Лекция
Это окончание невероятной информации про хранилища данных и учет влияния транзакций.
...
помощью триггера).
Пример 19.7.
Для разрешения отношения "многие ко многим" между таблицами "Служащий" (EMPLOYEE) и "Проект" (PROJECT) была введена связывающая таблица "Служащий Проект" (EMP_PROJ), которая имеет ограничения ссылочной целостности, с таблицей "Проект" (PROJECT), как показано на рис. 19.11.
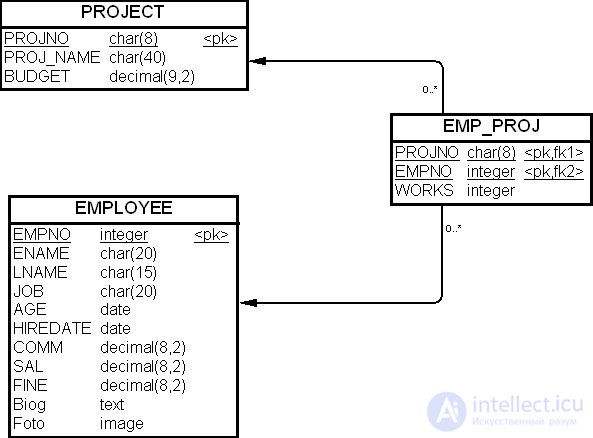
Связывающая таблица "Служащий Проект" (EMP_PROJ) была создана с помощью команды SQL, приведенной ниже.
create table EMP_PROJ (
PROJNO char(8) not null,
EMPNO integer not null,
WORKS integer null,
constraint PK_EMP_PROJ primary key (PROJNO, EMPNO).
constraint FK_EMP_PROJ_REFERENCE_PROJECT foreign key (PROJNO)
references PROJECT (PROJNO),
constraint FK_EMP_PROJ_REFERENCE_EMPLOYEE foreign key (EMPNO)
references EMPLOYEE (EMPNO)
)
go
Но у нас теперь, после разбиения таблицы "Проект" (PROJECT), появились две новые таблицы: "Текущие проекты" (PROJECT_CUR) вместо таблицы "Проекты" (PROJECT) и "Архивные проекты" (PROJECT_OLD), как показано на рис. 19.12.
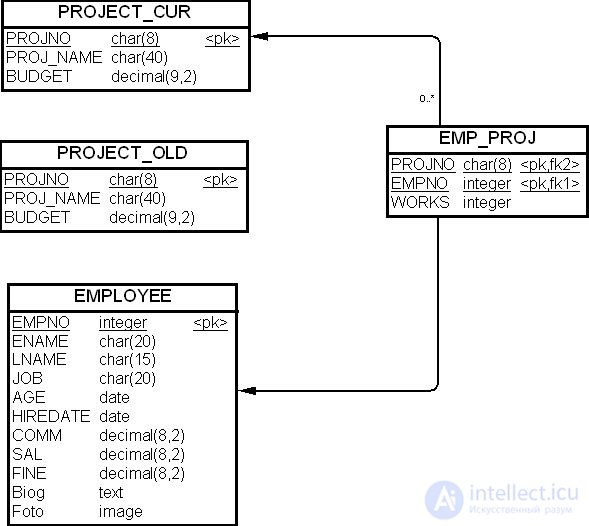
Предположим, что для реализации проекта организация нанимает сотрудников на временной основе (на время выполнения проекта), и вопрос: кто, какие проекты, когда выполнял – не интересует руководство организации. В этом случае взаимосвязь между исполнителями и проектами, которые уже завершены, не интересует руководство, и следовательно, в физической модели данных ничего менять не нужно.
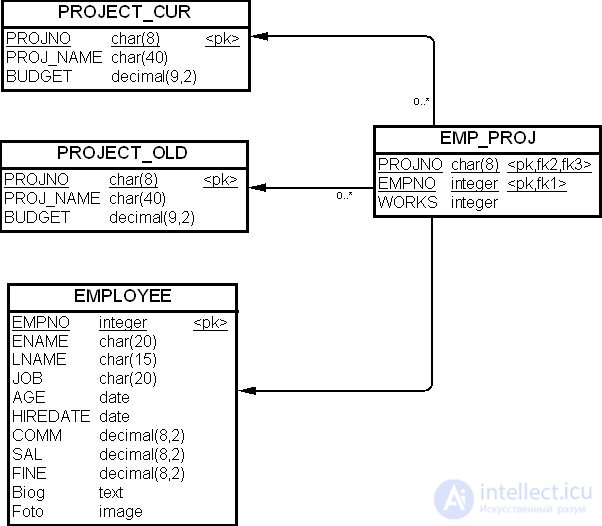
Однако если взаимосвязь между исполнителями и завершенными проектами должна отслеживаться (например, руководство будет изучать вопрос: кто, когда, какой проект выполнял), ее следует распространить и на таблицу "Архивные проекты" (PROJECT_OLD), как показано на рис. 19.13.
Чтобы учесть в БД проделанную нами работу, достаточно внести ограничение внешнего ключа в таблицу "Служащий Проект" (EMP_PROJ), как показано ниже:
drop table EMP_PROJ
Go
create table EMP_PROJ (
PROJNO char(8) not null,
EMPNO integer not null,
WORKS integer null,
constraint PK_EMP_PROJ primary key (PROJNO, EMPNO).
constraint FK_EMP_PROJ_REFERENCE_PROJECT foreign key (PROJNO)
references PROJECT_CUR (PROJNO),
constraint FK_EMP_PROJ_REFERENCE_PROJECT_OLD foreign key (PROJNO)
references PROJECT_OLD (PROJNO),
constraint FK_EMP_PROJ_REFERENCE_EMPLOYEE foreign key (EMPNO)
references EMPLOYEE (EMPNO)
)
go
При разбиении таблицы, для которой были определены ограничения ссылочной целостности, можно также рассмотреть возможность поддержки ссылочной целостности установлением взаимосвязи "один к одному" в сторону исходной таблицы от новой таблицы. В этом случае новая таблица будет иметь внешний ключ, идентичный первичному ключу таблицы. Например, связь "один к одному" между таблицами на рис. 19.14.
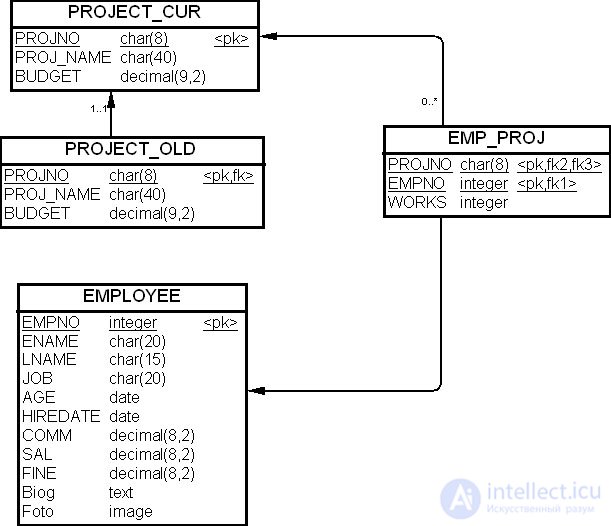
Если определено каскадное правило удаления для этого внешнего ключа (см. "Знакомство с CASE инструментом" ), то СУБД будет автоматически удалять строки новой таблицы, когда соответствующая строка исходной таблицы будет удалена, хотя управление вставкой строк придется перенести в приложение ХД. Команда SQL для этого случая приведена ниже.
create table PROJECT_OLD (
PROJNO char(8) not null,
PROJ_NAME char(40) not null,
BUDGET decimal(9,2) not null,
constraint PK_PROJECT_OLD primary key (PROJNO),
constraint FK_EMP_PROJ_REFERENCE_PROJECT_OLD_1 foreign key (PROJNO)
references PROJECT_СUR (PROJNO)
)
go
При принятии решения о разбиении таблицы следует придерживаться следующего алгоритма:
Объединение таблиц (Table collapsing) является процессом перемещения строк нескольких таблиц в одну, новую таблицу для ограничения числа соединений таблиц БД и улучшения производительности запросов.
Объединяющая таблица включает в себя колонки всех объединяемых таблиц. Если между таблицами были установлены ограничения ссылочной целостности, то при объединении колонки родительской таблицы дублируются, ограничения внешнего ключа таблиц-потомков удаляются из объединяющей таблицы и колонки, участвующие в соединении объединяемых таблиц, удаляются.
Рассмотрим примеры.
Пример. 13.8.
Предположим, что было принято решение об объединении таблиц "Покупатель" (Customer) и "Заказ" (Order), — их необходимо объединить, чтобы исключить операцию соединения в запросах к этим таблицам. Физическая модель данных до объединения приведена на рис. 19.15.
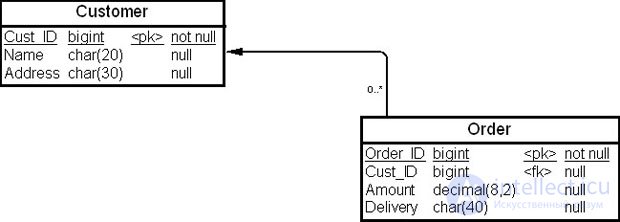
В результате объединения таблиц будет создана одна таблица "Покупатель Счет" (Cust_Order), содержащая все колонки объединяемых таблиц ( рис. 19.16).

Команда SQL для создания объединяющей таблицы приведена ниже.
create table Cust_Order ( Order_ID bigint not null, Cust_ID bigint not null, Amount decimal(8,2) null, Delivery char(40) null, Name char(20) null, Address char(30) null, constraint PK_CUST_ORDER primary key (Order_ID) ) go
Для ХД целесообразно рассматривать объединение нормализованных таблиц иерархии — например, таблиц измерений, представляющих измерение "Время" ( Time ), как на рис. 19.17. Денормализованная таблица измерений для иерархии "Время" приведена на рис. 19.18.
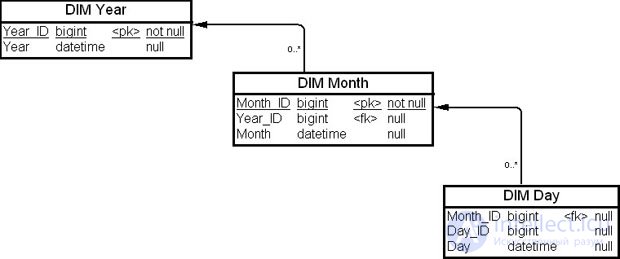

Денормализация колонок (Column denormalization) является процессом для ограничения числа часто встречающихся соединений таблиц БД и улучшения производительности запросов.
Рассмотрим следующий пример.
Пример 19.9.
Пусть задана физическая модель данных ( рис. 19.19).
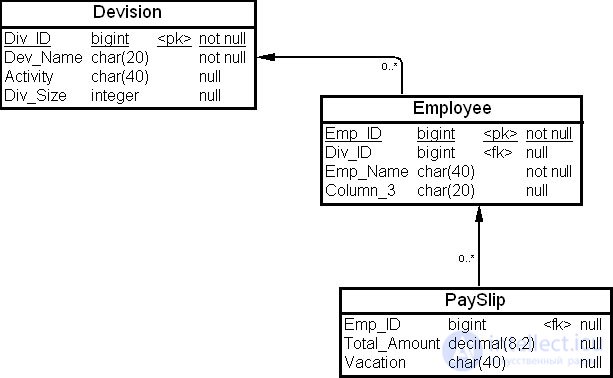
Допустим, что в отчете необходимо напечатать колонки "Название отдела" (Div_name) на платежной расписке из таблицы "Платежная расписка" (Pay Slip) каждого служащего. Для решения этой задачи можно рассмотреть вопрос о денормализации колонок таблицы, чтобы иметь колонку "Название отдела" (Div_Name) в таблице "Платежная расписка" (Pay Slip). Перенесем для этого колонку "Название отдела" (Div_Name) ( нисходящая денормализация ) в таблицу "Платежная расписка" (Pay Slip). Физическая модель данных таблицы "Платежная расписка" (Pay Slip) приведена на рис. 19.20.

Таким образом, мы сократим число соединений при совместном использовании в отчетах колонок таблицы "Платежная расписка" (Pay Slip) и колонки "Название отдела" (Div_Name).
В настоящей лекции мы рассмотрели процесс денормализации таблиц физической БД на уровне моделирования физической модели данных, как для БД, так и для ХД.
Денормализация представляет собой набор методов настройки физической модели БД, используемой для реализации ХД, с целью удовлетворения требований к производительности ХД. Эти методы представляют собой набор рекомендаций и эвристических правил по изменению физической структуры БД, которая была получена в результате первой итерации создания физической модели данных ХД. Применение этих методик носит рекомендательный характер.
В этой лекции были описаны различные типы денормализации и методы ее реализации. Кроме того, было рассмотрено, как при денормализации обеспечить целостность данных, не прибегая к созданию дополнительного кода.
Таким образом, под денормализацией понимают процесс достижения компромиссов в нормализованных таблицах посредством намеренного введения избыточности в целях увеличения производительности.
В большинстве случаев необходимость денормализации становится очевидной лишь на этапе проектирования приложений ХД или его эксплуатации. Другими словами, нельзя принять решение о денормализации на основании одной только модели данных. Обычно стараются найти в приложениях ХД критичные процессы и принимать решения о денормализации в основном в пользу этих процессов. Критичные процессы, как правило, определяют по высокой частоте, большому объему, высокой изменчивости или явному приоритету. Качественное описание транзакций БД позволяет определить наличие таких критических процессов.
Исследование, описанное в статье про хранилища данных и учет влияния транзакций, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое хранилища данных и учет влияния транзакций, хранилища данных и денормализация таблиц, горизонтальное разбиение таблиц, разбиение таблиц и ссылочная целостность, объединение таблиц базы данных, денормализация колонок, column denormalization и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Часть 1 Физическая модель хранилища данных: учет влияния транзакций, денормализация таблиц
Часть 2 Методы разбиения таблиц - Физическая модель хранилища данных: учет влияния
Часть 3 Резюме - Физическая модель хранилища данных: учет влияния транзакций, денормализация
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL