Лекция
Привет, Вы узнаете о том , что такое задача о наименьшем покрытии графа, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое задача о наименьшем покрытии графа, покрытие графа , настоятельно рекомендую прочитать все из категории Алгоритмы и теория алгоритмов.
Рассмотрим неориентированный граф G = (V, E).
Независимое множество вершин (внутренне устойчивое множество) — это множество вершин графа G такое, что любые две вершины в нем не смежны, то есть никакая пара вершин не соединена ребром. Множество S ⊂ V, удовлетворяющее условию
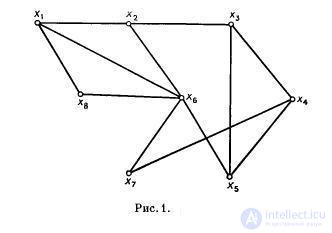
называется независимым множеством вершин. Для графа, изображенного на рисунке 1, независимыми являются {x7, x8, x2}, {x3, x1} множества вершин.
Независимое множество называется максимальным, когда нет другого независимого множества, в которое оно бы входило. Если множество удовлетворяет условию (1) и условию
является максимальным независимым множеством. Например, множества {x1, x3, x7} и {x4, x6} максимальные независимые, а {x7, x8, x2} — нет. В графе может быть более одного независимого множества.
Если Q является семейством всех независимых множеств графа G, то
называется числом независимости графа G, а множество S*, на котором достигается этот максимум, называется наибольшим независимым множеством.
Имеется n проектов, которые должны быть выполнены. Для выполнения проекта xi требуется некоторое подмножетсво Ri наличных ресурсов из множества {1, …, p}. Пусть каждый проект, задаваемый совокупностью средств, необходимых для его реализации, может быть выполнен за один и тот же промежуток времени. Построим граф G, каждая вершина которого соответствует некоторому проекту, а ребро (xi, xj) наличию общих средств обеспечения у проектов xi и xj. Максимальное независимое множество графа G представляет максимальное множество проектов, которое можно выполнить одновременно за один и тот же промежуток времени.
В динамической системе происходит постоянное обновление проектов через определенный промежуток времени, так что каждый раз нужно заново повторять процедуру построения максимального независимого множества в соответствующем графе G. На практике не всегда можно выполнить работы, соответствующие максимальному независимому множеству. Тогда можно каждой работе (вершине xi) сопоставить некоторый штраф pi, который будет увеличиваться с увеличением срока исполнения работы. В каждый момент времени нужно выбирать из семейства максимальных независимых множеств такое множество, которое максимизирует некоторую функцию штрафов на вершинах, содержащихся в выбранном множестве.
Максимальный полный подграф (клика) графа G это порожденный подграф, построенный на подмножестве S вершин графа и являющийся полным и максимальным в том смысле, что любой другой подграф графа G, построенный на множестве вершин H, содержащем S, не является полным. То есть, в отличие от максимального независимого множества, в клике все вершины попарно смежны.
Аналогично тому, как было определено число независимости графа, с помощью соотношения (3) мы можем определить кликовое число графа (известное также как густота илиплотность). Это — максимальное число вершин в кликах данного графа. Тогда, образно говоря, у "плотного" графа кликовое число будет, вероятно, больше, а число независимости меньше, в то время как у "разреженного" графа, по всей вероятности, будет иметь место противоположное соотношение между этими числами.
Если граф небольшой (например, с числом вершин, не превосходящим 20), то построить максимальное независимое множество можно последовательным перебором независимых множеств с одновременной проверкой каждого множества на максимальность. Если же вершин много, то этот процесс становится сложным технически. Число максимальных независимых множеств возрастает, но во время поиска большое число независимых множеств формируется, а затем вычеркивается, так как обнаруживается, что они содержатся в других, ранее полученных множествах и поэтому не являются максимальными.
Этот алгоритм является существенно упрощенным перебором, использующим дерево поиска. В процессе поиска — на некотором этапе k — независимое множество вершин Sk расширяется путем добавления к нему подходящим образом выбранной вершины (чтобы получилось новое независимое множество Sk+1) на этапе k+1, и так поступают до тех пор, пока добавление вершин станет невозможным, а порождаемое множество не станет максимальным независимым множеством. Пусть Qk будет на этапе k наибольшим множеством вершин, для которогоSk ∩ Qk = Ø, то есть после добавления любой вершины из Qk к Sk получается независимое множество Sk+1. В некоторый произвольный момент работы алгоритма множество Qk состоит из вершин двух типов: подмножества Qk- тех вершин, которые уже использовались в процессе поиска для расширения множеств Sk, и подмножества Qk+ таких вершин, которые еще не использовались. Тогда дальнейшее ветвление в дереве поиска включает процедуру выбора вершины xik ∈ Qk+, добавление ее к Sk для построения множества
и порождение новых множеств:
и
Шаг возвращения алгоритма состоит в удалении вершины xik из Sk+1, чтобы вернуться к Sk, изъятии xik из старого множества Qk+ и добавлении xik к старому множеству Qk- для формирования новых множеств Qk+ и Qk-.
Множество Sk является максимальный независимым множеством только тогда, когда невозможно его дальнейшее расширение, т. е. когда Qk+ = Ø. Если Qk+ ≠ Ø, то текущее множество Skбыло расширено на некотором предшествующем этапе работы алгоритма путем добавления вершины из Qk-, и поэтому оно не является максимальным независимым множеством. Таким образом, необходимым и достаточным условием того, что Sk — максимальное независимое множество, является выполнение равенств
Если очередной этап работы алгоритма наступает тогда, когда существует некоторая вершина х ∈ Qk-, для которой E(x) ∩ Qk+ = Ø, то безразлично, какая из вершин, принадлежащих Qk+, используется для расширения Sk, и это справедливо при любом числе дальнейших ветвлений; вершина х не может быть удалена из Qp- на любом следующем шаге р > k. Об этом говорит сайт https://intellect.icu . Таким образом, условие
является достаточным для осуществления шага возвращения, поскольку из Sk при всяком дальнейшем ветвлении уже не получится максимальное независимое множество.
Как и во всяком методе, использующем дерево поиска, здесь выгодно стремиться начать шаги возвращения как можно раньше, поскольку это ограничит "размеры" "ненужной" части дерева поиска. Следовательно, целесообразно сосредоточить усилия на том, чтобы возможно раньше добиться выполнения условия (8) с помощью подходящего выбора вершин, используемых при расширении множеств Sk. На каждом следующем шаге процедуры можно выбирать для добавления к Sk любую вершину xik ∈ Qk+ на шаге возвращения xik будет удалена из Qk+ и включена в Qk-. Если вершину xk выбрать так, чтобы она принадлежала множеству E(х) при некоторой вершине х из Qk-, то на соответствующем шаге возвращения величина
уменьшится на единицу (по сравнению с тем значением, которое было до выполнения прямого шага в шага возвращения), так что условие (8) теперь станет выполняться раньше.
Таким образом, один из возможных способов выбора вершины xik для расширения множества Sk состоит, во-первых, в нахождении вершины x* ∈ Qk- с возможно меньшим значением величины Δ(х*) и, кроме того, в выборе вершины xi из множества E(x*) ∩ Qk+. Такой выбор вершины xik будет приводить на шаге возвращения к уменьшению величины Δ(x*) — каждый раз на единицу — до тех пор, пока вершина x* не станет удовлетворять условию (8) при выполнении шага возвращения.
Следует отметить, что поскольку на шаге возвращения вершина xik попадает в Qk-, то может оказаться, что при этом новом входе значение величины Δ меньше, чем для ранее фиксированной вершины x*. Значит, надо проверить, не ускорит ли эта новая вершина выполнение условия (8). Это особенно важно в начале ветвления, когда Qk- = Ø.
Для графа G = (V, E) доминирующее множество вершин (называемое также внешне устойчивым множеством) есть множество вершин S ⊆ E, выбранное так, что для каждой вершины xj, не входящей в S, существует дуга, идущая из некоторой вершины множества S в вершину xj.
Таким образом, S есть доминирующее множество вершин, если
Для графа, приведенного на рис. 2, множества вершин {x1, x4, x6}, {x1, x4}, {x3, x5, x6} являются доминирующими множествами.
Доминирующее множество называется минимальным, если нет другого доминирующего множества, содержащегося в нем.
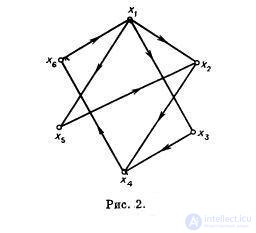
Множество S является минимальным доминирующим множеством, если оно удовлетворяет соотношению (10) и нет собственного подмножества в S, которое удовлетворяет условию, аналогичному (10). Так, например, для графа, приведенного на рис. 2, множество {x1, x4} — минимальное, а {x1, x4, x6} нет. Минимальным доминирующим множеством является также множество {x3, x5, x6}, и еще существует несколько таких множеств в этом графе. Следовательно, как и в случае максимальных независимых множеств, в графе может быть несколько минимальных доминирующих множеств, и они не обязательно содержат одинаковое число вершин.
Если Р — семейство всех минимальных доминирующих множеств графа, то число
называется числом доминирования графа G, а множество S*, на котором достигается минимум, называется наименьшим доминирующим множеством.
Для графа, приведенного на рис. 2, наименьшим доминирующим множеством является множество {x1, x4} и, следовательно, β[G] = 2.
Пусть At — транспонированная матрица смежности графа G с единичными диагональными элементами. Задача определения наименьшего доминирующего множества графа Gэквивалентна задаче нахождения такого наименьшего множества столбцов в матрице At, что каждая строка матрицы содержит единицу хотя бы в одном из выбранных столбцов. Эта последняя задача о поиске наименьшего множества столбцов, «покрывающих» все строки, изучалась довольно интенсивно под названием задачи о наименьшем покрытии (ЗНП).
В общей ЗНП матрица, состоящая из 0 и 1, не обязательно является квадратной. Кроме того, каждому столбцу j (в нашем случае каждой вершине xj) сопоставляется некоторая стоимость cj и требуется выбрать покрытие (или, в другой терминологии — для случая графов — доминирующее множество вершин) с наименьшей общей стоимостью). Поскольку задача построения наименьшего доминирующего множества вершин является весьма частной задачей о покрытии с cj = 1 для всех j = 1, …, n, то на первый взгляд кажется, что нахождение такого множества осуществляется на деле значительно проще, чем решение общей ЗНП.
ЗНП своим названием обязана следующей теоретико-множественной интерпретации. Даны множество R = {r1, …, rM} и семейство I = {S1, …, SN} множеств Sj ⊂ R. Любое подсемейство I′ = {Sj1, Sj2, …, Sjk} семейства I, такое, что
называется покрытием множества R, а множества Sji называются покрывающими множествами. Если вместе с соотношением (12) I′ удовлетворяет условию
т. е. множества Sji {i = 1, …, k} попарно не пересекаются, то называется разбиением множества R.
Если каждому Sj ∈ I поставлена в соответствие положительная стоимость cj, то ЗНП формулируется так: найти покрытие множества R, имеющее наименьшую стоимость, причем стоимость семейства I′ = {Sj1, …, Sjk} определяется как ∑i = 1k cji. Аналогично формулируется и задача о наименьшем разбиении (ЗНР).
Вследствие особой природы ЗНП часто удается сделать при ее исследовании определенные, хорошо известные заранее выводы и упрощения. Например:
Предположим, что все эти упрощения выполнены (если они возможны) и что исходная ЗНП уже переформулирована в соответствующей неприводимой форме.
ЗНР тесно связана с ЗНП, являясь по существу ЗНП с дополнительным ограничением (неперекрываемость). Это ограничение выгодно, если решать задачу с помощью некоторого метода, использующего дерево поиска: при таком ограничений может рано выясниться, что некоторые возможные ветвления дерева рассматривать не надо,
Простые методы решения ЗНР, использующие дерево поиска, были предложены Пирсом, Гарфинкелем и Немхаузеро.
Сущность этих методов такова. Вначале строятся "блоки" столбцов, по одному на каждый элемент rk из R, т. е. всего М блоков, k-й блок состоит из таких множеств семейства I(представленных столбцами), в которых содержится элемент ri, но отсутствуют элементы с меньшими индексами — r1, …, rk−1. Следовательно, каждое множество (столбец) появляется точно в одном определенном блоке и совокупность блоков может быть представлена в виде таблицы. В конкретных задачах некоторые из блоков могут отсутствовать.

В процессе работы алгоритма блоки отыскиваются последовательно и формирование k-гo блока начинается после того, как каждый элемент ri 1 ≤ i ≤ k − 1, будет покрыт частным решением. Таким образом, если какое-то множество в блоке k содержит элементы с индексами, меньшими k, то оно должно быть отброшено (на этом этапе) в соответствии с требованием неперекрываемости. Множества в пределах каждого блока размещаются в порядке возрастания их стоимостей и перенумеровываются так, что Sk теперь уже обозначает множество, соответствующее j-му столбцу таблицы.
Текущее "наилучшее" решение B′ сo стоимостью z′ известно на любом этапе поиска (B′ обозначает семейство соответствующих покрывающих множеств). Если В и z — соответствующие семейство и стоимость на данной стадий поиска, а Е — множество, представляющее те элементы (т. е. строки) ri, которые покрываются множествами из В, то одна из простых алгоритмов, использующих дерево поиска, можно вписать следующим образом.
Если поиск оканчивается с исчерпыванием блока 1 (см. шаг 4), то целесообразно переставить блоки в порядке возрастания числа столбцов (множеств) в каждом блоке. Это может быть осуществлено (перед построением исходной таблицы) перенумерацией элементов (строк) r1 … rM в порядке увеличения числа множеств из S, содержащих соответствующие элементы.
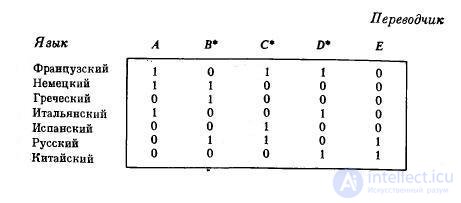
Предположим, что организации нужно нанять переводчиков французского, немецкого, греческого, итальянского, испанского, русского и китайского языков на английский и что имеется пять кандидатур А, В, С, D и Е. Каждая кандидатура владеет только некоторым собственным подмножеством из указанного выше множества языков и требует вполне определенную зарплату. Необходимо решить, каких переводчиков (с указанных выше языков на английский) надо нанять, чтобы затраты на зарплату были наименьшими. Это задача о наименьшем покрытии.
Если, например, требования на оплату труда у всех претендентов одинаковые и группы языков, на которых они говорят, указаны ниже в матрице Т, то решение задачи будет таким: нужно нанять переводчиков В, С, D.
Предположим, что некоторое количество единиц информации хранится в N массивах длины cj, j = 1, 2, …, N, причем на каждую единицу информации отводится по меньшей мере один массив. В некоторый момент делается запрос о М единицах информации. Они могут быть получены различными способами при помощи поиска в массиве. Для того чтобы получить все Mединиц информации и при этом произвести просмотр массивов наименьшей длины, надо решить ЗНП, вкоторой элемент ti j матрицы T равен 1, если информация i находится в массиве, и 0 в противном случае.
Пусть вершины неориентированного графе G представляют аэропорты, а дуги графа G — этапы полетов (беспосадочные перелеты), которые осуществляются в заданное время. Любой маршрут в этом графе (удовлетворяющий ряду условий, которые могут встретиться на практике) соответствует некоторому реально выполнимому маршруту полета. Пусть имеется N таких возможных маршрутов и для каждого из них каким-то способом подсчитана его стоимость (например, стоимость j-го маршрута равна cj). Задача нахождения множества маршрутов, имеющего наименьшую суммарную стоимость и такого, что каждый этап полета содержится хотя бы в одном выбранном маршруте, является задачей о наименьшем покрытии с матрицейТ = [ti j] в которой элемент ti j равен 1, если i-й этап содержится в j-м маршруте, и равен 0 в противном случае.
Выводы из данной статьи про задача о наименьшем покрытии графа указывают на необходимость использования современных методов для оптимизации любых систем. Надеюсь, что теперь ты понял что такое задача о наименьшем покрытии графа, покрытие графа и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Алгоритмы и теория алгоритмов

Комментарии