Лекция
Это окончание невероятной информации про распределенные и параллельные системы баз данных.
...
тиражирование) означает создание дубликатов данных. Репликаты -- это множество различных физических копий некоторого объекта базы данных (обычно таблицы), для которых поддерживается синхронизация (идентичность) с некоторой ``главной'' копией. Теоретически значения всех данных в тиражированных объектах должны автоматически и незамедлительно синхронизироваться друг с другом. (На практике это правило обычно несколько ослабляется.) В некоторых системах копии используются исключительно в режиме чтения и обновляются в соответствии с заданным расписанием. В других средах допускается модификация отдельных значений в копиях, и эти изменения распространяются в соответствии с процедурами планирования и координации. На рисунке 4 показаны различные модели тиражирования.
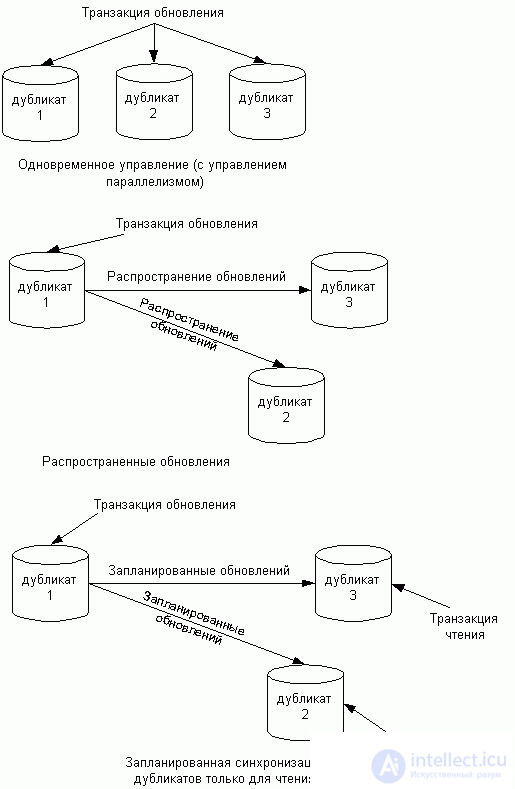
При репликации фрагменты данных тиражируются с учетом спроса на доступ к ним. Это полезно, если доступ к одним и тем же данным нужен из приложений, выполняющихся на разных узлах. В таком случае, с точки зрения экономии затрат, более эффективно будет поддерживать копии данных на всех узлах, чем непрерывно пересылать данные между узлами.
Основной проблемой репликации данных является то, что обновление любого логического объекта должно распространяться на все хранимые копии этого объекта. Трудности возникают из-за того, что некоторый узел, содержащий данный объект, может быть недоступен (например, из-за краха системы или данного узла) именно в момент обновления. В таком случае очевидная стратегия немедленного распространения обновлений на все копии может оказаться неприемлемой, поскольку предполагается, что обновление (а значит и исполнение транзакции) будет провалено, если одна из копий будет недоступна в текущий момент.
Важным компонентом структуры логического уровня РБД является сетевой каталог, который обеспечивает эффективное выполнение основных функций управления РБД и содержит всю информацию, необходимую для обеспечения независимости размещения, фрагментации и репликации. Существует несколько вариантов хранения системного каталога. Ниже перечислены некоторые из этих вариантов.
Для каждого подхода характерны определенные недостатки и проблемы. В первом подходе, очевидно, не достигается "независимость от центрального узла". Во втором утрачивается автономность функционирования, поскольку при обновлении каждого каталога это обновление придется распространять на каждый узел. В третьем выполнение не локальных операций становится весьма дорогостоящим (для поиска удаленного объекта потребуется в среднем осуществить доступ к половине имеющихся узлов). Четвертый подход более эффективен, чем третий (для поиска удаленного объекта потребуется осуществить доступ только к одному удаленному каталогу), но в нем снова не достигается ``независимость от центрального узла''.
Сегодня практически все крупнейшие производители СУБД предлагают решения в области управления распределенными ресурсами. Однако все эти решения поддерживают ограниченныефункции построения неоднородных распределенных систем.
Среди многочисленных прототипов и научно-исследовательских систем следует упомянуть систему SDD-1, созданную в конце 70-х -- начале 80-х годов в научно-исследовательском отделении фирмы Computer Corporation of America; систему R*, которая является распределенной версией системы System R и создана в начале 80-х годов фирмой IBM; а также систему Distributed INGRES, которая является распределенной версией системы INGRES и создана также в начале 80-х годов в Калифорнийском университете в Беркли.
Что касается коммерческих продуктов, то в настоящее время в большинстве реляционных систем предусмотрены разные виды поддержки использования распределенных баз данных с разной степенью функциональности. Среди таких систем наиболее известны система INGRES/STAR отделения Ingres Division фирмы The ASK Group Inc., система ORACLE фирмы Oracle Corporation, а также модуль распределенной работы системы DB2 фирмы IBM.
РБД стали в настоящее время объектом всестороннего исследования. При этом наряду с принципами конструирования и организации, алгоритмами действия большое внимание уделяется методам анализа качества работы РБД, а также исследованию закономерностей их функционирования и взаимосвязи качества работы с особенностями конструктивных и алгоритмических решений.
Однако ввиду исключительной сложности РБД как объекта формального описания и расчета до настоящего времени априорная оценка ожидаемого эффекта от тех или иных конструктивных и алгоритмических решений, а следовательно, и от капиталовложений, необходимых для их реализации, обычно базируется на общих качественных соображениях, не подкрепленных расчетом, когда влияние отдельных факторов оценивается интуитивно, и возможны грубые ошибки. Для практически убедительного суждения о качестве работы РБД с позиции потребителя необходимо оценить пусть с ограниченной, но заранее известной точностью функции распределения вероятностей параметров работы ИС.
Реальные сложные системы можно исследовать с помощью двух типов математических моделей: аналитических и имитационных. В аналитических моделях поведение систем записывается в виде некоторых функциональных соотношений или логических условий. Наиболее полное исследование удается провести в том случае, когда получены явные зависимости, связывающие искомые величины с параметрами исследуемых объектов и начальными условиями его изучения. Однако это удается выполнить только для сравнительно простых систем. Для РБД, которая является сложной системой, нам придется идти на упрощения представления реальных явлений, дающие возможность описать их поведение и представить взаимодействия между компонентами распределенной системы. Для построения аналитических моделей имеется мощный математический аппарат (алгебра, функциональный анализ, разностные уравнения, теория вероятностей, математическая статистика, теория массового обслуживания и т.д.).
Аналитические модели распределенных баз данных предложены в ряде работ изданных в начале 90-х годов. В своей книге [Cegel90] Г. Г. Цегелик рассмотрел несколько моделей РБД. Эти модели различаются разными подходами к их построению и выбранными топологиями. Эти модели позволяют оптимизировать распределение объектов РБД по узлам распределенной системы. Однако они построены при некоторых, очень значительных, упрощениях. Самое существенное из них -- это то, что эти модели статичны. Т.е. они не учитывают влияние динамических процессов в РБД. Это приводит к неточности модели и мы не в состоянии измерить степень этой неточности.
Аналитическую модель также рассматривают А. Г. Мамиконов, В. В. Кульба и др. Для этой модели характерны те же недостатки что и для модели, предложенной Г. Г. Цегеликом.
Основными методами расчета параметров работы ИС, используемыми в настоящее время, являются методы теории массового обслуживания и, имитационного моделирования. Применение их при ряде упрощающих допущений на законы распределения времени возникновения запросов, их объема, структуру системы и т.п. позволяет наряду с оценками времени передачи информации получить значения многих других характеристик РБД -- оценить длины очередей, вероятности отказа в обслуживании и т.п.
Однако методы теории массового обслуживания достаточно сложны и не могут в настоящее время использоваться для расчета временных характеристик в реальных РБД с большим числом узлов и каналов связи. Также при помощи теории массового обслуживания трудно предусмотреть все специфичные моменты работы реальных РБД. Поэтому для исследования предпочтительней использовать имитационное моделирование.
В имитационной модели поведение компонент объекта описывается набором алгоритмов, которые затем реализуют ситуации, возникающие в реальной системе. Моделирующие алгоритмы позволяют по исходным данным, содержащим сведения о начальном состоянии объекта, и фактическим значениям параметров системы отобразить реальные явления в системе и получить сведения о возможном поведении объекта для данной конкретной ситуации.
При всех преимуществах данного подхода автору неизвестны примеры использования методов имитационного моделирования для расчета параметров функционирования РБД в компьютерных информационных системах.
А как ты думаешь, при улучшении распределенные и параллельные системы баз данных, будет лучше нам? Надеюсь, что теперь ты понял что такое распределенные и параллельные системы баз данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Часть 1 Распределенные и параллельные системы баз данных
Часть 2 Исследовательские проблемы - Распределенные и параллельные системы баз данных
Часть 3 Объект и предмет исследования. - Распределенные и параллельные системы баз
Часть 4 Анализ методов моделирования РБД. - Распределенные и параллельные системы баз
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL