Лекция
Привет, Вы узнаете о том , что такое big data, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое big data, hive , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
В этой статье мы продолжим рассматривать возможности hive — движка, транслирующего SQL-like запросы в MapReduce задачи.
В предыдущей статье мы рассмотрели базовые возможности hive, такие как создание таблиц, загрузка данных, выполнение простых SELECT-запросов. Теперь поговорим о продвинутых возможностях, которые позволят выжимать максимум из Hive.
Одним из основных препятствий при работе с Hive является скованность рамками стандартного SQL. Эту проблему можно решить при помощи использования расширений языка — так называемых «User Defined Functions». Довольно много полезных функций встоено прямо в язык Hive. Приведу несколько самых интересных на мой взгляд(информация взята из оффициальной документации):
Json
Довольно частой задачей при работе с большими данынми является обработка неструктурированных данных, хранящихся в формате json. Для работы с json hive поддерживать специальный метод get_json_object, позволяющий извлекать значения из json-документов. Для извлечения значений из объекта используется ограниченная версия нотации JSONPath. Поддерживаются следующие операции:
Примеры работы с Json из оффициальной документаци:
Пусть есть таблица: src_json, состоящаяя из одной колонки(json) и одной строки:

Примеры запросов к таблице:
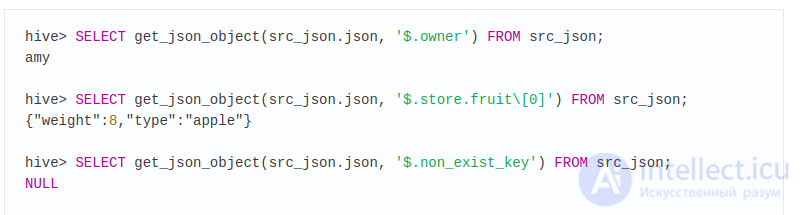
Xpath
Аналогично, если данные которые необходимо обрабатывать при помощи hive хранятся не в json, а в XML — их можно обрабатыватывать при помощи функции xpath, позвоялющей парсить XML при помощи соответствующего языка. Пример парсинга xml-данных при помощи xpath:

Другие полезные встроенные функции:
Встроенная библиотека содержит довольно богатый набор встроенных функций. Можно выделить несколько групп:
Полный список встроенных в hive функций можно найти в официальной документации.
Не всегда бывает достаточно встроенных в hive функций для решения поставленной задачи. Если встроенной функции не нашлось — можно написать свою UDF. Делается это на языке java.
Разберем создание собственной UDF на примере простой функции преобразования строки в lowercase:
1. Создадим пакет com/example/hive/udf и создадим в нем класс Lower.java:
mkdir -p com/example/hive/udf
edit com/example/hive/udf/Lower.java
2. Реализуем собственно класс Lower:

3. Добавим необходимые библиотеки в CLASSPATH (в вашем hadoop-дистрибутиве ссылки на jar-файлы могут быть немного другими):
export CLASSPATH=/opt/cloudera/parcels/CDH/lib/hive/lib/hive-exec.jar:/opt/cloudera/parcels/CDH/lib/hadoop/hadoop-common.jar
4. Компилируем нашу UDF-ку и собираем jar-архив:
javac com/example/hive/udf/Lower.java
jar cvf my_udf.jar *
5. Для того чтобы можно было использовать функцию в hive — нужно явно ее декларировать:

Еще одним способом расширения стандартного функционала HIVE является использование метода TRANSFORM, который позволяет преобразовывать данные при помощи кастомных скриптов на любом языке программирования(особенно это подходит тем кто не любит java и не хочет писать на ней udf-ки).
Синтаксис для использования команды следующий:

 — в данном случае это программа, которая получает данные на stdin, преобразует их и выдает на stdout преобразованные данные. Об этом говорит сайт https://intellect.icu . По сути это очень похоже на streaming-интерфейс к запуску map-reduce задач, о котором мы писали в статье Big Data Часть 2: Hadoop (ссылка внизу)
— в данном случае это программа, которая получает данные на stdin, преобразует их и выдает на stdout преобразованные данные. Об этом говорит сайт https://intellect.icu . По сути это очень похоже на streaming-интерфейс к запуску map-reduce задач, о котором мы писали в статье Big Data Часть 2: Hadoop (ссылка внизу)
Пример:
Пусть у нас есть таблица с зарплатами пользователей, получающих зарплату в разной валюте:
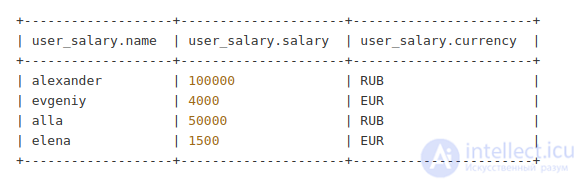
Мы хотим получить табличку, в которой будут рублевые зарплаты для всех пользователей. Для этого напишем скрипт на python, который выполняет преобразование данных:
Скрипт подразумевает что данные на вход поступают в tsv-формате(колонки разделены знаком табуляции). В случае если в таблице встретится значение NULL на вход скрипта попадет значение ‘\N’
Дальше используем этот скрипт для преобразования таблицы:
По сути использование операции TRANSFORM дает возможность полностью заменить классический MapReduce при помощи hive.
Как мы писали в статье про приемы и стратегии работы с MapReduce — для реализации JOIN’a двух таблиц в общем необходимо несколько MapReduce задач. Так как hive работает именно на MapReduce — то JOIN для него также является дорогой операцией.
Однако если одна из двух таблиц, которые необходимо сджойнить полностью влазит в оперативную память какждой ноды — можно обойтись одним MapReduce, загрузив табличку в память. Этот паттерн называется MapJoin. Для того чтобы Hive использовал именно MapJoin — необходимо дать ему подсказку(«hint» в терминологии Hive).
Пример:

В этом примере подразумевается что таблица «store_sales» — большая, а таблица «time_dim» — маленькая и влазит в память. /*+ MAPJOIN(time_dim) */ — это и есть та самая подсказка для для HIVE о запуске задачи MAPJOIN-задачи
Транзакционная модель ACID подразумевает поддержку 4х основных свойств:
Вообще говоря Hive не очень хорошо подходит для работы с изменяющимися данными, однако есть несколько кейсов, где поддержка изменяющихся данных необходима. В первую очередь это:
Для этих целей в hive начиная с версии 0.14 была реализованна поддержка транзакционной модели, реализуемая тремя операциями — INSERT, UPDATE и DELETE.
Поддержка этих операций очень ограниченна:
Поддержка транзакций реализована при помощи дельта-файлов. То есть при выполнеии операции обновления данных данные в исходном файле не обновляются, а создается новый файлик где отмечено какие строки были измененеы. Позже hive их объеденит при помощи операции compaction(аналогичная используется в hbase).
В общем, так как поддержка транзакций очень сильно лимитирована — стоит очень серьезно подумать перед тем как использовать этот функционал в Hive. Возможно стоит посмотреть в сторону HBase или традиционных реляционных баз данных.
В этой и предудщей статье цикла мы рассмотрели основные возможности Hive — мощного инструмента, облегчающего работу с MapReduce задачами. Hive прекрасно подходит аналитикам, привыкшим работать с SQL, может быть легко интегрирован в существующую инфраструктуру при помощи поддержки драйвера JDBC, а с учетом поддержки User Defined Functions и кастомных трансформаций — позволяет полностью перевести процессинг данных с классического MapReduce на себя. Однако hive не является «серебрянной пилюлей» — для часто обновляемых данных можно можно посмотреть в сторону таких инструментов как Hbase и классические реляционые базы данных.
Прочтение данной статьи про big data позволяет сделать вывод о значимости данной информации для обеспечения качества и оптимальности процессов. Надеюсь, что теперь ты понял что такое big data, hive и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL



Комментарии