Лекция
Это окончание невероятной информации про простые структуры данных.
...
такими данными обеспечивают доступ к выбранному биту данного. В языке PASCAL роль битовых типов выполняют беззнаковые целые типы byte и word. Над этими типами помимо операций, характерных для числовых типов, допускаются и побитовые операции. Аналогичным образом роль битовых типов играют беззнаковые целые и в языке C.
В языке PL/1 существует специальный тип данных - строка битов, объявляемый в программе, как: BIT(n).
Данные этого типа представляют собой последовательность бит длиною n. Строка битов занимает целое число байт в памяти и при необходимости дополняется справа нулями.
Операции над битовыми типами.
Над битовыми типами возможны три группы специфических операций: операции булевой алгебры, операции сдвигов, операции сравнения.
Операции булевой алгебры - НЕ (not), ИЛИ (or), И (and), исключающее ИЛИ (xor). Эти операции и по названию, и по смыслу похожи на операции над логическими операндами, но отличие в их применении к битовым операндам состоит в том, что операции выполняются над отдельными разрядами операндов.
Так операция НЕ состоит в том, что каждый разряд операнда изменяет значение на противоположный. Выполнение операции, например, ИЛИ над двумя битовыми операндами состоит в том, что выполняется ИЛИ между первым разрядом первого операнда и первым разрядом второго операнда, это дает первый разряд результата; затем выполняется ИЛИ между вторым разрядом первого операнда и вторым разрядом второго, получается второй разряд результата и т.д.
Ниже даны примеры выполнения побитовых логических операций:
а). x = 01101100 в). x = 01101100
not x = 10010011 y = 11001110
x and y = 01001100
б). x = 01101100 г). x = 01101100
y = 11001110 y = 11001110
x or y = 11101110 x xor y = 10100010
В некоторых языках (PASCAL) побитовые логические операции обозначаются так же, как и операции над логическими операндами и распознаются по типу операндов. В других языках (C) для побитовых и общих логических операций используются разные обозначения. В третьих (PL/1) - побитовые операции реализуются встроенными функциями языка.
Операции сдвигов выполняют смещение двоичного кода на заданное количество разрядов влево или вправо. Из трех возможных типов сдвига (арифметический, логический, циклический) в языках программирования обычно реализуется только логический (например, операциями shr, shl в PASCAL).
В операциях сравнения битовые данные интерпретируются как целые без знака, и сравнение выполняется как сравнение целых чисел. Битовые строки в языке PL/1 - более общий тип данных, к которому применимы также операции над строковыми данными, рассматриваемые в главе 4.
Значениями логического типа BOOLEAN может быть одна из предварительно объявленных констант false (ложь) или true (истина).
Данные логического типа занимают один байт памяти. При этом значению false соответствует нулевое значение байта, а значению true соответствует любое ненулевое значение байта. Например: false всегда в машинном представлении: 00000000; true может выглядеть таким образом: 00000001 или 00010001 или 10000000.
Однако следует иметь в виду, что при выполнении операции присваивания переменной логического типа значения true, в соответствующее поле памяти всегда записывается код 00000001.
Над логическими типами возможны операции булевой алгебры - НЕ (not), ИЛИ (or), И (and), исключающее ИЛИ (xor) - последняя реализована для логического типа не во всех языках. В этих операциях операнды логического типа рассматриваются как единое целое - вне зависимости от битового состава их внутреннего представления.
Кроме того, следует помнить, что результаты логического типа получаются при сравнении данных любых типов.
Интересно, что в языке C данные логического типа отсутствуют, их функции выполняют данные числовых типов, чаще всего - типа int. В логических выражениях операнд любого числового типа, имеющий нулевое значение, рассматривается как "ложь", а ненулевое - как "истина". Результатами логического типа являются целые числа 0 (ложь) или 1 (истина).

Значением символьного типа char являются символы из некоторого предопределенного множества. В большинстве современных персональных ЭВМ этим множеством является ASCII (American Standard Code for Information Intechange - американский стандартный код для обмена информацией). Это множество состоит из 256 разных символов, упорядоченных определенным образом и содержит символы заг- лавных и строчных букв, цифр и других символов, включая специальные управляющие символы. Допускается некоторые отклонения от стандарта ASCII, в частности, при наличии соответствующей системной поддержки это множество может содержать буквы русского алфавита. Порядковые номера ( кодировку) можно узнать в соответствующих разделах технических описаний.
Значение символьного типа char занимает в памяти 1 байт. Код от 0 до 255 в этом байте задает один из 256 возможных символов ASCII таблицы.
Например: символ "1" имеет ASCII код 49, следовательно машинное представление будет выглядеть следующим образом: 00110001.
ASCII, однако, не является единственно возможным множеством. Другим достаточно широко используемым множеством является код EBCDIC (Extended Binary Coded Decimal Interchange Code - расширенный двоично-кодированный десятичный код обмена), применяемый в системах IBM средней и большой мощности. В EBCDIC код символа также занимает один байт, но с иной кодировкой, чем в ASCII.
И ASCII, и EBCDIC включают в себя буквенные символы только латинского алфавита. Символы национальных алфавитов занимают "свободные места" в таблицах кодов и, таким образом, одна таблица может поддерживать только один национальный алфавит. Этот недостаток преодолен во множестве UNICODE, которое находит все большее распространение прежде всего в UNIX-ориентированных системах. В UNICODE каждый символ кодируется двумя байтами, что обеспечивает более 64 тыс. возможных кодовых комбинаций и дает возможность иметь единую таблицу кодов, включающую в себя все национальные алфавиты. UNICODE, безусловно, является перспективным, однако, повсеместный переход к двухбайтным кодам символов может вызвать необходимость переделки значительной части существующего программного обеспечения.
Специфические операции над символьными типами - только операции сравнения. При сравнении коды символов рассматриваются как целые числа без знака. Кодовые таблицы строятся так, что результаты сравнения подчиняются лексикографическим правилам: символы, занимающие в алфавите места с меньшими номерами, имеют меньшие коды, чем символы, занимающие места с большими номерами. В основном символьный тип данных используется как базовый для построения интегрированного типа "строка символов", рассматриваемого в гл.4.

Логическая структура.
Перечислимый тип представляет собой упорядоченный тип данных, определяемый программистом, т.е. программист перечисляет все значения, которые может принимать переменная этого типа. Значения являются неповторяющимися в пределах программы идентификаторами, количество которых не может быть больше 256, например,
type color=(red,blue,green);
work_day=(mo,tu,we,th,fr);
winter_day=(december,january,february);
Машинное представление.
Для переменной перечислимого типа выделяется один байт, в который записывается порядковый номер присваиваемого значения. Порядковый номер определяется из описаного типа, причЯм нумерация начинается с 0. Имена из списка перечислимого типа являются константами, например,
var B,С:color;
begin B:=bluе; (* B=1 *)
C:=green; (* С=2 *)
Write(ord(B):4,ord(C):4); end.
После выполнения данного фрагмента программы на экран будут выданы цифры 1 и 2. Содержимое памяти для переменных B И C при этом следующее:
В - 00000001; С - 00000010.

Операции.
На физическом уровне над переменными перечислимого типа определены операции создания, уничтожения, выбора, обновления. При этом выполняется определение порядкового номера идентификатора по его значению и, наоборот, по номеру идентификатораего значение.
На логическом уровне переменные перечислимого типа могут быть использованы только в выражениях булевского типа и в операциях сравнения; при этом сравниваются порядковые номера значений.
Логическая структура.
Один из способов образования новых типов из уже существующих - ограничение допустимого диапазона значений некоторого стандартного скалярного типа или рамок описанного перечислимого типа. Это ограничение определяется заданием минимального и максимального значений диапазона. При этом изменяется диапазон допустимых значений по отношению к базовому типу, но представление в памяти полностью соответствует базовому типу.
Машинное представление.
Данные интервального типа могут храниться в зависимости от верхней и нижней границ интервала независимо от входящего в этот предел количества значений в виде, представленном в таблице 2.4. Для данных интервального типа требуется память размером один, два или четыре байта, например,
var A: 220..250; (* Занимает 1 байт *)
В: 2221..2226; (* Занимает 2 байта *)
C: 'A'..'K'; (* Занимает 1 байт *)
begin A:=240; C:='C'; B:=2222; end.
После выполнения данной программы содержимое памяти будет следующим:
A - 11110000; C - 01000011; B - 10101110 00001000.
Операции.
На физическом уровне над переменными интервального типа определены операции создания, уничтожения, выбора, обновления. Дополнительные операции определены базовым типом элементов интервального типа.
| Базовый тип | Максимально допустимый диапазон | Размер требуемой памяти |
| ShortInt | -128..127 | 1 байт |
| Integer | -32768..32767 | 2 байта |
| LongInt | -2147483648..2147483647 | 4 байта |
| Byte | 0..255 | 1 байт |
| Word | 0..65535 | 2 байта |
| Char | chr(ord(0))..chr(ord(255)) | 1 байт |
| Boolean | False..True | 1 байт |
Таблица 2.4
Примечание: запись chr(ord(0)) в таблице следует понимать как: символ с кодом 0.
А) Интервальный тип от символьного: определение кода символа и, наоборот, символа по его коду.
Пусть задана переменная типа tz:'d'..'h'. Данной переменной присвоено значение 'e'. Байт памяти отведенный под эту переменную будет хранить ASCII-код буквы 'e' т.е. 01100101 (в 10-ом представлении 101).
Б) Интервальный тип от перечислимого: определение порядкового номера идентификатора по его значению и, наоборот, по номеру идентификатора - его значение.
На логическом уровне все операции, разрешенные для данных базового типа, возможны и для данных соответствующих интервальных типов.
Тип указателя представляет собой адрес ячейки памяти (в подавляющем большинстве современных вычислительных систем размер ячейки - минимальной адресуемой единицы памяти - составляет один байт). При программировании на низком уровне - в машинных кодах, на языке Ассемблера и на языке C, который специально ориентирован на системных программистов, работа с адресами составляет значительную часть программных кодов. При решении прикладных задач с использованием языков высокого уровня наиболее частые случаи, когда программисту могут понадобиться указатели, следующие:
1) При необходимости представить одну и ту же область памяти, а следовательно, одни и те же физические данные, как данные разной логической структуры. В этом случае в программе вводятся два или более указателей, которые содержат адрес одной и той же области памяти, но имеют разный тип (см.ниже). Обращаясь к этой области памяти по тому или иному указателю, программист обрабатывает ее содержимое как данные того или иного типа.
2) При работе с динамическими структурами данных,что более важно. Память под такие структуры выделяется в ходе выполнения программы, стандартные процедуры/функции выделения памяти возвращают адрес выделенной области памяти - указатель на нее. К содержимому динамически выделенной области памяти программист может обращаться только через такой указатель.
Физическое представление адреса существенно зависит от аппаратной архитектуры вычислительной системы. Рассмотрим в качестве примера структуру адреса в микропроцессоре i8086.
Машинное слово этого процессора имеет размер 16 двоичных разрядов. Если использовать представление адреса в одном слове, то можно адресовать 64 Кбайт памяти, что явно недостаточно для сколько-нибудь серьезного программного изделия. Поэтому адрес представляется в виде двух 16-разрядных слов - сегмента и смещения. Сегментная часть адреса загружается в один из специальных сегментных регистров (в i8086 таких регистров 4). При обращении по адресу задается идентификатор сегментного регистра и 16-битное смещение. Полный физический (эффективный) адрес получается следующим образом. Сегментная часть адреса сдвигается на 4 разряда влево, освободившиеся слева разряды заполняются нулями, к полученному таким образом коду прибавляется смещение, как показано на рис. 2.8.
Полученный эффективный адрес имеет размер 20 двоичных разрядов, таким образом, он позволяет адресовать до 1 Мбайт памяти.
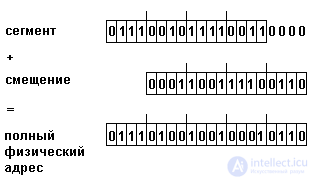
Рис 2.8. Вычисление полного адреса в микропроцессоре i8086.
Еще раз повторим, что физическая структура адреса принципиально различна для разных аппаратных архитектур. Так, например, в микропроцессоре i386 обе компоненты адреса 32-разрядные; в процессорах семейства S/390 адрес представляется в виде 31-разрядного смещения в одном из 19 адресных пространств, в процессоре Power PC 620 одним 64-разрядным словом может адресоваться вся как оперативная, так и внешняя память.
Операционная система MS DOS была разработана именно для процессора i8086 и использует описанную структуру адреса даже, когда выполняется на более совершенных процессорах. Однако, это сегодня единственная операционная система, в среде которой программист может работать с адресами в реальной памяти и с физической структурой адреса. Все без исключения современные модели процессоров аппаратно выполняют так называемую динамическую трансляцию адресов и совместно с современными операционными системами обеспечивают работу программ в виртуальной (кажущейся) памяти. Программа разрабатывается и выполняется в некоторой виртуальной памяти, адреса в которой линейно изменяются от 0 до некоторого максимального значения. Виртуальный адрес представляет собой число - номер ячейки в виртуальном адресном пространстве. Преобразование виртуального адреса в реальный производится аппаратно при каждом обращении по виртуальному адресу. Это преобразование выполняется совершенно незаметно (прозрачно) для программиста, поэтому в современных системах программист может считать физической структурой адреса структуру виртуального адреса. Виртуальный же адрес представляет собой целое число без знака. В разных вычислительных системах может различаться разрядность этого числа. Большинство современных систем обеспечивают 32-разрядный адрес, позволяющий адресовать до 4 Гбайт памяти, но уже существуют системы с 48 и даже 64-разрядными адресами.
В программе на языке высокого уровня указатели могут быть типизированными и нетипизированными. При объявлении типизированного указателя определяется и тип объекта в памяти, адресуемого этим указателем. Так например, объявления в языке PASCAL:
Var ipt : ^integer; cpt : ^char;
или в языке C:
int *ipt; char *cpt;
означают, что переменная ipt представляет собой адрес области памяти, в которой хранится целое число, а cpt - адрес области памяти, в которой хранится символ. Хотя физическая структура адреса не зависит от типа и значения данных, хранящихся по этому адресу, компилятор считает указатели ipt и cpt имеющими разный тип, и в Pascal оператор:
cpt := ipt;
будет расценен компилятором как ошибочный (компилятор C для аналогичного оператора присваивания ограничится предупреждением). Таким образом, когда речь идет об указателях типизированных, правильнее говорить не о едином типе данных "указатель", а о целом семействе типов: "указатель на целое", "указатель на символ" и т.д. Могут быть указатели и на более сложные, интегрированные структуры данных, и указатели на указатели.
Нетипизированный указатель - тип pointer в Pascal или void * в C - служит для представления адреса, по которому содержатся данные неизвестного типа. Работа с нетипизированными указателями существенно ограничена, они могут использоваться только для сохранения адреса, обращение по адресу, задаваемому нетипизированным указателем, невозможно.

Основными операциями, в которых участвуют указатели являются присваивание, получение адреса, выборка.
Присваивание является двухместной операцией, оба операнда которой - указатели. Как и для других типов, операция присваивания копирует значение одного указателя в другой, в результате оба указателя будут содержать один и тот же адрес памяти. Если оба указателя, участвующие в операции присваивания типизированные, то оба они должны указывать на объекты одного и того же типа.
Операция получения адреса - одноместная, ее операнд может иметь любой тип, результатом является типизированный (в соответствии с типом операнда) указатель, содержащий адрес объекта-операнда.
Операция выборки - одноместная, ее операндом является типизированный (обязательно!) указатель, результат - данные, выбранные из памяти по адресу, заданному операндом. Тип результата определяется типом указателя-операнда.
Перечисленных операций достаточно для решения задач прикладного программирования поэтому набор операций над указателями, допустимых в языке Pascal, этим и ограничивается. Системное программирование требует более гибкой работы с адресами, поэтому в языке C доступны также операции адресной арифметики, которые описываются ниже.
К указателю можно прибавить целое число или вычесть из него целое число. Поскольку память имеет линейную структуру, прибавление к адресу числа даст нам адрес области памяти, смещенной на это число байт (или других единиц измерения) относительно исходного адреса. Результат операций "указатель + целое", "указатель - целое" имеет тип "указатель".
Можно вычесть один указатель из другого (оба указателя-операнда при этом должны иметь одинаковый тип). Результат такого вычитания будет иметь тип целого числа со знаком. Его значение показывает на сколько байт (или других единиц измерения) один адрес отстоит от другого в памяти.
Отметим, что сложение указателей не имеет смысла. Поскольку программа разрабатывается в относительных адресах и при разных своих выполнениях может размещаться в разных областях памяти, сумма двух адресов в программе будет давать разные результаты при разных выполнениях. Смещение же объектов внутри программы друг относительно друга не зависит от адреса загрузки программы, поэ- тому результат операции вычитания указателей будет постоянным, и такая операция является допустимой.
Операции адресной арифметики выполняются только над типизированными указателями. Единицей измерения в адресной арифметике является размер объекта, который указателем адресуется. Так, если переменная ipt определена как указатель на целое число (int *ipt), то выражение ipt+1 даст адрес, больший не на 1, а на количество байт в целом числе (в MS DOS - 2). Вычитание указателей также дает в результате не количество байт, а количество объектов данного типа, помещающихся в памяти между двумя адресами. Это справедливо как для указателей на простые типы, так и для указателей на сложные объекты, размеры которых составляют десятки, сотни и более байт.
В связи с имеющимися в языке C расширенными средствами работы с указателями, следует упомянуть и о разных представлениях указателей в этом языке. В C указатели любого типа могут быть ближними (near) и дальними (far) или (huge). Эта дифференциация связана с физической структурой адреса в i8086, которая была рассмотрена выше. Ближние указатели представляют собой смещение в текущем сегменте, для представления такого указателя достаточно одного 16-разрядного слова. Дальние указатели представляются двумя 16-разрядными словами - сегментом и смещением. Разница между far или huge указателями состоит в том, что для первых адресная арифметика работает только со смещением, не затрагивая сегментную часть адреса, таким образом, операции адресной арифметики могут изменять адрес в диапазоне не более 64 Кбайт; для вторых - в адресной арифметике участвует и сегментная часть, таким образом, предел изменения адреса - 1 Мбайт.
Впрочем, это различие в представлении указателей имеется только в системах программирования, работающих в среде MS DOS, в современных же операционных системах, поддерживающих виртуальную адресацию, различий между указателями нет, все указатели можно считать гигантскими.
На этом все! Теперь вы знаете все про простые структуры данных, Помните, что это теперь будет проще использовать на практике. Надеюсь, что теперь ты понял что такое простые структуры данных, представление простых типов в памяти и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Структуры данных
Часть 1 2. ПРОСТЫЕ СТРУКТУРЫ ДАННЫХ и представление их в памяти компьютера
Часть 2 2.3. Логический тип - 2. ПРОСТЫЕ СТРУКТУРЫ ДАННЫХ и представление
Комментарии
Оставить комментарий
Структуры данных
Термины: Структуры данных