Лекция
Привет, сегодня поговорим про структура базы данных, обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое структура базы данных, иерархическая структура базы данных, сетевая структура базы данных, реляционная структура базы данных, объектно-ориентированная структура базы данных, гибридная структура базы данных, иерархическая базы данных, сетевая базы данных, реляционная базы данных, объектно-ориентированная базы данных, гибридная базы данных, многомерная модель , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
Создавая базу данных, мы стремимся упорядочить информацию по различным признакам для того, чтобы потом извлекать из нее необходимые нам данные в любом сочетании. Сделать это возможно, только если данные структурированы. Структурирование - это набор соглашений о способах представления данных. Понятно, что структурировать информацию можно по-разному. В зависимости от структуры различают иерархическую, сетевую, реляционную, объектно-ориентированную и гибридную модели баз данных. Самой популярной на сегодняшний день является реляционная структура .

Классификация баз данных в зависимости от использования моделей данных. рассмотри их подробнее
Иерархическая модель представляет собой ориентированный граф (перевернутое дерево) объектов, связанных иерархическими отношениями
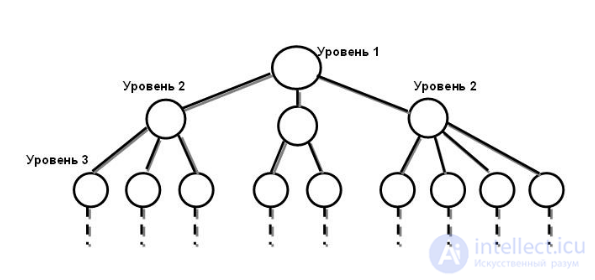
К основным понятиям иерархической модели относятся: уровень, элемент (узел), связь
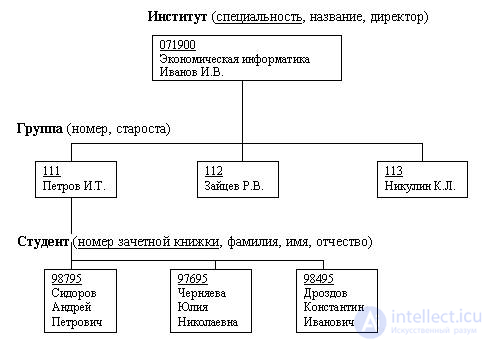
Это древовидная структура представления информации. Ее особенность в том, что каждый узел на более низком уровне имеет связь только с одним узлом на более высоком уровне. Посмотрим, например, на фрагмент иерархической структуры базы данных "Институт":
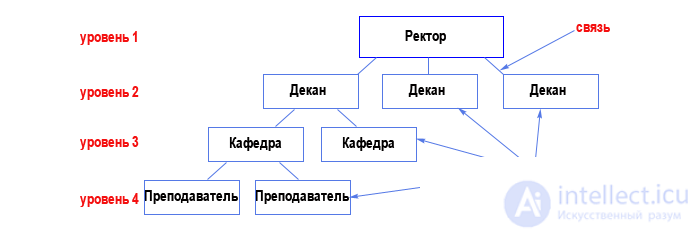
Из структуры понятно, что на одной кафедре может работать несколько преподавателей. Такая связь называется "один ко многим" (одна кафедра - много преподавателей). Но если мы попытаемся добавить в эту структуру группы студентов, то нам понадобится связь "многие ко многим":

(один преподаватель может работать со многими группами, а одна группа может учиться у многих преподавателей), а такой связи в иерархической структуре быть не может (т.к. связь может быть только с одним узлом на более высоком уровне). Это основной недостаток подобной структуры базы данных.
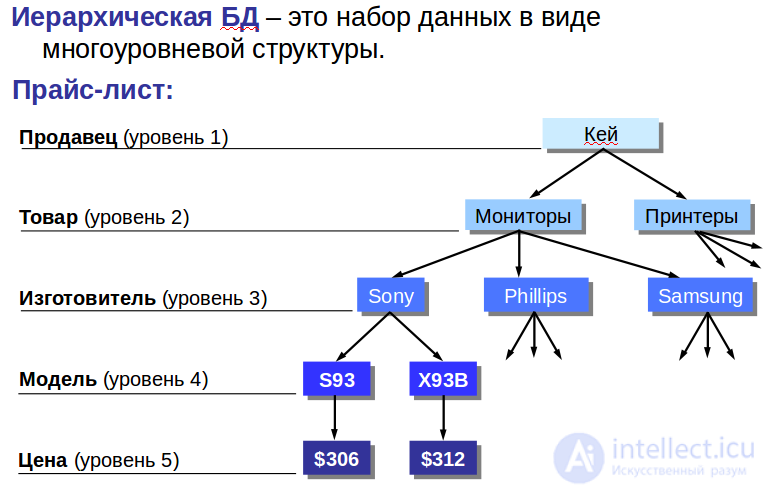
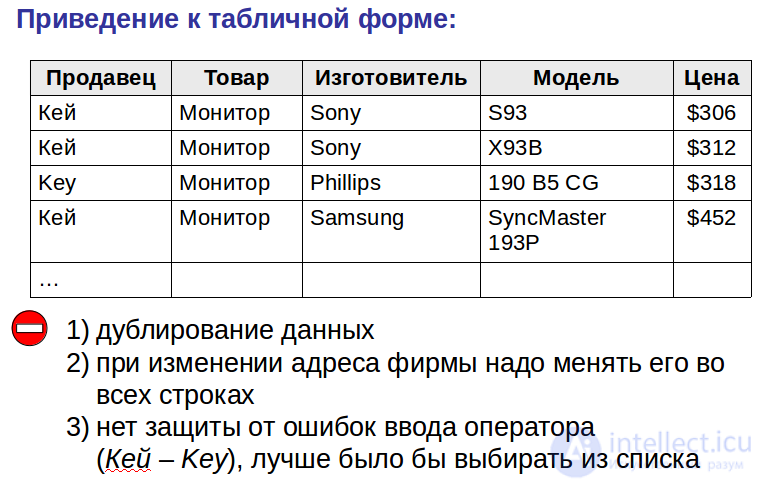
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных.
Как и сетевая, иерархическая модель данных базируется на графовой форме построения данных, и на концептуальном уровне она является просто частным случаем сетевой модели данных. В иерархической модели данных вершине графа соответствует тип сегмента или просто сегмент, а дугам — типы связей предок — потомок. В иерархических структуpax сегмент — потомок должен иметь в точности одного предка.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как ее логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры типичных операторов поиска данных с возможностью модификации:
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
СУБД, основанные на иерархической модели данных: IMS, PC/Focus, Team-Up, Data Edge, Ока, ИНЭС, МИРИС.
Примерами баз данных с иерархической моделью являются :
В сетевой модели при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом, связанных иерархическими отношениями.

По сути, это расширение иерархической структуры. Все то же самое, но существует связь "многие ко многим". Сетевая структура базы данных позволяет нам добавить группы в наш пример. Недостатком сетевой модели является сложность разработки серьезных приложений.
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:

Рис Пример сетевой модели данных
Примерный набор операций манипулирования данными:
Имеется (необязательная) возможность потребовать для конкретного типа связи отсутствие потомков, не участвующих ни в одном экземпляре этого типа связи (как в иерархической модели).
Недостатком сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе. Поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
Сетевая модель была одним из первых подходов, использовавшимся при создании баз данных в конце 50-х — начале 60-х годов. Активным пропагандистом этой модели был Чарльз Бахман. Идеи Бахмана послужили основой для разработки стандартной сетевой модели под эгидой организации CODASYL. После публикации отчетов рабочей группы этой организации в 1969, 1971 и 1973 годах многие компании привели свои сетевые базы данных более-менее в соответствие со стандартами CODASYL. До середины 70-х годов главным конкурентом сетевых баз данных была иерархическая модель данных, представленная ведущим продуктом компании IBM в области баз данных — IBM IMS .
В конце 60-х годов Эдгаром Коддом была предложена реляционная модель данных и после долгих и упорных споров с Бахманом реляционная модель приобрела большую популярность и теперь является доминирующей на рынке СУБД.
Сетевая СУБД — СУБД, построенная на основе сетевой модели данных.
К основным понятиям сетевой модели базы данных относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Несмотря на то, что эта модель решает некоторые проблемы, связанные с иерархической моделью, выполнение простых запросов остается достаточно сложным процессом.
Также, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
СУБД, основанные на сетевой модели данных: IDMS, db_Vista III, СЕТЬ, СЕТОР, КОМПАС
Список самых значимых сетевых СУБД на 1978 год :
Другие подобные СУБД:
Реляционная модель представляет собой совокупность двумерных таблиц, связанных отношениями.
Все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Подробно об этом мы будем говорить в следующих уроках, здесь же хочется отметить, что эта структура стала настоящим прорывом в развитии баз данных.
К основным понятиям реляционной модели относятся: тип данных, домен, атрибут, кортеж, отношение, первичный ключ

Рис элементы реляционной модели
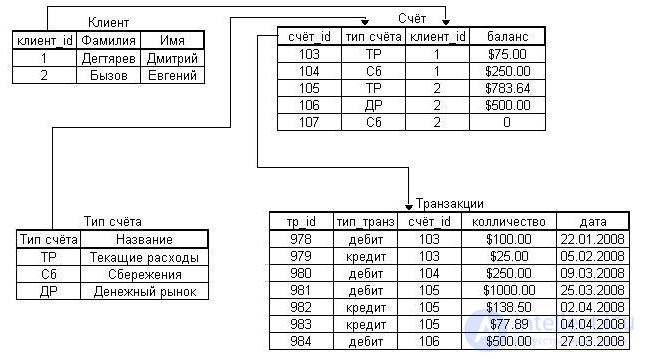
Рис пример реляционной модели
Достоинства реляционной модели данных
Недостатки реляционной модели данных
СУБД, основанные на реляционной модели данных:
Clipper, dBase, Paradox, FoxPro, Access, Oracle, Mysql, Postgress
В объектно-ориентированных базах данных данные хранятся в виде объектов, что очень удобно. Но на сегодняшний день такие БД еще распространенны, т.к. уступают в производительности реляционным.
Гибридные БД совмещают в себе возможности реляционных и объектно-ориентированных, поэтому их часто называют объектно-реляционными. Примером такой СУБД является Oracle, начиная с восьмой версии.
Несомненно, такие БД будут развиваться в будущем, но пока первенство остается за реляционными структурами. Поэтому именно их мы и будем изучать в последующих уроках.
ООМ графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом или
типом, конструируемым пользователем (определяется как Сlass).
К основным понятиям объектно-ориентированной модели относятся: объект, линии поведения, сообщения, класс, отношения.
Объекты являются моделями, очень близкими по своим свойствам и характеристикам объектам реального мира.
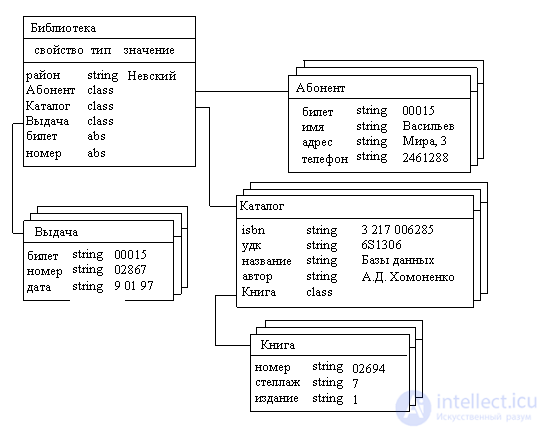
Объекты характеризуются свойствами, определяющими их состояние, и методами, определяющими их поведение. Объекты взаимодействуют друг с
другом путем передачи сообщений, активизирующих их линии поведения.
Компоненты объектно-ориентированной модели:
Первые публикации об объектно-ориентированных базах данных появились в середине 80-х годов.
Объектно-ориентированные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
В манифесте ООБД предлагаются обязательные характеристики, которым должна отвечать любая ООБД. Их выбор основан на 2 критериях: система должна быть объектно-ориентированной и представлять собой базу данных.
Обязательные характеристики
Необязательные характеристики:
Открытые характеристики:
Результатом совмещения возможностей (особенностей) баз данных и возможностей объектно-ориентированных языков программирования являются Объектно-ориентированные системы управления базами данных (ООСУБД). ООСУБД позволяет работать с объектами баз данных так же, как с объектами в программировании в ООЯП. ООСУБД расширяет языки программирования, прозрачно вводя долговременные данные, управление параллелизмом, восстановление данных, ассоциированные запросы и другие возможности.
Некоторые объектно-ориентированные базы данных разработаны для плотного взаимодействия с такими объектно-ориентированными языками программирования, как Python, Java, C#, Visual Basic .NET, C++, Objective-C и Smalltalk; другие имеют свои собственные языки программирования. ООСУБД используют точно такую же модель, что и объектно-ориентированные языки программирования.
СУБД должна обеспечивать:
Реализация объектно-ориентированного подхода
Реализация объектно-ориентированного подхода характеризуется следующими ключевыми свойствами объектов:
Достоинства объектно-ориентированной модели данных:
Недостатки объектно-ориентированной модели данных:
СУБД, основанные на объектно-ориентированной модели данных:
POET, Jasmine, Versant, Iris, Orion, Postgres.
Объектно-реляционная СУБД (ОРСУБД) — реляционная СУБД (РСУБД), поддерживающая некоторые технологии, присущие объектно-ориентированным СУБД и реализующие объектно-ориентированный подход: объекты, классы и наследование реализованы в структуре баз данных и языке запросов.
Объектно-реляционными СУБД являются, например, широко известные Oracle Database, Informix, DB2, PostgreSQL.
Хранилище данных: предметно-ориентированный, интегрированный, неизменяемый и поддерживающий хронологию набор данных, предназначенный для обеспечения принятия управленческих решений.
Основные модели представления данных в хранилищах данных:
В основе реляционных хранилищ данных лежит разделение данных на две группы – измерения и факты.
Измерения – это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе.
Примеры измерений: наименования товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т. д.
Измерения качественно описывают исследуемый бизнес-процесс.
Факты – это непрерывные по своему характеру данные (могут принимать бесконечное множество значений).
Примеры фактов: цена товара или изделия, их количество, сумма продаж или закупок, зарплата сотрудников, сумма кредита и т. д.
Факты количественно описывают бизнес-процесс.
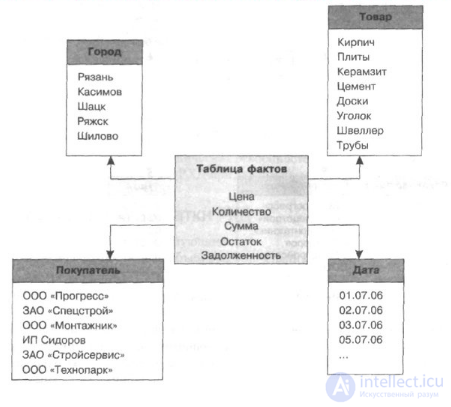
рис Схема построения реляционного хранилища данных «звезда»
Центральной является таблица фактов (Fact table), с которой связаны таблицы измерений (Dimension tables).
Преимущества схемы «звезда»:
Недостатки схемы «звезда»:
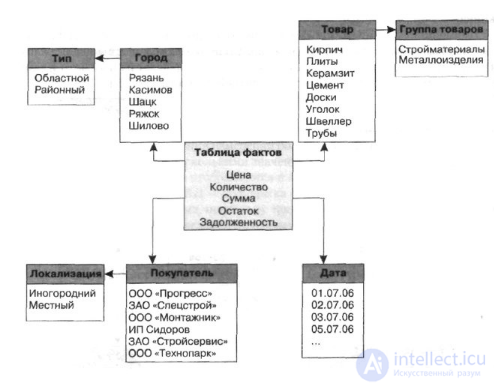
Рис Схема построения реляционного хранилища данных «снежинка» (модификация схемы «звезда»)
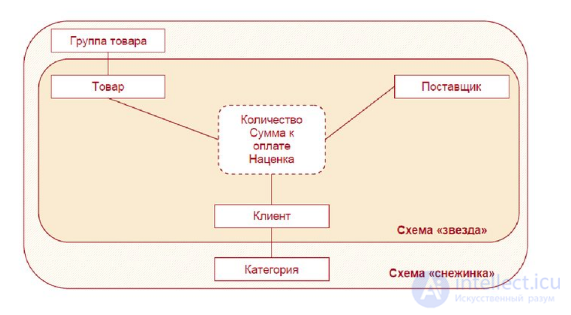
Основное функциональное отличие схемы «снежинка» от схемы «звезда» – это возможность работы с иерархическими уровнями, определяющими
степень детализации данных.
Преимущества схемы «снежинка»:
Недостатки схемы «снежинка»:
Преимущества реляционных хранилищ данных:
Главный недостаток реляционных хранилищ данных:
В основе многомерного представления данных лежит их разделение на две группы – измерения и факты
Многомерная модель данных реализуется с помощью многомерных кубов
Измерения – это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе (наименования
товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т. д.)
Факты – это данные, количественно описывающие бизнес-процесс, непрерывные по своему характеру, то есть они могут принимать
бесконечное множество значений (цена товара или изделия, их количество, сумма продаж или закупок, зарплата сотрудников, сумма
кредита, страховое вознаграждение и т. д.)

Многомерный куб можно рассматривать как систему координат, осями которой являются измерения (например, Дата, Товар, Покупатель). По осям
будут откладываться значения измерений
В ячейке 1 будут располагаться факты, относящиеся к продаже цемента ООО «Спецстрой» 3 ноября, в ячейке 2 – к продаже плит ЗАО «Пирамида» 6
ноября, а в ячейке 3 – к продаже плит ООО «Спецстрой» 4 ноября.
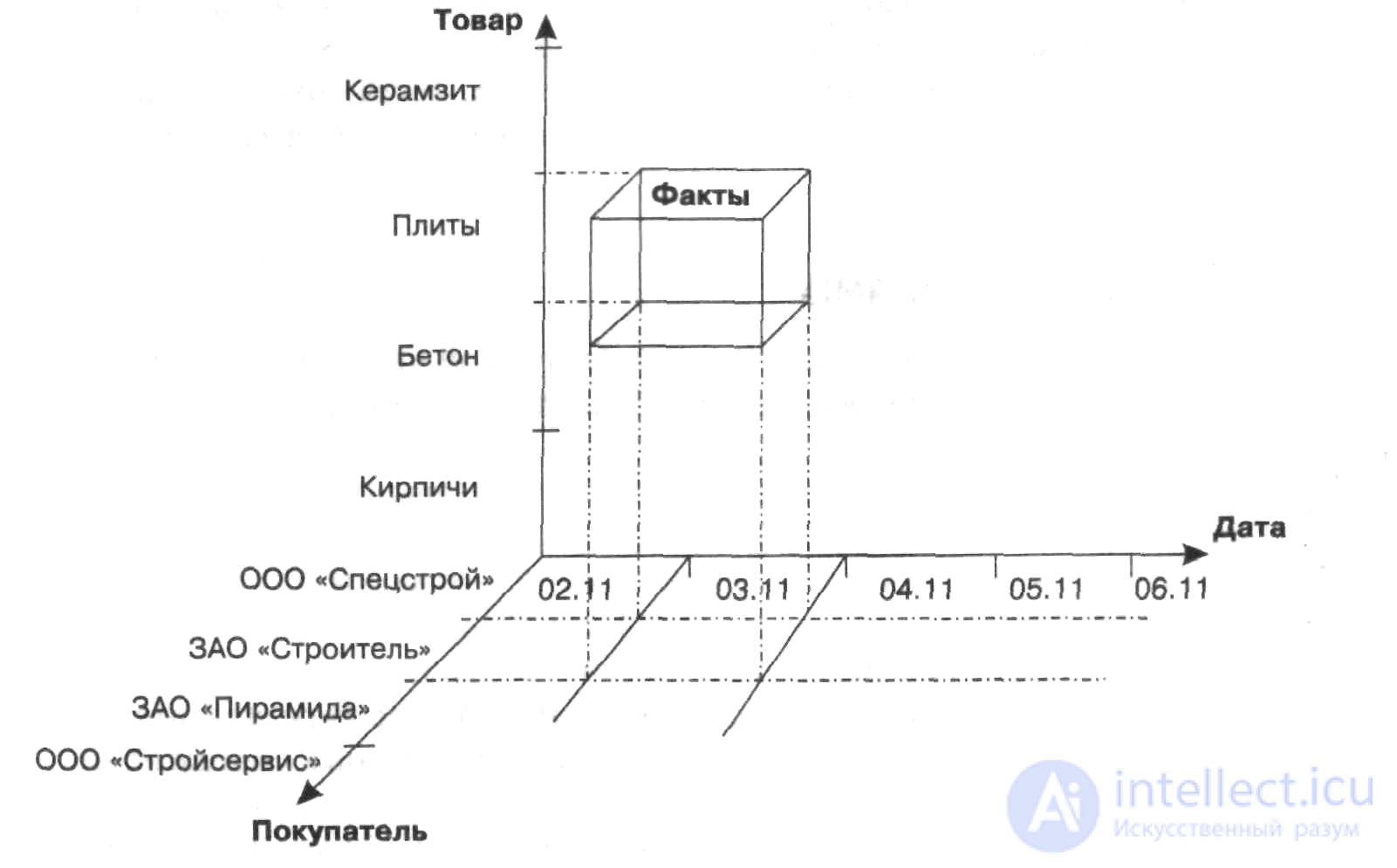
Рис Многомерный взгляд на измерения Дата, Товар и Покупатель
Выделенный сегмент будет содержать информацию о том, сколько плит, на какую сумму и по какой цене приобрела фирма ЗАО «Строитель» 3 ноября.
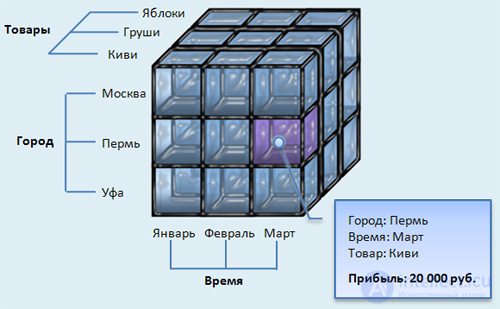
Из многомерного куба может быть составлен обычный плоский отчет. По столбикам и строчкам отчета будут бизнес-категории (грани куба), а в ячейках
показатели.
Преимущества многомерного подхода:
Недостатки использования многомерной модели:
Системы, поддерживающие многомерную модель данных:
Essbase, Media Multi-matrix, Oracle Express Server, Cache.
Многие программные продукты позволяют одновременно работать с многомерными и с реляционными БД.
В общем, мой друг ты одолел чтение этой статьи об структура базы данных. Работы впереди у тебя будет много. Смело пиши комментарии, развивайся и счастье окажется в твоих руках. Надеюсь, что теперь ты понял что такое структура базы данных, иерархическая структура базы данных, сетевая структура базы данных, реляционная структура базы данных, объектно-ориентированная структура базы данных, гибридная структура базы данных, иерархическая базы данных, сетевая базы данных, реляционная базы данных, объектно-ориентированная базы данных, гибридная базы данных, многомерная модель и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL