Лекция
Это продолжение увлекательной статьи про распределенные и параллельные системы баз данных.
...
выражаются в неравномерном разделении отношений и отрицательно влияют на балансировку нагрузки. В такой ситуации полезными могут оказаться гибридные архитектуры, узлы которых обладают разными вычислительными мощностями и объемами памяти. Другой подход состоит в дальнейшей декластеризации наиболее крупных разделов данных. Целесообразно также провести различие между понятиями логического и физического узла, так что логическому узлу может соответствовать несколько физических.
Еще один фактор, усложняющий задачу размещения данных, – это репликация данных для обеспечения высокого уровня доступности. Наивный подход здесь заключается в том, чтобы иметь две копии одних и тех же данных – первичную и резервную – на двух отдельных узлах. Но в случае отказа одного узла нагрузка на второй удвоится, что приведет к нарушению балансировки нагрузки. Для решения этой проблемы в последнее время было предложено несколько стратегий репликации для поддержки высокого уровня доступности, сравнительный анализ которых приведен в [Hsiao and DeWitt, 1991]. Интересный подход, который можно назвать расслоенной (interleaved) декластеризацией, применен в Teradata, где резервная копия декластеризуется между несколькими узлами. В случае отказа первичного узла его нагрузка распределяется между узлами, содержащими резервную копию. Однако реконструкция первичной копии из фрагментов ее резервной копии может оказаться дорогостоящей операцией. Существенны также затраты, требуемые на поддержание согласованного состояния резервной копии в нормальном режиме. Более разумное решение, названное цепочной (chained) декластеризацией, применено в Gamma, где первичная и резервная копии хранятся на двух соседних узлах. В режиме сбоя загрузка отказавшего узла распределяется между всеми остальными узлами, которые используют копии данных как первичного, так и вторичного узла. Поддержание согласованных копий в этом случае обходится дешевле. Открытым остается вопрос о процедуре размещения данных с учетом их реплицирования. Так же, как и размещение фрагментов в распределенных базах данных, эта проблема должна рассматриваться как одна из проблем оптимизации.
Исследовательское сообщество не располагает достаточно полным представлением о том, как связана производительность баз данных с разнообразными сетевыми архитектурами, которые развиваются вместе с современными распределенными СУБД. Возникает, в частности, вопрос о масштабируемости некоторых протоколов и алгоритмов в условиях, когда системы становятся географически распределенными [Stonebraker, 1989], или возрастает число отдельных системных компонентов [Garcia-Molina and Lindsay, 1990]. Важное значение имеет проблема пригодности механизмов для распределенной обработки транзакций в распределенных системах на базе глобальных сетей (WAN). Как упоминалось выше, работа этих протоколов связана с высокими накладными расходами, и реализация их на медленной сети WAN сильно затруднена [Stonebraker, 1989].
Вопросы масштабируемости – это лишь одна из сторон более общей проблемы, которая заключается в том, что не существует хороших подходов, позволяющих оценивать влияние сетевых архитектур и протоколов на производительность распределенных СУБД. Почти все исследования в этой сфере опираются на крайне упрощенные модели сетевых затрат, вплоть до совсем уж нереалистичного предположения о фиксированной коммуникационной задержке, не зависящей даже от таких важных параметров, как размер сообщения, степень загруженности и масштаб сети и т. п. В целом нет ясного представления ни о производительности предлагаемых алгоритмов и протоколов, ни о сравнительных характеристиках их поведения при переходе к глобальным сетям. Наиболее разумный подход к проблеме масштабируемости – это разработка общих и достаточно мощных моделей оценки производительности, измерительных инструментов и мотодологий. Некоторое время подобные работы проводились для централизованных СУБД, но они не получили достаточного развития и распространения на случай распределенных СУБД.
Хотя существует множество исследований в направлении производительности распределенных СУБД, все они, как правило, исходят из упрощенных моделей или искусственной рабочей загрузки, из противоречивых предположений или учитывают лишь некоторые специальные алгоритмы. Это не означает, что у нас нет никаких представлений об издержках сетевой обработки. Некоторые виды издержек известны довольно давно и принимались в расчет при проектировании даже довольно ранних систем. Однако они обычно рассматривались лишь качественно; для их количественных оценок нужны дальнейшие исследования на разных моделях производительности.
Как обсуждалось выше, на этапе глобальной оптимизации для исходного фрагментного запроса генерируется оптимальный план выполнения. При этом принимаются решения относительно упорядочения операций, перемещений данных между узлами, выбора тех или иных локальных или распределенных алгоритмов выполнения операций. С этим шагом связан ряд серьезных проблем. К ним относятся ограничения, привносимые стоимостной моделью, выбор подмножества языка запросов, соотношение между затратами оптимизации и затратами выполнения, интервал оптимизации/реоптимизации.
Стоимостная модель – центральное звено глобальной оптимизации запросов, поскольку она предоставляет необходимую абстракцию среды выполнения распределенной СУБД в терминах методов доступа, а также абстракцию самой базы данных в терминах информации об ее физической схеме и соответствующей статистики. Стоимостная модель используется для предсказания затрат на выполнение альтернативных планов запроса. Со стоимостными моделями зачастую связан ряд серьезных ограничений, которые снижают эффективность оптимизации, направленной на улучшение общей пропускной способности системы. Полезными здесь могут быть работы по созданию расширенных алгоритмов оптимизации на основе параметризуемой стоимостной модели [Freytag, 1987], которую можно настраивать экспериментальным способом. Хотя языки запросов становятся все более развитыми (новые версии SQL), на стадии глобальной оптимизации применяется весьма ограниченное их подмножество, а именно, подмножество, позволяющее формулировать SPJ-запросы (select-project-join – селекция-проекция-соединение) с конъюнктивными предикатами. Это важный класс запросов, для которого существуют развитые методы оптимизации. Разработаны, в частности, различные теории оптимального упорядочения соединений и полусоединений. В то же время, имеются и другие важные классы запросов, для которых еще предстоит создать соответствующие методы оптимизации: запросы с дизъюнкциями, объединениями, фиксированными точками (fixpoint), агрегацией и сортировкой. Многообещающий подход к этой проблеме заключается в отделении чисто языковые аспекты от собственно оптимизации, которую можно доверить нескольким "экспертам оптимизации".
Существует естественная связь между затратами на оптимизацию и качеством результирующего плана выполнения. Высокие затраты на оптимизацию оправданы для регулярно выполняемых запросов, поскольку стоимость оптимизации окупается снижением затрат на выполнение и амортизируется многократностью выполнения. Однако нерационально тратить слишком много ресурсов на оптимизацию однократно выполняемых сиюминутных запросов. Большую часть затрат оптимизации составляет поиск в пространстве решений, представляющих альтернативные планы выполнения. Для распределенных систем характерны большие размеры пространства решений, поскольку число распределенных стратегий выполнения очень велико. Следовательно, важное значение здесь имеют исследования, направленные на выработку эффективных методов обхода пространства решений, исключающих его исчерпывающий перебор.
Глобальная оптимизация запросов производится заранее, до их выполнения, поэтому она называется статической. Основная проблема, возникающая в связи с этим, заключается в том, что модель стоимости, которая использовалась при оптимизации, со временем становится неточной, как из-за изменения размеров фрагментов, так и из-за реорганизаций базы данных, проводимых для балансировки нагрузки. Таким образом, задача состоит в том, чтобы определить оптимальные интервалы рекомпиляции/реоптимизации запросов с учетом соотношения затрат на их оптимизацию и выполнение.
Критически важной проблемой с точки зрения стратегии поиска является проблема упорядочения соединений, которая является NP-полной от числа отношений [Ibaraki and Kameda, 1984]. Типичный подход к решению этой задачи – применение динамического программирования [Selinger et al., 1979], которое является детерминированной стратегией. Эта почти исчерпывающая стратегия, гарантирующая нахождение наилучшего плана из всех возможных. Затраты (по времени и памяти) на ее реализацию приемлемы для небольшого числа отношений. Однако уже для 5-7 отношений такой подход становится слишком дорогостоящим. В связи с этим в последнее время возрос интерес к стратегиям случайного перебора (randomized strategy), которые снижают сложность оптимизации, но не гарантируют нахождение наилучшего плана. Стратегии случайного перебора исследуют пространство решений контролируемым образом, в том смысле что оптимизация завершается по исчерпанию заданного для нее бюджета времени. Еще один способ снизить сложность оптимизации – применение эвристических подходов. В отличие от детерминированных стратегий, стратегии случайного перебора позволяют управлять соотношением затрат на оптимизацию и выполнение запросов [Ioannidis and Wong, 1987, Swami and Gupta, 1988, Ioannidis and Kang, 1990].
Несмотря на многочисленность исследований, в области распределенной обработки транзакций остается еще множество открытых вопросов. Выше уже обсуждались проблемы масштабируемости алгоритмов обработки транзакций. Дополнительных исследований требуют также протоколы управления репликацией, некоторые более изощренные модели транзакций и критерии корректности для несериализуемой обработки транзакций. В области репликации данных необходимы дальнейшие эксперименты, изучение методов реплицирования вычислений и коммуникаций; нуждается в исследовании также вопрос систематизации и применения специфических для конкретных приложений свойств репликации. Для оценки предлагаемых алгоритмов и системных архитектур необходима их всесторонняя экспериментальная проверка, и здесь недостает четкой методики для сравнения конкурирующих технологий.
Одна из трудностей количественных оценок для алгоритмов репликации состоит в отсутствии общепринятых моделей типичных характеристик сбоев. Например, модели Маркова, применяемые иногда для анализа показателей доступности для различных протоколов реплицирования, опираются на предположения о статистической независимости отдельных сбоев и об относительно малой вероятности разделения сети по сравнению с вероятностью отказа отдельного узла. В настоящее время мы не знаем, насколько эти предположения оправданы и насколько чувствительны к ним применяемые модели Маркова. Подтверждение моделей Маркова путем симуляции требует эмпирических измерений, поскольку методики симуляции часто опираются на те же предположения, которые лежат в основе анализа в моделях Маркова. Следовательно, необходимы эмпирические наблюдения в реальных промышленных системах с целью выработки простой модели типичных последовательностей сбоев.
Для достижения двух важнейших целей реплицирования – высокой доступности и производительности – нужны интегрированные системы, где репликация данных эффективно дополняется репликацией вычислений и коммуникаций (включая ввод-вывод). Однако достаточно хорошо изучены лишь вопросы репликации данных, в то время как в области репликации вычислений и коммуникаций сделано еще относительно мало.
В дополнение к репликации и в связи с ней необходимо также исследовать более сложные модели транзакций, в частности такие, в которых возможно использование семантики приложения [Elmagarmid, 1992, Weihl, 1989]. Подобные модели послужили бы достижению более высокой производительности и надежности, а также снижению конкуренции. По мере того как базы данных внедряются во все новые прикладные области, такие как инженерное проектирование, программные разработки, офисные информационные системы, видоизменяются и сама сущность транзакций, и предъявляемые к их обработке требования. Это означает, что следует выработать более изощренные модели транзакций, а также критерии корректности, отличные от сериализуемости.
Развитие моделей транзакций важно для распределенных систем по целому ряду причин. Наиболее существенная из них заключается в том, что новые прикладные области, которые будут поддерживаться распределенными СУБД (инженерное проектирование, офисные информационные системы, кооперативная деятельность и др.), требуют транзакций, включающих более абстрактные операции над сложными типами данных. Далее, для подобных приложений характерна парадигма разделения данных, отличная от той, которая принята в традиционных СУБД. Например, система поддержки кооперативной деятельности предполагает, скорее, кооперацию при доступе к общим данным, чем конкуренцию. Именно этими изменяющимися требованиями вызвана необходимость разработки новых моделей транзакций и соответствующих критериев корректности.
В качестве кандидатов, способных удовлетворить упоминавшимся выше требованиям, сейчас рассматриваются объектно-ориентированные СУБД. В таких системах операции (методы) инкапсулированы вместе с данными. Следовательно, для них необходимы четкие определения семантики модификации данных и модели транзакций, опирающиеся на семантику инкапсулированных операций [Ozsu, 1994].
За последние несколько лет распределенные и параллельные СУБД стали реальностью. Они предоставляют функциональность централизованных СУБД, но в такой среде, где данные распределены между компьютерами, связанными сетью, или между узлами многопроцессорной системы. Распределенные СУБД допускают естественный рост и расширение баз данных путем простого добавления в сеть дополнительных машин. Подобные системы обладают более привлекательными характеристиками "цена/производительность", благодаря современным прогрессивным сетевым технологиям. Параллельные СУБД – это, пожалуй, единственный реалистичный подход для удовлетворения потребностей многих важных прикладных областей, которым необходима исключительно высокая пропускная способность баз данных. Поэтому при проектировании параллельных и распределенных СУБД следует предусмотреть в них соответствующие протоколы и стратегии обработки, направленные на достижение высокой производительности. Обзор именно таких протоколов и стратегий и представлен в данной статье.
Мы не охватили ряд смежных вопросов. Две важные проблемы, не рассмотренные здесь, – это системы мультибаз данных и распределенные объектно-ориентированные базы данных. Многие информационные системы развиваются независимо, опираясь на собственные реализации СУБД. Позже, когда появляется необходимость "интегрировать" эти автономные и часто разнородные системы, возникают серьезные трудности. Системы, которые предоставляют доступ к подобным, независимо разработанным разнородным базам данных, называются мультибазами данных (multidatabase system) [Sheth and Larson, 1990].
Проникновение баз данных в такие области (проектирование, мультимедийные системы, геоинформационные системы, системы обработки графических образов), для которых реляционные СУБД изначально не предназначались, послужило стимулом для поиска новых моделей и архитектур баз данных. Среди наиболее серьезных кандидатов, претендующих на удовлетворение потребностей новых классов приложений, – объектно-ориентированные СУБД [Dogac et al., 1994]. Внедрение принципов распределенной обработки в эти СУБД стало источником целого ряда проблем, относящихся к области так называемого распределенного управления объектами [Ozsu et al., 1994]. Вопросы, связанные с мультибазами данных и распределенным управлением объектами, остались за рамками рассмотрения настоящей статьи.
Алгоритм голосования на базе кворума (quorum-based voting algorithm). Протокол управления репликами, при котором транзакция, для того чтобы выполнить операцию чтения или записи элемента данных, должна собрать необходимый кворум голосов его физических копий.
Алгоритм управления одновременным доступом (concurrency control algorithm). Алгоритм, который обеспечивает синхронизацию операций, относящихся к одновременно выполняемым транзакциям над разделяемой базой данных.
Архитектура клиент-сервер (client/server architecture). Архитектура распределенных/параллельных СУБД, в которой множество машин-клиентов, обладающих ограниченной функциональностью, осуществляют доступ к множеству серверов управления данными.
Архитектура без разделяемых ресурсов (shared-nothing architecture:). Архитектура параллельной СУБД, в которой каждый процессор имеет монопольный доступ к своей собственной оперативной памяти и к собственному набору дисков.
Архитектура с разделяемой памятью (shared-memory architecture). Архитектура параллельной СУБД, в которой каждый процессор посредством быстрых линий связи (высокоскоростной шины или коммутатора) имеет доступ к любому модулю памяти и к любому дисковому устройству.
Архитектура с разделяемыми дисками (shared-disk architecture). Архитектура параллельной СУБД, в которой каждый процессор имеет разделяемый доступ к любому диску системы посредством коммуникационных средств и монопольный доступ к собственной оперативной памяти.
Атомарность (atomicity). Свойство обработки транзакций, заключающееся в том, что либо выполняются все операции транзакции, либо не выполняется ни одна (принцип "все или ничего").
Блокирование (locking). Метод управления одновременным доступом, при котором на единицы хранения базы данных (страницы) накладываются блокировки от имени транзакции, которой необходим доступ к ним.
Внутризапросный параллелизм (intra-query parallelism). Параллельное выполнение множества независимых операций, которые могут относиться к одному и тому же запросу.
Внутриоперационный параллелизм (intra-operation parallelism). Параллельное выполнение одной реляционной операции в виде множества субопераций.
Двухфазовая фиксация транзакций (two-phase commit). Протокол атомарной фиксации, который гарантирует одинаковое завершение транзакции на всех затрагиваемых ею узлах. Название связано с тем, что в ходе выполнения протокола происходит два "раунда" обмена сообщениями между узлами.
Двухфазовое блокирование (two-phase locking). Алгоритм блокирования, при котором транзакция не имеет права установить новую блокировку на элемент данных, пока не сняты предыдущие.
Долговечность (durability). Свойство обработки транзакций, заключающееся в том, что результаты успешно завершенной (зафиксированной) транзакции сохраняются даже при последующих сбоях системы.
Изолированность (isolation). Свойство обработки транзакций, заключающееся в том, что результат действий, производимых транзакцией, не может зависеть (изолирован) от одновременно выполняющихся других транзакций.
Линейная масштабируемость (linear scaleup). Сохранение той же скорости обработки при увеличении размера базы данных вместе с одновременным пропорциональным наращиванием процессорной мощности и объема памяти.
Линейное ускорение (linear speedup). Пропорциональное увеличение скорости обработки при увеличении процессорной мощности и объема памяти и сохранении прежнего размера базы данных.
Межзапросный параллелизм (intra-query parallelism). Параллельное выполнение нескольких запросов, относящихся к разным транзакциям.
Независимость данных (data independence). Устойчивость прикладных программ и запросов к изменениям в физической организации базы данных (независимость от физических данных) или в ее логической организации (независимость от логических данных) и обратная независимость.
Неустойчивая база данных (volatile database). Часть базы данных, хранимая в буферах оперативной памяти.
Обработка запроса (query processing). Процесс трансляции декларативного запроса в последовательность низкоуровневых операций манипулирования данными.
Оптимизация запроса (query optimization). Процесс нахождения "наилучшей" стратегии выполнения запроса из некоторого множества альтернатив.
Параллельная система управления базами данных (parallel database management system). Система управления базами данных, реализованная на сильносвязанной многопроцессорной архитектуре.
Полная эквивалентность копий (one copy equivalence). Политика управления реплицированием, требующая, чтобы по завершении транзакции все копии каждого элемента данных, который модифицирует данная транзакция, были идентичны.
Прозрачность (transparency). Распространение понятия независимости данных на распределенные системы, при котором от пользователей экранируются такие аспекты хранения данных, как распределение, фрагментация, реплицирование.
Протокол журнализации (logging protocol). Протокол, который производит в отдельной области памяти записи обо всех изменениях в базе данных, прежде чем эти изменения будут реально выполнены.
Протокол терминирования (termination protocol). Протокол, при помощи которого отдельный узел может принять решение о том, как следует завершить транзакцию в условиях, когда он не может взаимодействовать с другими участвующими в данной транзакции узлами.
Протокол ROWA (Read-Once/Write-All protocol). Протокол управления реплицированием, который логическую операцию чтения отображает на операцию чтения любой физической копии, а логическую операцию записи – на множество операций записи во все физические копии элемента данных.
Распределенная система управления базами данных (distributed database management system).Система, которая управляет базой данных, распределенной по узлам компьютерной сети, и обеспечивает для пользователей прозрачность распределения данных.
Сериализуемость (serializability). Критерий корректности для управления одновременным доступом, который требует, чтобы эффект множества одновременно выполняемых транзакций был эквивалентен эффекту от их последовательного выполнения при каком-либо упорядочении.
Стабильная база данных (stable database). Часть базы данных, хранимая во вторичной памяти.
Транзакция (transaction). Неделимая (атомарная) единица выполнения операций над базой данных, в результате которой база данных остается в согласованном состоянии.
Тупик (deadlock). Ситуация, когда множество транзакций образует цикл, ожидая снятия блокировок, установленных другими транзакциями из этого множества.
1) Разница между оптимальным и "наилучшим" планом состоит в том, что для нахождения первого требуется исследование всех возможных планов, что на практике никогда не реализуется из-за трудноразрешимого характера задачи.
2) Вопросы репликации не столь существенны для параллельных СУБД, данные которых обычно не копируются на нескольких процессорах. Репликация может возникать как результат передачи (транспортировки) данных в ходе оптимизации запроса, но эти ситуации находятся вне ведения протоколов управления репликами.
Становление систем управления базами данных совпало по времени со значительными успехами в развитии технологий распределенных вычислений и параллельной обработки. В результате возникли системы управления распределенными базами данных. Именно эти системы становятся доминирующими инструментами для создания приложений интенсивной обработки данных. В среде распределенных СУБД упрощается решение вопросов, связанных с возрастанием объема баз данных или потребностей обработки. При этом редко возникает необходимость в серьезной перестройке системы; расширение возможностей обычно достигается за счет добавления процессорных мощностей или памяти.
В идеале распределенная СУБД обладает свойством линейной расширяемости и линейного ускорения. Под линейной расширяемостью понимается сохранение того же уровня производительности при увеличении размера базы данных и одновременном пропорциональном увеличении процессорной мощности и объема памяти. Линейное ускорение означает, что с наращиванием процессорной мощности и объема памяти при сохранении прежнего размера базы данных пропорционально возрастает производительность. Причем при расширении системы потребуется минимальная реорганизация существующей базы данных.
С учетом соотношения цена/производительность для микропроцессоров и рабочих станций экономически выгоднее оказывается составить систему из нескольких небольших компьютеров, чем реализовать ее на эквивалентной по мощности одной большой машине. Множество коммерческих распределенных СУБД функционируют на мини-компьютерах и рабочих станциях именно по причине более выгодного соотношения цена/производительность. Технологии, основанные на применении рабочих станций, получили столь широкое распространение благодаря тому, что большинство коммерческих СУБД способны работать в рамках локальных сетей, где в основном и используются рабочие станции. Развитие распределенных СУБД, предназначенных для глобальных сетей WAN, может привести к повышению роли мэйнфреймов. С другой стороны, распределенные СУБД будущих поколений, скорее всего, будут поддерживать иерархические сетевые структуры, состоящие из кластеров, в пределах которых компьютеры взаимодействуют на базе локальной сети, а сами кластеры соединяются между собой посредством высокоскоростных магистралей.
Все эти причины привели к бурному развитию технологий распределенных баз данных информационных систем. Однако остаются нерешенными некоторые сложные вопросы связанные с данной темой. Один из этих вопросов - динамические процессы в распределенных базах данных.
Объектом исследования является распределенная база данных компьютерных информационных систем.
Предметом исследования является влияние динамических процессов на функционирование распределенной базы данных.
Распределенная база данных (РБД) -- это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети.
Другими словами, системы распределенных баз данных состоят из набора узлов, связанных вместе коммуникационной сетью, в которой:
1)
каждый узел обладает своими собственными системами баз данных;
2)
узлы работают согласованно, поэтому пользователь может получить доступ к данным на любом узле сети, как будто все данные находятся на его собственном узле.
На рисунке 1 приведен пример распределенной базы данных.

Система управления распределенной базой данных (РСУБД) -- это программная система, которая обеспечивает управление распределенной базой данных таким образом, чтобы ее распределенность была прозрачна для пользователей.
Эти определения можно дополнить, если рассмотреть также различные характеристики РБД и РСУБД. В 1981г К. Дейт опубликовал свои правила для распределенных баз данных1. Ниже приведены эти 12 правил.
База данных физически распределяется по узлам данных при помощи фрагментации и репликации, или тиражирования, данных.
Отношения, принадлежащие реляционной базе данных, могут быть фрагментированы на горизонтальные или вертикальные разделы.
Горизонтальная фрагментация реализуется при помощи операции селекции, которая направляет каждый кортеж отношения в один из разделов, руководствуясь предикатом фрагментации. Например, для отношения Employee (Сотрудник) возможна фрагментация в соответствии с территориальным распределением рабочих мест сотрудников.
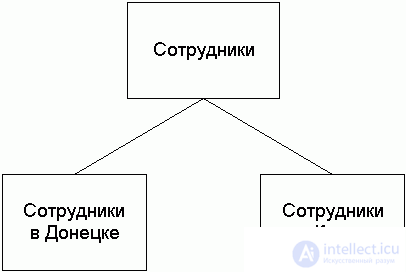
Тогда запрос ``получить информацию о сотрудниках компании'' может быть сформулирован так:
SELECT * FROM employee@donetsk, employee@kiev
При вертикальной фрагментации отношение делится на разделы при помощи операции проекции. Например, один раздел отношения Employee может содержать поля Номер_сотрудника (emp_id), ФИО_сотрудника (emp_name), Адрес_сотрудника (emp_adress), а другой -- поля Номер_сотрудника (emp_id), Оклад (salary), Руководитель (emp_chief).
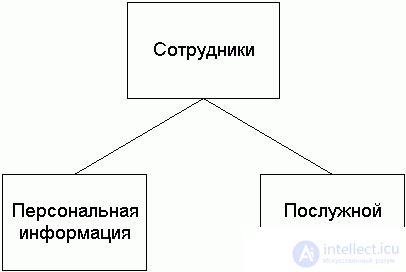
Тогда запрос ``получить информацию о заработной плате сотрудников компании'' будет выглядеть следующим образом:
SELECT employee.emp_id, emp_name, salary FROM employee@donetsk, employee@kiev ORDER BY emp_id
За счет фрагментации данные приближаются к месту их наиболее интенсивного использования, что потенциально снижает затраты на пересылки; уменьшаются также размеры отношений, участвующих в пользовательских запросах.
Второй способ распределения данных -- репликация. Репликация (или
продолжение следует...
Часть 1 Распределенные и параллельные системы баз данных
Часть 2 Исследовательские проблемы - Распределенные и параллельные системы баз данных
Часть 3 Объект и предмет исследования. - Распределенные и параллельные системы баз
Часть 4 Анализ методов моделирования РБД. - Распределенные и параллельные системы баз
А как ты думаешь, при улучшении распределенные и параллельные системы баз данных, будет лучше нам? Надеюсь, что теперь ты понял что такое распределенные и параллельные системы баз данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL