Лекция
Это окончание невероятной информации про производительность запросов к хранилищу данных.
...
происходит.
Шаг 4. Локализовать узкие места. Запрос, который выполняется медленно, может содержать много предложений и предикатов. Если это так – нужно определить, какие предложения или предикаты приводят к плохой производительности. Если удалить одно или два предложения или предиката, производительность выполнения запроса возрастает значительно. Эти предложения являются критическими параметрами выполнения запроса.
Можно поэкспериментировать с запросом, поочередно удаляя из него предложения или предикаты до тех пор, пока не будет достигнут подходящий уровень производительности. Локализуйте критические предложения и предикаты.
Примеры.
Шаг 5. Создать индексы для одной колонки для критических параметров. Если завершены шаги 1-4 и запрос все еще не удовлетворяет требованиям производительности, можно попытаться создать индексы специально для этого запроса, чтобы увеличить его производительность. В общем, индексы для одной колонки предпочтительнее, чем составные индексы, так как более вероятно их использование в других запросах. Попытайтесь увеличить производительность запроса с индексом для одной колонки, прежде чем разрабатывать многоколоночные индексы.
Локализуйте следующие колонки таблицы из запроса, которые не имеют индекса.
Сравните эти колонки с критическими факторами, определенными на шаге 4. Каждая из колонок, идентифицированная выше, должна соответствовать одному из критических предложений или предикатов, определенных на шаге 4. Если это так, создайте индекс для каждой из этих колонок. Определите, будет ли добавление этих индексов изменять план запроса. Если изменения будут – выполните запрос, чтобы определить, увеличилась ли производительность после добавления этих индексов.
Если добавление индексов не увеличивает производительность значительно, создайте другие индексы для других колонок из списка критических. Если не удается увеличить производительность запроса за счет создания индексов для одной колонки, то перейдите к следующему шагу.
Шаг 6. Создать индексы для нескольких колонок. Процедура идентификации колонок для создания составных индексов состоит в следующем.
Типы составных индексов приведены ниже.
Шаг 7. Удалить все индексы, которые не используются в плане запроса. Как уже указывалось выше, индексы замедляют выполнение команд DML, а их сопровождение требует времени и увеличивает стоимость обработки. Следовательно, вам следует проследить за использованием всех созданных индексов и удалить те, которые не используются запросом.
В этом разделе мы рассмотрим некоторые особенности, которые связаны с оптимизацией запросов к схемам типа "звезда", характерным для ХД. Изложение будет основываться на возможностях СУБД семейства MS SQL Server.
Обработка таблицы фактов является самой продолжительной частью выполнения запроса к схеме "звезда" в реляционном ХД на многомерной модели. Как правило, даже избирательные запросы получают на порядок больше строк из таблицы фактов, нежели из любого измерения. Поэтому использование наилучшего пути доступа в таблицу фактов важно для высокой производительности запроса.
СУБД семейства MS SQL Server применяют оптимизатор запросов на основе стоимости, то есть оптимизатор пытается создать план выполнения с минимальной оценочной стоимостью. В контексте хранения данных главная задача состоит в следующем: убедиться, что оптимизатор запроса оценивает однозначные альтернативы путей доступа для плана выполнения запроса к схеме "звезда". В оптимизатор запросов СУБД MS SQL Server включено несколько функций, автоматически обеспечивающих производительные планы выполнения запросов к схеме типа "звезда".
Запросы к схеме типа "звезда" можно разделить на три группы, как показано на рис. 24.1.
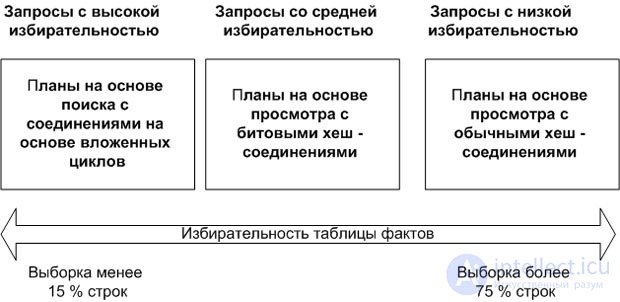
Эти три основные группы также позволяют оптимизатору определять правильные планы для таких запросов. Оптимизатор MS SQL Server основан на главном принципе избирательности запросов по отношению к таблице фактов. Запрос тем более избирателен, чем меньше строк из таблицы фактов он употребляет. Проценты строк, полученных из таблицы фактов, используются для создания классов запросов. Эти проценты отражают значения из типичных запросов клиентов, но не являются строгими границами для создания определений пути доступа.
В первый класс включены высокоизбирательные запросы, обрабатывающие до 15% строк таблицы фактов. Второй класс, со средней избирательностью, содержит запросы, обрабатывающие от 15 до 75% строк таблицы фактов. Запросы в третьем классе, с низкой избирательностью, требуют обработки более 75% строк таблицы фактов. Прямоугольники на рисунке показывают основные планы выполнения запросов для каждого класса избирательности.
Так как высокоизбирательные запросы к схеме типа "звезда" обычно получают не более 10-15% строк таблицы фактов, им можно позволить случайный доступ к таблице. Поэтому планы запросов для этого класса основаны на соединениях вложенных циклов вместе с поисками индексов (некластеризованных) и поиском закладок в таблице фактов. Так как они выполняют произвольный ввод/вывод в таблицу фактов, последовательный ввод/вывод, при получении больших количеств таблицы фактов, получается более производительным. Поэтому по мере роста количества строк, получаемых из таблицы фактов, выше определенного предела, применяется другой план запроса.
Поскольку запросы к схеме типа "звезда" средней избирательности обрабатывают значительную часть строк таблицы фактов, для доступа в таблицу фактов обычно применяются хэш-соединения со сканированием таблицы фактов или сканирование диапазона таблицы фактов. MS SQL Server использует растровые фильтры для улучшения производительности хэш-соединений.
Реализация соединения для каждого соединения – хэш-соединение, которое позволяет MS SQL Server взять информацию о соответствующих строках из таблиц измерений и получить информацию об уменьшении кардинальности соединения для обеих таблиц измерений. Физический оператор доступа к данным (например, сканирование таблицы) использует эту информацию о строках таблицы измерения, чтобы исключить строки таблицы фактов, которые не соответствуют условиям соединения против измерений.
Оптимизатор убирает эти строки таблицы фактов как можно раньше в процессе обработки запроса. Это позволяет экономить время работы ЦП и, возможно, сократить ввод/вывод с диска, потому что убранные строки не нужно обрабатывать в дальнейших операторах плана запроса.
Процесс оптимизации использует стандартную эвристику для оптимизации запроса, чтобы создать исходный набор вариантов плана выполнения запроса. Затем вызываются специальные расширения, чтобы создать дополнительные варианты плана запроса.
В случае хранения данных расширение определяет схемы типа "звезда", схемы типа "снежинка", последовательности запроса "звезда" и оценивает избирательность запроса относительно таблицы фактов. Если схема и форма запроса соответствуют последовательностям, оптимизатор автоматически добавляет последующие планы запроса в пространство планов, которое затем анализируется оптимизацией по стоимости, чтобы выбрать для выполнения лучший план запроса.
Во время выполнения запроса MS SQL Server следит за фактической избирательностью уменьшения соединения при выполнении. Если избирательность меняется, MS SQL Server динамически преобразует структуры данных информации об уменьшении соединения так, чтобы самая селективная применялась первой.
Большинство физических моделей ХД используют схему "звезда", но не полностью указывают отношения между таблицами измерения и фактов, как например, ограничениями внешнего ключа. Если ограничения внешнего ключа не заданы явно, оптимизатор запросов должен определять последовательности запросов в схеме "звезда" с помощью эвристики. Для этого применяется следующая эвристика.
Отметим, что это правила эвристики. В действительности ситуаций, в которых эвристика перепутает таблицу фактов с таблицей измерений, немного. Это влияет на выбор плана, но не изменяет правильности выбранного плана. Двоичные соединения, вовлеченные в запрос типа "звезда", затем сортируются по убыванию избирательности. Избирательность соединения в этом контексте определяется как отношение мощности ввода таблицы фактов и итоговой мощности соединения, то есть избирательность соединения показывает, насколько определенное измерение уменьшает мощность таблицы фактов. В общем случае следует рассматривать соединения с большей избирательностью первыми.
Процессор запроса MS SQL Server автоматически применяет оптимизацию к запросам, соответствующим схеме "звезда" и упомянутым выше условиям, когда получаемые планы запроса оцениваются как выгодные. Поэтому нет необходимости изменять свое приложение, чтобы воспользоваться этим способом увеличения производительности.
Чтобы ускорить обработку запросов в больших ХД, администраторы часто секционируют большие таблицы фактов по дате. Данные разделяются на группы файлов, уменьшая объем данных, который нужно просмотреть при обработке строк в определенном диапазоне; также это позволяет одновременно использовать производительность подлежащей дисковой системы, когда группы файлов расположены на многих физических дисках.
Как обсуждалось в предыдущих лекциях, секционирование успешно применяется для улучшения обработки запросов, особенно в больших приложениях поддержки решений.
В MS SQL Server 2008 включена новая функция — параллелизм секционированных таблиц (PTP), которая улучшает производительность запросов в случае секционирования, лучшим образом используя вычислительные мощности имеющегося оборудования, независимо от того, сколько секций затрагивает запрос или каков относительный размер отдельных секций. В типичном случае ХД с секционированной таблицей фактов пользователи смогут заметить значительное улучшение запросов, выполняющихся параллельно, особенно если количество доступных ядер процессора больше числа секций, затрагиваемых запросом. И эта новая функция работает сразу, без дополнительной настройки или изменений.
По мере того, как бизнес-аналитика становится популярной, предприятия добавляют все больше данных для анализа в свои ХД. Результат – экспоненциальный рост объема управляемых данных. Размер ХД утраивается каждые два года. Это ставит новые вопросы об управлении такими большими объемами данных и обеспечении приемлемой скорости выполнения запросов к ХД. Такие запросы обычно сложные, включающие много соединений и агрегатов, им нужен доступ к большим объемам данных. И многие запросы в рабочей нагрузке зависят от ввода-вывода.
Проблему помогает решить собственное сжатие данных. В MS SQL Server 2005 SP2 был включен новый формат хранения переменной длины под названием vardecimal для десятичных и числовых данных. Этот новый формат хранения может значительно уменьшить размер баз данных. Выигрыш в объеме может, в свою очередь, двумя способами улучшить производительность запросов, зависимых от ввода-вывода. Во-первых, нужно считывать меньше страниц, а во-вторых, так как данные хранятся в буферном пуле сжатыми, увеличивается ожидаемое время жизни страницы (иначе говоря, увеличивается вероятность, что нужная страница окажется в буфере). Конечно, выгода в объеме от сжатия данных приводит к нагрузке на ЦП в процессе сжатия и распаковки данных.
SQL Server 2008 использует формат хранения vardecimal, обеспечивая два вида сжатия: сжатие ROW и PAGE. Сжатие ROW расширяет формат хранения vardecimal за счет хранения всех типов данных фиксированной длины в формате хранения переменной длины.
Некоторые примеры типов данных фиксированной длины — integer, char и свободные типы данных. Несмотря на то, что MS SQL Server хранит эти типы данных в формате переменной длины, их семантика не меняется (с точки зрения приложения, тип данных продолжает быть фиксированной длины). Это значит, что можно воспользоваться преимуществами сжатия данных, не изменяя свои приложения.
Сжатие PAGE уменьшает избыточность данных в столбцах в одной или более строке на данной странице. Оно использует собственную реализацию алгоритма LZ78 (Лемпеля-Зива), сохраняя избыточные данные единожды на странице, ссылаясь затем на них из многих столбцов. Заметьте, что если вы применяете сжатие PAGE, сжатие ROW тоже используется.
Сжатие ROW и PAGE можно включить для таблицы, индекса или одной и более секций секционированных таблиц и индексов. Это дает полную гибкость выбора таблиц, индексов и секций для сжатия, позволяя найти баланс между выигрышем в объеме и нагрузкой на ЦП.
В SQL Server 2008 индексированные представления, выровненные по секциям, позволяют более эффективно создавать и управлять общими агрегатами в реляционном ХД, а также использовать их в тех сценариях, в которых раньше это было неэффективно. Это повышает производительность запроса. В типичном случае имеется таблица фактов, секционированная по дате. Индексированные представления (или общие агрегаты) определяются на этой таблице, чтобы ускорить запросы. При переключении на новую секцию таблицы соответствующие, определенные на секционированной таблице секции индексированных представлений, выровненных по секциям, тоже переключаются, причем автоматически.
Функция индексированных представлений, выровненных по секциям, дает преимущества индексированных представлений на больших секционированных таблицах без необходимости перестраивать агрегаты на всей секционированной таблице. К этим преимуществам относятся автоматическое поддержание агрегатов и сопоставление индексированного представления.
СУБД семейства MS SQL Server поддерживают секционирование по диапазону, позволяющее секционировать данные для простоты управления или группировать данные на основании схемы использования. Так, например, данные продаж можно секционировать по месяцам или кварталам. Можно сопоставить секцию с ее файловой группой, а файловую группу, в свою очередь, — с группой файлов. Это дает два преимущества. Во-первых, можно создавать резервные копии и восстанавливать секцию как независимый элемент. Во-вторых, можно сопоставить файловую группу с быстрой или медленной подсистемой ввода-вывода, в зависимости от схемы использования или загрузки запросами.
Важным моментом является схема доступа к данным. Запросы и операции DML могут нуждаться в доступе или манипуляциях только с частью секций. Поэтому если вы, например, анализируете данные продаж за 2008 год, вам требуется доступ только к соответствующим секциям; в идеальном варианте запросы, обращающиеся к данным в других секциях, не должны оказывать на вас никакого влияния (не считая ресурсов системы). В MS SQL Server 2005 одновременный доступ к различным секциям иногда приводит к блокировке таблицы, которая может затруднить доступ к другим секциям.
Чтобы снять такие ограничения, в SQL Server 2008 включен на уровне таблиц параметр, позволяющий контролировать укрупнение блокировок на уровне секции или таблицы. Политику укрупнения блокировок для таблицы можно изменить. Например, можно установить такое укрупнение блокировок:
ALTER TABLEset (LOCK_ESCALATION = AUTO)
Эта команда предписывает SQL Server выбрать подходящую для схемы таблицы гранулярность укрупнения блокировок. Если таблица не секционирована, укрупнение блокировок будет на уровне TABLE (таблицы). Если она секционирована, то гранулярность укрупнения блокировок будет на уровне секции. Этот параметр также используется в SQL Server как способ уменьшить вероятность гранулярности блокировки на уровне таблицы.
В этой лекции мы обсудили, как работают оптимизаторы запросов реляционных СУБД. В частности, представили короткий обзор функций СУБД семейства MS SQL Server 2008, которые помогут вам достичь большей производительности запросов поддержки решений в реляционных хранилищах данных.
Была рассмотрена важная для проектировщика ХД общая процедура настройки команды SELECT, результат выполнения которой не удовлетворяет требованиям производительности. Эта процедура является итерацией на пути построения оптимального набора индексов и состоит из семи шагов.
Исследование, описанное в статье про производительность запросов к хранилищу данных, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое производительность запросов к хранилищу данных и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Часть 1 Настройка производительности запросов к хранилищу данных
Часть 2 Статистическая коллекция MS SQL Server - Настройка производительности запросов к
Часть 3 Оптимизация запросов для схем типа "звезда" - Настройка производительности запросов
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL