструктурированной схемы есть свои недостатки — помимо упомянутых выше накладных расходов в коде приложения при смене модели данных — отсутствие всевозможных ограничений со стороны базы (not null, unique, check constraint и т.д.), плюс возникают дополнительные сложности в понимании и контроле структуры данных при параллельной работе с базой разных проектов (отсутствуют какие-либо словари на стороне базы). Впрочем, в условиях быстро меняющегося современного мира такая гибкость является все-таки преимуществом. В качестве примера можно привести Твиттер, который лет пять назад вместе с твиттом хранил лишь немного дополнительной информации (время, Twitter handle и еще несколько байтов метаинформации), однако сейчас в дополнение к самому сообщению в базе сохраняется еще несколько килобайт метаданных.
(Здесь и далее речь идет в-основном о key-value, document и column-family базах данных, graph базы данных могут не обладать этими свойствами).
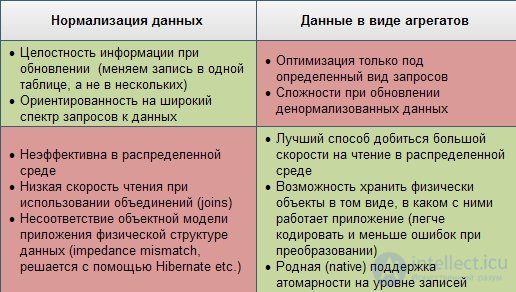
3. Представление данных в виде агрегатов (aggregates).
В отличие от реляционной модели, которая сохраняет логическую бизнес-сущность приложения в различные физические таблицы в целях нормализации, NoSQL хранилища оперируют с этими сущностями как с целостными объектами:
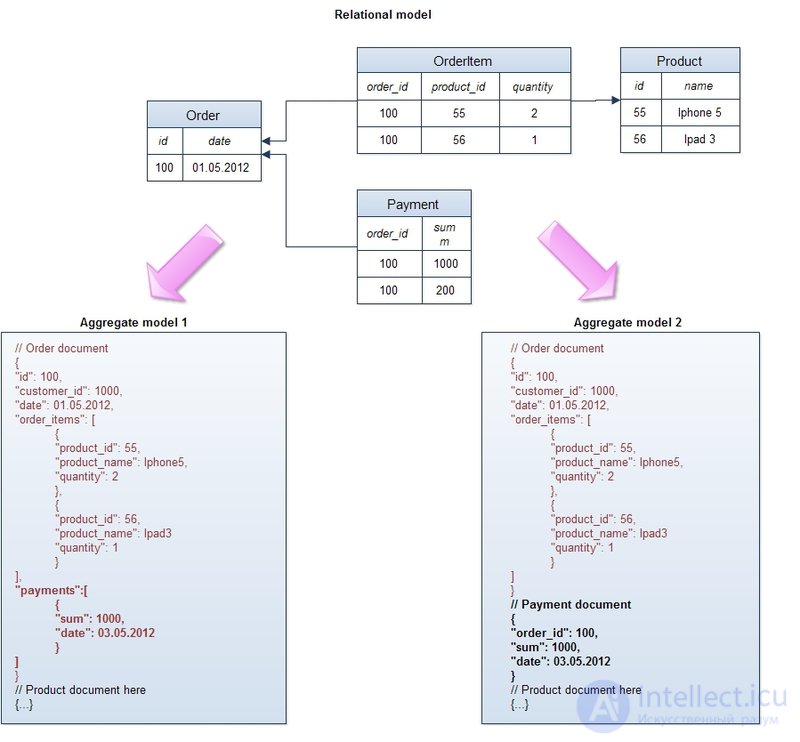
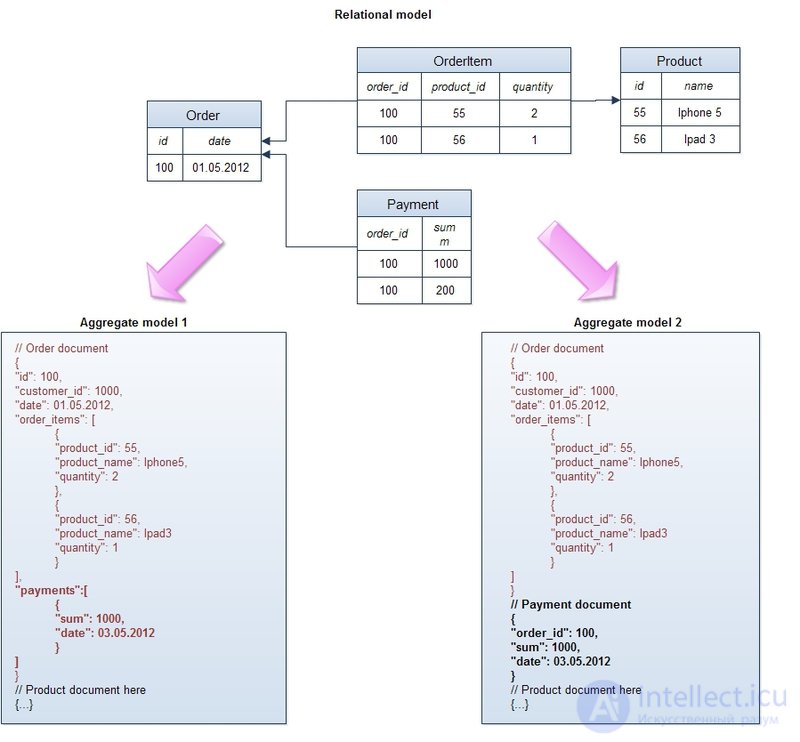
В этом примере продемонстрированы агрегаты для стандартной концептуальной реляционной модели e-commerce “заказ — позиции заказа — платежи — продукт”. В обоих случаях заказ объединяется с позициями в один логический объект, при этом каждая позиция хранит в себе ссылку на продукт и некоторые его атрибуты, например, название (такая денормализация необходима, чтобы не запрашивать объект продукта при извлечении заказа — главное правило распределенных систем — минимум “джоинов” между объектами). В одном агрегате платежи объединены с заказом и являются составной частью объекта, в другом — вынесены в отдельный объект. Этим демонстрируется главное правило проектирования структуры данных в NoSQL базах — она должна подчиняться требованиям приложения и быть максимально оптимизированной под наиболее частые запросы. Если платежи регулярно извлекаются вместе с заказом — имеет смысл их включать в общий объект, если же многие запросы работают только с платежами — значит, лучше их вынести в отдельную сущность.
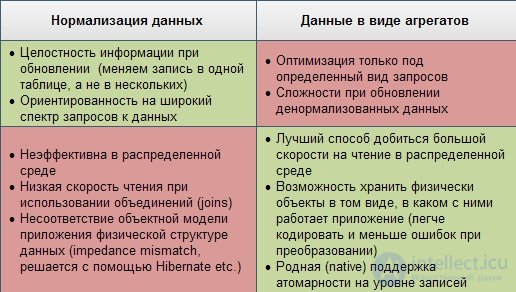
Многие возразят, заметив, что работа с большими, часто денормализованными, объектами чревата многочисленными проблемами при попытках произвольных запросов к данным, когда запросы не укладываются в структуру агрегатов. Что, если мы используем заказы вместе с позициями и платежами по заказу (так работает приложение), но бизнес просит нас посчитать, сколько единиц определенного продукта было проданно в прошлом месяце? В этом случае вместо сканирования таблицы OrderItem (в случае реляционной модели) нам придется извлекать заказы целиком в NoSQL хранилище, хотя большая часть этой информации нам будет не нужна. К сожалению, это компромисс, на который приходится идти в распределенной системе: мы не можем проводить нормализацию данных как в обычной односерверной системе, так как это создаст необходимость объединения данных с разных узлов и может привести к значительному замедлению работы базы
Плюсы и минусы обоих подходов я попытался сгруппировать в табличке:
4. Слабые ACID свойства.
Долгое время консистентность (consistency) данных была “священной коровой” для архитекторов и разработчиков. Все реляционные базы обеспечивали тот или иной уровень изоляции — либо за счет блокировок при изменении и блокирующего чтения, либо за счет undo-логов. С приходом огромных массивов информации и распределенных систем стало ясно, что обеспечить для них транзакционность набора операций с одной стороны и получить высокую доступность и быстрое время отклика с другой — невозможно. Более того, даже обновление одной записи не гарантирует, что любой другой пользователь моментально увидит изменения в системе, ведь изменение может произойти, например, в мастер-ноде, а реплика асинхронно скопируется на слейв-ноду, с которой и работает другой пользователь. В таком случае он увидит результат через какой-то промежуток времени. Это называется eventual consistency и это то, на что идут сейчас все крупнейшие интернет-компании мира, включая Facebook и Amazon. Последние с гордостью заявляют, что максимальный интервал, в течение которого пользователь может видеть неконсистентные данные составляют не более секунды. Пример такой ситуации показан на рисунке:
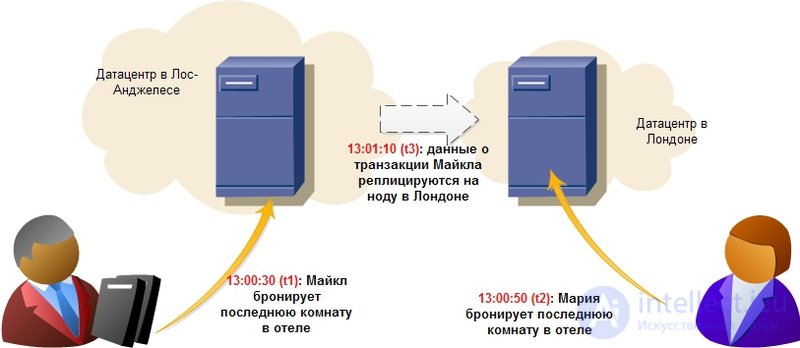
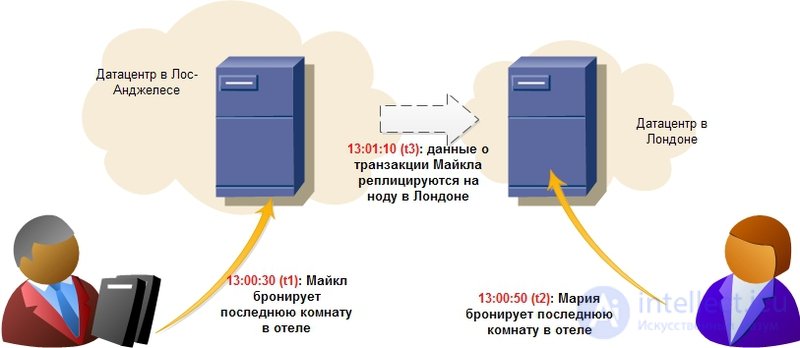
Логичный вопрос, который появляется в такой ситуации — а что делать системам, которые классически предъявляют высокие требования к атомарности-консистентности операций и в то же время нуждаются в быстрых распределенных кластерах — финансовым, интернет-магазинам и т.д? Практика показывает, что эти требования уже давно неактуальны: вот что сказал один разработчик финансовой банковской системы: “Если бы мы действительно ждали завершения каждой транзакции в мировой сети ATM (банкоматов), транзакции занимали бы столько времени, что клиенты убегали бы прочь в ярости. Что происходит, если ты и твой партнер снимаете деньги одновременно и превышаете лимит? — Вы оба получите деньги, а мы поправим это позже.” Другой пример — бронирование гостиниц, показанный на картинке. Онлайн-магазины, чья политика работы с данными предполагает eventual consistency, обязаны предусмотреть меры на случай таких ситуаций (автоматическое решение конфликтов, откат операции, обновление с другими данными). На практике гостиницы всегда стараются держать “пул” свободных номеров на непредвиденный случай и это может стать решением спорной ситуации.
На самом деле слабые ACID свойства не означают, что их нет вообще. В большинстве случаев приложение, работающее с реляционной базой данных, использует транзакцию для изменения логически связанных объектов (заказ — позиции заказа), что необходимо, так как это разные таблицы. При правильном проектировании модели данных в NoSQL базе (агрегат представляет из себя заказ вместе с перечнем пунктов заказа) можно добиться такого же самого уровня изоляции при изменении одной записи, что и в реляционной базе данных.
5. Распределенные системы, без совместно используемых ресурсов (share nothing).
Опять же, это не касается граф баз данных, чья структура по определению плохо разносится по удаленным нодам.
Это, возможно, главный лейтмотив развития NoSQL баз. С лавинообразным ростом информации в мире и необходимости ее обрабатывать за разумное время встала проблема вертикальной масштабируемости — рост скорости процессора остановился на 3.5 Ггц, скорость чтения с диска также растет тихими темпами, плюс цена мощного сервера всегда больше суммарной цены нескольких простых серверов. В этой ситуации обычные реляционные базы, даже кластеризованные на массиве дисков, не способны решить проблему скорости, масштабируемости и пропускной способности. Единственный выход из ситуации — горизонтальное масштабирование, когда несколько независимых серверов соединяются быстрой сетью и каждый владеет/обрабатывает только часть данных и/или только часть запросов на чтение-обновление. В такой архитектуре для повышения мощности хранилища (емкости, времени отклика, пропускной способности) необходимо лишь добавить новый сервер в кластер — и все. Процедурами шардинга, репликации, обеспечением отказоустойчивости (результат будет получен даже если одна или несколько серверов перестали отвечать), перераспределения данных в случае добавления ноды занимается сама NoSQL база. Вкратце представлю основные свойства распределенных NoSQL баз:
Репликация — копирование данных на другие узлы при обновлении. Позволяет как добиться большей масштабируемости, так и повысить доступность и сохранность данных. Принято подразделять на два вида:
master-slave:


и peer-to-peer:
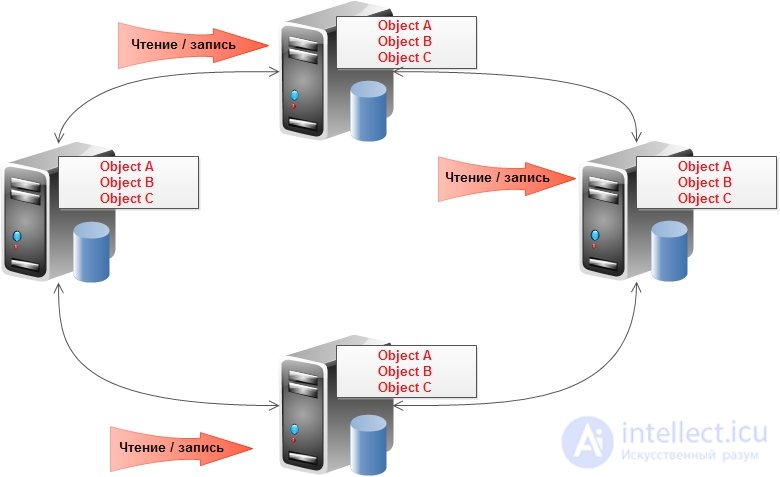

Первый тип предполагает хорошую масштабируемость на чтение (может происходить с любого узла), но немасштабируемую запись (только в мастер узел). Также есть тонкости с обеспечением постоянной доступности (в случае падения мастера либо вручную, либо автоматически на его место назначается один из оставшихся узлов). Для второго типа репликации предполагается, что все узлы равны и могут обслуживать как запросы на чтение, так и на запись.
Шардинг — разделение данных по узлам:
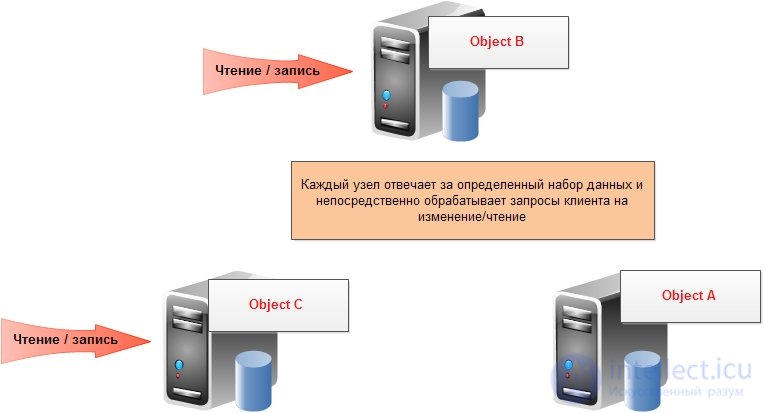
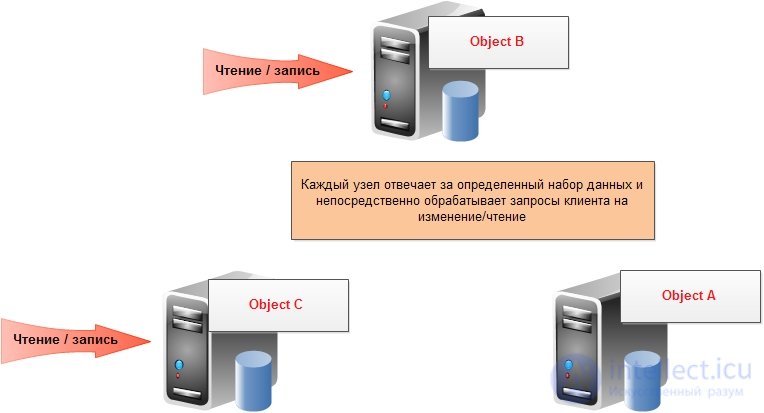
Шардинг часто использовался как “костыль” к реляционным базам данных в целях увеличения скорости и пропускной способности: пользовательское приложение партицировало данные по нескольким независимым базам данных и при запросе соответствующих данных пользователем обращалось к конкретной базе. В NoSQL базах данных шардинг, как и репликация, производятся автоматически самой базой и пользовательское приложение обособленно от этих сложных механизмов.
6. NoSQL базы в-основном оупенсорсные и созданы в 21 столетии.
Именно по второму признаку Садаладж и Фаулер не классифицировали объектные базы данных как NoSQL (хотя http://nosql-database.org/ включает их в общий список), так как они были созданы еще в 90-х и так и не снискали большой популярности.
Дополнительно я хотел остановиться на классификации NoSQL баз данных, но, пожалуй, сделаю это в следующей статье, если это будет интересно хаброюзерам.
Резюме.
NoSQL движение набирает популярность гигантскими темпами. Однако это не означает, что реляционные базы данных становятся рудиментом или чем-то архаичным. Скорее всего они будут использоваться и использоваться по-прежнему активно, но все больше в симбиозе с ними будут выступать NoSQL базы. Мы вступаем в эру polyglot persistence — эру, когда для различных потребностей используются разные хранилища данных. Теперь нет монополизма реляционных баз данных, как безальтернативного источника данных. Все чаще архитекторы выбирают хранилище исходя из природы самих данных и того, как мы ими хотим манипулировать, какие объемы информации ожидаются. И поэтому все становится только интереснее.
Система управления базами данных (СУБД) - это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Системы управления базами данных следует классифицировать отдельно ( рис. 4).
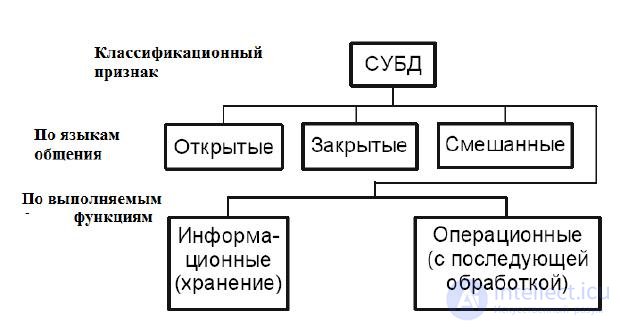
Рис. 4. Классификация СУБД
СУБД представляет собой оболочку, с помощью которой при организации структуры таблиц и заполнения их данными получается та или иная база данных. В связи с этим полезно поговорить о системе программно-технических, организационных и "человеческих" составляющих ( рис. 5).Программные средства включают систему управления, обеспечивающую ввод-вывод, обработку и хранение информации, создание, модификацию и тестирование БД, трансляторы.
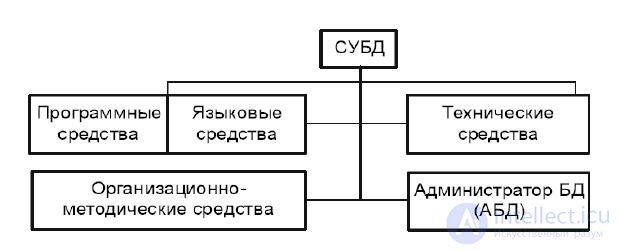
Рис. 5. Состав СУБД
Базовыми внутренними языками программирования являются языки четвертого поколения. В качестве базовых языков могут использоваться C, C++, Pascal, Object Pascal. Язык C++ позволяет строить программы на языке Visual Basic с широким спектром возможностей, более близком и понятном даже пользователю-непрофессионалу, и на непроцедурном (декларативном) языкеструктурированных запросов SQL. Следует отметить, что исторически для системы управления базой данных сложились три языка:
язык описания данных (ЯОД), называемый также языком описания схем, - для построения структуры ("шапки") таблиц БД;
язык манипулирования данными (ЯМД) - для заполнения БД данными и операций обновления (запись, удаление, модификация);
язык запросов - язык поиска наборов величин в файле в соответствии с заданной совокупностью критериев поиска и выдачи затребованных данных без изменения содержимого файлов и БД (язык преобразования критериев в систему команд).
В настоящее время функции всех трех языков выполняет язык SQL, относящийся к классу языков, базирующихся на исчислении кортежей (кортеж чаще всего является единицей информации), языки СУБД FoxPro, Visual Basic for Application (СУБД Access) и т.д.
Вместе с тем сохранились и языки запросов, например язык запросов по примеру Query By Example (QBE) класса исчисления доменов. Отметим, что эти языки в качестве "информационной единицы" БД используют отдельную запись. С помощью языков БДсоздаются приложения, базы данных и интерфейс пользователя, включающий экранные формы, меню, отчеты. При создании БДна базе СУБД FoxPro эти элементы (объекты) фиксируются в отдельных файлах, которые, в свою очередь, сосредоточиваются в одном файле, называемом проектом. После отработки БД проект преобразуется в приложение. В СУБД Access все созданные объекты размещаются в одном файле.
По степени универсальности различают два класса СУБД:
системы общего назначения - реализованные как программный продукт, способный функционировать на ЭВМ в определенной операционной системе и поставляемый пользователям как коммерческое изделие;
специализированные системы - создаваемые в случаях невозможности или не целесообразности использования СУБД общего назначения.
СУБД общего назначения - это сложные программные комплексы, предназначенные для выполнения всей совокупности функций, связанных с созданием и эксплуатацией БД информационной системы.
А как ты думаешь, при улучшении базы данных, будет лучше нам? Надеюсь, что теперь ты понял что такое базы данных, базы данных и знаний, виды баз данных, реляционные, не реляционные, субд, озера данных, сети данных, болото данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии