Лекция
Привет, Вы узнаете о том , что такое организация синхронизации данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое организация синхронизации данных, клиент-сервер для мобильного приложения , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.

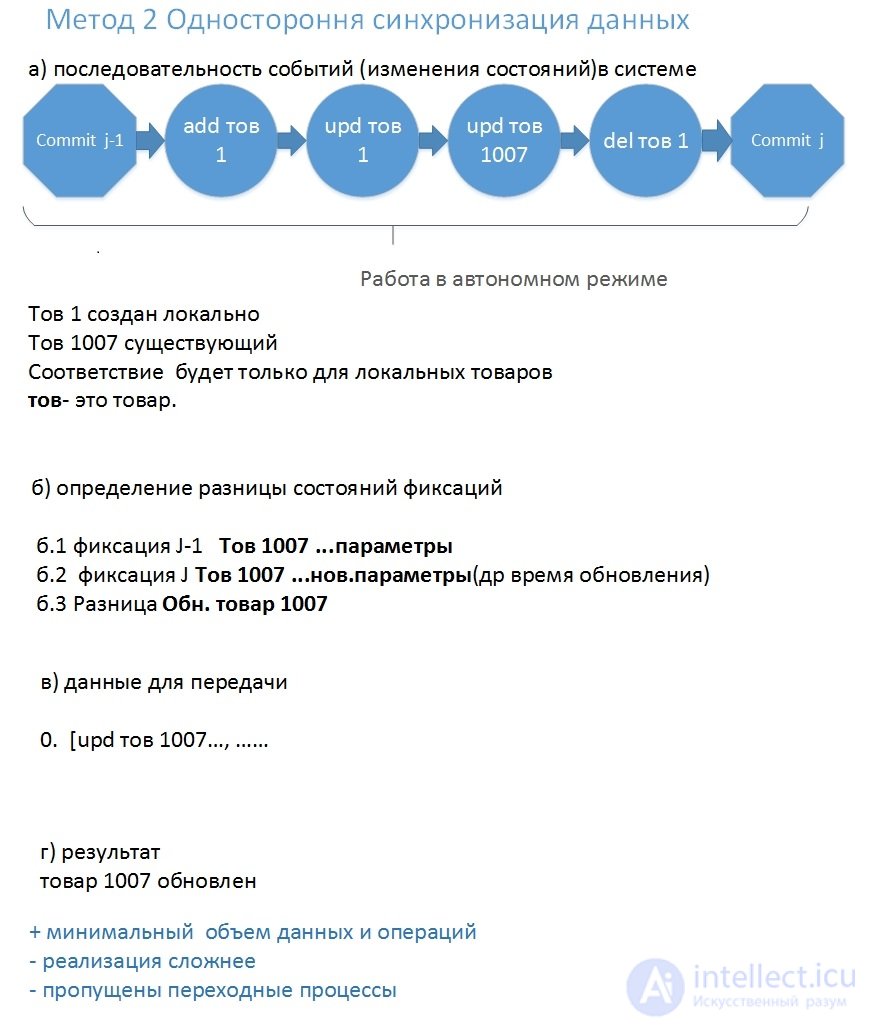
передаваемые параметры (поля) 1.data- строка в формате json Описание: 1. данные в поле data передаются в строке в формате json В них передаем данные, которые нужно синхронизировать. При этом используется: а) уникальное локальное время создания(изменения) "ut" (каждой записи ) б) и уникальный локальный ид (для каждой сущности) (ид толжны быть уникальны, иметь знак -). в) передача без знака минус для ид , если ид глобальный.
data =
[
{
"cmd":1,
"ut":134256789088,
"tb":"product",
"dt": [-6341,134,13,12,12312,12]
},
{ "cmd":2,
"ut":4578678789876,
"tb":"product",
"dt":[1,12,162,124,142,12,12,-341, 126,12,122,122]
},
{ "cmd":3,
"ut":45678908765,
"tb":"product",
"dt":
}
]
где
cmd - команда (1,2,3) подробнее см. ниже
ut - юникстайм (в секундах) каждой записи на устройстве
( время последней локальной работы с данным объектом )
dt- массив данных без названий полей
tb - название таблицы для синхронизации
значения см ниже
2. передавать не более N записей за один запрос, если записей больше N, то передать сначала подчиненные записи , потом все остальное порциями(постранично)
Комментарии
1. если устройство получило негативный ответ от сервера(отличный от 200 и после повтора передачи без синхронизации)
или у устройства нет доступа в интернет то все данные записывать в локальную базу
после появления интернет или при наличии таких данных определить разность ранее синхронизированных данных
и новых данных собранных offline
результатом этих сравнений должны быть объекты и три операции над ними добавление, обновление, удаление
необходимые для того чтобы базы были одинаковые
2. отправляем следующие данные
--с ид <0 (приложение все записи созданные в автономном режиме сохраняет с глобальным ид=0,
но передавать нужно с локальным ид со знаком минус)- если новый объект- использоваться может в связанных данных
(после передачи команды на синхронизацию и в случае успеха приложение должно обновить глобальные ид на серверные значения)
--с признаком обновления (приложение должно иметь флаг обновления к каждой записи синхнонизируемых сущностей)
данный флаг можно сбросить только после отправки команды синхронизировать и если она прошла успешно
--с ид в таблице удалений (приложение должно хранить все ид записей и название сущностей которые удаляются в автономном режиме)
после отправки команды на синхронизацию и в случае ее успешного выполнения приложение очищает список удаленных записей
3.отправляем команду на синхронизацию
в случае успеха загружаем все данные или загружаем измененные данные и удаляем служебные данные в приложении
(в этот момент формируется отложенная запись на синхронизацию в связанных аккаунтах через PUSH)
4.клиент хранит
1. новые записи должны иметь ид <0 и равным уникальному локальному номеру
2.удаленные записи должны храниться в таблице удалений
3. обновленные записи в автономном режиме желательно помечать признаком обновлений
5.названия операций
ins=1
upd=2
del=3
6.название сущностей и полей доступных для вставки или обновления (если запись нужно удалить то нужен только ид):
передавать данные нужно именно в этом порядке без названия полей- только данные
сущность1 [id ид.поля..... ]
сущность2[id ид.поля..... ]
сущность3 [id ид.поля..... ]
т.о. синхронизация от устройства на сервер состоит из таких дейтвий
1. передать данные (при этом выволняются комплекс проверок на сервере)
2. сохранить изменения (выполняются изменения отсортированные по unixtime )
и ставятся изменения(синхронизвции через пуши) в очередь для связанных
с этим аккаунтом устройствами (аккаунтами)
3. если на сервере имеется запись с unixtime больше чем на устройстве,
то изменение или удаление данной записи игнорируется и такую запись
нужно устройству уже загрузить с сервера
4. после передачи и фиксации данных на сервере нужно получить
данные(из п3) от сервера и занести в локальную бд устройства
5. т.к нет обратной синхронизации,то желательно в конце выполнить полную загрузку данных
(для обновления ид),это нужно если не доставился, или не отправился пуш с запросом на обратную синхронизацию или не учитывались данные переданные
в пуш
примечания
1. отрицальный локальный ид используется в трех случаях
если добавляется новая запись - всегда
(должна быть обязательно передана раньше ее использования в других записях)
если обновляется или удаляется запись созданная локально, при этом передавать такую запись не имеет смыла в случае синхронизации по методу 2
если обновляется существующая запись но с указанием в поле на локальную запись
Прочтение данной статьи про организация синхронизации данных позволяет сделать вывод о значимости данной информации для обеспечения качества и оптимальности процессов. Надеюсь, что теперь ты понял что такое организация синхронизации данных, клиент-сервер для мобильного приложения и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Из статьи мы узнали кратко, но содержательно про организация синхронизации данных
Комментарии