Лекция
Это продолжение увлекательной статьи про повышение производительности запросов.
...
style="padding: 0px; margin: 0px; color: rgb(0, 0, 0); font-family: "lucida grande", tahoma, verdana, arial, sans-serif; font-size: 12px;">
Секции q01, q02, q03, q04 будут содержать строки с диапазоном дат, которые определены в предложениях типа PARTITION q02 VALUES LESS THAN ('01-jul-2002') и будут распределены в табличных пространствах ts_01, ts_02, ts_03, ts_04. Предложение SUB PARTITION 4 предписывает СУБД Oracle разбиение каждой секции на четыре логические единицы, а предложение SUB PARTITION BY HASH (s_customer_id) распределяет строки заданного диапазона среди этих четырех подчиненных секций.
В СУБД Oracle предусмотрено секционирование индексов (index partitioning), которое означает преднамеренное распределение индексов таблиц по назначенным табличным пространствам в соответствии с ключом секционирования. Секционирование индексов может быть глобальным и локальным.
Локально секционированный индекс имеет такой же ключ секционирования, то же количество табличных пространств и те же правила секционирования, что и отвечающая ему базовая таблица. Глобально секционированный индекс содержит предложение PARTITION BY RANGE, в котором задаются параметры секционирования, отличные от параметров секционирования соответствующей базовой таблицы.
Секционированные индексы могут быть префиксными или непрефиксными. В случае префиксного секционированного индекса секционирование производится по ключу секционирования, который содержит основную часть индексного ключа. В случае непрефиксных секционированных индексов секционирование выполняется по значениям, отличным от значений колонки индексирования.
Индексы могут быть секционированы и в случае, когда индексируемая таблица не секционируется. В этом случае по умолчанию предполагается, что индекс является глобальным секционированным индексом. В СУБД Oracle не предусмотрена поддержка глобальных непрефиксных секционированных индексов.
В локально секционированном индексе ключевые значения одной секции индекса соответствуют строкам таблицы из одной ее секции.
Пример 14/11.
Создадим локальный секционированный индекс для таблицы "Продажи" (Sales) из примера 20.8. Ключом секционирования этой таблицы является колонка "Дата продажи" (s_date). Фрагмент кода создания индекса приведен ниже:
CREATE INDEX sales_ndx ON Sales (s_date)
LOCAL
(PARTITION st_i_q01 TABLESPACE ts_01,
PARTITION st_i_q02 TABLESPACE ts_02,
PARTITION st_i_q03 TABLESPACE ts_03,
PARTITION st_i_q04 TABLESPACE ts_04
);
Локально секционированный индекс называется равносекционированным (equi-partitioned), если он имеет то же число секций и те же правила секционирования, что и его базовая таблица. Обратите внимание, что в примере при создании индекса не использовалось предложение PARTITION BY RANGE. СУБД Oracle автоматически берет структуру секционирования для индекса из структуры секционирования базовой таблицы Sales. Также можно опустить и предложения типа PARTITION st_i_q02 TABLESPACE ts_02. Если опущено PARTITION, то СУБД Oracle автоматически создаст имена секций. Если опущено TABLESPACE, то СУБД Oracle автоматически разместит секции в тех же табличных пространствах, в которых находятся соответствующие секции базовой таблицы.
Глобально секционированный индекс имеет структуру секций, отличную от структуры секций базовой таблицы данного индекса. В качестве примера создадим глобально секционированный индекс для таблицы "Продажи" (Sales) из примера 20.8.
Пример 20.12.
В качестве ключа секционирования для индекса возьмем колонку "Идентификатор покупателя" (s_customer_id). В фрагменте кода ниже для секций индекса используются другие индексные пространства с именами ts_i_01, ts_i_02, ts_i_03. Число секций индекса не совпадает с числом секций базовой таблицы для этого индекса.
CREATE INDEX sales_ndx ON Sales (s_customer_id)
GLOBAL
PARTITION BY RANGE (s_customer_id)
(PARTITION st_i_q1 VALUES LESS THAN (10000)
TABLESPACE ts_i_01,
PARTITION st_i_q2 VALUES LESS THAN (20000)
TABLESPACE ts_i_02,
PARTITION st_i_q3 VALUES LESS THAN (MAXVALUE)
TABLESPACE ts_i_03,
);
Локально секционированный индекс может быть создан по колонке, отличной от ключа секционирования базовой таблицы индекса. В примере 20.13 создается такой непрефиксный индекс для таблицы "Продажи" (Sales) из примера 20.8.
Пример 20.13.
В качестве колонки секционирования для индекса взята колонка "Идентификатор покупателя" (s_customer_id), а для секций индекса выбраны другие табличные пространства ts_i_01, ts_i_02, ts_i_03, ts_i_04, отличающиеся от табличных пространств секций базовой таблицы индекса.
CREATE INDEX sales_ndx_1 ON Sales (s_customer_id)
LOCAL
(PARTITION st_i_q01 TABLESPACE ts_i_01,
PARTITION st_i_q02 TABLESPACE ts_i_02,
PARTITION st_i_q03 TABLESPACE ts_i_03,
PARTITION st_i_q04 TABLESPACE ts_i_04
);
При принятии решения о секционировании индексов следует иметь в виду следующее.
В СУБД Oracle есть возможность секционировать представления. Основная идея секционирования представлений проста. Пусть физическая таблица разбита на несколько таблиц (необязательно с помощью методов секционирования таблиц) в соответствии с критерием разбиения, который делает обработку запроса более производительной. Критерий разбиения будем называть предикатом секционирования. Тогда можно создать и настроить представления таким образом, чтобы с их помощью обращение к данным этих таблиц было проще для пользователя. Секция представления определяется в соответствии с диапазоном значений ключа секционирования. Запросы, которые используют диапазон значений для выборки данных из секций представления, будут получать доступ только к тем секциям, которые соответствуют диапазонам значений ключа секционирования.
Секции представления могут быть определены предикатами секционирования, заданными либо при помощи ограничения CHECK, либо с использованием предложения WHERE. Покажем, как могут быть применены оба приема, на примере несколько модифицированной таблицы "Продажи" (Sales), которую мы рассматривали в предыдущем разделе. Допустим, что данные о продажах для календарного года размещаются в четырех отдельных таблицах, каждая из которых соответствует кварталу года — Q1_Sales, Q2_Sales, Q3_Sales и Q4_Sales.
Пример 20.14.
Секционирование представлений с помощью ограничения CHECK. С помощью команды ALTER TABLE можно добавить ограничения на колонку "Дата продажи" (s_date) каждой таблицы, чтобы ее строки соответствовали одному из кварталов года. Созданное затем представление sales дает возможность обращаться к этим таблицам, как к одной, так и ко всем вместе.
ALTER TABLE Q1_Sales ADD CONSTRAINT C0 CHECK (s_date BETWEEN 'jan-1-2002' AND 'mar-31-2002'); ALTER TABLE Q2_Sales ADD CONSTRAINT C1 CHECK (s_date BETWEEN 'apr 1-2002' AND 'jun-30-2002'); ALTER TABLE Q3_Sales ADD CONSTRAINT C2 check (s_date BETWEEN 'jul-1-2002' AND 'sep-30-2002'); ALTER TABLE Q4_Sales ADD CONSTRAINT C3 check (s_date BETWEEN 'oct-1-2002' AND 'dec-31-2002'); CREATE VIEW sales_v AS SELECT * FROM Q1_Sales UNION ALL SELECT * FROM Q2_Sales UNION ALL SELECT * FROM Q3_Sales UNION ALL SELECT * FROM Q4_Sales;
Преимуществом такого секционирования представлений является то, что предикат ограничения CHECK не оценивается для каждой строки запроса. Такие предикаты исключают вставку в таблицы строк, не соответствующих критерию предиката. Строки, соответствующие предикату секционирования, извлекаются из базы данных быстрее.
Пример 20.15.
Секционирование представлений с помощью предложения WHERE. Создадим представление для тех же таблиц, что и в примере выше.
CREATE VIEW sales_v AS SELECT * FROM Q1_Sales WHERE s_date BETWEEN 'jan-1-2002' AND 'mar-31-2002' UNION ALL SELECT * FROM Q2_Sales WHERE s_date BETWEEN 'apr-1-2002' AND 'jun-30-2002' UNION ALL SELECT * FROM Q3_Sales WHERE s_date BETWEEN 'jul-1-2002' AND 'sep-30-2002' UNION ALL SELECT * FROM Q4_Sales WHERE s_date BETWEEN 'oct-1-2002' AND 'dec-31-2002';
Метод секционирования представлений с помощью предложения WHERE имеет некоторые недостатки. Во-первых, критерий секционирования проверяется во время выполнения для всех строк во всех секциях, которые охватываются запросом. Во-вторых, пользователи могут ошибочно вставить строку не в ту секцию, т.е. вставить строку, относящуюся к первому кварталу, в третий квартал, что приведет к неправильной выборке данных по этим кварталам.
У этого приема есть и достоинство по сравнению с использованием ограничения CHECK. Можно разместить секцию, соответствующую предикату WHERE, на удаленной базе данных. Фрагмент определения преставления приведен ниже.
SELECT * FROM east_sales@icp.ac.ru WHERE LOC = 'EAST' UNION ALL SELECT * FROM west_sales@ioc.ac.ru WHERE LOC = 'WEST';
Принимая решение о создании секционированных представлений, необходимо помнить о следующих факторах.
В СУБД семейства MS SQL Server также поддерживается секционирование таблиц, индексов и представлений. Однако, в отличие от СУБД семейства Oracle, секционирование в СУБД семейства MS SQL Server выполняется по унифицированной схеме.
В MS SQL Server все таблицы и индексы в БД считаются секционированными, даже если они состоят всего лишь из одной секции. Фактически, секции представляют собой базовую организационную единицу в физической архитектуре таблиц и индексов. Это означает, что логическая и физическая архитектура таблиц и индексов, включающая несколько секций, полностью отражает архитектуру таблиц и индексов, состоящих из одной секции.
Секционирование таблиц и индексов задается жестко на уровне строк ( секционирование по столбцам не допускается) и позволяет осуществлять доступ через единую точку входа (имя таблицы или имя индекса ) таким образом, что в коде приложения не требуется знать число секций. Секционирование может осуществляться на базовой таблице, а также на связанных с ней индексах.
Для создания секционированной таблицы в СУБД MS SQL Server используются следующие объекты БД: функции секционирования и схемы секционирования. Эти объекты позволяют разделять данные на конкретные сегменты и управлять их местоположением в БД или ХД. Например, можно распределить данные по нескольким дисковым массивам в зависимости от даты поступления данных или других отличительных признаков. Следует отметить, что таблицу можно секционировать по одному из ее столбцов, и каждая секция должна содержать данные, которые не могут храниться в других секциях.
При секционировании таблицы сначала нужно определить правило, по которому данные будут разделяться на сегменты. Для сопоставления отдельных строк данных с разными сегментами служит функция секционирования.
Строки данных могут сегментироваться по колонке любого типа, кроме следующих: text, ntext, image, xml, timestamp, varchar(max), nvarchar(max), varbinary(max), псевдонимы типов данных и пользовательские типы данных среды CLR. Однако функция секционирования должна распределять каждую строку данных только в одну секцию таблицы ; иными словами, в результате применения функции одна и та же строка не может принадлежать нескольким секциям одновременно.
Чтобы секционировать таблицу, в ней необходимо создать или выбрать колонку секционирования ( ключ секционирования ). Ключ секционирования можно создать в схеме таблицы в момент создания таблицы либо добавить позднее путем модификации таблицы. Столбец может принимать значения NULL, но все строки, содержащие значения NULL, будут по умолчанию помещаться в самую левую секцию таблицы. Этого можно избежать, указав при создании функции секционирования, что значения NULL должны помещаться в самую правую секцию таблицы. Выбор левой или правой секций – важное решение проектирования, проявляющееся при изменении схемы секционирования, добавлении дополнительных секций или удалении существующих.
При создании функции секционирования можно выбрать функции LEFT или RIGHT. Разница между секциями LEFT и RIGHT состоит в размещении данных по секциям. Функция LEFT распределяет данные по принципу от самого низкого значения до самой высокой величины (то есть по возрастанию). Функция RIGHT распределяет данные по принципу от самого высокого значения до самого низкого (то есть по убыванию). Рассмотрим пример.
Пример 20.16.
Возьмем следующие примеры определения функций секционирования с использованием LEFT и RIGHT:
CREATE PARTITION FUNCTION Left_Partition (int) AS RANGE LEFT FOR VALUES (1,10,100) CREATE PARTITION FUNCTION Right_Partition (int) AS RANGE RIGHT FOR VALUES (1,10,100)
В первой функции ( Left_Partition ) значения 1, 10 и 100 размещаются соответственно в первой, второй и третьей секциях. Во второй функции ( Right_Partition ) эти значения размещаются во второй, третьей и четвертой секциях.
При создании секционированной таблицы важно, чтобы секции получились сбалансированными по кардинальности. Это позволяет оценить, сколько дискового пространства потребуется для каждой секции. Использование параметров LEFT и RIGHT определяет, куда будут размещаться данные, что, в свою очередь, задает размер секции и размеры индексов, созданных на ней.
Определить номер секции, в которую попадут те или иные данные, можно с помощью функции $PARTITION, как показано ниже:
SELECT $PARTITION.Left_Partition (10) SELECT $PARTITION.Right_Partition (10)
Первая команда SELECT возвращает значение 2, вторая – значение 3.
После создания функции секционирования и выбора способа разделения данных по секциям следует решить, где будет создаваться каждая секция в файловой системе. Для создания связи секций с их размещением в файловой системе используются схемы секционирования. Схемы секционирования управляют тем, каким образом отдельные секции хранятся на диске, путем использования файловых групп для размещения каждой секции на дисковой подсистеме. Схемы секционирования можно настроить таким образом, чтобы все секции располагались в единой файловой группе, чтобы каждая секция располагалась в своей файловой группе или чтобы несколько секций использовали общие файловые группы. Последний способ дает администратору базы данных широкие возможности рассредоточения операций ввода-вывода на диске.
В примере 20.17 показаны некоторые из способов, позволяющих присвоить схеме секционирования одну или несколько файловых групп. Следует помнить, что файловые группы, используемые схемой секционирования, должны существовать в базе данных перед созданием схемы.
Пример 20.17.
Выполним присвоение файловых групп схеме секционирования. Сначала приведем пример размещения всех секций таблицы в одной файловой группе с именем PRIMARY.
CREATE PARTITION SCHEME Primary_Left_Scheme
AS PARTITION Left_Partition
ALL TO ([PRIMARY])
Чтобы разместить все секции в различных файловых группах, нужно выполнить следующую команду:
CREATE PARTITION SCHEME Different_Left_Scheme
AS PARTITION Left_Partition
TO (Filegroup1, Filegroup2, Filegroup3, Filegroup4)
Чтобы разместить несколько секций в различных файловых группах, нужно выполнить следующую команду:
CREATE PARTITION SCHEME Multiple_Left_Scheme
AS PARTITION Left_Partition
TO (Filegroup1, Filegroup2, Filegroup1, Filegroup2)
Если создать указанные в примере функции секционирования и использовать приведенную схему секционирования для создания таблицы, то впоследствии можно будет определить, где будут размещаться отдельные строки данных в секционированных таблицах.
Пример 20.18.
Рассмотрим в качестве примера схему типа "звезда" с таблицей фактов "Продажи" (SALES), как показано на рис. 20.6. Создадим секционированную таблицу "Продажи" (SALES).
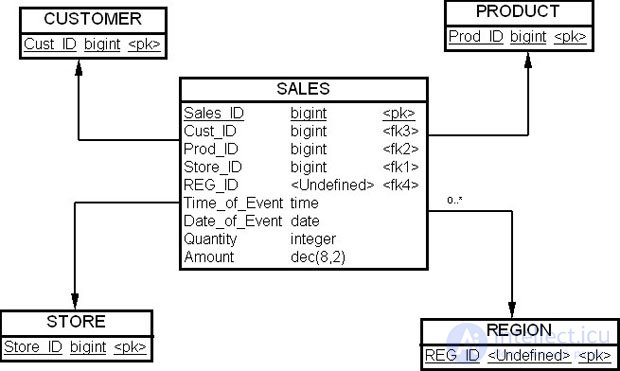
Сначала мы должны создать функцию секционирования:
CREATE PARTITION FUNCTION
MyPartitionFunctionLeft
(date)
AS RANGE LEFT
FOR VALUES ('1/01/2005', '1/01/2007', '1/01/2009)
MyPartitionFunctionLeft — это название функции разделения, datetime — тип данных ключа секционирования, а RANGE LEFT указывает, как делить значения данных, которые связаны с датами FOR VALUES.
Ключ секционирования имеет тип данных date, т.е. это колонка "Дата события" (Date_of_Event). В команде, приведенной выше, деление строк на непересекающиеся группы построено по принципу разбиения их на двухлетние группы. Разделение на секции RANGE LEFT делит данные в диапазонах значений, показанных на рис. 20.7.

Каждая область значений в секции имеет границы, которые определены в операторе FOR VALUES. Если дата продажи была 23 июня 2006 года, то строка будет храниться в секции 2 (P2).
Теперь создадим схему секционирования. Схема секционирования отображает секции на различные файловые группы (с именами MyFilegroup1, MyFilegroup2, MyFilegroup3, MyFilegroup4 ) , как показано в следующей команде:
CREATE PARTITION SCHEME MyPartitionScheme AS MyPartitionFunction TO (MyFilegroup1, MyFilegroup2, MyFilegroup3, MyFilegroup4)
MyPartitionScheme – это имя схемы секционирования, а имя MyPartitionFunction определяет функцию секционирования. Эта команда отображает данные в секции, которые связаны с одной или несколькими файловыми группами. Строки с данными со значениями колонки "Дата продажи" (Date_of_Event date) до 1/01/05 связаны с MyFilegroup1. Строки этой колонки со значениями, большими или равными 1/01/05 и до 1/01/07, назначены MyFilegroup2. Строки со значениями, большими или равными 1/01/07 и до момента 1/01/09, связаны с MyFilegroup3. Все остальные строки со значениями, большими или равными 1/01/09, связаны с MyFilegroup4.
Для каждого набора граничных значений (которые задаются условием FOR VALUES функции секционирования ) количество секций будет равно "Количество граничных значений" + 1 секция. Предыдущее предложение CREATE PARTITION SCHEME включает три ограничения и четыре секции. Независимо от того, созданы ли секции с RANGE RIGHT или RANGE LEFT, количество секций всегда будет равно "Количество граничных значений" + 1, вплоть до 1000 секций на таблицу.
Теперь мы можем создать секционированную таблицу фактов "Продажи" (SALES). Создание секционированной таблицы мало чем отличается от создания обычной таблицы, нужно только сослаться на имя схемы секционирования в условии ON, как показано в команде ниже.
CREATE TABLE SALES (Sales_ШВ bigint identity (1, 1) primary not clustered NOT NULL, Cust_ID bigint null, Prod_ID bigint null, Store_ID bigint null, REG_ID char(10) null, Time_of_Event time null, Quantity integer not null, Amount dec(8,2) not null, Date_of_Event date NOT NULL) ON MyPartitionScheme (Date_of_Event)
Определяя имя схемы секционирования, проектировщик указывает, что эта таблица является секционированной. Очевидно, схема секционирования, функция секционирования и файловые группы должны существовать в БД до того, как будет создаваться таблица.
Можно объединять только две смежные секции. Чтобы слить две секции, выполните
продолжение следует...
Часть 1 Проектирование производительности хранилищ данных - indexing индексирование,
Часть 2 О некоторых параметрах проектирования индексов - Проектирование производительности хранилищ данных
Часть 3 Секционирование представлений - Проектирование производительности хранилищ данных - indexing индексирование,
Часть 4 Повышение производительности запросов: кластеры - Проектирование производительности хранилищ данных -
Часть 5 Резюме - Проектирование производительности хранилищ данных - indexing индексирование,
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL