Лекция
Привет, Вы узнаете о том , что такое оконная функция, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое оконная функция, оконные функции, window functions , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции , считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьей мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
При обычном запросе, все множество строк обрабатывается как бы единым «цельным куском», для которого считаются агрегаты. А при использовании оконных функций, запрос делится на части (окна) и уже для каждой из отдельных частей считаются свои агрегаты.

Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
Примечание Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER дает больше свободы, чем жесткий JOIN. Да и объем кода в итоге окажется гораздо меньше.
оконная функция -это SQL-функция,в которой входные значения берутся из "окна" одной или нескольких строк в наборе результатов оператора SELECT.
Функции окон отличаются от других SQL-функций наличием пункта OVER.Если функция имеет условие OVER,то это функция окна.Если в ней отсутствует условие OVER,то это обычная агрегатная или скалярная функция.Функции окна также могут иметь условие FILTER между функцией и условием OVER.
Оконные функции начинаются с оператора OVER и настраиваются с помощью трех других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Синтаксис примерно такой:
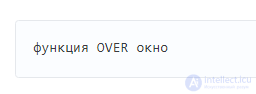

Окно — это некоторое выражение, описывающее набор строк, которые будет обрабатывать функция и порядок этой обработки.
Причем окно может быть просто задано пустыми скобками (), т.е. окном являются все строки результата запроса.
Например, в этом селекте к обычным полям id, header и score просто добавится нумерация строк.
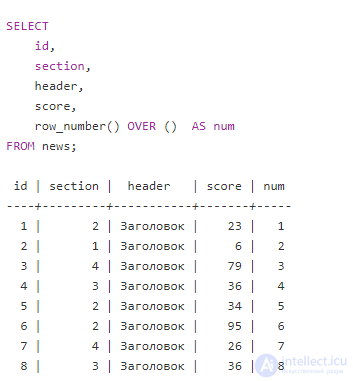
В оконное выражение можно добавить ORDER BY, тогда можно изменить порядок обработки.
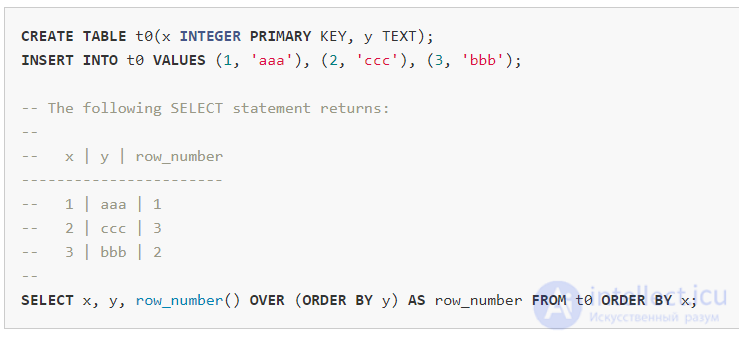
Функция окна row_number()присваивает каждой строке последовательные целые числа в порядке пункта "ORDER BY" внутри окна-defn (в данном случае "ORDER BY y").Обратите внимание,что это не влияет на порядок,в котором результаты возвращаются из общего запроса.Порядок конечного результата по-прежнему регулируется пунктом "ЗАКАЗАТЬ ПО",приложенным к заявлению SELECT (в данном случае "ЗАКАЗАТЬ ПО x").
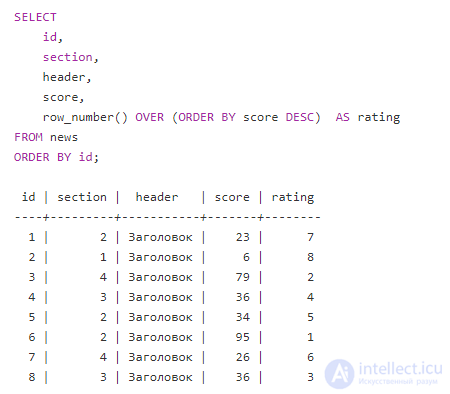
Обратите внимание, что я добавил еще и в конце всего запоса ORDER BY id, при этом рейтинг посчитан все равно верно. Т.е. СУБД просто отсортировал результат вместе с результатом работы оконной функции, один order ничуть не мешает другому.
В отличие от обычных функций,оконные функции не могут использовать ключевое слово DISTINCT.Кроме того,функции окон могут появляться только в наборе результатов и в пункте ORDER BY оператора SELECT.
Оконные функции бывают двух видов: агрегированные оконные функции и встроенные оконные функции . Каждая агрегатная оконная функция может также работать как обычная агрегатная функция, просто опуская предложения OVER и FILTER. Более того, все встроенные агрегатные функции SQLite можно использовать как агрегатную оконную функцию, добавив соответствующее предложение OVER. Приложения могут регистрировать новые агрегированные оконные функции с помощью интерфейса sqlite3_create_window_function () . Однако встроенные оконные функции требуют специальной обработки в планировщике запросов, и, следовательно, новые оконные функции, которые демонстрируют исключительные свойства, обнаруженные во встроенных оконных функциях, не могут быть добавлены приложением.
Агрегатная оконная функция похожа на обычную агрегатную функцию , за исключением того, что ее добавление в запрос не изменяет количество возвращаемых строк. Вместо этого для каждой строки результат агрегатной оконной функции такой, как если бы соответствующий агрегат выполнялся по всем строкам в «оконной рамке», указанной в предложении OVER.
Дальше — больше. В оконное выражение можно добавить слово PARTITION BY [expression],
например row_number() OVER (PARTITION BY section), тогда подсчет будет идти в каждой группе отдельно:
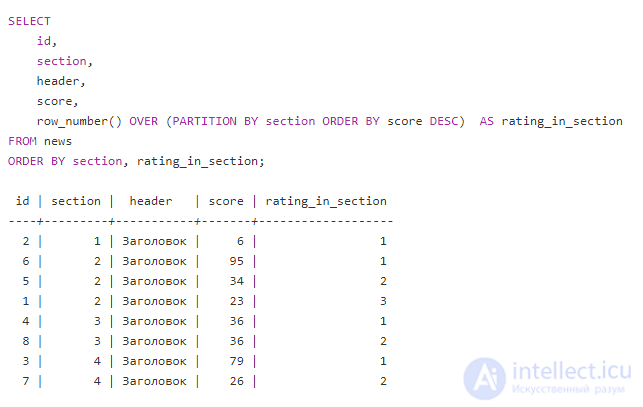
Если не указывать партицию, то партицией является весь запрос.
Тут сразу надо немного сказать о функциях, которые можно использовать, так как есть очень важный нюанс.
В качестве функции можно использовать, так сказать, истинные оконные функции из мануала — это
row_number(),
rank(),
lead() и т.д., а можно использовать функции-агрегаты, такие как: sum(), count() и т.д.
Так вот, это важно, агрегатные функции работают слегка по-другому: если не задан ORDER BY в окне, идет подсчет по всей партиции один раз, и результат пишется во все строки (одинаков для всех строк партиции). Если же ORDER BY задан, то подсчет в каждой строке идет от начала партиции до этой строки.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010:
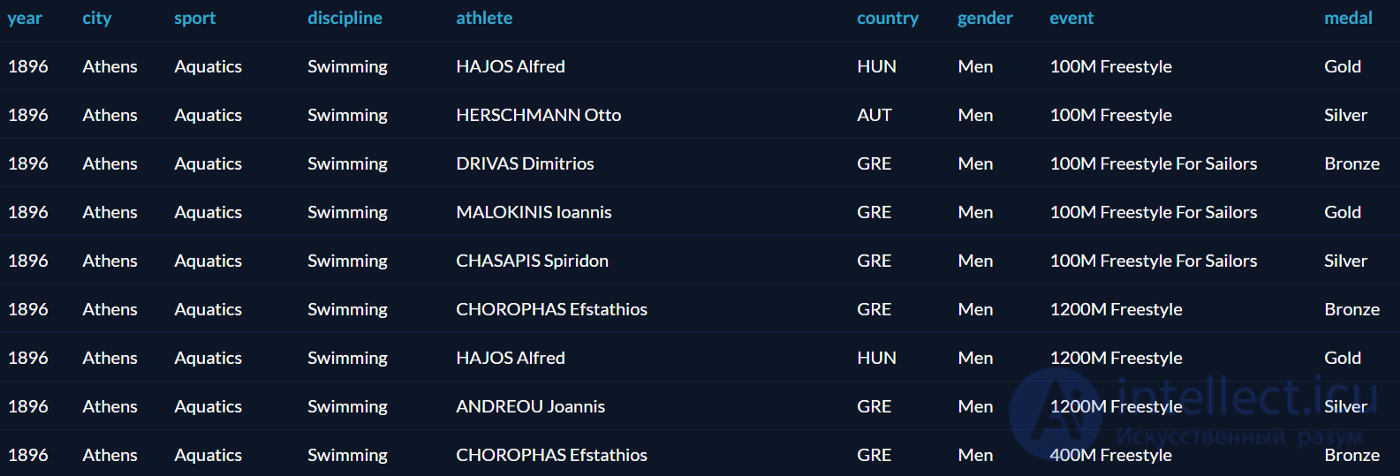
Как уже говорилось выше, оператор OVER создает оконную функцию. Начнем с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
SELECT athlete, event, ROW_NUMBER() OVER() AS Row_Number FROM Summer_Medals ORDER BY Row_Number ASC;

Каждая пара «спортсмен — вид спорта» получила номер, причем к этим номерам можно обращаться по имени row_number.
ROW_NUMBER можно объединить с ORDER BY, чтобы определить, в каком порядке строки будут нумероваться. Выберем с помощью DISTINCT все имеющиеся виды спорта и пронумеруем их в алфавитном порядке:
SELECT sport, ROW_NUMBER() OVER(ORDER BY sport ASC) AS Row_N FROM ( SELECT DISTINCT sport FROM Summer_Medals ) AS sports ORDER BY sport ASC;

PARTITION BY позволяет сгруппировать строки по значению определенного столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учетом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
Функция LAG берет строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:
– Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы WITH Tennis_Gold AS ( SELECT Athlete, Gender, Year, Country FROM Summer_Medals WHERE Year >= 2004 AND Sport = 'Tennis' AND event = 'Singles' AND Medal = 'Gold')
– Оконная функция разделяет по полу и берет чемпиона из предыдущей строки SELECT Athlete as Champion, Gender, Year, LAG(Athlete) OVER (PARTITION BY gender ORDER BY Year ASC) AS Last_Champion FROM Tennis_Gold ORDER BY Gender ASC, Year ASC;
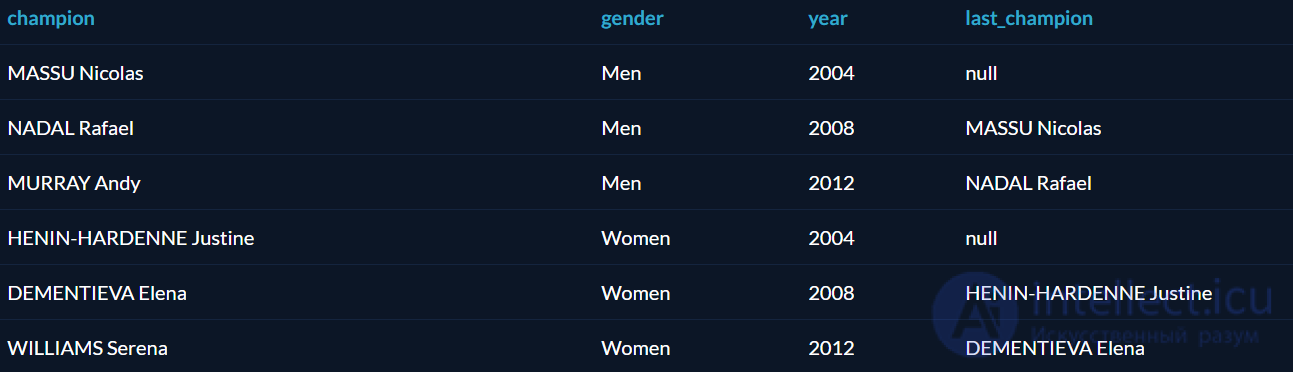
Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин. Для победителей 2008 и 2012 года приведен предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
– Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы WITH Tennis_Gold AS ( SELECT Athlete, Gender, Year, Country FROM Summer_Medals WHERE Year >= 2004 AND Sport = 'Tennis' AND event = 'Singles' AND Medal = 'Gold')
– Оконная функция разделяет по полу и берет чемпиона из следующей строки SELECT Athlete as Champion, Gender, Year, LEAD(Athlete) OVER (PARTITION BY gender ORDER BY Year ASC) AS Future_Champion FROM Tennis_Gold ORDER BY Gender ASC, Year ASC;

Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:

Вот код:
-- Табличное выражение выбирает страны и считает годы
WITH countries AS (
SELECT
Country,
COUNT(DISTINCT year) AS participated
FROM
Summer_Medals
WHERE
Country in ('GBR', 'DEN', 'FRA', 'ITA','AUT')
GROUP BY
Country)
-- Разные оконные функции ранжируют страны
SELECT
Country,
participated,
ROW_NUMBER()
OVER(ORDER BY participated DESC) AS Row_Number,
RANK()
OVER(ORDER BY participated DESC) AS Rank_Number,
DENSE_RANK()
OVER(ORDER BY participated DESC) AS Dense_Rank
FROM countries
ORDER BY participated DESC;
Есть три типа рам:ROWS,GROUPS и RANGE.Тип кадра определяет,как измеряются начальная и конечная границы кадра.
ROWS : тип кадра ROWS означает, что начальная и конечная границы кадра определяются путем подсчета отдельных строк относительно текущей строки.
ГРУППЫ : Тип кадра ГРУППЫ означает, что начальная и конечная границы определяются путем подсчета «групп» относительно текущей группы. «Группа» - это набор строк, каждая из которых имеет эквивалентные значения для всех условий предложения ORDER BY окна. («Эквивалентность» означает, что оператор IS истинен при сравнении двух значений.) Другими словами, группа состоит из всех одноранговых узлов строки.
RANGE : тип кадра RANGE требует, чтобы в предложении ORDER BY окна был ровно один член. Назовите этот термин «X». С типом кадра RANGE элементы кадра определяются путем вычисления значения выражения X для всех строк в разделе и кадрирования тех строк, для которых значение X находится в пределах определенного диапазона значения X для текущей строки. . Подробнее см. Описание в спецификации границы « PRECEDING » ниже.
Типы кадров ROWS и GROUPS похожи в том,что они оба определяют протяженность кадра путем подсчета относительно текущего ряда.Разница заключается в том,что ROWS считает отдельные строки,а GROUPS-одноранговые группы.Тип кадра RANGE отличается.Тип кадра RANGE определяет протяженность кадра путем поиска значений выражений,которые находятся в пределах некоторого диапазона значений относительно текущей строки.
Окно определяется с помощью обязательной инструкции OVER(). Давайте рассмотрим синтаксис этой инструкции:
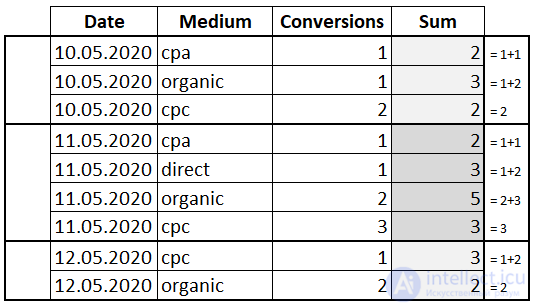
Теперь разберем как поведет себя множество строк при использовании того или иного ключевого слова функции. А тренироваться будем на простой табличке содержащей дату, канал с которого пришел пользователь и количество конверсий:
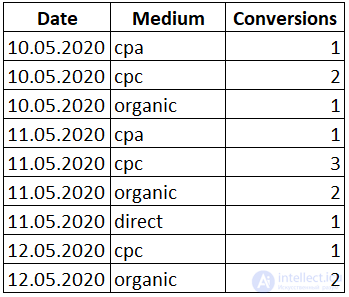
Откроем окно при помощи OVER() и просуммируем столбец «Conversions»:
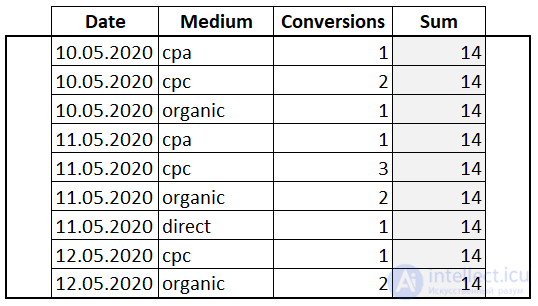
Мы использовали инструкцию OVER() без предложений. В таком варианте окном будет весь набор данных и никакая сортировка не применяется. Появился новый столбец «Sum» и для каждой строки выводится одно и то же значение 14. Это сквозная сумма всех значений колонки «Conversions».
Теперь применим инструкцию PARTITION BY, которая определяет столбец, по которому будет производиться группировка и является ключевой в разделении набора строк на окна:

Инструкция PARTITION BY сгруппировала строки по полю «Date». Теперь для каждой группы рассчитывается своя сумма значений столбца «Conversions».
Попробуем отсортировать значения внутри окна при помощи ORDER BY:

К предложению PARTITION BY добавилось ORDER BY по полю «Medium». Таким образом мы указали, что хотим видеть сумму не всех значений в окне, а для каждого значения «Conversions» сумму со всеми предыдущими. То есть мы посчитали нарастающий итог.
Инструкция ROWS позволяет ограничить строки в окне, указывая фиксированное количество строк, предшествующих или следующих за текущей.
Инструкция RANGE, в отличие от ROWS, работает не со строками, а с диапазоном строк в инструкции ORDER BY. То есть под одной строкой для RANGE могут пониматься несколько физических строк одинаковых по рангу.
Обе инструкции ROWS и RANGE всегда используются вместе с ORDER BY.
В выражении для ограничения строк ROWS или RANGE также можно использовать следующие ключевые слова:
Разберем на примере:
В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать.
Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Оконные функции можно подразделить на следующие группы:
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
Пример использования агрегатных функций с оконной инструкцией OVER:


Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.

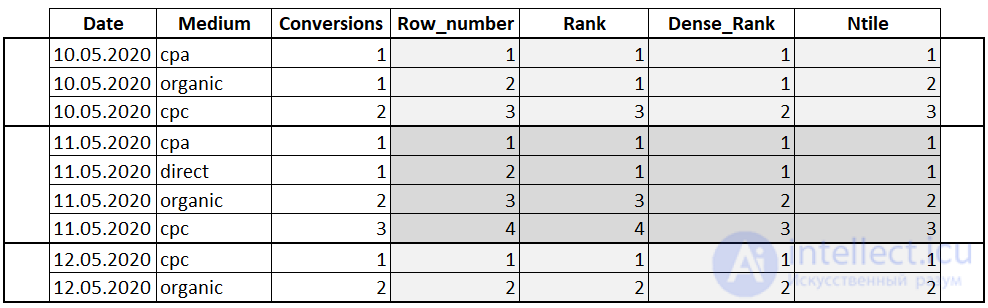
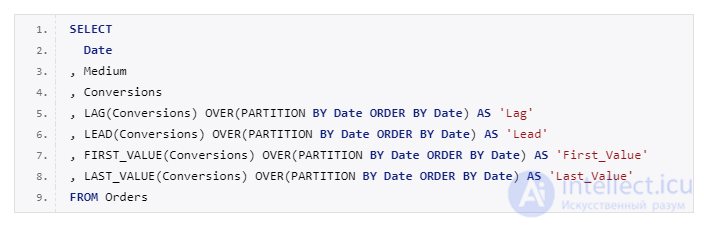
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
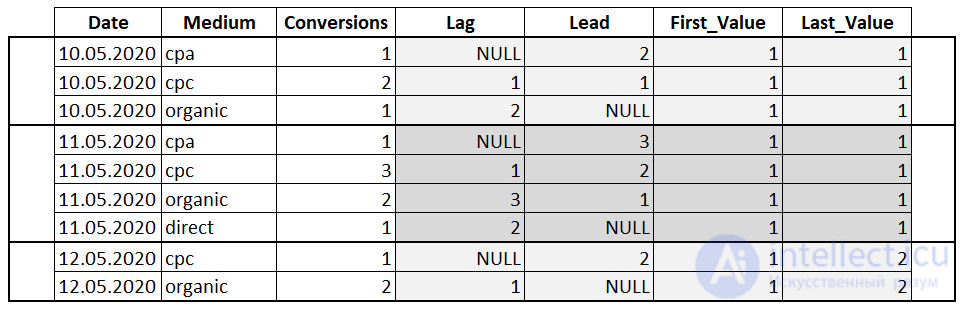
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP.
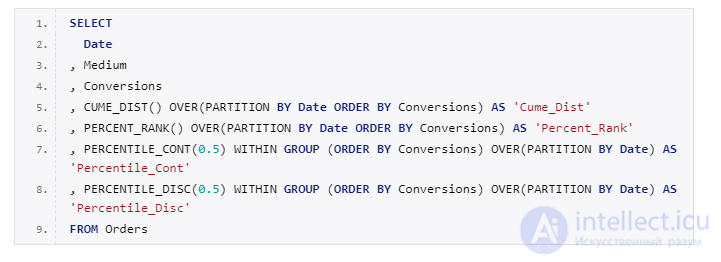
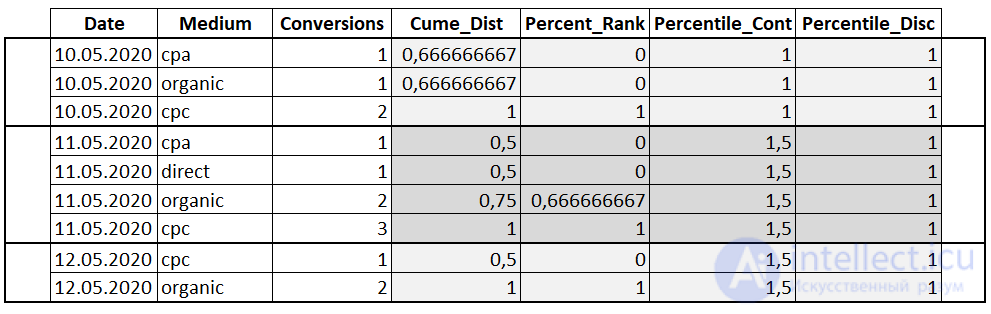
Благодаря модели атрибуции можно обоснованно оценить вклад каждого канала в достижение конверсии. Давайте попробуем посчитать две разных модели атрибуции с помощью оконных функций.
У нас есть таблица с id посетителя (им может быть Client ID, номер телефона и тп.), датами и количеством посещений сайта, а также с информацией о достигнутых конверсиях.

В Google Analytics стандартной моделью атрибуции является последний непрямой клик. И в данном случае 100% ценности конверсии присваивается последнему каналу в цепочке взаимодействий.
Попробуем посчитать модель по первому взаимодействию, когда 100% ценности конверсии присваивается первому каналу в цепочке при помощи функции FIRST_VALUE.
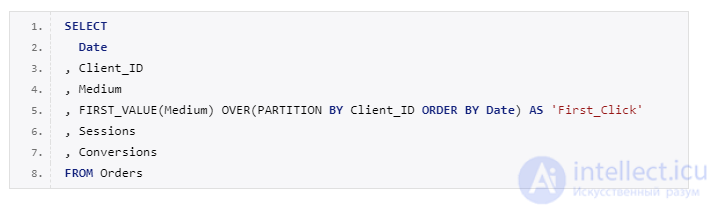

Рядом со столбцом «Medium» появился новый столбец «First_Click», в котором указан канал в первый раз приведший посетителя к нам на сайт и вся ценность зачтена данному каналу.
Произведем агрегацию и получим отчет.

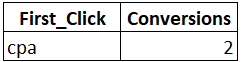
В этом случае работает правило: чем ближе к конверсии находится точка взаимодействия, тем более ценной она считается. Попробуем рассчитать эту модель при помощи функции DENSE_RANK.
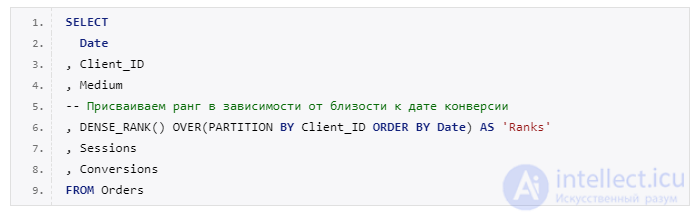
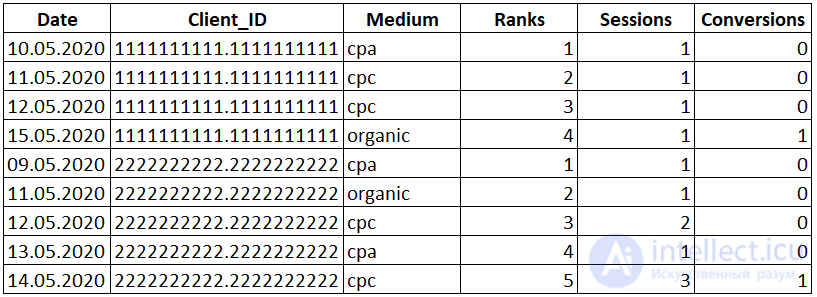
Рядом со столбцом «Medium» появился новый столбец «Ranks», в котором указан ранг каждой строки в зависимости от близости к дате конверсии.
Теперь используем этот запрос для того, чтобы распределить ценность равную 1 (100%) по всем точкам на пути к конверсии.

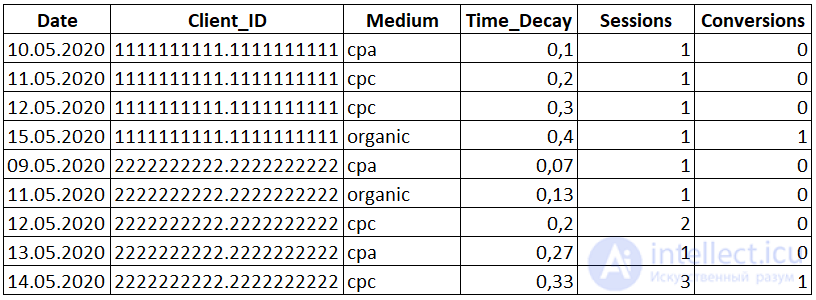
Рядом со столбцом «Medium» появился новый столбец «Time_Decay» с распределенной ценностью.
И теперь, если сделать агрегацию, можно увидеть как распределилась ценность по каналам.

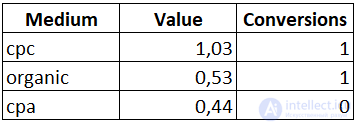
Из получившегося отчета видно, что самым весомым каналом является канал «cpc», а канал «cpa», который был бы исключен при применении стандартной модели атрибуции, тоже получил свою долю при распределении ценности.
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.
Исследование, описанное в статье про оконная функция, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое оконная функция, оконные функции, window functions и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL