Лекция
Привет, сегодня поговорим про улучшенные алгоритмы сортировки на е языка си , обещаю рассказать все что знаю. Для того чтобы лучше понимать что такое улучшенные алгоритмы сортировки на е языка си , настоятельно рекомендую прочитать все из категории Алгоритмы и теория алгоритмов.
Все алгоритмы, рассмотренные в предыдущих разделах, имеют один фатальный недостаток — время их выполнения имеет порядок n2. Это делает сортировку больших объемов данных очень медленной. По существу, в какой-то момент эти алгоритмы становятся слишком медленными, чтобы их применять[1]. К сожалению, страшные истории о "сортировках, которые продолжались три дня", зачастую реальны. Когда сортировка занимает слишком много времени, причиной этому обычно является неэффективность использованного в ней алгоритма. Тем не менее, первой реакцией в такой ситуации часто становится оптимизация кода вручную, возможно, путем переписывания его на ассемблере. Несмотря на то, что ручная оптимизация иногда ускоряет процедуру на постоянный множитель[2], если алгоритм сортировки не эффективен, сортировка всегда будет медленной независимо от того, насколько оптимально написан код. Следует помнить, если время работы процедуры пропорционально n2, то увеличение скорости кода или компьютера даст лишь небольшое улучшение[3], поскольку время выполнения увеличивается как n2. (На самом деле, кривая n2 на рис. 21.1 (пузырьковая сортировка) растянута вправо, но в остальном соответствует действительности.) Существует правило: если используемый в программе алгоритм слишком медленный сам по себе, никакой объем ручной оптимизации не сделает программу достаточно быстрой. Решение заключается в применении лучшего алгоритма сортировки.
Ниже описаны два прекрасных метода сортировки. Первый называется сортировкой Шелла. Второй — быстрая сортировка — обычно считается самым лучшим алгоритмом сортировки. Оба метода являются более совершенными способами сортировки и имеют намного лучшую общую производительность, чем любой из приведенных выше простых методов.
Сортировка Шелла называется так по имени своего автора, Дональда Л. Шелла (Donald Lewis Shell)[4]. Однако это название закрепилось, вероятно, также потому, что действие этого метода часто иллюстрируется рядами морских раковин, перекрывающих друг друга (по-английски "shell" — "раковина"). Общая идея заимствована из сортировки вставками и основывается на уменьшении шагов[5]. Рассмотрим диаграмму на рис. 21.2. Сначала сортируются все элементы, отстоящие друг от друга на три позиции. Затем сортируются элементы, расположенные на расстоянии двух позиций. Наконец, сортируются все соседние элементы.
Рис. 21.2. Сортировка Шелла
Проход 1 f d a c b e
\___\___\___/ / /
\___\_____/ /
\_______/
Проход 2 c b a f d e
\___\___|___|___/ /
\______|______/
Проход 3 a b c d e f
|___|___|___|___|___|
Результат a b c d e f
|
То, что этот метод дает хорошие результаты, или даже то, что он вообще сортирует массив, увидеть не так просто. Тем не менее, это верно. Каждый проход сортировки распространяется на относительно небольшое количество элементов либо на элементы, расположенные уже в относительном порядке. Поэтому сортировка Шелла эффективна, а каждый проход повышает упорядоченность[6].
Конкретная последовательность шагов может быть и другой. Единственное правило состоит в том, чтобы последний шаг был равен 1. Например, такая последовательность:
9, 5, 3, 2, 1
дает хорошие результаты и применяется в показанной здесь реализации сортировки Шелла. Следует избегать последовательностей, которые являются степенями числа 2 — по математически сложным соображениям они уменьшают эффективность сортировки (но сортировка по-прежнему работает!).
/* Сортировка Шелла. */
void shell(char *items, int count)
{
register int i, j, gap, k;
char x, a[5];
a[0]=9; a[1]=5; a[2]=3; a[3]=2; a[4]=1;
for(k=0; k < 5; k++) {
gap = a[k];
for(i=gap; i < count; ++i) {
x = items[i];
for(j=i-gap; (x < items[j]) && (j >= 0); j=j-gap)
items[j+gap] = items[j];
items[j+gap] = x;
}
}
}
Вы могли заметить, что внутренний цикл for имеет два условия проверки. Очевидно, что сравнение x<items[j] необходимо для процесса сортировки. Выражение j>=0 предотвращает выход за границу массива items. Эти дополнительные проверки в некоторой степени понижают производительность сортировки Шелла.
В слегка модифицированных версиях данного метода сортировки применяются специальные элементы массива, называемые сигнальными метками. Об этом говорит сайт https://intellect.icu . Они не принадлежат к собственно сортируемому массиву, а содержат специальные значения, соответствующие наименьшему возможному и наибольшему возможному элементам[7]. Это устраняет необходимость проверки выхода за границы массива. Однако применение сигнальных меток элементов требует конкретной информации о сортируемых данных, что уменьшает универсальность функции сортировки.
Анализ сортировки Шелла связан с очень сложными математическими задачами, которые выходят далеко за рамки этой книги. Примите на веру, что время сортировки пропорционально
n1,2
при сортировке n элементов[8]. А это уже существенное улучшение по сравнению с сортировками порядка n2. Чтобы понять, насколько оно велико, обратитесь к рис. 21.3, на котором показаны графики функций n2 и n1,2. Тем не менее, не стоит чрезмерно восхищаться сортировкой Шелла — быстрая сортировка еще лучше.
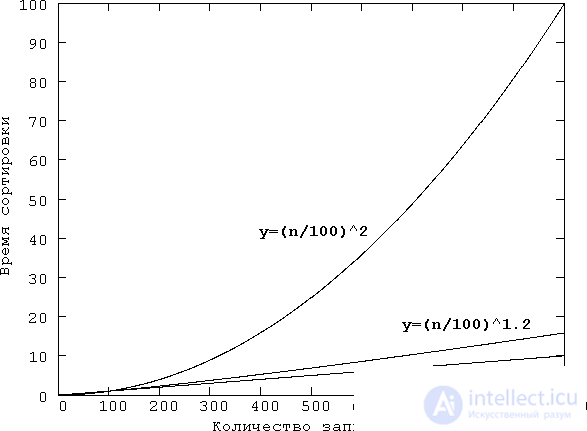
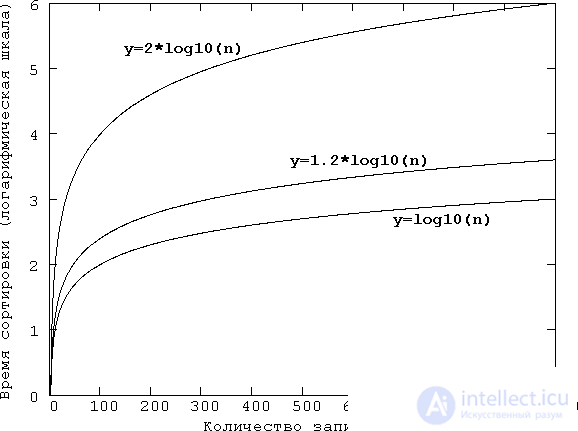
Рис. 21.3. Попытка наглядного представления кривых n2 и n1,2. Хотя вычертить эти кривые с точным соблюдением масштаба на каком-нибудь значимом для целей сортировки интервале изменения количества записей (n), например, на интервале от 0 до 1000, не представляется возможным, получить представление о поведении этих кривых можно с помощью графиков функций у=(n/100)2 и у=(n/100)1,2. Для сравнения построен также график прямой у=n/100. Кроме того, чтобы получить представление о росте этих кривых, можно на оси ординат принять логарифмический масштаб, — это все равно, что начертить логарифмы этих функций
|
Быстрая сортировка, придуманная Ч. А. Р. Хоаром[9] (Charles Antony Richard Hoare) и названная его именем, является самым лучшим методом сортировки из представленных в данной книге и обычно считается лучшим из существующих в настоящее время алгоритмом сортировки общего назначения. В ее основе лежит сортировка обменами — удивительный факт, учитывая ужасную производительность пузырьковой сортировки!
Быстрая сортировка построена на идее деления. Общая процедура заключается в том, чтобы выбрать некоторое значение, называемоекомпарандом (comparand)[10], а затем разбить массив на две части. Все элементы, большие или равные компаранду, перемещаются на одну сторону, а меньшие — на другую. Потом этот процесс повторяется для каждой части до тех пор, пока массив не будет отсортирован. Например, если исходный массив состоит из символов fedacb, а в качестве компаранда используется символ d, первый проход быстрой сортировки переупорядочит массив следующим образом:
Начало f e d a c b Проход 1 b c a d e f
Затем сортировка повторяется для обеих половин массива, то есть bса и def. Как вы видите, этот процесс по своей сути рекурсивный, и, действительно, в чистом виде быстрая сортировка реализуется как рекурсивная функция[11].
Значение компаранда можно выбирать двумя способами — случайным образом либо усреднив небольшое количество значений из массива. Для оптимальной сортировки необходимо выбирать значение, которое расположено точно в середине диапазона всех значений. Однако для большинства наборов данных это сделать непросто. В худшем случае выбранное значение оказывается одним из крайних. Тем не менее, даже в этом случае быстрая сортировка работает правильно. В приведенной ниже версии быстрой сортировки в качестве компаранда выбирается средний элемент массива.
/* Функция, фызывающая функцию быстрой сортировки. */
void quick(char *items, int count)
{
qs(items, 0, count-1);
}
/* Быстрая сортировка. */
void qs(char *items, int left, int right)
{
register int i, j;
char x, y;
i = left; j = right;
x = items[(left+right)/2]; /* выбор компаранда */
do {
while((items[i] < x) && (i < right)) i++;
while((x < items[j]) && (j > left)) j--;
if(i <= j) {
y = items[i];
items[i] = items[j];
items[j] = y;
i++; j--;
}
} while(i <= j);
if(left < j) qs(items, left, j);
if(i < right) qs(items, i, right);
}
В этой версии функция quick() готовит вызов главной сортирующей функции qs(). Это обеспечивает общий интерфейс с параметрами itemsи count, но несущественно, так как можно вызывать непосредственно функцию qs() с тремя аргументами.
Получение количества сравнений и обменов, которые выполняются при быстрой сортировке, требует математических выкладок, которые выходят за рамки данной книги. Тем не менее, среднее количество сравнений равно
n log n
а среднее количество обменов примерно равно
n/6 log n
Эти величины намного меньше соответствующих характеристик рассмотренных ранее алгоритмов сортировки.
Необходимо упомянуть об одном особенно проблематичном аспекте быстрой сортировки. Если значение компаранда в каждом делении равно наибольшему значению, быстрая сортировка становится "медленной сортировкой" со временем выполнения порядка n2. Поэтому внимательно выбирайте метод определения компаранда. Этот метод часто определяется природой сортируемых данных. Например, в очень больших списках почтовой рассылки, в которых сортировка происходит по почтовому индексу, выбор прост, потому что почтовые индексы довольно равномерно распределены — компаранд можно определить с помощью простой алгебраической функции. Однако в других базах данных зачастую лучшим выбором является случайное значение. Популярный и довольно эффективный метод — выбрать три элемента из сортируемой части массива и взять в качестве компаранда значение, расположенное между двумя другими.

[1]Конечно, это не означает, что функция f(n)=n2 в какой-то точке возрастает скачкообразно. Вовсе нет! Просто при увеличении размера массива n меняется характер сортировки, из внутренней она фактически становится внешней, когда массив не помещается в оперативной памяти и начинается интенсивная подкачка страниц, а за ней пробуксовывание механизма виртуальной памяти. Вот эти-то события действительно могут наступить внезапно, и тогда может показаться, что незначительное увеличение сортируемого массива или просто добавление какой-либо совершенно незначительной задачи приведет к катастрофическому увеличению времени сортировки (например в десятки раз!).
[2]Отдельные программисты — "любители рассказов о рыбной ловле" — клянутся об увеличении эффективности сначала наполовину, затем вдвое-втрое, к середине рассказа — на порядок, а к концу рассказа — на несколько порядков. (Такое не получается даже в специально подобранных примерах для рекламного проспекта по языку Ассемблера.) На самом деле производительность может даже упасть. В лучшем случае удается повысить ее на 10-12% для реально значимых производственных задач. При этом чем сложнее алгоритм, тем сложнее переписать его на Ассемблере и тем проще сделать в нем ошибку при переписывании, а тем более сложнее ее найти. Кроме того, следует учитывать и такой фактор: например, программу писал какой-то квалифицированный программист, который выбрал простой (но не очень эффективный — при чем об этом он знал) алгоритм потому, что менеджеры настаивали на скорейшем завершении программы, а оптимизацию этой программы те же менеджеры поручат весьма не самым квалифицированным специалистам! Эффект действительно будет на несколько порядков больше, но в совершенно противоположную сторону! Ведь с таким же успехом для "улучшения" трагедий Шекспира за пишущие машинки можно было усадить стадо обезьян!
[3]Действительно, чтобы увеличить в m раз размер сортируемого массива при сохранении времени сортировки, быстродействие процессора придется увеличить в m2 раз при условии, что время доступа к элементам массива не увеличится, т.е. не уменьшится, например, эффективность подкачки страниц.
[4]Считается, что Дональд Л. Шелл описал свой метод сортировки 28 июля 1959 года. Данный метод классифицируется какслияние с обменом; часто называется также сортировкой с убывающим шагом.
[5]Шаг — расстояние между сортируемыми элементами на конкретном этапе сортировки.
[6]Т.е. уменьшает количество беспорядков (инверсий).
[7]-∞ и +∞.
[8]Вообще говоря, время сортировки Шелла зависит от последовательности шагов. (Впрочем, минимум равен, конечно, n log2n.) Оптимальная последовательность не известна до сих пор. Дональд Кнут исследовал различные последовательности (не забыв и последовательность Фибоначчи). Фактически он пришел к выводу, что в определении наилучшей последовательности есть какое-то "колдовство". В 1969 г. Воган Пратт обнаружил, что если все шаги выбираются из множества чисел вида 2p3q, меньших n, то время работы будет порядка n(log n)2. А.А. Папернов и Г.В. Стасевич в 1965 г. доказали, что максимальное время сортировки Шелла не превосходит О(n1,5), причем уменьшить показатель 1,5 нельзя. Большое число экспериментов с сортировкой Шелла провели Джеймс Петерсон и Дэвид Л. Рассел в Стэнфордском университете в 1971 г. Они пытались определить среднее число перемещений при 100≤n≤250`000 для последовательно сти шагов 2k-1. Наиболее подходящими формулами оказались 1,21n1,26 и ,39n(ln n)-2,33n ln n. Но при изменении диапазона n оказалось, что коэффициенты в представлении степенной функцией практически не изменяются, а коэффициенты в логарифмическом представлении изменяются довольно резко. Поэтому естественно предположить, что именно степенная функция описывает истинное асимптотическое поведение сортировки Шелла.
[9]Встречается также написание Ч. Э. Р. Хоор.
[10]Компаранд — операнд в операции сравнения. Иногда называется также основой и критерием разбиения.
[11]Если хотите избежать рекурсии, не волнуйтесь, все очень легко переписывается даже для Фортрана IV, в упомянутой ранее литературе вы без труда найдете нужный нерекурсивный вариант.
На этом все! Теперь вы знаете все про улучшенные алгоритмы сортировки на е языка си , Помните, что это теперь будет проще использовать на практике. Надеюсь, что теперь ты понял что такое улучшенные алгоритмы сортировки на е языка си и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Алгоритмы и теория алгоритмов

Комментарии