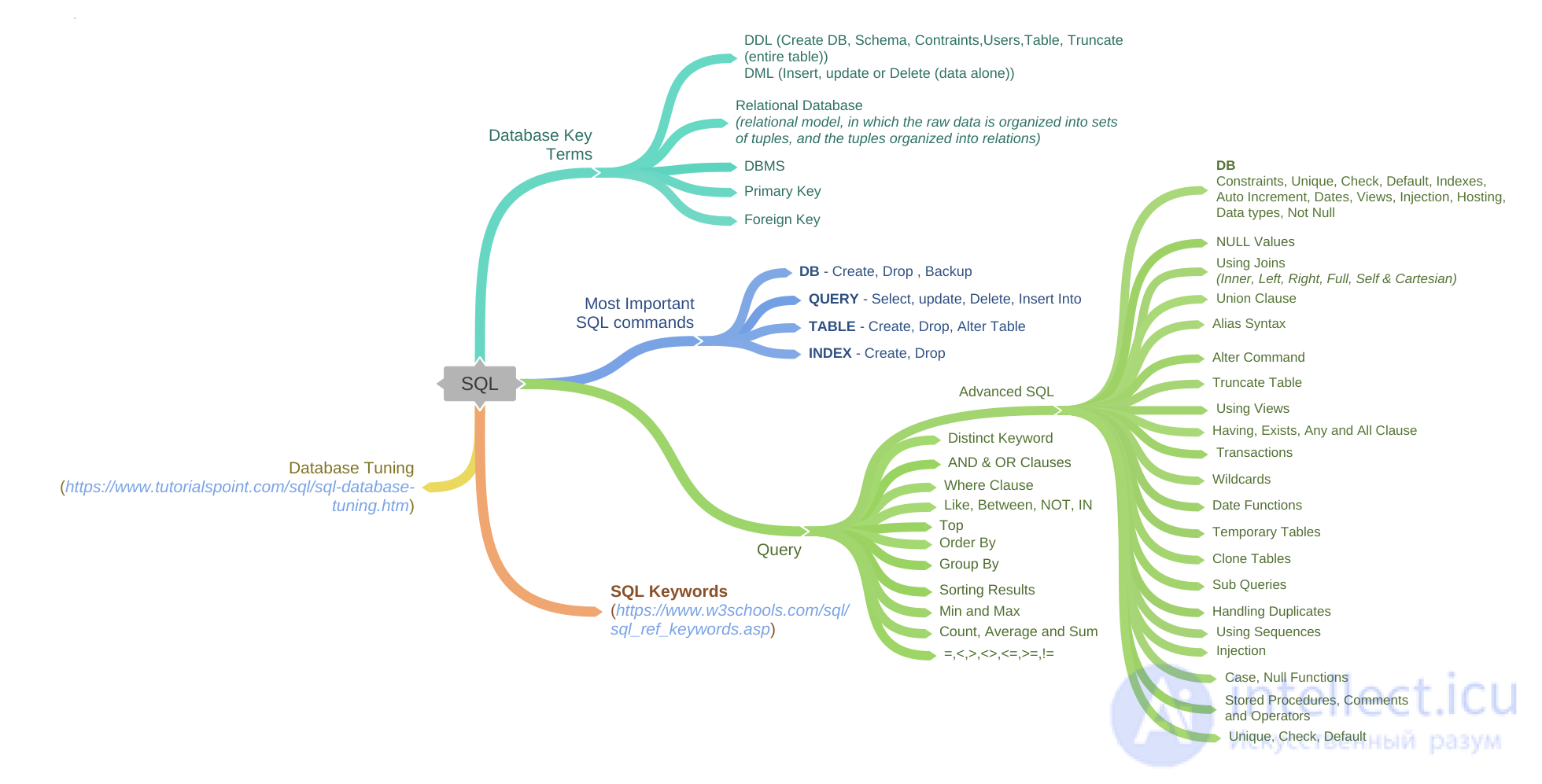
Лекция
Привет, Вы узнаете о том , что такое реляционные базы данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое реляционные базы данных, crud, crud операции, типы данных sql, виды запросов, виды sql операций, ddl, dml, dcl, tcl, select from, insert into , update set, delete from, upsert , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Реляционная база данных — база данных, основанная на реляционной модели данных. Понятие «реляционный» основано на англ. relation («отношение, зависимость, связь»). Для работы с реляционными БД применяют реляционные СУБД.
Практически все базы данных имеют следующие составляющие
При создании таблицы или добавлении поля в таблицу базы геоданных поля создаются с конкретным типом данных. Типы данных представляют собой классификации, которые позволяют определить возможные значения, операции, которые могут быть выполнены для этих данных, а также каким образом данные этого поля будут храниться в базе данных.
В каждой БД свой набор типов, но часто есть типы данных которые поддерживаю почти все БД
целочисленные INT
с плаващей точккой FLOAT, DECIMAL
строковые VARCHAR, TEXT
время DATE, TIME, TIMESTAMP
+ - * /

CRUD — акроним, обозначающий четыре базовые функции, используемые при работе с базами данных : создание (англ. create), чтение (read), модификация (update), удаление (delete). Введен Джеймсом Мартином (англ. James Martin) в 1983 году как стандартная классификация функций по манипуляции данными.
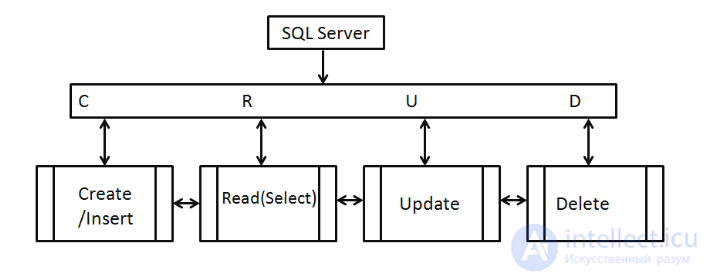
1) Первая буква CRUD, «C», относится к CREATE, также известному как add, insert. В этой операции ожидается вставка новой записи с помощью оператора вставки SQL . SQL использует оператор INSERT INTO для создания новых записей в таблице.
2) Вторая буква CRUD, «R», относится к операции SELECT (получение данных). Слово «чтение» извлекает данные или набор записей из перечисленных таблиц. SQL использует команду SELECT для извлечения данных. Когда дело доходит до выполнения запросов, вы можете использовать SQL Server Management Studio, SQL Server Data Tools или sqlcmd в зависимости от ваших предпочтений.
Например, чтобы прочитать связанные данные из указанной таблицы, воспользуйтесь синтаксисом ниже.
SELECT * FROM <TableName>
3) Третья буква CRUD, «U», относится к операции обновления. Используя ключевое слово Update, SQL вносит изменения в существующие записи таблицы.
При выполнении обновления вам необходимо определить целевую таблицу и столбцы, которые необходимо обновить, вместе со связанными значениями, и вам также может потребоваться знать, какие строки необходимо обновить. В общем, вы хотите ограничить количество строк, чтобы избежать проблем с эскалацией блокировок и параллелизмом.
В SQL этим функциям операциям соответствуют операторы Insert (создание записей), Select (чтение записей), Update (редактирование записей), Delete (удаление записей) также используется некая матрица полномочий, crud matrix

В реляционной базе данных каждая таблица должна иметь первичный ключ — поле или комбинацию полей, которые единственным образом идентифицируют каждую строку таблицы. Если ключ состоит из нескольких полей, он называется составным. Ключ должен быть уникальным и однозначно определять запись. По значению ключа можно отыскать единственную запись. Ключи служат также для упорядочивания информации в БД.
Таблицы реляционной БД должны отвечать требованиям нормализации отношений. Нормализация отношений — это формальный аппарат ограничений на формирование таблиц, который позволяет устранить дублирование, обеспечивает непротиворечивость хранимых в базе данных, уменьшает трудозатраты на ведение базы данных.
5.1 вложенные SQL запросы
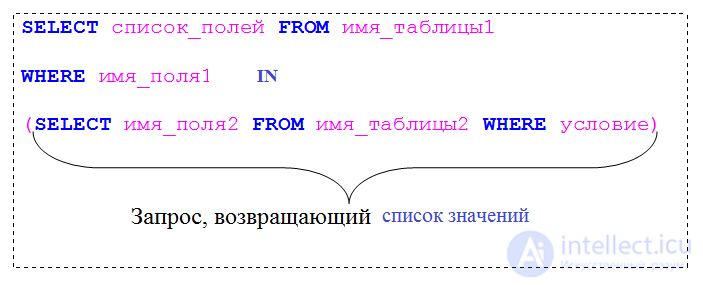
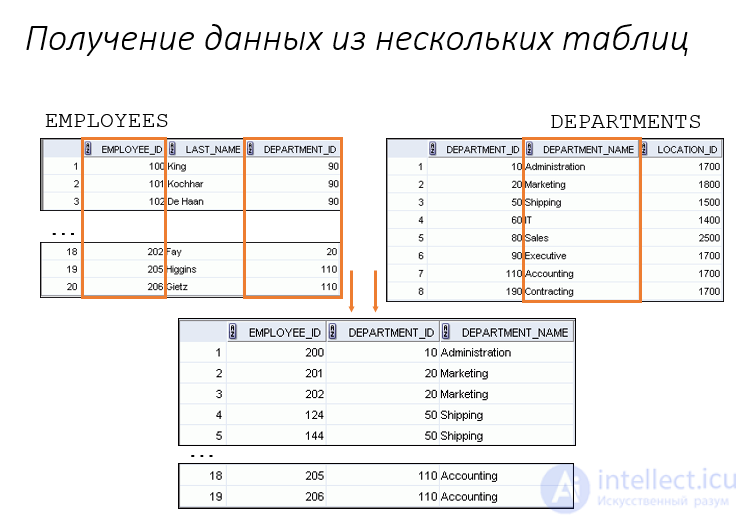
Запрос – это важнейший инструмент для извлечения информации из одной или нескольких таблиц БД. Посредством запроса можно вносить изменения в саму БД. Запрос может служить источником данных для форм, отчетов и страниц доступа к данным.
В этом случае вложенный запрос размещается в инструкции WHERE основного запроса, как показано на рисунке:

При этом следует помнить, что вложенный запрос должен возвращать гарантированно одно значение. Именно с этим значением будет производиться сравнение. Если вложенный запрос вернет несколько значений, то сравнение произвести не удастся из-за отсутствия однозначности.
Пусть в таблице spec хранится список специальностей вуза. Каждая специальность прикреплена к своему факультету. Факультеты хранятся в таблице facult. Таким образом, имеется связь типа «один-ко-многим» между факультетами и специальностями.

Необходимо получить список специальностей факультета «математический».
С этой целью выполним запрос:

SELECT spec.namespec FROM spec WHERE spec.idfacult=1;
В итоге будет получен список из двух специальностей: Прикладная математика и Кибернетика.
Здесь вместо знака равно в инструкции WHERE используется оператор IN, который будет сравнивать значение поля со списком значений.
Попробуем вывести список заявлений, поданных на математический факультет. Задача отличается от предыдущей тем, что на факультете несколько специальностей. Следовательно, нужно искать заявления, которые поданы не на одну специальность, а на целый список специальностей:


Он вернет список заявлений, поданных на специальности 1 и 6.
Соотнесенный(коррелирующий) подзапрос – это подзапрос, который содержит ссылку на поля из внешнего запроса.

Пусть каждый выпускник подал несколько заявлений на разные специальности. У заявления есть много атрибутов: форма обучения, приоритет, курс, специальность и т.д. Для каждого абитуриента нужно заявление, которое было подано им последним. (Допустим, абитуриент Интеллект интелектович подал три заявления. Из этого списка необходимо только то заявление, которое было подано позже двух других.)
Найти такие заявления очень просто запросом с группировкой по коду абитуриента:

Но в результате мы получим только код заявления, в то время как нужно видеть все атрибуты заявления - форму, специальность, приоритет, курс и т.д. Добавлять «лишние» поля в групповые запросы крайне нежелательно. Поэтому задачу лучше всего решать с помощью соотнесенного подзапорса.
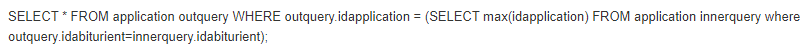
outquery и innerquery здесь являются псевдонимами для внешней и внутренней части.
Вложенный запрос – это запрос, который находится внутри другого SQL запроса и встроен внутри условного оператора WHERE.
Данный вид запросов используется для возвращения данных, которые будут использоваться в основном запросе, как условие для ограничения получаемых данных.
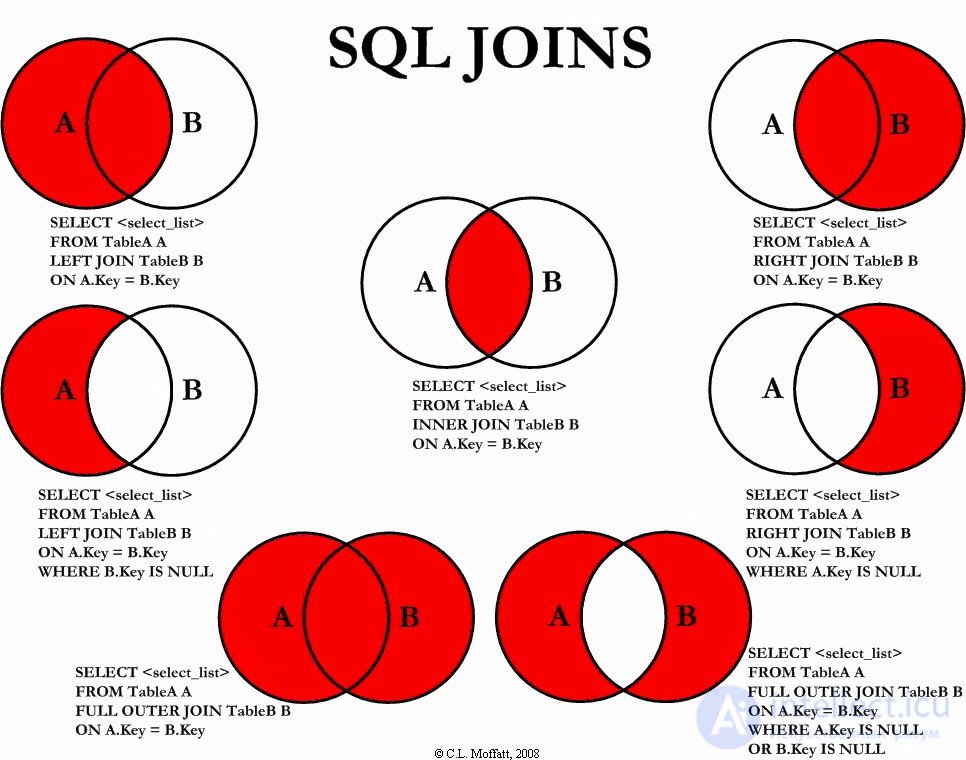
Операция объединения (JOIN) является наиболее мощной функциональной особенностью языка SQL, Ее концепция очень проста, но при этом широко применима в случаях, когда нужно объединить два и более набора данных. Объединение двух таблиц заключается в объединении каждой строки первой таблицы с каждой строкой второй таблицы, для которых истинно значение некоторого предиката.
1) CROSS JOIN является базовым вариантом объединения и представляет собой декартово произведение (Cartesian product). Эта операция просто объединяет каждую строку первой таблицы с каждой строкой второй таблицы
2) операция INNER JOIN (или просто JOIN, иногда также THETA JOIN) позволяет выполнять фильтрацию результата декартова произведения на основе некоторого предиката.
3) EQUI JOIN. На самом деле, «EQUI» не является ключевым словом SQL, а просто обозначает специальный вариант записи особого случая операции INNER JOIN. Следует отметить, что не совсем правомерно называть EQUI JOIN особым случаем, поскольку эту операцию мы выполняем чаще всего в SQL и OLTP приложениях, когда просто объединяем таблицы на основе отношения первичного/внешнего ключа.
4) Левое внешнее объединение (LEFT OUTER JOIN) Мы рассмотрели операцию INNER JOIN, возвращающую только те комбинации строк левой/правой таблицы, для которых значение предиката в предложении ON является истинным. Операция OUTER JOIN позволяет нам включить в результат строки одной таблицы, для которых не были найдены соответствующие строки в другой таблице.
5) Правое внешнее объединение (RIGHT OUTER JOIN) Операция RIGHT OUTER JOIN выполняет ту же задачу, что и LEFT OUTER JOIN, но для правой таблицы, то есть возвращает в результате все строки правой таблицы.
6) Полное внешнее объединение (FULL OUTER JOIN) Существует также операция FULL OUTER JOIN, которая возвращает в результате все строки как левой, так и правой таблицы.Альтернативный синтаксис: Внешнее объединение на основе равенства (EQUI OUTER JOIN)
7) Полуобъединение («SEMI» JOIN) В реляционной алгебре существует операция полуобъединения (semi join), которая, к сожалению, не имеет синтаксического представления в SQL. Если бы синтаксис для данной операции существовал, вероятно, он имел бы следующий вид: LEFT SEMI JOIN и RIGHT SEMI JOIN
8)В SQL мы можем использовать два варианта альтернативного синтаксиса, чтобы реализовать операцию «SEMI» JOIN.
Альтернативный синтаксис: EXISTS Альтернативный синтаксис: IN
9)Антиобъединение («ANTI» JOIN) Операция «ANTI» JOIN является противоположностью операции «SEMI» JOIN
Альтернативный синтаксис: NOT EXISTS(Опасный) альтернативный синтаксис: NOT IN Будьте осторожны! В то время как синтаксисы на основе EXISTS и IN эквивалентны, синтаксисы на основе NOT EXISTS и NOT IN не эквивалентны. Это связано со спецификой NULL-значений.
(Опасный) альтернативный синтаксис: LEFT JOIN / IS NULL
10)Латеральное объединение (LATERAL JOIN) альтернативный синтаксис на основе ключевого слова APPLY
11) Объединение на основе MULTISET Немногие СУБД поддерживают данный тип объединения (на самом деле, только Oracle), но если задуматься, это крайне полезный вариант операции JOIN, позволяющий создавать вложенные коллекции (nested collection). Если бы все СУБД поддерживали эту операцию, нам больше не понадобилось бы объектно-реляционное отображение (object-relational mapping, ORM)!

Оператор UNION позволяет обединить две однотипных выборки. Эти выборки могут быть из разных таблиц или из одной и той же таблицы
(подробнее читай др. наши лекции или веди в поиск нужное)
В SQL команда UPSERT — это комбинация двух операций: INSERT и UPDATE. Она используется для того, чтобы вставить новую запись в таблицу, если ее не существует, или обновить уже существующую запись, если она есть. Это помогает избежать дублирования данных.
В разных системах управления базами данных (СУБД) реализация UPSERT может немного отличаться.
В PostgreSQL используется конструкция INSERT ... ON CONFLICT, которая реализует UPSERT:
INSERT INTO table_name (column1, column2, column3) VALUES (value1, value2, value3) ON CONFLICT (column1) DO UPDATE SET column2 = EXCLUDED.column2, column3 = EXCLUDED.column3;
Здесь:
В MySQL используется конструкция INSERT ... ON DUPLICATE KEY UPDATE:
INSERT INTO table_name (column1, column2, column3) VALUES (value1, value2, value3) ON DUPLICATE KEY UPDATE column2 = VALUES(column2), column3 = VALUES(column3);
Здесь:
SQLite использует INSERT OR REPLACE для реализации подобного поведения:
INSERT OR REPLACE INTO table_name (column1, column2, column3) VALUES (value1, value2, value3);
Однако, в этом случае, если запись с таким уникальным ключом существует, она будет удалена и заново создана, что не всегда удобно.
Таким образом, UPSERT — это мощная команда для работы с данными, позволяющая одновременно и добавлять, и обновлять записи в зависимости от ситуации.
Хранимые функции являются разновидностью хранимых процедур. Они включены в состав программных объектов баз данных с целью наибольшего соответствия языкам программирования, например Си или Java. Хранимые функции применяются для расширения функциональных возможностей операторов SELECT и ряда других SQL-операторов.

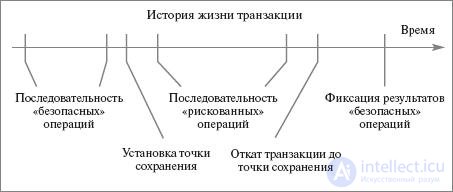
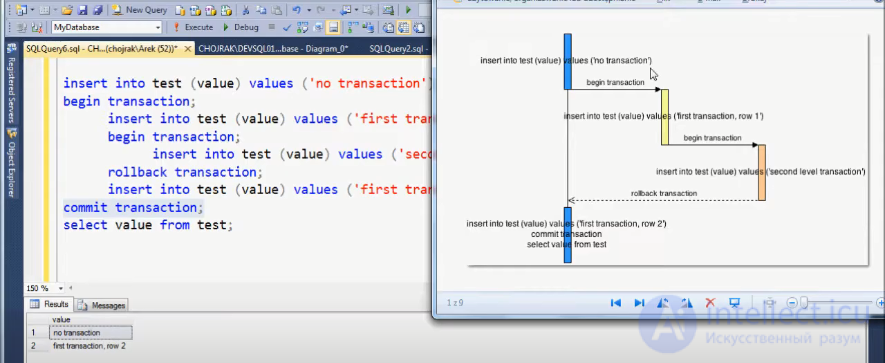


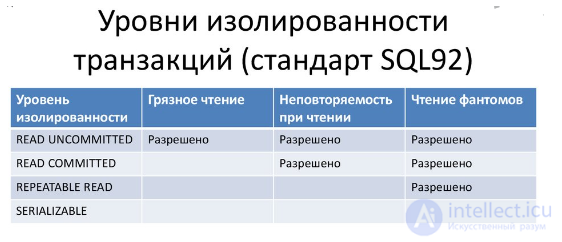
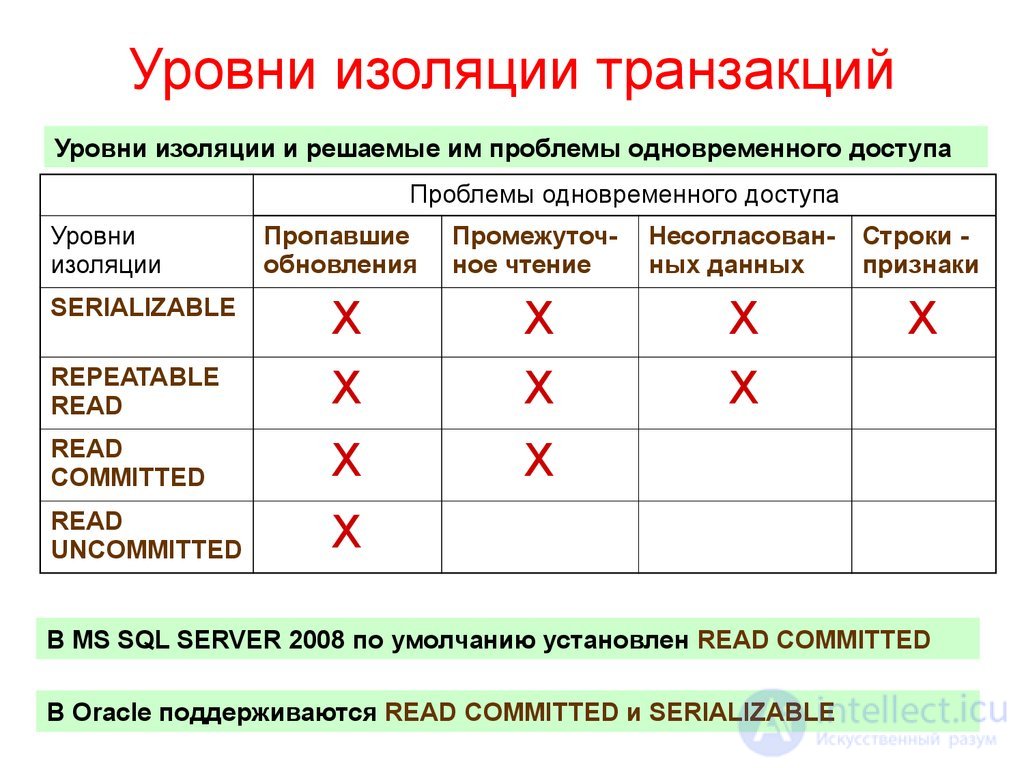
При одновременном выполнении двух транзакций, обращающихся к одним и тем же данным, могут возникать следующие проблемные ситуации:
В заключение, эта статья об реляционные базы данных подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое реляционные базы данных, crud, crud операции, типы данных sql, виды запросов, виды sql операций, ddl, dml, dcl, tcl, select from, insert into , update set, delete from, upsert и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL

Комментарии