Лекция
Это продолжение увлекательной статьи про повышение производительности запросов.
...
отдельных строк, и с их помощью нельзя выполнить поиск значений в некотором диапазоне. В СУБД Oracle нельзя применить опцию REVERSE к битовым индексам и к исключительно индексным таблицам.
Пример 20.5.
Числовые ключи, содержащие последовательные числа, есть, в частности, в таблице "Служащий" (EMPLOYEE) – "Номер служащего" (EMPNO). Можно создать для этой таблицы дополнительный индекс с обращением ключа для извлечения записи о сотруднике. Заметим, что для этой колонки уже есть индекс первичного ключа.
CREATE INDEX dep_ndx ON EMPLOYEE (EMPNO) REVERSE;
В процессе эксплуатации администратор базы данных может перестроить этот индекс с помощью команды ALTER INDEX:
ALTER INDEX EMPLOYEE REBUILD NOREVERSE;
В СУБД семейства MS SQL Server возможность создания индексов с обращением значения ключа средствами диалекта SQL отсутствует.
Если в предложении WHERE применяется функция по индексированной колонке, то обычно СУБД не используют этот индекс при организации доступа к строкам таблицы. Но при создании индекса на основе значения функции (function-based index), которая является той же функцией, что и в предложении WHERE, СУБД как семейства Oracle, так и семейства MS SQL Server использует такой индекс для считывания строк, удовлетворяющих критерию отбора.
В СУБД семейства MS SQL Server вычисляемые колонки могут иметь свойство PERSISTED. Это означает, что компонент Database Engine хранит вычисленные значения в таблице и обновляет их при обновлении любых колонок, от которых зависит вычисляемый столбец. Компонент Database Engine использует эти материализованные значения, когда создает индекс по колонке и когда запрос обращается к индексу.
Для индексации вычисляемой колонки она должна быть детерминированной и точной. Если используется свойство PERSISTED, список типов индексируемых вычисляемых колонок расширяется и включает следующие типы:
Пример 20.6.
В качестве примера использования индексов по вычисляемой колонке приведем пример моделирования хеш-индекса в MS SQL Server.
Предположим, что никакого индекса для колонки "Фамилия" (ENAME) в таблице "Служащий" (EMPLOYEE) создано не было. Тогда, если в предложении WHERE команды SELECT задан предикат поиска по колонке "Фамилия" (ENAME), то СУБД будет сканировать таблицу. Если таблица содержит около 1000000 строк, то операция сканирования будет увеличивать время обработки запроса.
Создадим хеш-индекс для колонки "Фамилия" (ENAME) с помощью функции checksum(), для этого добавим в таблицу вычисляемую колонку, как показано ниже.
alter table EMPLOYEE add ENameHash as checksum(EName); go
Далее создадим индекс по этой колонке, как показано ниже.
create index IDX_ENames on EMPLOYEE (ENameHash); go
При наличии в БД такого индекса СУБД будет его использовать при обработке запроса описанного в данном примере.
В СУБД семейства MS SQL Server можно создавать и использовать фильтрованные индексы, для создания таких индексов в команде CREATE INDEX предусмотрена возможность использования предложения WHERE.
Применение предложения WHERE
Предикат фильтра использует простую логику сравнения и не может ссылаться на вычисляемый столбец, столбец определяемого пользователем типа, столбец пространственного типа данных или столбец типа hierarchyID. Сравнения с помощью литералов NULL с операторами сравнения недопустимы. Вместо этого используются операторы IS NULL и IS NOT NULL.
Фильтруемый индекс подходит для столбцов, имеющих точно определенные подмножества данных.
Пример 20.7.
Создадим фильтрованный индекс в таблице "Служащий" (EMPLOYEE) для колонки "Штрафы" (FINE), чтобы быстро получать списки оштрафованных сотрудников.
CREATE NONCLUSTERED INDEX IDX_FINE
ON EMPLOYEE (EName, FINE)
WHERE FINE > 0;
GO
В настоящем разделе мы рассмотрели различные типы индексов и примеры их создания. В следующем разделе остановимся подробнее на параметрах проектирования индексов.
При проектировании индексов необходимо иметь некоторый механизм для оценки качества предполагаемого индекса. Введем несколько понятий, с помощью которых можно грубо оценить качество потенциального индекса.
Кардинальностью колонки (cardinality) таблицы называется число дискретных различных значений колонки, которые встречаются в строках таблицы. Например, если в таблице "Служащий" (EMPLOYEE) мы заводим колонку для указания пола – "Пол" (SEX), то кардинальность этой колонки есть 2, так в природе у людей существует только два пола — мужской и женский. Для колонки первичного ключа кардинальность будет равна числу строк в таблице.
Причина, по которой кардинальность колонки важна для проектирования индексов, состоит в том, что кардинальность индексируемой колонки определяет число уникальных входов, которые должны сохраняться в индексе, т.е. число записей в индексе. Так, для индексируемой колонки "Пол" (SEX) будут существовать два уникальных входа, которые будут повторяться много раз в индексе. При предположении равновероятного распределения пола сотрудников на 100000 строк в таблице "Служащий" (EMPLOYEE) каждый вход индекса будет повторяться 50000 раз. СУБД вряд ли будут принимать решение об использовании такого индекса при построении плана запроса.
Определить кардинальность потенциальной колонки индексирования в существующей таблице БД достаточно просто.
SELECT COUNT (DISTINCT колонка) FROM таблица;
При проектировании новой БД для ХД следует оценить кардинальность всех потенциальных индексируемых колонок во всех таблицах физической модели данных ХД, исходя из имеющейся документации.
Способ, с помощью которого СУБД оценивает действие кардинальности, состоит в использовании фактора селективности выборки (selectivity factor). Фактор селективности выборки индекса определяется как величина, обратная кардинальности индексной колонки:

Фактор селективности оценивает потенциальный объем операций ввода-вывода. Чем меньше фактор селективности, тем меньше требуется операций ввода-вывода для получения результирующего множества строк таблицы. СУБД оценивает эту величину, чтобы решить, применять индекс для доступа к строкам таблицы или нет.
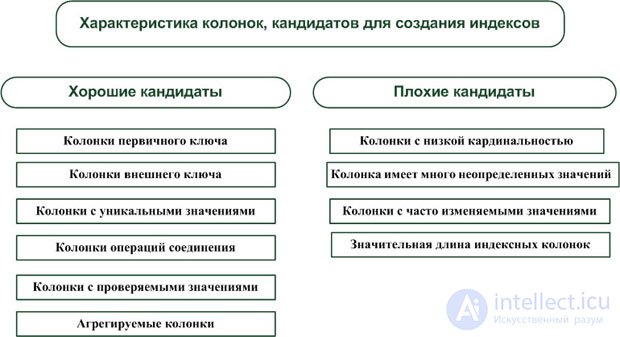
В заключение раздела приведем список правил для определения колонок, которые являются хорошими и плохими кандидатами для индексирования. Об этом говорит сайт https://intellect.icu . Эти правила могут быть использованы при принятии решения о построении индексов реляционной базы данных.
Хорошими кандидатами для индексирования обычно являются:
Факторы, влияющие на низкую эффективность индексов:
Плохими кандидатами для индексирования обычно являются:
Следует соблюдать следующие общие правила при создании индексов.
К сожалению, часто проектировщики принимают крайне неудачные решения об индексировании. Это приводит к тому, что в ХД появляется слишком много индексов. В результате тратится много времени на поддержку этих индексов, дисковое пространство расходуется неэффективно, СУБД "путается" в выборе подходящего индекса или не использует их вовсе. Поэтому необходимо помнить о двух основных принципах построения индекса:
На рис. 20.4 приведены рекомендации по выбору колонок для создания индексов.
Как правило, в таблицах ХД содержится огромное количество данных. Чем больше размер таблицы, тем больше времени потребуется для некоторых операций по выборке строк таблицы и для выполнения некоторых функций администратора базы данных — например, для резервного копирования и восстановления. Большие по размеру индексированные таблицы имеют также большие индексы, которые требуют много времени СУБД для их обслуживания.
Секционирование (partitioning) — это способ физического распределения таблиц и индексов среди двух или более табличных пространств (СУБД Oracle) или в одной или более файловых группах (СУБД MS SQL Server) в зависимости от значений ключевых колонок таблиц с целью повышения производительности операций ввода-вывода. Таким образом, секционирование – это разбиение таблицы на группы, с сохранением для всех групп общего определения структуры. Табличное пространство (СУБД Oracle) или файловая группа (СУБД MS SQL Server) – это физическое месторасположение таблиц БД в файловой структуре операционной системы.
Фрагмент таблицы, расположенный в отдельной файловой группе, будем называть секцией таблицы. Секционирование также повышает эффективность резервного копирования и восстановления за счет выполнения этих задач с участием меньшего объема данных. Секцию таблицы можно трактовать как предопределенный поименованный фрагмент памяти на одном или нескольких дисках, к которому можно обращаться в предложениях SQL по имени.
В реализации секционирования одним из важных понятий является колонка таблицы, относительно значений которой СУБД будет делать физическое разнесение таблицы по различным файловым группам на жестких дисках. Эти колонка называется ключом секционирования (partition key).
Секционирование таблиц и индексов задается жестко на уровне строк ( секционирование по столбцам не допускается) и позволяет осуществлять доступ через единую точку входа (имя таблицы или имя индекса ) таким образом, что в коде приложения не требуется знать число секций, находящихся за точкой входа. Секционирование может осуществляться на базовой таблице, а также на связанных с ней индексах.
Мы отдельно рассмотрим секционирование таблиц для семейств СУБД Oracle и MS SQL Server.
В СУБД семейства Oracle поддерживается несколько видов секционирования: секционирование по диапазону , хеш-секционирование , составное секционирование , а также различные виды секционирования индексов.
Секционирование по диапазону (range partitioning) означает распределение строк таблицы на различные предопределенные табличные пространства в зависимости от значения ключа секционирования. Доступ к такой таблице, как и к любой другой, осуществляется по ее имени, причем доступ к секциям, расположенным в каждом табличном пространстве, можно получить отдельно. Например, таблицу, содержащую финансовые квартальные отчеты организации, можно секционировать по дате таким образом, что отчеты по каждому кварталу будут храниться в отдельном табличном пространстве. При такой организации секций данные только по одному кварталу будут выбираться из одного табличного пространства, что повысит эффективность работы базы данных в целом.
Секционирование по диапазону базируется на упорядочении строк таблицы в секциях на основе значения колонок ключа секционирования. Концептуально таблица, секционированная по диапазону, устроена, как на рис. 20.5.
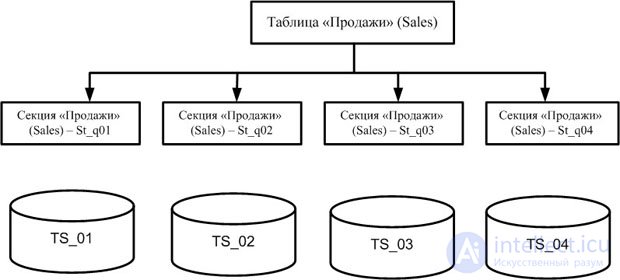
Для создания секционированных таблиц используется команда SQL CREATE TABLE с предложением PARTITION. В СУБД Oracle ключ секционирования не может иметь тип LONG.
Пример 20.8.
Рассмотрим систему обработки заказов. Предположим, что в ней есть таблица "Продажи" (Sales), в которой сохраняются данные о количестве, времени и цене продаж для каждого покупателя. Можно использовать секционирование по диапазону, а именно по кварталу, для представления этой таблицы в базе данных. Предположим, что мы имеем четыре определенных ранее табличных пространства c именами ts_01, ts_02, ts_03, ts_04, распределенные по четырем дискам, как показано на рисунке ниже.
Фрагмент скрипта определяет таблицу "Продажи" (Sales) с физическим размещением секций, как на рис. 20.5:
CREATE TABLE Sales
(
s_customer_id number(6),
s_amt number(9,2),
s_date date)
PARTITION BY RANGE (s_date)
(PARTITION st_q01 VALUES LESS THAN ('01-apr-2002')
TABLESPACE ts_01,
PARTITION st_q02 VALUES LESS THAN ('01-jul-2002')
TABLESPACE ts_02,
PARTITION st_q03 VALUES LESS THAN ('01-oct-2002')
TABLESPACE ts_03,
PARTITION st_q04 VALUES LESS THAN (MAXVALUE)
TABLESPACE ts_04
);
Предложение PARTITION BY RANGE (s_date) указывает СУБД Oracle выполнить секционирование таблицы по ключу секционирования s_date. Предложения вида (PARTITION st_q01 VALUES LESS THAN ('01-apr-2002') TABLESPACE ts_01 определяют имя секции st_q01 и ее размещение в соответствующем табличном пространстве ts_01.
Чтобы получить доступ к строкам таблицы, расположенным в определенной секции, и узнать о продажах в третьем квартале, можно использовать команду SELECT, как показано ниже:
SELECT s_customer_id, s_amt FROM Sales PARTITION (st_q03);
Мы видим, что для того, чтобы получить доступ к строкам секции таблицы, нужно указать опцию PARTITION (имя секции) после имени таблицы в предложении FROM.
Администратор базы данных может легко удалять, добавлять, перемещать, расщеплять, усекать и изменять секции с помощью команды ALTER TABLE. Удалить отдельную секцию можно также, удалив соответствующее ей табличное пространство.
Хеш-секционирование (hash partitioning) означает равномерное распределение строк таблицы по назначенным табличным пространствам в зависимости от значения ключа секционирования, который в данном случае хешируется. Этот вид секционирования удобно применять для строк, у которых распределение значений ключа секционирования неравномерно или плохо группируется. Для принятия решения о создании хеш-секционированной таблицы необходимо достаточно точно представлять размер этой таблицы, поскольку встроенные в СУБД Oracle алгоритмы хеширования используют этот размер для вычисления позиции строки на физической странице базы данных. Определение размера таблицы может привести к большому числу коллизий, т.е. к попаданию строк с различными значениями ключа на одну и ту же страницу, что приводит к поддержке цепочек переполнения и дополнительному вводу-выводу.
Пример 20.9.
Рассмотрим ту же, что и в примере 20.8, таблицу "Продажи" (Sales) и ту же схему ( рис. 20.5) табличных пространств. Однако используем в качестве ключа секционирования "Идентификатор покупателя" ( s_customer_id ). Отметим, что распределение значений этой колонки может быть очень неравномерно. Фрагмент кода SQL для создания хеш-секционированной таблицы "Продажи" (Sales) можно написать так:
CREATE TABLE Sales
(
s_customer_id number(6),
s_amt number(9,2),
s_date date)
PARTITION BY HASH (s_customer_id)
(PARTITION q01 TABLESPACE ts_01,
PARTITION q02 TABLESPACE ts_02,
PARTITION q03 TABLESPACE ts_03,
PARTITION q04 TABLESPACE ts_04
);
Предложение PARTITION BY HASH (s_customer_id) указывает СУБД Oracle выполнить секционирование таблицы по ключу секционирования s_customer_id. Предложения вида (PARTITION q01 TABLESPACE ts_01 определяют имя секции st_q01 и ее размещение в соответствующем табличном пространстве ts_01.
Составное секционирование (composite partittioning) является комбинацией секционирования по диапазону и хеш-секционирования. Это означает, что таблица сначала распределяется среди табличных пространств на основе диапазона значений ключа секционирования, далее каждая из полученных секций диапазонов делится на подчиненные секции, или подсекции, и затем строки равномерно распределяются среди подчиненных секций по значению хеш-ключа.
Пример 20.10.
Рассмотрим ту же, что и в предыдущем примере, таблицу "Продажи" (Sales) и ту же схему табличных пространств. В качестве ключа секционирования по диапазону используем колонку "Дата продажи" (s_date). В качестве ключа хеш-секционирования — "Идентификатор покупателя" (s_customer_id). Однако теперь каждая секция по диапазону будет разделена на предопределенное число подсекций. Фрагмент кода SQL для создания таблицы "Продажи" (Sales) с составным секционированием можно написать так:
CREATE TABLE Sales
(
s_customer_id number(6),
s_amt number(9,2),
s_date date)
PARTITION BY RANGE (s_date)
SUB PARTITION BY HASH (s_customer_id)
SUB PARTITION 4
STORE IN (ts_01, ts_02, ts_03, ts_04)
(PARTITION q01 VALUES LESS THAN ('01-apr-2002'),
PARTITION q02 VALUES LESS THAN ('01-jul-2002'),
PARTITION q03 VALUES LESS THAN ('01-oct-2002'),
PARTITION q04 VALUES LESS THAN (MAXVALUE)
);
продолжение следует...
Часть 1 Проектирование производительности хранилищ данных - indexing индексирование,
Часть 2 О некоторых параметрах проектирования индексов - Проектирование производительности хранилищ данных
Часть 3 Секционирование представлений - Проектирование производительности хранилищ данных - indexing индексирование,
Часть 4 Повышение производительности запросов: кластеры - Проектирование производительности хранилищ данных -
Часть 5 Резюме - Проектирование производительности хранилищ данных - indexing индексирование,
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL