Лекция
Привет, Вы узнаете о том , что такое аналитическая обработка данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое аналитическая обработка данных, аналитическая обработка данных в хранилищах данных, аналитические функции, статистические функции, функции ранжирования, оконные функции, функции для генерирования отчетов , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
В настоящей лекции мы сконцентрируем внимание на тех возможностях, которые предоставляет SQL по аналитической обработке данных в ХД. В приводимых примерах будем придерживаться диалекта Transact-SQL СУБД семейства MS SQL Server.
Отметим, что в целом SQL не имеет хорошей поддержки для решения аналитических задач. Однако встроенная поддержка аналитических функций в Transact-SQL и его ориентированность на работу с множествами делают его хорошим инструментом для выполнения таких вычислений над данными, хранящимися в ХД. аналитические функции и ориентированность на работу с множествами дают Transact-SQL определенные преимущества перед другими языками манипулирования данными.
Основные вычисления в системах бизнес-аналитики — вычисление скользящего среднего, ранжирование выборки, и т. д. — требуют большого объема программирования в стандартном SQL. Функции такого типа называются аналитическими функциями.
Аналитические функции подразделяются на следующие категории:
В табл. 23.1 приведена краткая характеристика категорий аналитических функций.
| Тип | Использование |
|---|---|
| Ранжирование | Вычисление рангов, проценталей в результирующем множестве |
| Оконные функции | Вычисление кумулятивных и скользящих средних: SUM, AVG, MIN, MAX, COUNT, и т.д. |
| Генерирование отчетов | Формируют результирующие множества для построения отчетов. Работа с функциями: SUM, AVG, MIN, MAX, COUNT и т.д. |
| Статистические функции | Вычисляют средние, дисперсии и т.д. по результирующему множеству |
Для выполнения этих операций добавлено несколько элементов в обработку команд SQL. Эти элементы встроены в SQL. Существует несколько новых понятий, используемых аналитическими функциями.
В Transact-SQL поддерживаются девять различных агрегатных функций, которые необходимы при проведении статистических расчетов. Помимо агрегатных функций, которые уже упоминались в предыдущей лекции, — SUM(), MIN(), MAX(), COUNT() и AVG() — имеются еще четыре, непосредственно предназначенные для финансовых и статистических вычислений: STDEV(), STDEVP(), VAR(), VARP() (табл. 23.2).
Статистические функции выполняют вычисление на наборе значений и возвращают одиночное значение. За исключением функции COUNT, эти функции не учитывают значения NULL. Также они часто используются в выражении GROUP BY команды SELECT.
Эти функции могут использоваться в качестве выражений только в следующих случаях:
| Функция | Возвращаемое значение |
|---|---|
| AVG() | Возвращает среднее арифметическое группы значений. Значения NULL не учитываются. Возвращаемый тип определяется типом вычисленного результата expression.
AVG ( [ ALL | DISTINCT ] expression ) |
| CHECKSUM_AGG() | Возвращает контрольную сумму значений в группе. Значения NULL не учитываются. Возвращает контрольную сумму всех значений expression как int.
CHECKSUM_AGG ( [ ALL | DISTINCT ] expression ) |
| COUNT(*) | Возвращает количество элементов в группе. Функция COUNT всегда возвращает значение типа int.
COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
|
| COUNT_BIG | Возвращает количество элементов в группе. Функция COUNT_BIG всегда возвращает значение типа bigint.
COUNT_BIG ( { [ ALL | DISTINCT ] expression } | * )
|
| GROUPING | Указывает, является указанное выражение столбца в списке GROUP BY статистическим или нет. В результирующем наборе функция GROUPING возвращает 1 (статистическое выражение) или ноль (нестатистическое выражение). Функция GROUPING может использоваться только в предложениях SELECT <список выбора>, HAVING и ORDER BY, если указано предложение GROUP BY.
GROUPING ( <column_expression> ) |
| MAX() | Возвращает максимальное значение в выражении. Возвращает такое же значение, как и expression.
MAX ( [ ALL | DISTINCT ] expression ) |
| MIN() | Возвращает минимальное значение выражения. Возвращает такое же значение, как и expression.
MIN ( [ ALL | DISTINCT ] expression ) |
| SUM() | Возвращает сумму всех (либо только уникальных) значений в выражении. Функция SUM может быть использована только для числовых колонок. Сумма всех значений выражения expression представлена в наиболее точном формате данных, используемом в выражении expression.
SUM ( [ ALL | DISTINCT ] expression ) |
| STDEV() | Возвращает статистическое стандартное отклонение всех значений в указанном выражении. Возвращаемый тип - float.
STDEV ( [ ALL | DISTINCT ] expression ) |
| STDEVP() | Возвращает статистическое среднеквадратичное отклонение совокупности всех значений в указанном выражении. Возвращаемый тип - float.
STDEVP ( [ ALL | DISTINCT ] expression ) |
| VAR() | Возвращает статистическую дисперсию всех значений в указанном выражении. Возвращаемый тип - float.
VAR ( [ ALL | DISTINCT ] expression ) |
| VARP() | Возвращает статистическую дисперсию для заполнения всех значений в указанном выражении. Возвращаемый тип - float.
VARP ( [ ALL | DISTINCT ] expression ) |
Указание ALL применяет функцию ко всем значениям. ALL является аргументом по умолчанию, а DISTINCT указывает, что рассматривается каждое уникальное значение.
Рассмотрим пример, в котором применяются встроенные агрегатные функции для вычисления основных статистических параметров.
Пример 23.1. Агрегатные и статистические функции
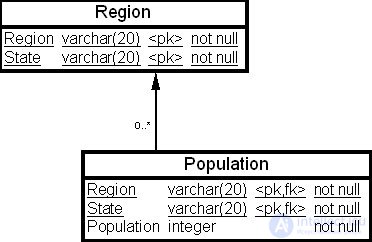
Пусть в ХД имеется таблица фактов "Население" ( Population ), содержание которой приведено в табл. 23.3, и таблица измерений "Район" ( Region ), физическая структура которых приведена на рис. 23.1.
Оператор SELECT, приведенный ниже, иллюстрирует применение агрегатных и статистических функций.
SELECT Region. MIN(Population) AS Minimum, MAX(Populations)AS Maximum, AVG(Population) AS Average. VAR(Population) AS Variance FROM Region GROUP BY Region ORDER BY Maximum DESC
| Region | State | Population |
|---|---|---|
| Восточный округ | МО | 31878234 |
| Южный округ | МА | 19128261 |
| Северный округ | КФ | 18184774 |
| Южный округ | СР | 14399985 |
| Северный округ | ПК | 7987933 |
| Западный округ | ВО | 7322870 |
| Восточный округ | КП | 5337939 |
| Центральный округ | ТЛ | 5358592 |
| Западный округ | ЧЕ | 5071604 |
| Центральный округ | ФС | 3300902 |
Результат выполнения запроса приведен ниже.
Вывод 1.
| Region | Minimum | Maximum | Average | Variance |
|---|---|---|---|---|
| Восточный округ | 5532939 | 31878234 | 18705586 | 347037284318512.5 |
| Южный округ | 14399985 | 19128261 | 16764123 | 11118296966088.0 |
| Северный округ | 7987933 | 18184774 | 13086353 | 51987783189640.5 |
| Западный округ | 5071604 | 7322870 | 6197237 | 25340993C1378.0 |
| Центральный округ | 3300902 | 5358692 | 4329797 | 2117249842050.0 |
Пример 23.2. Использование GROUPING
Предположим, что нам необходимо произвести статистическую обработку значений колонки "Объем продаж" (Sale), сгруппированных по колонке "Квота" (Quota) в таблице "Продажи" (Sales), структура которой показана на рис. 23.2. Функция GROUPING применяется к колонке Quota.

Следующий запрос решает поставленную задачу:
SELECT Quota, SUM(Sale) 'TotalSales', GROUPING(Quota) AS 'Grouping' FROM Sales GROUP BY Quota WITH ROLLUP; GO
В результирующем наборе показаны два значения NULL в колонке Quota. Первое значение NULL представляет группу значений NULL из этого столбца в таблице. Второе значение NULL находится в строке итогов, добавленной операцией ROLLUP. Строка итогов показывает суммы TotalSales для всех групп Quota и обозначается 1 в столбце Grouping.
Результат выполнения запроса приведен ниже.
Вывод 2.
| Quota | TotalSales | Grouping |
|---|---|---|
| NULL | 1533087.5999 | 0 |
| 250000.00 | 33461260.59 | 0 |
| 300000.00 | 9299677.9445 | 0 |
| NULL | 44294026.1344 | 1 |
В прикладной статистике используется много статистических функций. В следующем разделе мы покажем, как вычислять некоторые из них средствами языка SQL.
Задачи позиционирования записей или задачи нахождения записей на основании их физического расположения в выборке исторически были сложными для решения средствами SQL. Найти запись по значению в языках, ориентированных на работу с множествами, довольно просто; найти же запись по позиции является сложной задачей.
Задача нахождения медиан представляет собой задачу позиционирования записей. Если в выборке нечетное количество записей, значение медианы равно значению записи, расположенной точно в середине выборки. Выше и ниже этого значения существует одинаковое количество элементов. Если в выборке четное количество значений, значение медианы равно либо среднему двух центральных значений (в случае финансовых медиан), либо меньшему из них (в случае статистических медиан).
Задача позиционирования записей значительно упрощается, когда в таблице есть уникальный последовательный целый ключ (identity-колонка). Если это так, ключ становится виртуальным номером записи, и имеется возможность обращаться к записям в любой позиции таблицы как к массиву. За счет этого мы можем вычислять медианы практически мгновенно даже для выборок, состоящих из миллионов значений.
Пример. 16.3. Вычисление медианы.
Пусть в ХД имеется таблица фактов "Финансы" (Finance), содержащая несколько миллионов значений цен на товары. Физическая структура таблицы приведена на рис. 23.3. Колонка ID создана с квалификатором типа identity. Записи отсортированы по значению колонки "Цена" (Price) за счет создания кластеризованного индекса, для чего была добавлена колонка ID, т.е. записи были просто перенумерованы. Индекс на колонку "Цена" (Price) был удален, а на колонку ID — создан.

Следующий запрос вычисляет финансовую медиану:
SELECT AVG(Price) AS "Финансовая медиана" FROM finance
WHERE ID BETWEEN MAX(ID) / 2 AND (MAX(ID) / 2) + SIGN(MAX{(ID) +1 % 2)
Функция SIGN() используется для того, чтобы сделать обработку четного и нечетного числа записей в одном предложении BETWEEN. Выражение с этой функцией добавляет к количеству записей в выборке 1, чтобы изменить его с четного на нечетное или наоборот, затем вычисляет остаток от деления на число 2, чтобы понять, четное или нечетное число, и возвращает 1 или 0 в зависимости от знака.
Оконные функции определены в стандарте ISO SQL. Об этом говорит сайт https://intellect.icu . В СУБД семейства MS SQL Server предоставляются ранжирующие и статистические оконные функции. Окно — это набор строк, определяемый пользователем. Оконная функция вычисляет значение для каждой строки в результирующем наборе, полученном из окна.
Оконные функции могут использоваться для вычисления кумулятивных, скользящих и центрированных агрегатов. Они возвращают значение для каждой строки в таблице, которое зависит от других строк соответствующего окна. Они могут быть использованы только в предложениях SELECT и ORDER BY запроса. Как правило, оконные функции обеспечивают доступ к более чем одной строке таблицы без самосоединения.
Предложение OVER определяет секционирование и упорядочение набора строк до применения соответствующей оконной функции. В качестве оконных функций используются агрегатные и статистические ( SUM, AVG, MAX, MIN, COUNT ), ранжирующие функции. Каждая из ранжирующих функций ROW_NUMBER, DENSE_RANK, RANK и NTILE задействует предложение OVER (см. сл. раздел настоящей лекции).
Синтаксис:
< OVER_CLAUSE > ::= OVER ( [PARTITION BY value_expression, … [n] ] <ORDER BY expression>)
< OVER_CLAUSE > ::= OVER ( [PARTITION BY value_expression, … [n] ]
PARTITION BY разделяет результирующий набор на секции. Оконная функция применяется к каждой секции отдельно, и вычисление начинается заново для каждой секции. Если это предложение опущено, функция интерпретирует все результирующее множество как одну группу.
value_expression указывает столбец, по которому секционируется набор строк, произведенный соответствующим предложением FROM. Аргумент value_expression может ссылаться только на столбцы, доступные через предложение FROM. Аргумент value_expression не может ссылаться на выражения или псевдонимы в списке выбора. Выражение value_expression может быть выражением столбца, скалярным вложенным запросом, скалярной функцией или пользовательской переменной.
Предложение ORDER BY задает порядок для ранжирующей оконной функции. Если предложение ORDER BY используется в контексте ранжирующей оконной функции, оно может ссылаться только на столбцы, доступные через предложение FROM. Указывать положение имени или псевдонима столбца в списке выборки с помощью целого числа нельзя. Предложение ORDER BY не может работать со статистическими оконными функциями.
В одном запросе с одним предложением FROM может использоваться несколько статистических или ранжирующих оконных функций. Однако предложение OVER для каждой функции может применять свое секционирование и упорядочение. Предложение OVER не может работать со статистической функцией CHECKSUM.
Семантика NULL-значений оконных функций соответствует семантике NULL-значений агрегатных функций SQL.
Покажем на примере, как используются статистические оконные функции.
Пример. 16.4. Статистические оконные функции.
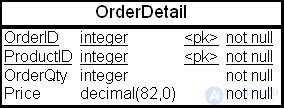
Пусть в ХД имеется таблица фактов "Позиции счетов" (OrderDetail), содержащая номер позиции (OrderID), идентификатор товара (ProductID), количество товара (OrderQt) и стоимость товара (Price). Физическая структура таблицы приведена на рис. 23.4.
Пусть необходимо для двух позиций счетов 43659 и 43664 посчитать для каждого проданного товара общее количество проданного товара, среднее количество каждого проданного товара, минимальное и максимальное количество проданного товара.
Следующий запрос решает поставленную задачу с использованием оконных функций.
SELECT OrderID, ProductID, OrderQty ,SUM(OrderQty) OVER(PARTITION BY OrderID) AS 'Итого' ,AVG(OrderQty) OVER(PARTITION BY OrderID) AS 'Среднее' ,COUNT(OrderQty) OVER(PARTITION BY OrderID) AS 'Кол-во' ,MIN(OrderQty) OVER(PARTITION BY OrderID) AS 'Min' ,MAX(OrderQty) OVER(PARTITION BY OrderID) AS 'Max' FROM OrderDetail WHERE OrderID IN(43659,43664); GO
Результат выполнения запроса приведен ниже.
Вывод 3.
| OrderID | ProductID | OrderQty | Итого | Среднее | Кол-во | Min | Max |
|---|---|---|---|---|---|---|---|
| 43659 | 776 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 777 | 3 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 778 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 771 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43659 | 772 | 1 | 26 | 2 | 12 | 1 | 6 |
| 43664 | 772 | 1 | 14 | 1 | 8 | 1 | 4 |
| 43664 | 775 | 4 | 14 | 1 | 8 | 1 | 4 |
| 43664 | 714 | 1 | 14 | 1 | 8 | 1 | 4 |
Пусть руководство организации требует подсчитать процент проданного товара по позиции 43659. Следующий запрос с использованием оконных функций решает поставленную задачу.
SELECT OrderID, ProductID, OrderQty ,SUM(OrderQty) OVER(PARTITION BY OrderID) AS 'Итого' ,CAST(1. * OrderQty / SUM(OrderQty) OVER(PARTITION BY OrderID) *100 AS DECIMAL(5,2))AS 'Процент проданного товара' FROM OrderDetail WHERE OrderID = 43659;
Результат выполнения запроса приведен ниже.
Вывод 4.
| OrderID | ProductID | OrderQty | Итого | Процент проданного товара |
|---|---|---|---|---|
| 43659 | 776 | 1 | 26 | 3.85 |
| 43659 | 777 | 3 | 26 | 11.54 |
| 43659 | 778 | 1 | 26 | 3.85 |
| 43659 | 771 | 1 | 26 | 3.85 |
| 43659 | 772 | 1 | 26 | 3.85 |
Как видно из рассмотренных примеров, использование предложения OVER является более эффективным, чем использование вложенных запросов. Применение оконных ранжирующих функций будет рассмотрено в следующем разделе.
Функции ранжирования вычисляют ранг записи по отношению к другим записям в наборе данных, основываясь на значении набора метрик (measures). Они возвращают ранжирующее значение для каждой строки в секции. В зависимости от используемой функции значения некоторых строк могут совпадать.
Типы ранжирующих функций приведены в табл. 23.4.
| Функция | Возвращаемое значение |
|---|---|
| RANK | Возвращает ранг каждой строки в секции результирующего набора. Ранг строки вычисляется как единица плюс количество рангов, находящихся до этой строки. Возвращаемый тип данных — bigint |
| DENSE_RANK | Возвращает ранг строк в секции результирующего набора без промежутков в ранжировании. Ранг строки равен количеству различных значений рангов, которые предшествуют строке, увеличенному на единицу. Возвращаемый тип данных — bigint |
| NTILE | Распределяет строки упорядоченной секции в заданное количество групп. Группы нумеруются, начиная с единицы. Для каждой строки функция NTILE возвращает номер группы, которой принадлежит строка |
| ROW_NUMBER | Возвращает последовательный номер строки в секции результирующего набора, 1 соответствует первой строке в каждой из секций. Возвращаемый тип данных — bigint |
Функции RANK и DENSE_RANK позволяют ранжировать итемы в группе, например, найти top 3 товаров, продаваемых в Калифорнии в последний год. Существуют две функции ранжирования с синтаксисом:
RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )
< partition_by_clause > ([PARTITION BY <value expression1> [, ...]]) делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым применяется функция RANK.
< order_by_clause > ( ORDER BY <value expression2> [collate clause] [ASC|DESC] ) определяет порядок, в котором значения RANK применяются к строкам в секции. Целое значение не может представлять столбец < order_by_clause > при использовании его в ранжирующей функции.
Если две и более строки претендуют на один ранг, то все они получат одинаковый ранг. Например, если двум лучшим продавцам соответствует одинаковое значение объема продаж, им обоим присваивается ранг 1. Менеджер по продажам со следующим по величине значением объема продаж получит ранг номер 3, так как перед ним находятся две строки с более высоким рангом. Поэтому функция RANK не всегда возвращает последовательные целые числа.
Порядок сортировки, используемый для всего запроса, определяет порядок, в котором строки будут появляться в результирующем наборе.
DENSE_RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )
< partition_by_clause > делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым применяется функция DENSE_RANK.
< order_by_clause > определяет порядок, в котором значения DENSE_RANK применяются к строкам секции. Целое число не может представлять столбец в <order_by_clause>, который используется в ранжирующей функции.
Если две или более строки одной секции равны при ранжировании, каждой такой строке присваивается один и тот же ранг. Например, если двум лучшим продавцам соответствует одинаковое значение объема продаж, им обоим присваивается ранг 1. Менеджеру по продажам со следующим по величине значением объема продаж назначается ранг 2. Это на единицу больше, чем число разных рангов строк, расположенных перед этой строкой. Таким образом, между номерами, возвращаемыми функцией DENSE_RANK, нет промежутков, и они всегда имеют последовательные значения ранга.
Порядок сортировки строк в результате определяется порядком сортировки результата всего запроса. Из этого следует, что строка с рангом 1 не всегда является первой строкой в секции.
Таким образом, различие между RANK и DENSE_RANK состоит в том, что DENSE_RANK не оставляет промежутков в ранжируемой последовательности.
Функцию RANK рекомендуется применять в случаях, если:
Рассмотрим ряд примеров применения ранжирующих функций.
Можно выполнять ранжирование по нескольким выражениям. Функции ранжирования необходимы для нахождения связи между значениями на множестве записей. Если первое выражение не может выявить связь, то второе используется для выявления связи и т.д.
Пример 23.5. Использование функции RANK().
Путь нужно ранжировать товар, основываясь на продажах в рублях в каждом регионе, разрывая связь с доходом. Физическая схема киоска данных приведена на рис. 23.5.
На схеме представлены таблица фактов "Продажи" (sale) с метриками "Количество" (s_amount) и "Прибыль" (s_profit); две таблицы измерений "Регион" (region) и "Товар" (product).
Следующий запрос решает поставленную задачу:
SELECT r_regionkey, p_productkey, s_amount, s_profit, RANK() OVER (ORDER BY s_amount DESC, s_profit DESC) AS 'Ранг по востоку' FROM region, product, sales WHERE region.r_regionkey = sales.s_regionkey AND product.p_productkey = sales.s_productkey AND r_regionkey = 'Восток';

Результат выполнения запроса приведен ниже.
Вывод 5.
| R_REGIONKEY | S_PRODUCTKEY | S_AMOUNT | S_PROFIT | Ранг по востоку |
|---|---|---|---|---|
| Восток | Ботинки | 130 | 30 | 1 |
| Восток | Жакеты | 100 | 28 | 2 |
| Восток | Брюки | 100 | 24 | 3 |
| Восток | Свитеры | 75 | 24 | 4 |
| Восток | Рубашки | 75 | 24 | 4 |
| Восток | Ремни | 60 | 12 | 6 |
| Восток | Футболки | 20 | 10 | 7 |
Для жакетов и брюк колонка "Доход" (s_profit) показывает связь с колонкой "Количество" (s_amount). Но для свитеров и рубашек колонка "Доход" не может установить связь с колонкой "Количество". Следовательно, им присвоен один и тот же ранг.
Различие между RANK() и DENSE_RANK() может быть показано с помощью запроса к таблице фактов "Продажи":
SELECT р_productkey, SUM(s_amount) as 'Суммарное количество', RANK() OVER (ORDER BY SUM(s_amount) DESC) AS 'rank_all', DENSE_RANK() OVER (ORDER BY SUM(s_amount) DESC) AS 'rank_dense' FROM sales GROUP BY р_productkey;
Результат выполнения запроса приведен ниже.
Вывод 6.
| S_PRODUCTKEY | Суммарное количество | rank_all | rank_dense |
|---|---|---|---|
| Ботинки | 100 | 1 | 1 |
| Жакеты | 100 | 1 | 1 |
| Брюки | 89 | 3 | 2 |
| Свитеры | 75 | 4 | 3 |
| Рубашки | 75 | 4 | 3 |
| Ремни | 66 | 6 | 4 |
| Футболки | 66 | 6 | 4 |
Как видно по результирующему множеству, в случае функции DENSE_RANK() наибольшее значение ранга равно числу различных значение в наборе данных.
Функция RANK() может быть применена для операции в группах, т.е. ранг переустанавливается при изменении группы данных. Это важно для опции PARTITION BY. Группирующее выражение в PARTITION BY выделяет подклассы данных в наборе данных, с которыми работает RANK.
Пример 23.6. Необходимо ранжировать товары в каждом регионе по их продаже в рублях. Можно написать запрос для схемы на рис. 23.5, который ранжирует товары на основе их продаж в рублях в каждом регионе ( rank_of_product_per_region ) и во всех регионах ( rank_of_product_total ).
SELECT r_regionkey, p_productkey, SUM(s_amount) AS 'SUM_S_AMOUNT', RANK() OVER (PARTITION BY r_regionkey ORDER BY SUM(s_amount) DESC) AS 'rank_of_product_per_region', RANK() OVER (ORDER BY SUM(s_amount) DESC) AS 'rank_of_product_total' FROM product, region, sales WHERE region.r_regionkey = sales.r_regionkey AND product.p_productkey = sales.p_productkey GROUP BY r_regionkey, p_productkey ORDER BY r_regionkey;
Результат выполнения запроса приведен ниже.
Вывод 7.
| R_REGIONKEY | P_PRODUCTKEY | SUM_S_AMOUNT | RANK_OF_PRODUCT_PER_REGION | RANK_OF_PRODUCT_TOTAL |
|---|---|---|---|---|
| Восток | Ботинки | 130 | 1 | 1 |
| Восток | Жакеты | 95 | 2 | 4 |
| Восток | Рубашки | 80 | 3 | 6 |
| Восток | Свитеры | 75 | 4 | 7 |
| Восток | Футболки | 60 | 5 | 11 |
| Восток | Ремни | 50 | 6 | 12 |
| Восток | Брюки | 20 | 7 | 14 |
| Запад | Ботинки | 100 | 1 | 2 |
| Запад | Жакеты | 99 | 2 | 3 |
| Запад | Футболки | 89 | 3 | 5 |
| Запад | Свитеры | 75 | 4 | 7 |
| Запад | Рубашки | 75 | 4 | 7 |
| Запад | Ремни | 66 | 6 | 10 |
| Запад | Брюки | 45 | 7 | 13 |
Функция NTILE() делит упорядоченную секцию на указанное число групп, называемых бакетами ( buckets ), и назначает номер бакета каждой строке в секции. Для каждой строки функция NTILE() возвращает номер группы, которой принадлежит строка. NTILE() — очень полезная функция, поскольку дает возможность разделить набор данных на 40, 30 или другое число групп.
Бакеты вычисляются так, чтобы каждый из них имел одинаковое число строк, назначенное ему, или на одну больше. Например, если есть 100 строк в секции и находится функция NTILE для 4 бакетов, то 25 строк будет назначаться каждому бакету.
Если число строк в секции не делится нацело (на число бакетов), то число строк, назначаемое каждому бакету в начале, будет отличаться по крайней мере на 1. Например, если есть 103 строки в секции, к которой применяется функция NTILE(5), первые 21 строк будут назначены 1 бакету, следующие 21 — 2 бакету, следующие 21 — 3 бакету, следующие 20 — 4 бакету и последние 20 — 5 бакету.
Синтаксис:
NTILE (integer_expression) OVER ( [ <partition_by_clause> ] < order_by_clause > )
integer_expression - положительное целое выражение-константа, указывающее количество групп, на которые необходимо разделить каждую секцию. Аргумент integer_expression может иметь тип int или bigint.
<partition_by_clause> делит результирующий набор, сформированный предложением FROM.
< order_by_clause > определяет порядок назначения значений функции NTILE строкам секции.
Аргумент integer_expression может ссылаться только на столбцы в предложении PARTITION BY и не может ссылаться на столбцы, перечисленные в текущем предложении FROM.
Пример 23.7. Использование функции NTILE()
Пусть нам нужно провести группировку проданных товаров по объему продаж, используя схему на рис. 23.5. Это можно сделать с помощью следующего запроса:
SELECT p_productkey, s_amount, NTILE(4) (ORDER BY s_amount DESC AS '4_tile' FROM product, sales WHERE product.p_productkey = sales.p_productkey;
Результат выполнения запроса приведен ниже.
Вывод 8.
| P_PRODUCTKEY | S_AMOUNT | 4_TILE |
|---|---|---|
| Костюмы | 110 | 1 |
| Ботинки | 100 | 1 |
| Жакеты | 90 | 1 |
| Рубашки | 89 | 2 |
| Футболки | 84 | 2 |
| Свитеры | 75 | 2 |
| Джинсы | 75 | 3 |
| Ремни | 75 | 3 |
| Брюки | 69 | 3 |
| Ленты | 56 | 4 |
| Носки | 45 | 4 |
NTILE() является недетерминистической функцией. Равные значения могут распределяться различным бакетам (75 назначено бакетам 2 и 3); бакеты '1', '2' и '3' имеют по 3 элемента — на один больше, чем бакет '4'. В результирующем множестве "джинсы" можно было бы назначить бакету 2 (вместо 3) и "свитеры" — бакету 3 (вместо 2), потому что не существует упорядочивания по колонке p_productkey. Для того чтобы быть уверенным в детерминистическом результате, вы должны упорядочить результирующее множество по уникальному ключу.
Функция ROW_NUMBER() назначает уникальный номер (последовательно, начиная с 1, в порядке, определенном ORDER BY ) каждой строке в секции.
Синтаксис:
ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> )
<partition_by_clause> делит результирующий набор, полученный по предложению FROM.
<order_by_clause> определяет порядок, в котором значение функции ROW_NUMBER назначается строкам в секции. Целое число не может представлять столбец, если аргумент <order_by_clause> используется в ранжирующей функции.
Предложение ORDER BY определяет последовательность, в которой строкам назначаются уникальные номера с помощью функции ROW_NUMBER в пределах указанной секции.
Пример 23.8. Использование функции ROW_NUMBER ()
Пусть нам нужно провести группировку проданных товаров по объему продаж, используя схему на рис. 23.5. Это можно сделать с помощью следующего запроса:
SELECT p_productkey, s_amount,
ROW_NUMBER() (ORDER BY s_amount DESC) AS srnum
FROM product, sales
WHERE product.p_productkey = sales.p_productkey;
Результат выполнения запроса приведен ниже.
Вывод 8.
| P_PRODUCTKEY | S_AMOUNT | SRNUM |
|---|---|---|
| Ботинки | 100 | 1 |
| Жакеты | 90 | 2 |
| Рубашки | 89 | 3 |
| Футболки | 84 | 4 |
| Свитеры | 75 | 5 |
| Джинсы | 75 | 6 |
| Ремни | 75 | 7 |
| Брюки | 69 | 8 |
| Ленты | 56 | 9 |
| Носки | 45 | 10 |
| Костюмы | NULL | 11 |
Свитерам, джинсам и ремням (с s_amount = 75) назначаются различные номера строк (5, 6, 7).
Подобно функции NTILE(), функция ROW_NUMBER() является недетерминистической функцией, так что "свитеры" мог бы получить номер строки 7 (вместо 5), а "ремни" — 5 (вместо 7). Чтобы избежать подобных ситуаций, необходимо сортировать результирующее множество по уникальному ключу.
После того как запрос выполнен, значения агрегатов (типа количество строк в результирующем множестве или среднее значение в колонке) могут быть вычислены для секции и быть доступными для других отчетов. Агрегатные функции генерирования отчетов (Reporting aggregate functions) возвращают значения агрегатов для каждой строки в секции. К агрегатным функциям генерирования отчетов относятся функции SUM(), AVG(), MAX(), MIN(), COUNT(), использующее предложение OVER. Их поведение относительно NULL-значений такое же, как и в агрегатных функциях SQL.
В предыдущих разделах настоящей лекции мы уже обсуждали такое применение агрегатных функций. Поэтому в настоящем разделе приведем только несколько примеров.
Функции генерирования отчетов допустимы только для предложений SELECT. Основное их назначение состоит в способности выполнять многократный разбор блока данных результирующего множества запроса. Запросы типа "Подсчитать число продавцов, у которых уровень продаж больше на 10% от числа продаж по городу" не требуют соединений между отдельными блоками запроса.
Пример 23.9. Использование агрегатных функций для генерирования отчетов
Пусть нам нужно для каждого товара найти регион, в котором наблюдается максимальный уровень продаж каждого товара, используя схему на рис. 23.5. Это можно сделать с помощью следующего запроса:
SELECT s_productkey, s_regionkey, sum_s_amount
FROM
(SELECT p_productkey, r_regionkey, SUM(s_amount) AS 'sum_s_amount',
MAX(SUM(s_amount)) OVER
(PARTITION BY p_productkey) AS 'max_sum_s_amount'
FROM sales
GROUP BY p_productkey, r_regionkey)
WHERE sum_s_amount = max_sum_s_amount;
Данные внутреннего запроса к таблице фактов "Продажи" (sales), сгруппированные по колонкам p_productkey и p_regionkey, агрегируются для первых трех колонок, и функция MAX(SUM(s_amount)) возвращает результат.
Вывод 9.
| P_PRODUCTKEY | S_REGIONKEY | SUM_S_AMOUNT | MAX_SUM_S_AMOUNT |
|---|---|---|---|
| Жакеты | Запад | 99 | 99 |
| Жакеты | Восток | 50 | 99 |
| Брюки | Восток | 20 | 45 |
| Брюки | Запад | 45 | 45 |
| Рубашки | Восток | 60 | 80 |
| Рубашки | Запад | 80 | 80 |
| Ботинки | Запад | 100 | 130 |
| Ботинки | Восток | 130 | 130 |
| Свитеры | Запад | 75 | 75 |
| Свитеры | Восток | 75 | 75 |
| Носки | Восток | 95 | 95 |
| Носки | Запад | 66 | 95 |
Результат выполнения внешнего запроса приведен ниже.
Вывод 10.
| P_PRODUCTKEY | S_REGIONKEY | SUM_S_AMOUNT |
|---|---|---|
| Жакеты | Запад | 99 |
| Брюки | Запад | 45 |
| Рубашки | Запад | 80 |
| Ботинки | Восток | 130 |
| Свитеры | Запад | 75 |
| Свитеры | Восток | 75 |
| Носки | Восток | 95 |
Пример 23.10. Использование агрегирующих и ранжирующих функций для генерации отчета.
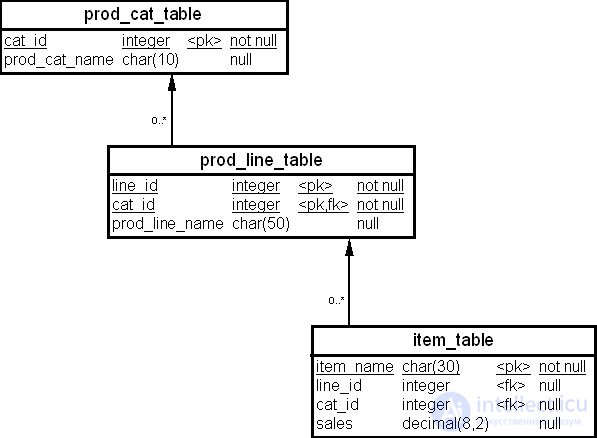
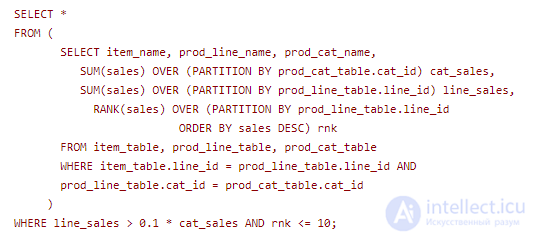
Более сложным является пример вычисления первых 10-ти (top 10) продаж той линейки товаров, которая имеет вклад более 10% в продажи товаров этой категории. Физическая схема для таблиц, используемых для решения этой задачи, приведена на рис. 23.6. Первая колонка является ключом для всех таблиц запроса.
Синтаксис предложения CASE и некоторые его применения были рассмотрены в "Проектирование и разработка процесса ETL" . С помощью предложения CASE можно легко найти среднюю зарплату всех сотрудников организации (если зарплата меньше 2000 руб., то она принимается равной 2000 руб.), как показано в запросе ниже:
SELECT AVG(CASE when e.sal > 2000 THEN e.sal ELSE 2000 end) FROM emps e;
Таблица "Сотрудники" (emps) включает в себя колонки "Табельный номер" (empid), "ФИО" (name), "Должность" (job) и "Зарплата" (sal), как показано на рис. 23.7.

Предложение CASE можно использовать при построении диаграмм для определенных пользователем бакетов (и по числу бакетов и по ширине каждого бакета). В первом примере ниже строится гистограмма итоговых сумм (totals) в нескольких колонках и выводится одной строкой. Во втором примере гистограмма показывается с колонкой метки, одной колонкой для итоговой суммы (totals) и выводится с помощью нескольких строк.
Пример 23.11. Построение гистограммы.
Пусть необходимо построить гистограмму распределения покупателей по возрастным группам для людей преклонного возраста. Возрастные группы определяются следующими условиями: 70-79, 80-89, 90-99, 100+.
Следующий запрос решает поставленную задачу (предполагается, что таблица "Покупатели" (customer) содержит колонку "Возраст" (age)):
SELECT SUM(CASE WHEN age BETWEEN 70 AND 79 THEN 1 ELSE 0 END) as "70-79", SUM(CASE WHEN age BETWEEN 80 AND 89 THEN 1 ELSE 0 END) as "80-89", SUM(CASE WHEN age BETWEEN 90 AND 99 THEN 1 ELSE 0 END) as "90-99", SUM(CASE WHEN age > 99 THEN 1 ELSE 0 END) as "100+" FROM customer;
Результат выполнения внешнего запроса приведен ниже.
Вывод 11.
| 70-79 | 80-89 | 90-99 | 100+ |
|---|---|---|---|
| 4 | 2 | 3 | 1 |
Следующий запрос решает ту же задачу, но выводит гистограмму в виде "столбика".
Пример 23.12.
SELECT CASE WHEN age BETWEEN 70 AND 79 THEN '70-79' WHEN age BETWEEN 80 and 89 THEN '80-89' WHEN age BETWEEN 90 and 99 THEN '90-99' WHEN age > 99 THEN '100+' END) as age_group, COUNT(*) as age_count FROM customer GROUP BY CASE WHEN age BETWEEN 70 AND 79 THEN '70-79' WHEN age BETWEEN 80 and 89 THEN '80-89' WHEN age BETWEEN 90 and 99 THEN '90-99' WHEN age > 99 THEN '100+' END);
Результат выполнения внешнего запроса приведен ниже.
Вывод 12.
| age_group | age_count |
|---|---|
| 70-79 | 4 |
| 80-89 | 2 |
| 90-99 | 3 |
| 100+ | 1 |
В заключение нужно отметить, что некоторые СУБД имеют в своих диалектах SQL боле широкий набор статистических функций, оконных функций, функций ранжирования и функций генерирования отчетов. Например, в СУБД Oracle 11g имеется набор функций для построения линейной регрессии.
Приведем в качестве примера краткий обзор функций построения линейной регрессии для СУБД семейства Oracle.
Функции регрессий устанавливают соответствие по обычному методу наименьших квадратов (ordinary-least-squares) — линию регрессии для набора пар чисел. Данные функции применяются к набору пар of (e1, e2) после проверки всех пар на равенство нулевому значению (либо e1, либо e2)l. e1 — значение зависимой переменной ("y-значение"), а e2 — значение независимой переменной ("x-значение"). Оба выражения должны быть числовыми. Функции регрессии вычисляются за один проход по всем данным.
Перечень функций линейной регрессии дан в табл. 23.5.
| Функция | Действие |
|---|---|
| REGR_COUNT | Функция REGR_COUNT возвращает количество ненулевых пар, которые участвуют в построении линии регрессии. Если все пары (e1, e2) нулевые (либо e1, либо e2 равны нулю), функция возвращает 0 |
| REGR_AVGX REGR_AVGY | Функции REGR_AVGY и REGR_AVGX вычисляют среднее значение (averages) независимой и зависимой переменных линии регрессии соответственно. Функция REGR_AVGY вычисляет среднее первого аргумента (e1) после проверки пар (e1, e2) на нулевое значение (см. выше). Аналогично, функция REGR_AVGX вычисляет среднее для второго аргумента (e2). Обе функции возвращают нуль, если на входе задано пустое множество |
| REGR_SLOPE | Функция REGR_SLOPE вычисляет тангенс угла наклона линии регрессии, соответствующей ненулевым парам (e1, e2) |
| REGR_INTERCEPT | Функция REGR_INTERCEPT вычисляет отсечение на оси Y. Возвращает NULL, если тангенс угла наклона или среднее значение равны NULL |
| REGR_R2 | Функция REGR_R2 вычисляет коэффициент детерминации для линии регрессии (после проверки пар (e1, e2) на нуль) |
| REGR_SXX | Функция REGR_R2 возвращает значения из интервала [0, 1], если регрессия определена, или NULL — в противном случае |
| REGR_SYY REGR_SXY | Функции REGR_SXX, REGR_SYY и REGR_SXY используются для вычисления различных диагностических статистик регрессионного анализа |
Пример 23.13. Вычисления линейной регрессии.
В примере вычисляется регрессия по методу наименьших квадратов, которая показывает премиальные сотрудников как линейную функцию их зарплаты. Величины SLOPE, ICPT, RSQR — наклон, пересечение и коэффициент детерминации регрессии, соответственно. Значения AVGSAL и AVGBONUS есть средняя зарплата и средний размер премий сотрудников, соответственно, а целочисленная величина CNT есть число сотрудников в отделе, для которого вычисления проводятся.
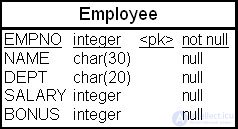
Пусть имеется таблица "Сотрудники" (Employee) с колонками "Табельный номер" (EMPNO), "ФИО" (NAME), "Отдел" (DEPT), "Зарплата" (SALARY), "Премии" (BONUS) ( рис. 23.8). Таблица содержит восемь сотрудников (табл. 23.6).
| Табельный номер | ФИО | Отдел | Заплата | Премия |
|---|---|---|---|---|
| 45 | Петров | Продажи | 4500 | 500 |
| 52 | Иванов | Продажи | 4300 | 450 |
| 41 | Ивлев | Продажи | 5600 | 800 |
| 65 | Кузнецова | Продажи | 3200 | |
| 36 | Александров | Оборудование | 6700 | 1150 |
| 58 | Самгин | Оборудование | 3000 | 350 |
| 25 | Ворошилов | Оборудование | 8200 | 1860 |
| 54 | Васильев | Оборудование | 6000 | 900 |
Следующий запрос вычисляет параметры линейной регрессии.
SELECT REGR_SLOPE(BONUS, SALARY) SLOPE,
REGR_INTERCEPT(BONUS, SALARY) ICPT,
REGR_R2(BONUS, SALARY) RSQR,
REGR_COUNT(BONUS, SALARY) COUNT,
REGR_AVGX(BONUS, SALARY) AVGSAL,
REGR_AVGY(BONUS, SALARY) AVGBONUS,
REGR_SXX(BONUS, SALARY) SXX,
REGR_SXY(BONUS, SALARY) SXY,
REGR_SYY(BONUS, SALARY) SXY
FROM employee
GROUP BY dept;
Результаты выполнения запроса приведены ниже.
Вывод 13.
| SLOPE | ICPT | RSQR | CNT | AVGSAL | AVGBONUS |
|---|---|---|---|---|---|
| 2759379 | -583.729 | 9263144 | 4 | 5975 | 1065 |
| 2704082 | -714.626 | 9998813 | 3 | 4800 | 583.33333 |
В настоящей лекции мы изучили ряд функций SQL, используемых при аналитической обработке данных в ХД и киосках данных. Это статистические функции, ранжирующие функции и оконные функции.
Статистические функции выполняют вычисление на наборе значений и возвращают одиночное значение. Они, за исключением функции COUNT, не учитывают значения NULL. Также они часто используются в выражении GROUP BY команды SELECT.
Функции ранжирования вычисляют ранг записи по отношению к другим записям в наборе данных, основываясь на значении набора метрик таблиц фактов ХД. Они возвращают ранжирующее значение для каждой строки в секции. В зависимости от используемой функции значения некоторых строк могут совпадать.
Оконные функции могут использоваться для вычисления кумулятивных, скользящих и центрированных агрегатов. Они возвращают значение для каждой строки в таблице, которое зависит от других строк соответствующего окна. Они могут быть использованы только в предложениях SELECT и ORDER BY запроса. Как правило, оконные функции обеспечивают доступ более чем к одной строке таблицы без самосоединения.
Был также рассмотрен ряд примеров применения вышеперечисленных функций для генерирования отчетных данных, а в сочетании с CASE-выражением — для построения гистограмм.
Проектировщику ХД очень полезно знать возможности аналитической обработки данных в SQL для более качественного проектирования схем данных ХД и определения гранулированности таблиц фактов.
Исследование, описанное в статье про аналитическая обработка данных, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое аналитическая обработка данных, аналитическая обработка данных в хранилищах данных, аналитические функции, статистические функции, функции ранжирования, оконные функции, функции для генерирования отчетов и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL

Комментарии