Лекция
Привет, Вы узнаете о том , что такое проектирование баз данных, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое проектирование баз данных , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Модель данных — это концептуальное представление для выражения и передачи бизнес-требований. Она наглядно показывает характер данных, бизнес-правила, управляющие данными, и то, как данные будут организованы в базе данных.
Моделирование данных можно сравнить со строительством дома. Допустим, компании ABC необходимо построить дом для гостей (база данных). Компания вызывает архитектора (разработчик моделей данных) и объясняет требования к зданию (бизнес-требования). Архитектор (модельер данных) разрабатывает план (модель данных) и передает его компании ABC. Наконец, компания ABC вызывает инженеров-строителей (администраторов баз данных и разработчиков баз данных) для строительства дома.
Данным дадим такое определение. Это информация о состоянии свойств какого-либо объекта. То есть есть у нас объект морковка. (Почему именно морковка? Ну просто она у меня сейчас на столе в тарелке. Кстати, она зрение укрепляет!)
У нее есть свойства: магазин, цвет, сочность, длина, свежесть, ну там и еще что-нибудь. Каждое свойство имеет значение.
Допустим, у нас есть множество разных морковок. У всех из них свой набор свойств. Мы можем написать об этом в тетрадке в виде поэтичного текста. Но работать с этим будет не удобно. Удобнее работать с данными, когда они представлены в таблице. Названия столбцов - названия свойств, каждая строка - конкретная морковка, в ячейках - значения соответствующего свойства конкретной морковки.
Сущности и атрибуты. Сущности — это «вещи» в бизнес-среде, о которых мы хотим хранить данные, например, продукты, клиенты, заказы и т.д. Атрибуты используются для организации и структурирования данных. Например, нам необходимо хранить определенную информацию о продаваемых нами продуктах, такую как отпускная цена или доступное количество. Эти фрагменты данных являются атрибутами сущности Product. Сущности обычно представляют собой таблицы базы данных, а атрибуты — столбцы этих таблиц.
Взаимосвязь. Взаимосвязь между сущностями описывает, как одна сущность связана с другой. В модели данных сущности могут быть связаны как: «один к одному», «многие к одному» или «многие ко многим».
Сущность пересечения. Если между сущностями есть связь типа «многие ко многим», то можно использовать сущность пересечения, чтобы декомпозировать эту связь и привести ее к типу «многие к одному» и «один ко многим».
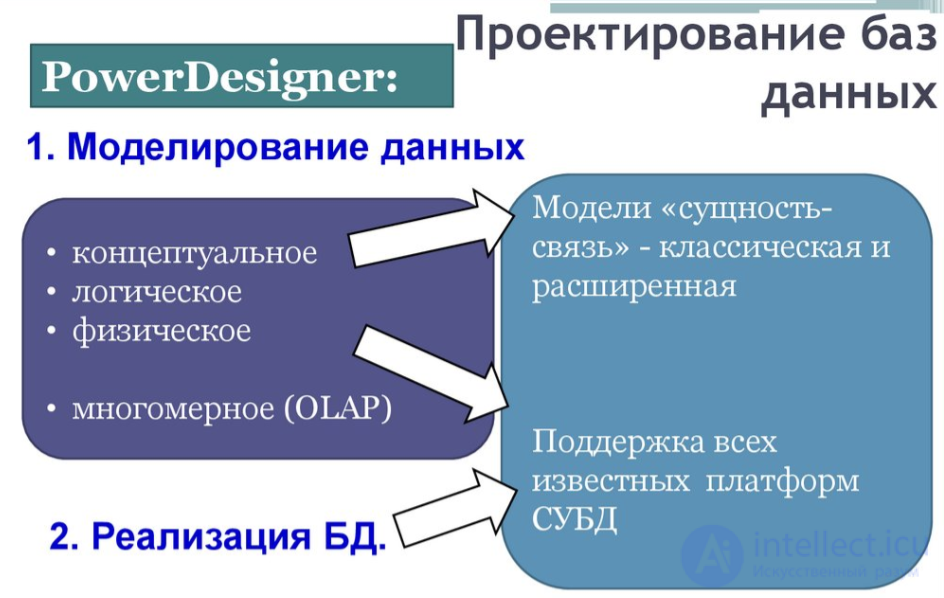
Простой пример: есть 2 сущности — телешоу и человек. Каждое телешоу может смотреть один или несколько человек, в то время как человек может смотреть одно или несколько телешоу.
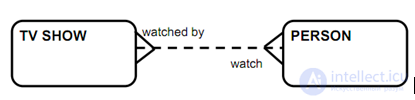
Эту проблему можно решить, введя новую пересекающуюся сущность «Просмотр записи»:
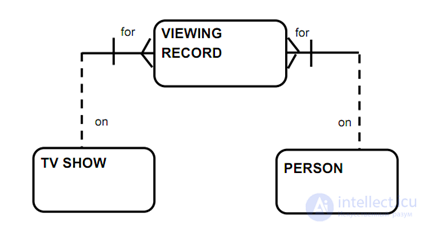
ER диаграмма показывает сущности и отношения между ними. ER-диаграмма может принимать форму концептуальной модели данных, логической модели данных или физической модели данных.
Концептуальная модель данных включает в себя все основные сущности и связи, не содержит подробных сведений об атрибутах и часто используется на начальном этапе планирования. Пример:
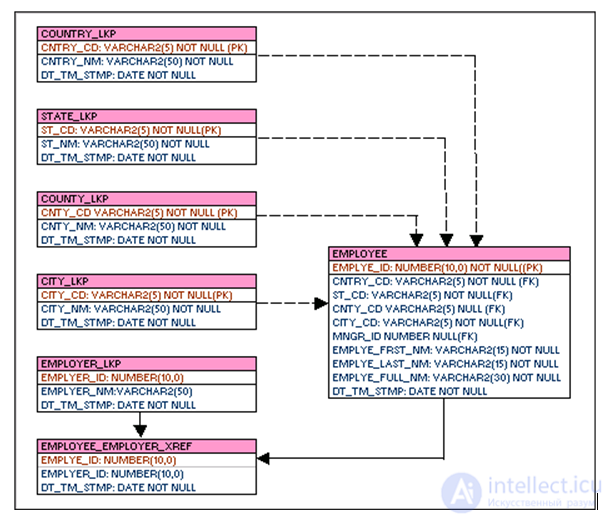
Логическая модель данных — это расширение концептуальной модели данных. Она включает в себя все сущности, атрибуты, ключи и взаимосвязи, которые представляют бизнес-информацию и определяют бизнес-правила. Пример:
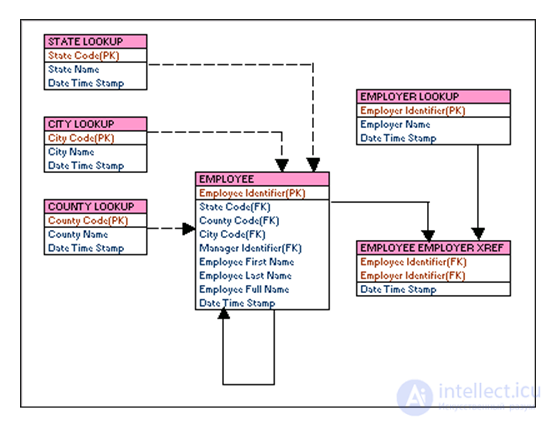
Физическая модель данных включает в себя все необходимые таблицы, столбцы, связи, свойства базы данных для физической реализации баз данных. Производительность базы данных, стратегия индексации, физическое хранилище и денормализация — важные параметры физической модели. Пример:
В зависимости от бизнес-требований ваша модель данных может быть реляционной или размерной. Реляционная модель — это метод проектирования, направленный на устранение избыточности данных. Данные делятся на множество дискретных сущностей, каждая из которых становится таблицей в реляционной базе данных. Таблицы обычно нормализованы до 3-й нормальной формы. В OLTP приложениях используется эта методология.
В размерной модели данные денормализованы для повышения производительности. Здесь данные разделены на измерения и факты и упорядочены таким образом, чтобы пользователю было легче извлекать информацию и создавать отчеты.
Давайте-ка что-нибудь намоделируем.
Таблица:
| Магазин | Цвет | Сочность | Свежесть | Номер | Адрес магазина |
|---|---|---|---|---|---|
| Перекресток | Рыжий | 70% | 15 дней | 1 | Москва |
| Связной | Синий | 2% | 5 дней | 2 | Паттайя |
| Перекресток | Красный | 75% | 10 дней | 3 | Москва |
Ну и так далее. Довольно удобно. Но есть здесь определенные недостатки. Не критикуйте пока, я именно этим сейчас и буду заниматься, и мы сделаем все как надо. Данные мы можем хранить не только о морковках. Можем, например, о магазинах поставщиках морковки, как мы и сделали.
Какие здесь недостатки. В одной таблице хранятся описания разнотипных объектов: морковок и магазинов. Нужно создавать для каждого типа объектов свою таблицу. В нашем случае это будут таблицы "Магазины" и "Морковки".
Магазины:
| Название | Адрес | Номер |
|---|---|---|
| Перекресток | Москва | 1 |
| Связной | Паттайя | 2 |
Морковки:
| Цвет | Сочность | Свежесть | Номер | Номер магазина |
|---|---|---|---|---|
| Рыжий | 70% | 15 дней | 1 | 1 |
| Синий | 2% | 5 дней | 2 | 2 |
| Красный | 75% | 10 дней | 3 | 1 |
Преимуществом такого подхода является минимизация неоправданного дублирования больших объемов информации. Об этом говорит сайт https://intellect.icu . Здесь мы вместо того, чтобы два раза писать про морковку из московского перекрестка написали 2 раза магазин с номером 1, а тот, в свою очередь, описан один раз в другой таблице. Согласитесь, теперь наша база данных занимает меньше места и пользоваться этим удобнее. И список магазинов теперь отделен от морковок и не придется их там выискивать. Кстати, забыл сказать. База данных - набор информации, организованной каким-либо способом. У нас это таблицы, причем, как видите связанные: номер магазина в информации о морковке указывает на соответствующую строку таблицы о магазинах (о связи мы поговорим чуть позже).
Так вот. Если база данных организована в виде двумерных таблиц, связанных между собой, то такая модель называетсяреляционной.
Таблицы связываются по полям, называемым ключами. Ключи могут быть первичными и внешними. В нашем примере в таблице "Морковки" поле номер - это первичный ключ таблицы.То же и в "Магазинах". Первичный ключ уникально идентифицирует запись в таблице, т.е. не содержит повторяющихся значений. В таблице "Морковки" есть поле "номер магазина". Это внешний ключ - поле которое хранит значения первичного ключа привязанной таблицы.
Существуют следующие разновидности отношений (связей) между таблицами:
*Один-ко-многим. Самый распространенный вид связи. Одной записи таблицы соответствует любое количество (и 0, и 1, и даже еще больше) записей другой таблицы. Как в нашем примере. Один магазин поставляет разные морковки.
*Многие-ко-многим. На сама деле, из названия ясно, что из себя представляет какая связь, поэтому лишние слова тут не нужны. Ну, например, пусть теперь у нас будет таблица не "Морковки", а более широкое понятие "Продукты" и та же таблица "Магазины". Один и тот же продукт может продаваться в нескольких магазинах, в то же время один магазин может торговать многими продуктами. По-хорошему, такую связь надо избегать, т.к. она противоречит как определению нормальных форм, так и целостности связей (оба этих понятия рассмотрим позже). Лучше сделать две связи один-ко многим.
Например:
-Связь многие-ко-многим: Магазины(название, флаг), Продукты(название, флаг). Каждый продукт продается тем магазином, с которым флаг у него одинаковый. Как видите, и организовать такую связь, чтобы еще и понятно было что к чему, уже проблематично.
-Заменяем на две связи один-ко-многим. Магазины(название,флаг), Продукты(название, флаг), Отношения(флаг_магазина, флаг_продукта). Теперь в первых двух таблицах - только уникальные значения. Чем это все хорошо, вы узнаете, когда пойдет речь о целостности и нормальных формах. Пока что основывайтесь на ваших предположениях. позже мы вернемся к этому примеру и проверим их.
*Один-к-одному. Большого смысла в таких связях нет. как правило из таблиц которые так связаны можно сделать одну. Но вот когда столбцов в таблице слишком много, можно ей воспользоваться.
Целостность данных - их корректность, полнота и непротиворечивость. Со связями так же.
Что же нарушает целостность? Например, при связи один-ко-многим в подчиненной таблице может быть любое количество записей, соответствующих главной. Но в главной всегда должна быть только одна, не больше и не меньше, соответствующих записей. Так вот если в подчиненной таблице есть записи, значение первичного ключа которых не встречается во внешнем ключе главной таблице, вот тут и нарушается целостность (смотрим определение целостности и понимаем почему). Такие нарушения можно контролировать - если они произошли, достаточно проанализировать значения ключей. Средствами языка SQL это выполняется одним маленьким запросом SELECT * FROM sub_table t2 WHERE NOT EXISTS (SELECT * FROM primary_table t1 WHERE t1.foriegn_key = t2.primary_key). Из названия полей все ясно. Запрос выведет записи-сироты подчиненной таблицы. О языке SQL позже.
Так же просто и контролировать появление таких вещей, и об этом мы довольно подробно поговорим. Подумайте, удобно ли вам будет поддерживать целостность при связи многие-ко-многим. Отношения в базе данных приведены к нормальным формам, если данные, организованные таким образом не содержат избыточности и нет угроз их целостности. В примере с морковкой мы уже проводили нормализацию - процесс приведения к нормальным формам.
Какие же существуют нормальные формы? На практике обычно выделяют четыре:
*Первая нормальная форма - такая форма, что в ячейки таблицы хранится только одно значение, а не список значений. Т.е. в реляционных базах данных первая норм.форма всегда достигнута.
*Вторая н.ф. подразумевает отсутствие таких столбцов, которые зависят только от части составного первичного ключа и кроме этого таблица приведена уже к 1й н.ф.. Хороший пример дается в Википедии:
Пусть Начальник и Должность вместе образуют первичный ключ в такой таблице:
| Начальник | Должность | Зарплата | Наличие компьютера |
|---|---|---|---|
| Гришин | Кладовщик | 20000 | Нет |
| Васильев | Программист | 40000 | Есть |
| Васильев | Кладовщик | 25000 | Нет |
Зарплату сотруднику каждый начальник устанавливает сам, но ее границы зависят от должности. Наличие же компьютера у сотрудника зависит только от должности, то есть зависимость от первичного ключа не полная.
В результате приведения к 2NF получим две таблицы:
| Начальник | Должность | Зарплата |
|---|---|---|
| Гришин | Кладовщик | 20000 |
| Васильев | Программист | 40000 |
| Васильев | Кладовщик | 25000 |
Здесь первичный ключ, как и в исходной таблице, составной, но единственный не входящий в него атрибут Зарплата зависит теперь от всего ключа, то есть полно.
| Должность | Наличие компьютера |
|---|---|
| Кладовщик | Нет |
| Программист | Есть |
*В 3й н.ф. таблица находится, если она находится во второй н.ф. и ни один столбец не зависит от других столбцов, невходящих в первичный ключ.
*В 4й н.ф. таблица находится (ясно, что она находится и во всех предыдущих н.ф.), если ни одна строка таблицы своим существованием не обязывает к существованию другую строку в этой же таблице.
Вы столкнетесь позже с таблицей, которая не находится в 4й н.ф. и не должна в ней находиться.
Кроме таблиц, в которых хранится информация, СУБД предоставляет еще ряд объектов, помогающих обеспечивать и поддерживать целостность данных, удобный доступ к данным и прочие вещи.
Среди этих объектов Представления, Хранимые процедуры, Триггеры, Индексы. Другие объекты уже в разных СУБД могут как присутствовать, так и отсутствовать.
Представления (view) - динамическая таблица, содержащая в себе выборку из нескольких или более других таблиц. Изменение данных в таблицах, которые представлены в выборке, сразу же отражаются и в представлении.
Хранимые Процедуры (Stored Procedures) - последовательность SQL-инструкций, в том числе, содержащие инструкции на процедурных расширениях языка SQL, позволяющих организовывать такие управляющие структуры, как циклы, ветвления.
Использовать их можно как для выполнения часто встречающихся запросов (хранимая процедура выполняется быстрее, т.к. откомпилирована), так и для проведения каких-то вычислений и манипуляций с данными средствами СУБД.
Триггеры (Trigger) - это хранимые процедуры, вызывающиеся автоматически при наступлении какого-либо события. Они могут быть включены до и после удаления, добавления или обновления информации.
Например, перед удалением можно проверить, не останется ли в результате этого осиротевших записей в дочерней таблице и, если это так, запретить удаление. Либо можно после удаления автоматически удалить привязанные записи в другой таблице. Перед вставкой и обновлением также можно провести какие-нибудь проверки на то, что новая информация не повредит целостность данных. После вставки и обновления можно провести какие-либо действия исходя из вставленного набора.
Индексы (index) - это объект, благодаря которому производительность базы данных увеличивается во много раз. В очень много. Сейчас поймем как и почему.
Данные в таблицах хранятся в произвольном порядке и в больших количествах. Когда данные организованы так, поиск проводить можно только последовательным перебором. И если к столбце не привязан индекс, именно так поиск и происходит.
Индекс можно составлять из одного или нескольких столбцов. Иногда из выражений с использованием столбцов (сумма там, верхний регистр, конкатенация). Данные из которых составлен индекс, хранятся в виде дерева - такая структура позволяет использовать очень быстрые алгоритмы поиска. Каждый элемент индекса указывает на какую-либо строку таблицы.
Индексы могут быть уникальными, когда ни один элемент индекса не повторяется, и неуникальными. При помощи уникальных индексов можно осуществлять контроль повторяющихся значений. Неуникальные нужны просто для ускорения поиска или в связях таблиц. Первичный и внешний ключи таблицы всегда должны быть проиндексированы.
Компания ABC имеет 200 продуктовых магазинов в восьми городах. В каждом магазине есть разные отделы, такие как «Товары повседневного спроса», «Косметика», «Замороженные продукты», «Молочные продукты» и т.д. В каждом магазине на полках находится около 20 000 отдельных товаров. Отдельные продукты называются складскими единицами (SKU). Около 6 000 артикулов поступают от сторонних производителей и имеют штрих-коды, нанесенные на упаковку продукта. Эти штрих-коды называются универсальными кодами продукта (UPC). Данные собираются POS-системой в 2 местах: у входной двери для покупателей, и у задней двери, где поставщики осуществляют доставку.
В продуктовом магазине менеджмент занимается логистикой заказа, хранением и продажами продуктов. Также продолжают расти рекламные активности, такие как временные скидки, реклама в газетах и т.д.
Разработайте модель данных для анализа операций этой продуктовой сети.
Шаг 1. Сбор бизнес-требований
Руководство хочет лучше понимать покупки клиентов, фиксируемые POS-системой. Модель должна позволять анализировать, какие товары продаются, в каких магазинах, в какие дни и по каким акционным условиям. Кроме того, это складская среда, поэтому необходима размерная модель.
Шаг 2: Идентификация сущностей
В случае размерной модели нам необходимо идентифицировать наши факты и измерения. Перед разработкой модели необходимо уточнить объем требуемых данных. Согласно требованию, нам нужно видеть данные о конкретном продукте в определенном магазине в определенный день по определенной схеме продвижения. Это дает нам представление о необходимых сущностях:
Date Dimension
Product Dimension
Store Dimension
Promotion Dimension
Количество, которое необходимо рассчитать (например, объем продаж, прибыль и т.д), будет отражено в таблице с фактическими продажами.
Шаг 3: Концептуальная модель данных
Предварительная модель данных будет создана на основе информации, собранной о сущностях. В нашем случае она будет выглядеть так:
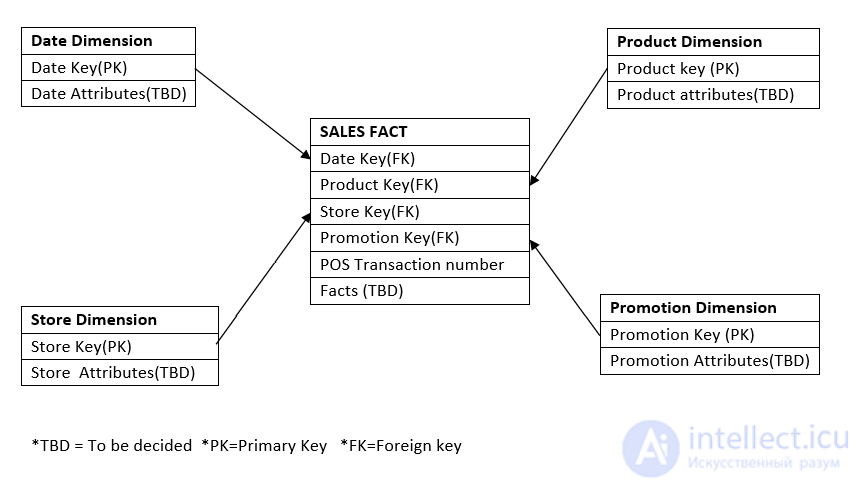
Шаг 4: Доработка атрибутов и создание логической модели данных
Теперь необходимо завершить работу над атрибутами для сущностей. В нашем случае дорабатываются следующие атрибуты:
Date Dimension:

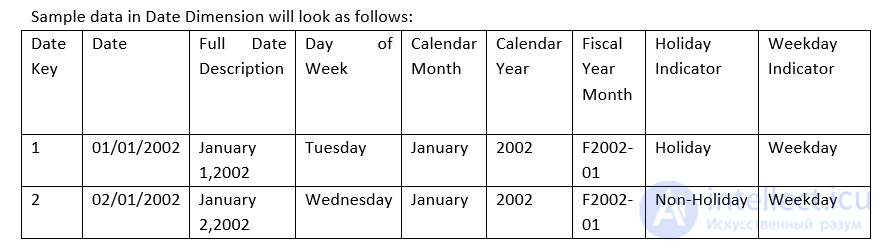
Product:

Store:

Promotion:
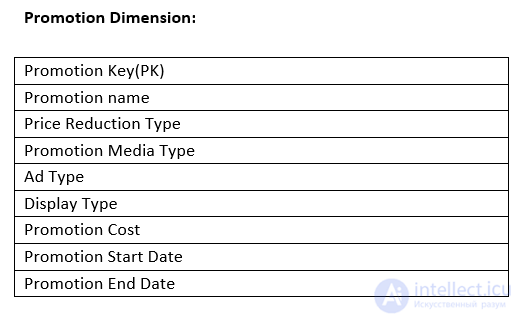
Sales Fact:
Номер транзакции.
Объем продаж (например, количество банок овощного супа с лапшой).
Сумма продаж в долларах: количество продаж * цена за единицу.
Стоимость в долларах: стоимость продукта, взимаемая поставщиком.
Сумма валовой прибыли в долларах: доход от продаж - затраты.
Логическая модель данных будет выглядеть так:
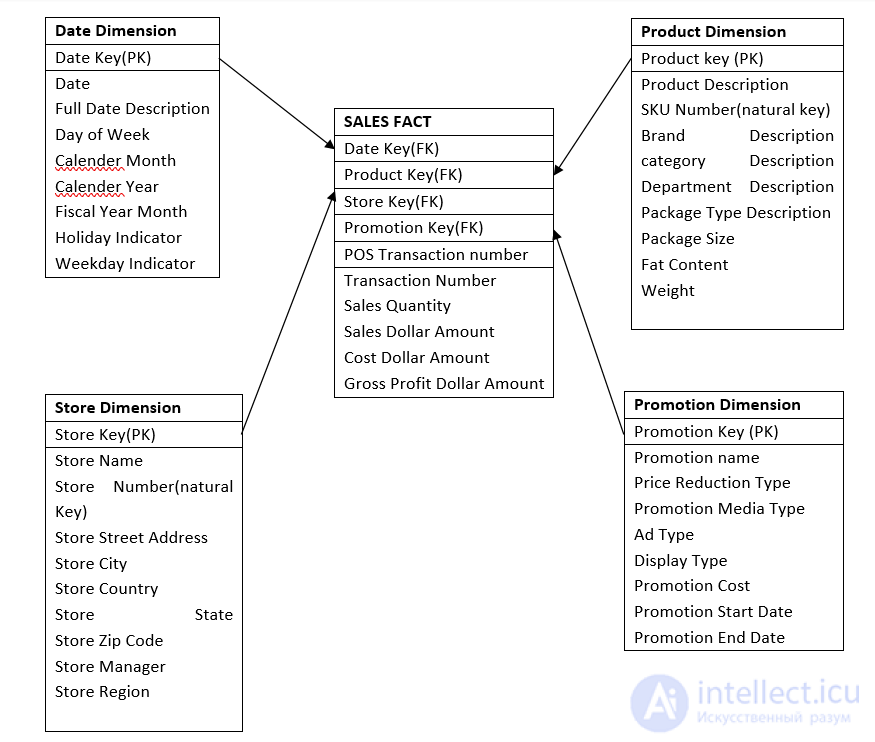
Шаг 5: Создание физических таблиц в базе данных
С помощью инструмента моделирования данных или с помощью кастомных скриптов теперь можно создавать физические таблицы в базе данных.
Думаю, теперь стало достаточно очевидно, что моделирование данных — одна из важнейших задач при разработке программного приложения. И оно закладывает основу для организации, хранения, извлечения и представления данных.
Раасмотрим их назначение и приведем несколько их примеров.
Case-средства применяются на этапах проектирования. Не только БД. В проектировании ПО, бизнес-планов, всего, где можно произвести декомпозицию задачи, выделить какой-то функционал.
Можно взять карандаш, бумажку, и нарисовать все там, а потом начать это реализовывать. Вот и первое неудобство. Пришла мысль получше, надо стереть, перерисовать. Не осталось места на бумажке, чтобы разместить тот или иной блок, ну или еще что-то там. Когда все, наконец, готово, надо реализовать это средствами выбранного языка. Во-первых, придется работать руками. Во-вторых, тут начнут возникать всякие неприятности: что-то не учел, что-то сложно реализуется выбранным языком, еще какая-нибудь гадость.
Вот, используя case-средства вы можете кроме того, что избавиться от проблем бумажки с карандашом, после завершения проектирования перегнать это в ту среду, в которой планируете работать дальше. Если это был макет БД, создать базу по этому макету в вашей СУБД. Конечно, доработать придется, но все же. Кроме того, в большинстве случаев, ошибки анализа вам будет проще обнаружить уже на этом этапе.
Приведу пару примеров: ER-Win, PB-Win, Rational Rose.
Вот и все, собственно.
Как всегда, начинать следует с постановки задачи и анализа. Не то чтобы уж все прям так официально, но вы должны иметь четкое представление того, что вам надо. И чем вернее это представление на ранних этапах, тем меньше потом придется менять.
Проанализировали, что-то у вас получилось, теперь нормализация. До максимально возможной нормальной формы. А заодно и именование таблиц и столбцов. как в программировании имена переменных, так и здесь. По имени должно быть ясно что куда.
На этих двух этапах можно применять к бумажку с карандашом, и CASE-средства.
Если в таблице получается составной первичный ключ или если первичный ключ - столбец со строковыми значениями, создайте по ним уникальный индекс, а для первичного ключа создайте еще один столбец. Числовой. Так проще организовывать связи и быстрее будут проходить выборки и каскадные операции
Создавайте индексы по тем полям, по которым планируется частый поиск.
Поддерживайте целостность данных триггерами и пользуйтесь хранимыми процедурами для изменения данных и доступа к ним.
В заключение, эта статья об проектирование баз данных подчеркивает важность того что вы тут, расширяете ваше сознание, знания, навыки и умения. Надеюсь, что теперь ты понял что такое проектирование баз данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL