Лекция
Это продолжение увлекательной статьи про статические структуры данных.
...
характеризующихся различным типом данных. Записи являются чрезвычайно удобным средством для представления программных моделей реальных объектов предметной области, ибо, как правило, каждый такой объект обладает набором свойств, характеризуемых данными различных типов.
Пример записи - совокупность сведений о некотором студенте.
Объект "студент" обладает свойствами:
Пример: var
rec:record
num :byte; { личный номер студента }
name :string[20]; { Ф.И.О. }
fac, group:string ; { факультет, группа }
math,comp,lang :byte; {оценки по математике, выч. }
end; {технике, ин. языку }
В памяти эта структура может быть представлена в одном из двух видов :
а) в виде последовательности полей, занимающих непрерывную область памяти (рис. 3.10). При такой организации достаточно иметь один указатель на начало области и смещение относительно начала. Это дает экономию памяти, но лишнюю трату времени на вычисление адресов полей записи.
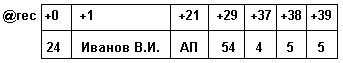
Рис. 3.10. Представление в памяти переменной типа record в виде последовательности полей
б) в виде связного списка с указателями на значения полей записи. При такой организации имеет место быстрое обращение к элементам, но очень неэкономичный расход памяти для хранения. Структура хранения в памяти связного списка с указателями на элементы приведена на рис. 3.11.
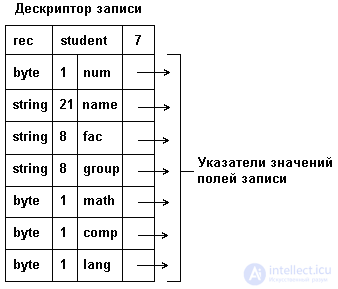
Рис. 3.11. Представление в памяти переменной типа record в виде связного списка.
Примечание: для экономии объема памяти, отводимой под запись, значения некоторых ее полей хранятся в самом дескрипторе, вместо указателей, тогда в дескрипторе должны быть записаны соответствующие признаки.
В соответствии с общим подходом языка C дескриптор записи (в этом языке записи называются структурами) не сохраняется до выполнения программы. Поля структуры просто располагаются в смежных слотах памяти, обращения к отдельным полям заменяются на их адреса еще на этапе компиляции.
Полем записи может быть в свою очередь интегрированная структура данных - вектор, массив или другая запись. В некоторых языках программирования (COBOL, PL/1) при описании вложенных записей указывается уровень вложенности, в других (PASCAL, C) - уровень вложенности определяется автоматически.
Полем записи может быть другая запись,но ни в коем случае не такая же. Это связано прежде всего с тем, что компилятор должен выделить для размещения записи память. Предположим, описана запись вида:
type rec = record
f1 : integer;
f2 : char ;
f3 : rec; end;
Как компилятор будет выделять память для такой записи? Для поля f1 будет выделено 2 байта, для поля f2 - 2 байта, а поле f3 - запись, которая в свою очередь состоит из f1 (2 байта), f2 (2 байта) и f3, которое... и т.д. Недаром компилятор C, встретив подобное описание, выдает сообщение о нехватке памяти.
Однако, полем записи вполне может быть указатель на другую такую же запись: размер памяти, занимаемой указателем известен и проблем с выделением памяти не возникает. Этот прием широко используется в программировании для установления связей между однотипными записями (см. главу 5).
Важнейшей операцией для записи является операция доступа к выбранному полю записи - операция квалификации. Практически во всех языках программирования обозначение этой операции имеет вид:
< имя переменной-записи >.< имя поля >
Так, для записи, описанной в начале п.3.5.1, конструкции: stud1.num и stud1.math будут обеспечивать обращения к полям num и math соответственно.
Над выбранным полем записи возможны любые операции, допустимые для типа этого поля.
Большинство языков программирования поддерживает некоторые операции, работающие с записью, как с единым целым, а не с отдельными ее полями. Это операции присваивания одной записи значения другой однотипной записи и сравнения двух однотипных записей на равенство/неравенство. В тех же случаях, когда такие операции не поддерживаются языком явно (язык C), они могут выполняться над отдельными полями записей или же записи могут копироваться и сравниваться как неструктурированные области памяти.
В ряде прикладных задач программист может столкнуться с группами объектов, чьи наборы свойств перекрываются лишь частично. Обработка таких объектов производится по одним и тем же алгоритмам, если обрабатываются общие свойства объектов, или по разным - если обрабатываются специфические свойства. Можно описать все группы единообразно, включив в описание все наборы свойств для всех групп, но такое описание будет неэкономичным с точки зрения расходуемой памяти и неудобным с логической точки зрения. Если же описать каждую группу собственной структурой, теряется возможность обрабатывать общие свойства по единым алгоритмам.
Для задач подобного рода развитые языки программирования (C, PASCAL) предоставляют в распоряжение программиста записи с вариантами. Запись с вариантами состоит из двух частей. В первой части описываются поля, общие для всех групп объектов, моделируемых записью. Среди этих полей обычно бывает поле, значение которого позволяет идентифицировать группу, к которой данный объект принадлежит и, следовательно, какой из вариантов второй части записи должен быть использован при обработке. Вторая часть записи содержит описания непересекающихся свойств - для каждого подмножества таких свойств - отдельное описание. Язык программирования может требовать, чтобы имена полей-свойств не повторялись в разных вариантах (PASCAL), или же требовать именования каждого варианта (C). В первом случае идентификация поля, находящегося в вариантной части записи при обращении к нему ничем не отличается от случая простой записи:
< имя переменной-записи >.< имя поля >
Во втором случае идентификация немного усложняется:
< имя переменной-записи >.< имя варианта >.< имя поля >
Рассмотрим использование записей с вариантами на примере. Пусть требуется размещать на экране видеотерминала простые геометрические фигуры - круги, прямоугольники, треугольники. Для "базы данных", которая будет описывать состояние экрана, удобно представлять все фигуры однотипными записями. Для любой фигуры описание ее должно включать в себя координаты некоторой опорной точки (центра, правого верхнего угла, одной из вершин) и код цвета. Другие же параметры построения будут разными для разных фигур. Так для круга - радиус; для прямоугольника - длины непараллельных сторон; для треугольника - координаты двух других вершин.
Запись с вариантами для такой задачи в языке PASCAL выглядит, как:
type figure = record
fig_type : char; { тип фигуры }
x0, y0 : word; { координаты опорной точки }
color : byte; { цвет }
case fig_t : char of
'C': ( radius : word); { радиус окружности }
'R': (len1, len2 : word); { длины сторон прямоугольника }
'T': (x1,y1,x2,y2 : word); { координаты двух вершин }
end;
а в языке C, как:
typedef struct
{ char fig_type; /* тип фигуры */
unsigned int x0, y0; /* координаты опорной точки */
unsigned char color; /* цвет */
union
{ struct
{ unsigned int radius; /* радиус окружности */
} cyrcle;
struct
{ unsigned int len1, len2; /* длины сторон прямоугольника */
} rectangle;
struct
{ unsigned int x1,y1,x2,y2; /* координаты двух вершин */
} triangle;
} fig_t;
} figure;
И если в программе определена переменная fig1 типа figure, в которой хранится описание окружности, то обращение к радиусу этой окружности в языке PASCAL будет иметь вид: fig1.radius, а в C: fig1.circle.radius
Поле с именем fig_type введено для представления идентификатора вида фигуры, который, например, может кодироваться символами: "C"- окружность или "R"- прямоугольник, или "T"- треугольник.
Выделение памяти для записи с вариантами показано на рис.3.12.
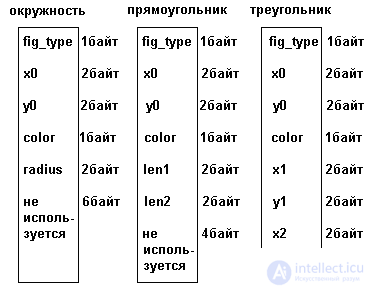
Рис.3.12. Выделение памяти для записи с вариантами
Как видно из рисунка, под запись с вариантами выделяется в любом случае объем памяти, достаточный для размещения самого большого варианта. Если же выделенная память используется для меньшего варианта, часть ее остается неиспользуемой. Общая для всех вариантов часть записи размещается так, чтобы смещения всех полей относительно начала записи были одинаковыми для всех вари- антов. Очевидно, что наиболее просто это достигается размещением общих полей в начале записи, но это не строго обязательно. Вариантная часть может и "вклиниваться" между полями общей части. Поскольку в любом случае вариантная часть имеет фиксированный (максимальный) размер, смещения полей общей части также останутся фиксированными.
Когда речь шла о записях, было отмечено, что полями записи могут быть интегрированные структуры данных - векторы, массивы, другие записи. Аналогично и элементами векторов и массивов могут быть также интегрированные структуры. Одна из таких сложных структур - таблица. С физической точки зрения таблица представляет собой вектор, элементами которого являются записи. Характерной логической особенностью таблиц, которая и определила их рассмотрение в отдельном разделе, является то, что доступ к элементам таблицы производится не по номеру (индексу), а по ключу - по значению одного из свойств объекта, описываемого записью-элементом таблицы. Ключ - это свойство, идентифицирующее данную запись во множестве однотипных записей. Как правило, к ключу предъявляется требование уникальности в данной таблице. Ключ может включаться в состав записи и быть одним из ее полей, но может и не включаться в запись, а вычисляться по положению записи. Таблица может иметь один или несколько ключей. Например, при интеграции в таблицу записей о студентах (описание записи приведено в п.3.5.1) выборка может производиться как по личному номеру студента, так и по фамилии.
Основной операцией при работе с таблицами является операция доступа к записи по ключу. Она реализуется процедурой поиска. Поскольку поиск может быть значительно более эффективным в таблицах, упорядоченных по значениям ключей, довольно часто над таблицами необходимо выполнять операции сортировки. Эти операции рассматриваются в следующих разделах данной главы.
Иногда различают таблицы с фиксированной и с переменной длиной записи. Очевидно, что таблицы, объединяющие записи совершенно идентичных типов, будут иметь фиксированные длины записей. Необходимость в переменной длине может возникнуть в задачах, подобных тем, которые рассматривались для записей с вариантами. Как правило таблицы для таких задач и составляются из записей с вариантами, т.е. сводятся к фиксированной (максимальной) длине записи. Значительно реже встречаются таблицы с действительно переменной длиной записи. Хотя в таких таблицах и экономится память, но возможности работы с такими таблицами ограничены, так как по номеру записи невозможно определить ее адрес. Таблицы с записями переменной длины обрабатываются только последовательно - в порядке возрастания номеров записей. Доступ к элементу такой таблицы обычно осуществляется в два шага. На первом шаге выбирается постоянная часть записи, в которой содержится - в явном или неявном виде - длина записи. На втором шаге выбирается переменная часть записи в соответствии с ее длиной. Прибавив к адресу текущей записи ее длину, получают адрес следующей записи.
Так таблица с записями переменной длины может, например, рассматриваться в некоторых задачах программируемых в машинных кодах. Каждая машинная команда - запись, состоит из одного или нескольких байт. Первый байт - всегда код операции, количество и формат остальных байтов определяется типом команды. Процессор выбирает байт по адресу, задаваемому программным счетчиком, и определяет тип команды. По типу команды процессор определяет ее длину и выбирает остальные ее байты. Содержимое программного счетчика увеличивается на длину команды.
В этом и следующих разделах представлен ряд алгоритмов поиска данных и сортировок, выполняемых на статических структурах данных, так как это характерные операции логического уровня для таких структур. Однако, те же операции и те же алгоритмы применимы и к данным, имеющим логическую структуру таблицы, но физически размещенным в динамической памяти и на внешней памяти, а также к логическим таблицам любого физического представления, обладающим изменчивостью.
Объективным критерием, позволяющим оценить эффективность того или иного алгоритма, является, так называемый, порядок алгоритма. Порядком алгоритма называется функция O(N), позволяющая оценить зависимость времени выполнения алгоритма от объема перерабатываемых данных (N - количество элементов в массиве или таблице). Эффективность алгоритма тем выше, чем меньше время его выполнения зависит от объема данных. Большинство алгоритмов с точки зрения порядка сводятся к трем основным типам:
Эффективность степенных алгоритмов обычно считается плохой, линейных - удовлетворительной, логарифмических - хорошей.
Аналитическое определение порядка алгоритма, хотя часто и сложно, но возможно в большинстве случаев. Возникает вопрос: зачем тогда нужно такое разнообразие алгоритмов, например, сортировок, если есть возможность раз и навсегда определить алгоритм с наилучшим аналитическим показателем эффективности и оставить "право на жизнь" исключительно за ним? Ответ прост: в реальных задачах имеются ограничения, определяемые как логикой задачи, так и свойствами конкретной вычислительной среды, которые могут помогать или мешать программисту, и которые могут существенно влиять на эффективность данной конкретной реализации алгоритма. Поэтому выбор того или иного алгоритма всегда остается за программистом.
В последующем изложении все описания алгоритмов даны для работы с таблицей, состоящей из записей R , R , ..., R[N] с ключами K , K , ..., K[N]. Во всех случаях N - количество элементов таблицы. Программные примеры для сокращения их объема работают с массивами целых чисел. Такой массив можно рассматривать как вырожденный случай таблицы, каждая запись которой состо- ит из единственного поля, которое является также и ключом. Во всех программных примерах следует считать уже определенными: константу N- целое положительное число, число элементов в массиве; константу EMPTY - целое число, признак "пусто" (EMPTY=-1); тип - type SEQ = array[1..N] of integer; сортируемые последовательности.
Простейшим методом поиска элемента, находящегося в неупорядоченном наборе данных, по значению его ключа является последовательный просмотр каждого элемента набора, который продолжается до тех пор, пока не будет найден желаемый элемент. Если просмотрен весь набор, но элемент не найден - значит, искомый ключ отсутствует в наборе.
Для последовательного поиска в среднем требуется (N+1)/2 сравнений. Таким образом, порядок алгоритма - линейный - O(N).
Программная иллюстрация линейного поиска в неупорядоченном массиве приведена в следующем примере, где a - исходный массив, key - ключ, который ищется; функция возвращает индекс найденного элемента или EMPTY - если элементт отсутствует в массиве.
{===== Программный пример 3.4 =====}
Function LinSearch( a : SEQ; key : integer) : integer;
var i : integer;
for i:=1 to N do { перебор эл-тов массива }
if a[i]=key then begin { ключ найден - возврат индекса }
LinSearch:=i; Exit; end;
LinSearch:=EMPTY; {просмотрен весь массив, но ключ не найден }
end;
Другим относительно простым методом доступа к элементу является метод бинарного (дихотомического, двоичного) поиска, который выполняется в заведомо упорядоченной последовательности элементов. Записи в таблицу заносятся в лексикографическом (символьные ключи) или численно (числовые ключи) возрастающем порядке. Для достижения упорядоченности может быть использован какой-либо из методов сортировки (см. 3.9).
В рассматриваемом методе поиск отдельной записи с определенным значением ключа напоминает поиск фамилии в телефонном справочнике. Сначала приближенно определяется запись в середине таблицы и анализируется значение ее ключа. Если оно слишком велико, то анализируется значение ключа, соответствующего записи в середине первой половины таблицы, и указанная процедура повторяется в этой половине до тех пор, пока не будет найдена требуемая запись. Если значение ключа слишком мало, испытывается ключ, соответствующий записи в середине второй половины таблицы, и процедура повторяется в этой половине. Этот процесс продолжается до тех пор, пока не будет найден требуемый ключ или не станет пустым интервал, в котором осуществляется поиск.
Для того, чтобы найти нужную запись в таблице, в худшем случае требуется log2(N) сравнений. Это значительно лучше, чем при последовательном поиске.
Программная иллюстрация бинарного поиска в упорядоченном массиве приведена в следующем примере, где a - исходный массив, key - ключ, который ищется; функция возвращает индекс найденного элемента или EMPTY - если элементт отсутствует в массиве.
{===== Программный пример 3.5 =====}
Function BinSearch(a : SEQ; key : integer) : integer;
Var b, e, i : integer;
begin
b:=1; e:=N; { начальные значения границ }
while b<=e do { цикл, пока интервал поиска не сузится до 0 }
begin i:=(b+e) div 2; { середина интервала }
if a[i]=key then
begin BinSearch:=i; Exit; {ключ найден - возврат индекса }
end else
if a[i] < key then b:=i+1 { поиск в правом подинтервале }
else e:=i-1; { поиск в левом подинтервале }
end; BinSearch:=EMPTY; { ключ не найден }
end;
Трассировка бинарного поиска ключа 275 в исходной последовательности:
75, 151, 203, 275, 318, 489, 524, 519, 647, 777
представлена в таблице 3.4.
| Интерация | b | e | i | K[i] |
| 1 | 1 | 10 | 5 | 318 |
| 2 | 1 | 4 | 2 | 151 |
| 3 | 3 | 4 | 3 | 203 |
| 4 | 4 | 4 | 4 | 275 |
Таблица 3.4
Алгоритм бинарного поиска можно представить и несколько иначе, используя рекурсивное описание. В этом случае граничные индексы интервала b и e являются параметрами алгоритма.
Рекурсивная процедура бинарного поиска представлена в программном примере 3.6. Для выполнения поиска необходимо при вызове процедуры задать значения ее формальных параметров b и е - 1 и N соответственно, где b, e - граничные индексы области поиска.
{===== Программный пример 3.6 =====}
Function BinSearch( a: SEQ; key, b, e : integer) : integer;
Var i : integer;
begin
if b > e then BinSearch:=EMPTY { проверка ширины интервала }
else begin
i:=(b+e) div 2; { середина интервала }
if a[i]=key then BinSearch:=i {ключ найден, возврат индекса}
else if a[i] < key then { поиск в правом подинтервале }
BinSearch:=BinSearch(a,key,i+1,e)
else { поиск в левом подинтервале }
BinSearch:=BinSearch(a,key,b,i-1);
end; end;
Известно несколько модификаций алгоритма бинарного поиска, выполняемых на деревьях, которые будут рассмотрены в главе 5.
Для самого общего случая сформулируем задачу сортировки таким образом: имеется некоторое неупорядоченное входное множество ключей и должны получить выходное множество тех же ключей, упорядоченных по возрастанию или убыванию в численном или лексикографическом порядке.
Из всех задач программирования сортировка, возможно, имеет самый богатый выбор алгоритмов решения. Назовем некоторые факторы, которые влияют на выбор алгоритма (помимо порядка алгоритма).
1). Имеющийся ресурс памяти: должны ли входное и выходное множества располагаться в разных областях памяти или выходное множество может быть сформировано на месте входного. В последнем случае имеющаяся область памяти должна в ходе сортировки динамически перераспределяться между входным и выходным множествами; для одних алгоритмов это связано с большими затратами, для других - с меньшими.
2). Исходная упорядоченность входного множества: во входном множестве (даже если оно сгенерировано датчиком случайных величин) могут попадаться упорядоченные участки. В предельном случае входное множество может оказаться уже упорядоченным. Одни алгоритмы не учитывают исходной упорядоченности и требуют одного и того же времени для сортировки любого (в том числе и уже упорядоченного) множества данного объема, другие выполняются тем быстрее, чем лучше упорядоченность на входе.
3). Временные характеристики операций: при определении порядка алгоритма время выполнения считается обычно пропорциональным числу сравнений ключей. Ясно, однако, что сравнение числовых ключей выполняется быстрее, чем строковых, операции пересылки, характерные для некоторых алгоритмов, выполняются тем быстрее, чем меньше объем записи, и т.п. В зависимости от характеристик записи таблицы может быть выбран алгоритм, обеспечивающий минимизацию числа тех или иных операций.
4). Сложность алгоритма является не последним соображением при его выборе. Простой алгоритм требует меньшего времени для его реализации и вероятность ошибки в реализации его меньше. При промышленном изготовлении программного продукта требования соблюдения сроков разработки и надежности продукта могут даже превалировать над требованиями эффективности функционирования.
Разнообразие алгоритмов сортировки требует некоторой их классификации. Выбран один из применяемых для классификации подходов, ориентированный прежде всего на логические характеристики применяемых алгоритмов. Согласно этому подходу любой алгоритм сортировки использует одну из следующих четырех стратегий (или их комбинацию).
1). Стратегия выборки. Из входного множества выбирается следующий по критерию упорядоченности элемент и включается в выходное множество на место, следующее по номеру.
2). Стратегия включения. Из входного множества выбирается следующий по номеру элемент и включается в выходное множество на то место, которое он должен занимать в соответствии с критерием упорядоченности.
3). Стратегия распределения. Входное множество разбивается на ряд подмножеств (возможно, меньшего объема) и сортировка ведется внутри каждого такого подмножества.
4). Стратегия слияния. Выходное множество получается путем слияния маленьких упорядоченных подмножеств.
Далее приводится обзор (далеко не полный) методов сортировки, сгруппированных по стратегиям, применяемым в их алгоритмах. Все алгоритмы рассмотрены для случая упорядочения по возрастанию ключей.
Сортировка простой выборкой.
Данный метод реализует практически "дословно" сформулированную выше стратегию выборки. Порядок алгоритма простой выборки - O(N^2). Количество пересылок - N.
Алгоритм сортировки простой выборкой иллюстрируется программным примером 3.7.
В программной реализации алгоритма возникает проблема значения ключа "пусто". Довольно часто программисты используют в качестве такового некоторое заведомо отсутствующее во входной последовательности значение ключа, например, максимальное из теоретически возможных значений. Другой, более строгий подход - создание отдельного вектора, каждый элемент которого имеет логический тип и отражает состояние соответствующего элемента входного множества ("истина" - "непусто", "ложь" - "пусто"). Именно такой подход реализован в нашем программном примере. Роль входной последовательности здесь выполняет параметр a, роль выходной - параметр b, роль вектора состояний - массив c. Алгоритм несколько усложняется за счет того, что для установки начального значения при поиске минимума приходится отбрасывать уже "пустые" элементы.
{===== Программный пример 3.7 =====}
Procedure Sort( a : SEQ; var b : SEQ);
Var i, j, m : integer;
c: array[1..N] of boolean; {состояние эл-тов вх.множества}
begin
for i:=1 to N do c[i]:=true; { сброс отметок}
for i:=1 to N do {поиск 1-го невыбранного эл. во вх.множестве}
begin j:=1;
while not c[j] do j:=j+1;
m:=j; { поиск минимального элемент а}
for j:=2 to N do
if c[j] and (a[j] < a[m]) then m:=j;
b[i]:=a[m]; { запись в выходное множество}
c[m]:=false; { во входное множество - "пусто" }
end; end;
Обменная сортировка простой выборкой.
Алгоритм сортировки простой выборкой, однако, редко применяется в том варианте, в каком он описан выше. Гораздо чаще применяется его, так называемый, обменный вариант. При обменной сортировке выборкой входное и выходное множество располагаются в одной и той же области памяти; выходное - в начале области, входное - в оставшейся ее части. В исходном состоянии входное множество занимает всю область, а выходное множество - пустое. По мере выполнения сортировки входное множество сужается, а выходное - расширяется.
Обменная сортировка простой выборкой показана в программном примере 3.8. Процедура имеет только один параметр - сортируемый массив.
{===== Программный пример 3.8 =====}
Procedure Sort(var a : SEQ);
Var x, i, j, m : integer;
begin
for i:=1 to N-1 do { перебор элементов выходного множества}
{ входное множество - [i:N]; выходное - [1:i-1] }
begin m:=i;
for j:=i+1 to N do { поиск минимума во входном множестве }
if (a[j] < a[m]) then m:=j;
{ обмен 1-го элемента вх. множества с минимальным }
if i<>m then begin
x:=a[i]; a[i]:=a[m]; a[m]:=x;
end;end; end;
Результаты трассировки программного примера 3.8 представлены в таблице 3.5. Двоеточием показана граница между входным и выходным множествами.
| Шаг | Содержимое массива а |
| Исходный | :242 447 286 708_24_11 192 860 937 561 |
| 1 | _11:447 286 708_ 24 242 192 860 937 561 |
| 2 | _11_24:286 708 447 242 192 860 937 561 |
| 3 | _11_24 192:708 447 242 286 860 937 561 |
| 4 | _11_24 192 242:447 708 286 860 937 561 |
| 5 | _11_24 192 242 286:708 447 860 937 561 |
| 6 | _11_24 192 242 286 447:708 860 937 561 |
| 7 | _11_24 192 242 286 447 561:860 937 708 |
| 8 | _11_24 192 242 286 447 561 708:937 860 |
| 9 | _11_24 192 242 286 447 561 708 860:937 |
| Результат | _11_24 192 242 286 447 561 708 860 937: |
Таблица 3.5
Очевидно, что обменный вариант обеспечивает экономию памяти. Очевидно также, что здесь не возникает проблемы "пустого" значения. Общее число сравнений уменьшается вдвое - N*(N-1)/2, но порядок алгоритма остается степенным - O(n^2). Количество перестановок N-1, но перестановка, по-видимому, вдвое более времяемкая операция, чем пересылка в предыдущем алгоритме.
Довольно простая модификация обменной сортировки выборкой предусматривает поиск в одном цикле просмотра входного множества сразу и минимума, и максимума и обмен их с первым и с последним элементами множества соответственно. Хотя итоговое количество сравнений и пересылок в этой модификации не уменьшается, достигается экономия на количестве итераций внешнего цикла.
Приведенные выше алгоритмы сортировки выборкой практически нечувствительны к исходной упорядоченности. В любом случае поиск минимума требует полного просмотра входного множества. В обменном варианте исходная упорядоченность может дать некоторую экономию на перестановках для случаев, когда минимальный элемент найден на первом месте во входном множестве.
Пузырьковая сортировка.
Входное множество просматривается, при этом попарно сравниваются соседние элементы множества. Если порядок их следования не соответствует заданному критерию упорядоченности, то элементы меняются местами. В результате одного та- кого просмотра при сортировке по возрастанию элемент с самым большим значением ключа переместится ("всплывет") на последнее место в множестве. При следующем проходе на свое место "всплывет" второй по величине ключа элемент и т.д. Для постановки на свои места N элементов следует сделать N-1 проходов. Выходное множество, таким образом, формируется в конце сортируемой последовательности, при каждом следующем проходе его объем увеличивается на 1, а объем входного множества уменьшается на 1.
Порядок пузырьковой сортировки - O(N^2). Среднее число сравнений - N*(N-1)/2 и таково же среднее число перестановок, что значительно хуже, чем для обменной сортировки простым выбором. Однако, то обстоятельство, что здесь всегда сравниваются и перемещаются только соседние элементы, делает пузырьковую сортировку удобной для обработки связных списков. Перестановка в связных списках также получается более экономной.
Еще одно достоинство пузырьковой сортировки заключается в том, что при незначительных модификациях ее можно сделать чувствительной к исходной упорядоченности входного множества. Рассмотрим некоторые их таких модификаций.
Во-первых, можно ввести некоторую логическую переменную, которая будет сбрасываться в false перед началом каждого прохода и устанавливаться в true при любой перестановке. Если по окончании прохода значение этой переменной останется false, это означает, что менять местами больше нечего, сортировка закончена. При такой модификации поступление на вход алгоритма уже упорядоченного множества потребует только одного просмотра.
Во-вторых, может быть учтено то обстоятельство, что за один просмотр входного множества на свое место могут "всплыть" не один, а два и более элементов. Это легко учесть, запоминая в каждом просмотре позицию последней перестановки и установки этой позиции в качестве границы между множествами для следующего просмотра. Именно эта модификация реализована в программной иллюстрации пузырьковой сортировке в примере 3.9. Переменная nn в каждом проходе устанавливает верхнюю границу входного множества. В переменной x запоминается позиция перестановок и в конце просмотра последнее запомненное значение вносится в nn. Сортировка будет закончена, когда верхняя граница входного множества станет равной 1.
{===== Программный пример 3.9 =====}
Procedure Sort( var a : seq);
Var nn, i, x : integer;
begin
nn:=N; { граница входного множества }
repeat x:=1; { признак перестановок }
for i:=2 to nn do { перебор входного множества }
if a[i-1] > a[i] then begin { сравнение соседних эл-в }
x:=a[i-1]; a[i-1]:=a[i]; a[i]:=x; { перестановка }
x:=i-1; { запоминание позиции }
end; nn:=x; { сдвиг границы }
until (nn=1); {цикл пока вых. множество не захватит весь мас.}
end;
Результаты трассировки программного примера 3.9 представлены в таблице 3.6.
| Шаг | nn | Содержимое массива а |
| Исходный | 10 | 717 473 313 160 949 764_34 467 757 800: |
| 1 | 9 | 473 313 160 717 764_34 467 757 800:949 |
| 2 | 7 | 313 160 473 717_34 467 757:764 800 949 |
| 3 | 5 | 160 313 473_34 467:717 757 764 800 949 |
| 4 | 4 | 160 313_34 467:473 717 757 764 800 949 |
| 5 | 2 | 160_34:313 467 473 717 757 764 800 949 |
| 6 | 1 | _34:160 313 467 473 717 757 764 800 949 |
| Результат | : 34 160 313 467 473 717 757 764 800 949 |
Таблица 3.6
Еще одна модификация пузырьковой сортировки носит название шейкер-сортировки. Суть ее состоит в том, что направления просмотров чередуются: за просмотром от начала к концу следует просмотр от конца к началу входного множества. При просмотре в прямом направлении запись с самым большим ключом ставится на свое место в последовательности, при просмотре в обратном направлении - запись с самым маленьким. Этот алгоритм весьма эффективен для задач восстановления упорядоченности, когда исходная последовательность уже была упорядочена, но подверглась не очень значительным изменениям. Упорядоченность в последовательности с одиночным изменением будет гарантированно восстановлена всего за два прохода.
Сортировка Шелла.
Это еще одна модификация пузырьковой сортировки. Суть ее состоит в том, что здесь выполняется сравнение ключей, отстоящих один от другого на некотором расстоянии d. Исходный размер d обычно выбирается соизмеримым с половиной общего размера сортируемой последовательности. Выполняется пузырьковая сортировка с интервалом сравнения d. Затем величина d уменьшается вдвое и вновь выполняется пузырьковая сортировка, далее d уменьшается еще вдвое и т.д. Последняя пузырьковая сортировка выполняется при d=1. Качественный порядок сортировки Шелла остается O(N^2), среднее же число сравнений, определенное эмпирическим путем - log2(N)^2*N. Ускорение достигается за счет того, что выяв- ленные "не на месте" элементы при d>1, быстрее "всплывают" на свои места.
Пример 3.10 иллюстрирует сортировку Шелла.
{===== Программный пример 3.10 =====}
Procedure Sort( var a : seq);
Var d, i, t : integer; k : boolean; { признак перестановки }
begin d:=N div 2; { начальное значение интервала }
while d > 0 do { цикл с уменьшением интервала до 1 }
begin k:=true; {пузырьковая сортировка с
продолжение следует...
Часть 1 3. СТАТИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Часть 2 3.6. Таблицы как структура данных - 3. СТАТИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Часть 3 3.8.2. Сортировки включением - 3. СТАТИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Часть 4 Вау!! 😲 Ты еще не читал? Это зря! - 3. СТАТИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
На этом все! Теперь вы знаете все про статические структуры данных, Помните, что это теперь будет проще использовать на практике. Надеюсь, что теперь ты понял что такое статические структуры данных, вектор структура данных, массивы структура данных, множества структура данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных
Комментарии
Оставить комментарий
Структуры данных
Термины: Структуры данных