Как нам сохранить полноту, точность и однозначность, не заплатив за это излишней спецификацией?
Лекция
Привет, Вы узнаете о том , что такое 6. Абстрактные типы данных (АТД), Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое 6. Абстрактные типы данных (АТД) , настоятельно рекомендую прочитать все из категории Структуры данных.
Если вам не терпится окунуться в глубины объектной технологии и подробно изучить множественное наследование, динамическое связывание и другие игрушки, то, на первый взгляд, эта лекция может показаться лишней задержкой на этом пути, поскольку она в основном посвящена изучению некоторых математических понятий (хотя вся используемая в ней математика элементарна).
Но так же, как самый талантливый музыкант извлечет пользу из изучения основ музыкальной теории, знания об абстрактных типах данных помогут вам понять и получить удовольствие от практики ОО-анализа, проектирования и программирования, хотя привлекательность этих понятий, возможно, уже проявилась и без помощи теории. Поскольку абстрактные типы данных являются теоретическим базисом для всего метода, следствия идей, вводимых в этой лекции, будут ощущаться во всей оставшейся части курса.
Более того, как будет видно в конце лекции, эти идеи выходят за рамки собственно ПО и приводят к принципам интеллектуальных исследований, которые, возможно, применимы и в других дисциплинах.
Это открыло мне глаза, я начал понимать, что значит использовать инструмент, называемый алгеброй. Черт возьми, никто никогда не говорил мне ничего подобного раньше. Мсье Дюпюи [учитель математики] произносил напыщенные фразы об этом предмете, но ни разу не сказал этих простых слов: это разделение труда, которое, как и всякое другое разделение труда производит чудеса и позволяет уму сконцентрировать все свои силы только на одной стороне объектов, только на одном из их качеств.
Насколько другим это предстало бы перед нами, если бы мсье Дюпюи сказал нам: "Этот сыр мягкий или твердый, он белый, он синий, он старый, он молодой, он твой, он мой, он легкий или он тяжелый. Из всех его многочисленных качеств давайте рассматривать только вес. Каким ни был этот вес, давайте назовем его A. А теперь, не думая больше о весе, давайте применять к А все, что мы знаем о количестве."
Такая простая вещь, но до сих пор никто не говорил нам о ней в этой отдаленной провинции...
Стендаль, "Жизнь Анри Брюлара"
Что касается абстракции, то она состоит в отделении ощутимых свойств тел либо от других их свойств, либо от самих тел, которые ими обладают. Когда это отделение делается неудачно или неверно применяется, возникают ошибки, что возможно как в философских вопросах, так и в физических и математических вопросах. Прямой путь к ошибке в философии - недостаточно упростить изучаемые объекты, и верный путь к получению ошибочных результатов в физике и математике - это считать объекты менее сложными, чем они есть на самом деле.
Дени Дидро, "Письмо слепого на благо тех, кто может видеть"
Чтобы получить надлежащие описания объектов, наш метод должен удовлетворять трем условиям:
[x]. Описания должны быть точными и недвусмысленными.
[x]. Они должны быть полными - или, по крайней мере, иметь в каждом конкретном случае нужную нам полноту (некоторые детали можно намеренно опускать).
[x]. Они не должны быть излишне специфицированы.
Последний пункт делает ответ нетривиальным. В конце концов, легко сделать описание точным, недвусмысленным и полным, если мы готовы "выдать все секреты", указав все детали объектного представления. Но такое описание, как правило, будет включать чересчур много информации для авторов программ, которым требуется доступ к таким объектам.
Это замечания похожи на комментарии, которые привели к понятию скрытия информации. Там дело было в том, что, предоставляя в качестве первичного источника информации исходный код модуля (элементы, связанные с реализацией) авторам клиентских программ, зависящих от этого модуля, мы можем окунуть их в поток деталей, который помешает им сосредоточиться на своей собственной работе и затруднит перспективу развития проекта. Здесь нас ожидает та же опасность, что и в случае, когда мы позволяем модулям использовать некоторую структуру данных на основании информации, которая относится к представлению этой структуры, а не к ее существенным свойствам.
Чтобы лучше понять всю важность описаний абстрактных типов данных, исследуем глубже потенциальные последствия использования физической реализации в качестве основы описания объектов.
Удобным и хорошо изученным примером является описание объектов типа стек. Объект стек служит для того, чтобы накапливать и доставать другие объекты в режиме "последним пришел - первым ушел" ("LIFO"), элемент, вставленный в стек последним, будет извлечен из него первым. Стек повсеместно используется в информатике и во многих программных системах, в частности, компиляторы и интерпретаторы усыпаны разными видами стеков.
| Надо сказать, что стеки присутствуют в дидактических представлениях абстрактных типов данных в таком большом количестве, что Э. Дейкстра как-то остроумно заметил, что "абстрактные типы данных являются прекрасной теорией, целью которой является описание стеков". Совершенно справедливо. Но в следующих лекциях курса понятие абстрактных типов данных так часто применяется в гораздо более сложных случаях, что я не чувствую стыда, начиная рассмотрение с этого ключевого примера. Он является простейшим из известных мне примеров, содержащих в себе почти все важные идеи абстрактных типов данных. |
Существует несколько физических представлений стеков:

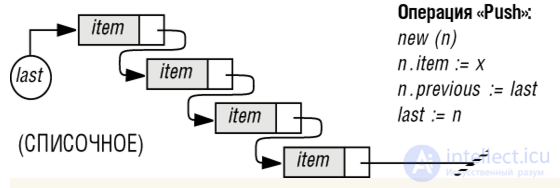
Рис. 6.1. Три возможных представления стеков
Этот рисунок иллюстрирует три наиболее популярных представления стеков. Для удобства ссылок дадим каждому из них свое имя:
[x]. МАССИВ_ВВЕРХ: представляет стек посредством массива representation и целого числа count, с диапазоном значений от 0 (для пустого стека) до capacity - размера массива representation, элементы стека хранятся в массиве и индексируются от 1 до count.
[x]. МАССИВ_ВНИЗ: похож на МАССИВ_ВВЕРХ, но элементы помещаются в конец стека, а не в начало. Здесь число, называемое free, является индексом верхней свободной позиции в стеке или 0, если все позиции в массиве заняты и изменяется в диапазоне от capacity для пустого стека до 0 для заполненного. Элементы стека хранятся в массиве и индексируются от capacity до free+1.
[x]. СПИСОЧНОЕ: при списочном представлении каждый элемент стека хранится в ячейке с двумя полями: item, содержащем сам элемент, и previous, содержащем указатель на ячейку с предыдущим элементом. Для этого представления нужен также указатель last на ячейку, содержащую вершину стека.
Рядом с каждым представлением на рисунке приведен фрагмент программы (в духе Паскаля), с соответствующей реализацией основной стековой операции: втолкнуть элемент x на вершину стека (push).
Для представлений с помощью массивов МАССИВ_ВВЕРХ и МАССИВ_ВНИЗ команды увеличивают или уменьшают указатель на вершину (count или free) и присваивают x соответствующему элементу массива. Так как эти представления поддерживают стеки с не более чем capacity элементами, то корректные реализации должны содержать защищающие от переполнения тесты соответствующего вида:
if count " capacity then ...
if free " 0 then ...,
(на рисунке они для простоты опущены).
Для представления СПИСОЧНОЕ вталкивание элемента требует четырех действий:
[x]. создания новой ячейки n (здесь оно выполняется с помощью процедуры Паскаля new, которая выделяет память для нового объекта);
[x]. присваивания x полю item новой ячейки;
[x]. присоединения новой ячейки к вершине стека путем присвоения ее полю previous текущего значения указателя last;
[x]. изменения last так, чтобы он ссылался на только что созданную ячейку.
Хотя эти представления встречаются чаще всего, существует и много других представлений стеков. Например, если вам нужны два стека с однотипными элементами и память для их представления ограничена, то можно использовать один массив с двумя метками вершин count как в представлении МАССИВ_ВВЕРХ и free как в МАССИВ_ВНИЗ. При этом один стек будет расти вверх, а другой - вниз. Условием полного заполнения этого представления является равенство count= free.
Преимущество такого представления состоит в уменьшении риска переполнить память: при двух массивах размера n, представляющих стеки способом МАССИВ_ВВЕРХ или МАССИВ_ВНИЗ, память исчерпается, как только любой из стеков достигнет n элементов. А в случае одного массива размера 2n, содержащего два стека лицом к лицу, работа продолжается до тех пор, пока их общая длина не превысит 2n, что менее вероятно, если стеки растут независимо друг от друга. (Для любых переменных p и q, max (p +q) "= max (p) + max (q)).
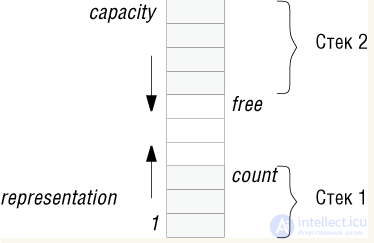
Рис. 6.2. Представление двух стеков лицом к лицу
Каждое из этих и другие возможные представления полезны в разных ситуациях. Выбор одного из них в качестве эталона для определения стека был бы типичным примером излишней спецификации. Почему мы должны, например, предпочесть МАССИВ_ВВЕРХ представлению СПИСОЧНОЕ? Большинство видимых свойств представления МАССИВ_ВВЕРХ - массив, число count, верхняя граница - несущественны для понимания представляемой ими структуры.
Почему так плохо использовать конкретное представление в качестве спецификации?
Можно напомнить результаты изучения Линцем (Lientz) и Свенсоном (Swanson) стоимости сопровождения. Было установлено, что более 17% стоимости ПО приходится на изменения в форматах данных. Ясно, что метод, который ставит анализ и проектирование в зависимость от физического представления структур данных, не обеспечит разработку достаточно гибкого ПО.
Поэтому при использовании объектов или типов объектов в качестве основы для архитектуры системы требуется найти лучший способ описания, чем конкретное представление.
Как бы стеки не заставили нас забыть, что кроме излюбленных специалистами по информатике примеров имеются структуры данных, тесно связанные с объектами реальной жизни. Вот забавный пример, взятый из почты форума Риски (Risks) (группа новостей Usenet comp.risks), который иллюстрирует опасности взгляда на данные, чересчур сильно зависящего от их конкретных свойств. Некто Даррелл Д. Е. Лонг, которого родители наградили двумя инициалами второго имени, получил кредитную карточку, в которой был указан лишь первый из них "Д". После обращения к менеджеру фирмы TRW ему была прислана другая карточка, в которой был лишь второй инициал "Е". Он пишет:
| Я позвонил в бюро выдачи кредитов, и оказалось, что, по-видимому, программист, который проектировал базу данных TRW, решил, что каждому хорошему американцу пожаловано второе имя лишь с одним инициалом. Как вежливо объяснила мне по телефону дама: "Они выделили в системе достаточно мегабайт (sic) только для одного инициала второго имени и это чрезвычайно трудно изменить". |
Кроме типичного примера технократического оправдания ("мегабайты"), урок в этом случае заключается в том, что нужно избегать ориентации программы на физические свойства данных.
Автор приведенного выше письма, в основном, беспокоился из-за ненужной почты, что неприятно, но не смертельно, архивы форума Риски (Risks) полны случаями вызванной компьютерами неразберихи с гораздо более серьезными последствиями. Уже отмечавшаяся выше "проблема миллениума" является другим примером опасности, возникающей при организации доступа к данным на основе их физического представления, ее последствия обошлись в сотни миллионов долларов.
Как нам сохранить полноту, точность и однозначность, не заплатив за это излишней спецификацией?
Представления стека при всех их различиях объединяет то, что они описывают структуру "хранения" (т.е. структуру, используемую для хранения других объектов), к которой применяются определенные операции, обладающие определенными свойствами. Сосредоточившись не на выборе конкретного представления структуры, а на этих операциях и свойствах, можно получить достаточно абстрактное, но, тем не менее, полезное описание понятия стек.
Обычно для стеков рассматриваются следующие операции:
[x]. Команда вталкивания некоторого элемента на вершину стека. Назовем эту операцию put.
[x]. Команда удаления верхнего элемента стека. Назовем ее remove.
[x]. Запрос элемента, находящегося на вершине стека (если стек не пуст). Назовем его item.
[x]. Запрос на проверку пустоты стека. (Он позволит клиентам заранее проверить возможность операций remove и item.)
Кроме того, нам понадобится операция-конструктор для создания пустого стека. Назовем ее make.
| Две вещи заслуживают более подробных объяснений далее в этой лекции. Во-первых, могут показаться необычными имена операций, Давайте пока считать, что put означает push, remove означает pop, а item означает top. Во-вторых, операции разбиты на три категории: конструкторы, создающие объекты, запросы, возвращающие информацию об объектах, и команды, которые могут изменять объекты. Эта классификация также требует дополнительных объяснений. |
При традиционном взгляде на структуры данных мы рассматривали бы понятие стека, заданное с помощью некоторого объявления данных, соответствующего одному из вышеуказанных представлений, например для представления МАССИВ_ВВЕРХ. В стиле Паскаля это выглядит как
count: INTEGER
representation: array [1 .. capacity] of STACK_ELEMENT_TYPE
где константа capacity - это максимальное число элементов в стеке. Тогда put, remove, item, empty и make будут подпрограммами, которые работают на структурах, определенных этим объявлением объектов.
Чтобы сделать главный шаг в направлении абстракции данных, нужно стать на противоположную точку зрения: забыть на некоторое время о конкретном представлении и взять в качестве определения структуры данных операции сами по себе. Иначе говоря, стек - это любая структура, к которой клиенты могут применять перечисленные выше операции.
Только что намеченный метод описания структур данных выглядит довольно эгоистичным подходом в мире структур данных. Нас не столько интересует то, что они собой представляют внутренне, как то, что они могут друг другу предложить. В этом мы похожи на экономиста - пылкого приверженца теорий приоритета производства и невидимой руки, воспитанного в духе школы "пусть-все-решит-свободный-рынок". Мир объектов (а, следовательно, и архитектуры ПО) будет миром взаимодействующих объектов, общающихся на основе точно определенных протоколов.
Аналогия с экономикой будет сопровождать наше изложение и дальше, агенты - программные модули - называются поставщиками и клиентами, протоколы будут называться контрактами, и большая часть ОО-разработки, на самом деле, может рассматриваться как "Проектирование по Контракту" - это заголовок одной из следующих лекций.
Не следует чересчур увлекаться этой аналогией (как и всякой другой): эта работа не учебник по экономике и она не содержит даже намеков на точку зрения автора в этой области. Сейчас нам достаточно отметить поразительные аналогии подхода абстрактных типов данных с некоторыми теориями о взаимодействии агентов-людей.
Давайте убедимся в том что, приведенная выше спецификация и ее детали являются достаточно удобными. Для того, кто раньше сталкивался со стеками, избранные при обсуждении стека имена операций могут показаться странными или даже шокирующими. Каждому уважающему себя специалисту по информатике операции со стеком известны под другими именами:
| Стандартное имя операции над стеком | Имя, используемое здесь |
| Push (втолкнуть) | Put (поместить) |
| Pop (вытолкнуть) | Remove (удалить) |
| Top (вершина) | Item (элемент) |
| New (новый) | Make (создать) |
Таблица 6.1.Имена операций над стеком
Зачем использовать терминологию, отличающуюся от общепринятой? Причина - в желании достичь более высокого уровня понимания структур данных - особенно "контейнеров", которые используются для хранения объектов.
Стеки это просто один из видов контейнеров, точнее они относятся к категории контейнеров, которые можно назвать распределителями. Распределитель предоставляет своим клиентам механизм для хранения (put), извлечения (item) и удаления (remove) объектов, но не дает им возможности управлять тем, какой объект будет извлекаться или удаляться. Например, метод доступа LIFO, используемый в стеках, позволяет извлекать или удалять только тот элемент, который был сохранен последним. Другой вид распределителей - очередь, которая использует метод доступа "первым в, первым из" (FIFO): элементы добавляются в один конец очереди, а извлекаются и удаляются - с другого конца. Пример контейнера, не являющегося распределителем, - это массив, в нем вы сами выбираете целочисленные номера позиций, в которые вставляются или из которых извлекаются объекты.
Поскольку схожесть разных видов контейнеров (распределителей, массивов и т.п.) более важна, чем различия между тем, как они хранят, извлекают или удаляют объекты, эта книга твердо придерживается стандартизованной терминологии, которая сглаживает различия между вариантами структур данных и, наоборот, подчеркивает их общность. Поэтому базисная операция извлечения элемента будет всегда называться item, базисная операция удаления элемента будет всегда называться remove, и т.д.
Вопросы именования могут вначале показаться поверхностными - "косметическими", как иногда говорят программисты. Но не забывайте, что одна из наших конечных целей - создать основу для мощных, профессиональных библиотек программных компонент, допускающих повторное использование. Такие библиотеки будут содержать десятки тысяч доступных операций. Без их систематической и ясной номенклатуры и разработчики, и пользователи этих библиотек быстро потонут в потоке специальных и несравнимых имен, что создаст сильное (и не имеющее оправдания) препятствие к масштабному повторному использованию.
Таким образом, вопросы именования - это не косметика. Хорошее, допускающее повторное использование ПО - это ПО, которое предоставляет пользователям соответствующий набор функций и предоставляет их под правильными именами.
Имена, использованные здесь для операций стеков, являются частью соглашений об именовании, которых мы придерживаемся во всей книге.
В разработке программного обеспечения, как и в других научных и технических дисциплинах, плодотворная идея после того, как ее раскрыли, может показаться очевидной, даже если потребовалось много времени, чтобы она возникла. Сначала зачастую появляются плохие и запутанные (что часто одно и то же) идеи, и требуется время, чтобы более простые и элегантные заняли их место.
Это замечание справедливо и для абстрактных типов данных. Хотя хорошие разработчики ПО всегда с пользой применяли абстракцию (вследствие хорошего образования или просто интуитивно), многие из существующих ныне систем были разработаны без учета этой цели.
В предыдущих разделах нам удалось сделать первые шаги по дороге к АТД. Их достаточно для понимания того, что программа, написанная в соответствии с самыми элементарными представлениями об абстракции данных, должна была бы рассматривать MAIL_MESSAGE (ПОЧТОВОЕ_СООБЩЕНИЕ) как точно определенное абстрактное понятие. Одной из операций сообщения мог быть запрос, называемый, например, sender (отправитель), возвращающий информацию об отправителе сообщения. Любой элемент почтовой программы, которому была бы нужна эта информация, получал бы ее только через этот запрос sender. Если бы почтовая программа была разработана в соответствии с этим, кажущимся очевидным, принципом, то для моего небольшого упражнения достаточно было бы изменить только код запроса sender. Более того, весьма вероятно, что в этом случае программа предоставляла бы также и операцию set_sender (установить_отправителя), которая позволила бы выполнить требуемую работу еще проще.
Отметим, что рассматриваемая почтовая программа использовалась весьма успешно. Но она является типичным представителем нынешнего стандарта в индустрии ПО. До тех пор, пока мы не выйдем далеко за пределы этого стандарта фраза "проектирование программного обеспечения" останется примером принятия желаемого за действительное.
Представленный выше беглый набросок абстракции данных слишком неформален, чтобы его можно было постоянно использовать. Вернемся к нашему главному примеру. Стек, как мы это поняли, должен определяться в терминах применимых к нему операций, но тогда нам нужно определить эти операции!
Приведенные содержательные описания явно недостаточны - put вталкивает элемент на "вершину" стека, remove выталкивает элемент, находящийся на вершине. Нам нужно точно знать, как клиенты могут использовать эти операции и что они для этого должны делать.
Спецификация АТД предоставит эту информацию. Она состоит из четырех разделов, разъясняемых в следующих разделах:
Для спецификации АТД в этих разделах будут использоваться простая математическая нотация.
| Эту нотацию - математический формализм - не надо путать с программной нотацией в остальной части книги, даже если для согласования она использует тот же стиль синтаксиса. У нее нет специального имени, и она не является нотацией языка программирования. Она могла бы послужить отправной точкой для формального языка спецификаций, но мы удовлетворимся использованием не требующих объяснения соглашений для однозначной спецификации АТД. |
В разделе ТИПЫ указываются специфицируемые типы. В общем случае, может оказаться удобным определять одновременно несколько АТД, хотя в нашем примере имеется лишь один тип STACK(СТЕК). Между прочим, что такое тип? Ответ на этот вопрос объединит все положения, развиваемые далее в этой лекции: тип - это совокупность объектов, характеризуемая функциями, аксиомами и предусловиями. Не будет большой ошибкой рассматривать пока тип как множество объектов в математическом смысле слова "множество" - тип STACK как множество всех возможных стеков, тип INTEGER как множество всех целых чисел и т.д.
Однако при этом не должно быть никакой путаницы: АТД, такой как STACK, - это не объект (один конкретный стек), а совокупность объектов (множество всех стеков). Напомним, в чем состоит наша главная цель: найти подходящую основу для модулей наших программных систем. Очевидно, не имеет смысла делать основой для модуля один конкретный объект - один стек, один самолет, один счет в банке. ОО-проектирование даст нам возможность строить модули, отражающие свойства всех стеков, всех самолетов, всех банковских счетов, или, по крайней мере, значительной их части.
Объект, принадлежащий множеству объектов, описываемых спецификацией АТД, называется экземпляром этого АТД. Например, конкретный стек, обладающий свойствами абстрактного типа данных STACK, будет экземпляром АТД STACK. Понятие экземпляра проходит через все ОО-проектирование и программирование, и будет играть важную роль в объяснении поведения программ во время исполнения.
В разделе ТИПЫ просто перечисляются типы, вводимые в данной спецификации. Здесь:
Типы
[x]. STACK[G]
Таким образом, наша спецификация относится к одному абстрактному типу данных - STACK, задающему стеки объектов произвольного типа G.
В описании STACK[G] именем G обозначен произвольный, не определяемый тип. G называется формальным родовым параметром для типов элементов АТД STACK, а сам STACK называется родовым или универсальным АТД. Механизм, допускающий такие параметризованные спецификации, известен как универсализация, мы уже сталкивались с аналогичным понятием в обзоре конструкций пакетов.
Можно писать спецификации АТД без параметризации, но ценой будут неоправданные повторения. Кроме того, возможность повторного использования желательна не только для программ, но и для спецификаций! Благодаря механизму универсализации, можно выполнять параметризацию типов в явном виде, выбрав для параметра некоторое произвольное имя (здесь - G), представляющее переменную для типа элементов стека.
В результате такой АТД как STACK - это не просто тип, а скорее образец типа. Для получения непосредственно используемого типа стека нужно определить тип элементов стека, например ACCOUNT, и передать его в качестве фактического родового параметра, соответствующего формальному параметру G. Поэтому, хотя сам по себе STACK это образец типа, обозначение STACK[ACCOUNT] задает полностью определенный тип. Про такой тип, полученный с помощью передачи фактических параметров типов в родовой тип, говорят, что он порожден из общего по образцу.
Эти понятия можно применять рекурсивно: каждый тип должен, по крайней мере, в принципе, иметь спецификацию АТД, поэтому можно и тип ACCOUNT считать абстрактным типом данных. Кроме того, тип, подставляемый в качестве фактического параметра типа в STACK (для получения типа, порожденного по образцу) может и сам быть порожденным по образцу. Например, можно вполне корректно использовать обозначение STACK[STACK [ACCOUNT]] для определения соответствующего абстрактного типа данных: элементами этого типа являются стеки, элементами которых, в свою очередь, являются банковские счета.
Как показывает этот пример, предыдущее определение "экземпляра" нуждается в некоторой модификации. Строго говоря, конкретный стек является экземпляром не типа STACK (который, как мы заметили, является скорее образцом типа, а не типом), а некоторого типа, порожденного типом STACK, например, образцом типа STACK[ACCOUNT]. Тем не менее, нам удобно и далее говорить об экземплярах типа S и других образцов типов, понимая при этом, что речь идет об экземплярах порожденных ими типов.
Аналогично, не очень правильно говорить о типе STACK как об АТД: правильный термин в этом случае - "образец АТД". Но для простоты в данном обсуждении мы будем и далее, если это не приведет к путанице, опускать
продолжение следует...
Часть 1 6. Абстрактные типы данных (АТД)
Часть 2 Перечисление функций - 6. Абстрактные типы данных (АТД)
Часть 3 Назад к тому, с чего начали? - 6. Абстрактные типы
Часть 4 Правило канонического сокращения - 6. Абстрактные типы данных (АТД)
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Структуры данных
Термины: Структуры данных