Лекция
Привет, Вы узнаете о том , что такое big data, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое big data, mapreduce , настоятельно рекомендую прочитать все из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL.
В предыдущих статьях мы описали парадигму MapReduce, а также показали как на практике реализовать и выполнить MapReduce-приложение на стеке Hadoop. Пришла пора описать различные приемы, которые позволяют эффективно использовать MapReduce для решения практических задач, а также показать некоторые особенности Hadoop, которые позволяют упростить разработку или существенно ускорить выполнение MapReduce-задачи на кластере.
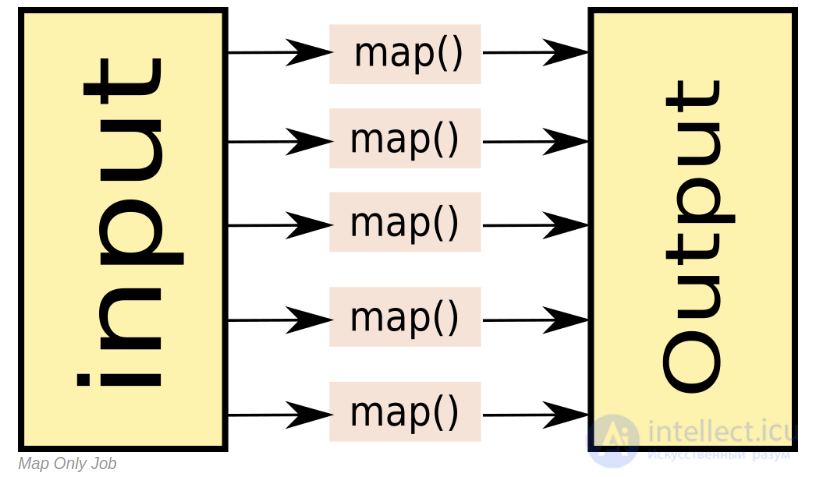
Как мы помним, MapReduce состоит из стадий Map, Shuffle и Reduce. Как правило, в практических задачах самой тяжелой оказывается стадия Shuffle, так как на этой стадии происходит сортировка данных. На самом деле существует ряд задач, в которых можно обойтись только стадией Map. Вот примеры таких задач:
Такие задачи решаются при помощи Map-Only. При создании Map-Only задачи в Hadoop нужно указать нулевое количество reducer’ов:
M
Пример конфигурации map-only задачи на hadoop:
| Native interface | Hadoop Streaming Interface |
Указать нулевое количество редьюсеров при конфигурации job’a:
Более развернутый пример по ссылке. |
Не указываем редьюсер и указываем нулевое количество редьюсеров Пример:
|
Map Only jobs на самом деле могут быть очень полезными. Например, в платформе Facetz.DCA для выявления характеристик пользователей по их поведению используется именно один большой map-only, каждый маппер которого принимает на вход пользователя и на выход отдает его характеристики.
Как я уже писал, обычно самая тяжелая стадия при выполнении Map-Reduce задачи – это стадия shuffle. Происходит это потому, что промежуточные результаты (выход mapper’a) записываются на диск, сортируются и передаются по сети. Однако существуют задачи, в которых такое поведение кажется не очень разумным. Например, в той же задаче подсчета слов в документах можно предварительно предагрегировать результаты выходов нескольких mapper’ов на одном узле map-reduce задачи, и передавать на reducer уже просуммированные значения по каждой машине.
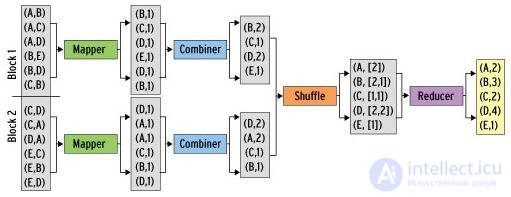
Combine. Взято по ссылке
В hadoop для этого можно определить комбинирующую функцию, которая будет обрабатывать выход части mapper-ов. Комбинирующая функция очень похожа на reduce – она принимает на вход выход части mapper’ов и выдает агрегированный результат для этих mapper’ов, поэтому очень часто reducer используют и как combiner. Важное отличие от reduce – на комбинирующую функцию попадают не все значения, соответствующие одному ключу.
Более того, hadoop не гарантирует того, что комбинирующая функция вообще будет выполнена для выхода mapper’a. Поэтому комбинирующая функция не всегда применима, например, в случае поиска медианного значения по ключу. Тем не менее, в тех задачах, где комбинирующая функция применима, ее использование позволяет добиться существенного прироста к скорости выполнения MapReduce-задачи.
Использование Combiner’a на hadoop:
| Native Interface | Hadoop streaming |
При конфигурации job-a указать класс-Combiner. Как правило, он совпадает с Reducer:
|
В параметрах командной строки указать команду -combiner. Об этом говорит сайт https://intellect.icu . Как правило, эта команда совпадает с командой reducer’a. Пример:
|
Бывают ситуации, когда для решения задачи одним MapReduce не обойтись. Например, рассмотрим немного видоизмененную задачу WordCount: имеется набор текстовых документов, необходимо посчитать, сколько слов встретилось от 1 до 1000 раз в наборе, сколько слов от 1001 до 2000, сколько от 2001 до 3000 и так далее.
Для решения нам потребуется 2 MapReduce job’а:
Решение на псевдокоде:

Для того, чтобы выполнить последовательность MapReduce-задач на hadoop, достаточно просто в качестве входных данных для второй задачи указать папку, которая была указана в качестве output для первой и запустить их по очереди.
На практике цепочки MapReduce-задач могут представлять собой достаточно сложные последовательности, в которых MapReduce-задачи могут быть подключены как последовательно, так и параллельно друг другу. Для упрощения управления такими планами выполнения задач существуют отдельные инструменты типа oozie и luigi, которым будет посвящена отдельная статья данного цикла.
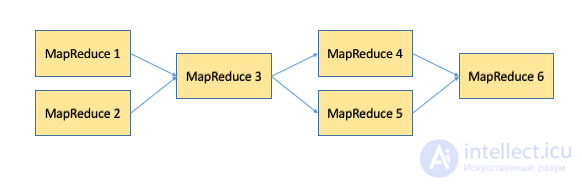
Пример цепочки MapReduce-задач.
Важным механизмом в Hadoop является Distributed Cache. Distributed Cache позволяет добавлять файлы (например, текстовые файлы, архивы, jar-файлы) к окружению, в котором выполняется MapReduce-задача.
Можно добавлять файлы, хранящиеся на HDFS, локальные файлы (локальные для той машины, с которой выполняется запуск задачи). Я уже неявно показывал, как использовать Distributed Cache вместе с hadoop streaming: добавляя через опцию -file файлы mapper.py и reducer.py. На самом деле можно добавлять не только mapper.py и reducer.py, а вообще произвольные файлы, и потом пользоваться ими как будто они находятся в локальной папке.
Использование Distributed Cache:
| Native API |
|
| Hadoop Streaming |
|
Те, кто привык работать с реляционными базами, часто пользуются очень удобной операцией Join, позволяющей совместно обработать содержание некоторых таблиц, объединив их по некоторому ключу. При работе с большими данными такая задача тоже иногда возникает. Рассмотрим следующий пример:
Имеются логи двух web-серверов, каждый лог имеет следующий вид:
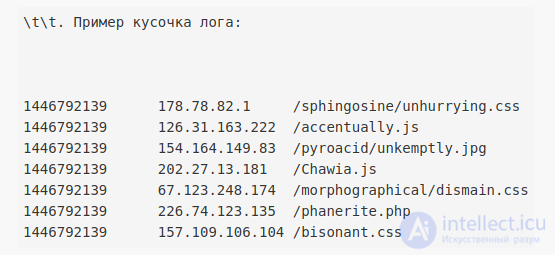
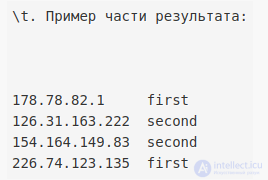
Необходимо посчитать для каждого IP-адреса на какой из 2-х серверов он чаще заходил. Результат должен быть представлен в виде:
К сожалению, в отличие от реляционных баз данных, в общем случае объединение двух логов по ключу (в данном случае – по IP-адресу) представляет собой достаточно тяжелую операцию и решается при помощи 3-х MapReduce и паттерна Reduce Join:
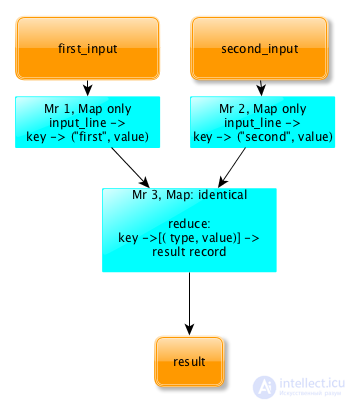
Общая схема ReduceJoin
ReduceJoin работает следующим образом:
key -> (type, value)
key -> [(type, value)]
Важно, что в этот момент на редьюсер попадают записи из обоих логов и при этом по полю type можно идентифицировать, из какого из двух логов попало конкретное значение. Значит данных достаточно, чтобы решить исходную задачу. В нашем случае reducere просто должен посчитать для каждого ключа записей, с каким type встретилось больше и вывести этот type.
Паттерн ReduceJoin описывает общий случай объединения двух логов по ключу. Однако есть частный случай, при котором задачу можно существенно упростить и ускорить. Это случай, при котором один из логов имеет размер существенно меньшего размера, чем другой. Рассмотрим следующую задачу:
Имеются 2 лога. Первый лог содержит лог web-cервера (такой же как в предыдущей задаче), второй файл (размером в 100кб) содержит соответствие URL-> Тематика. Пример 2-го файла:
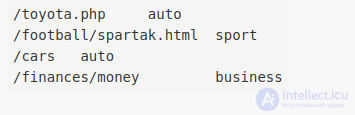
Для каждого IP-адреса необходимо рассчитать страницы какой категории с данного IP-адреса загружались чаще всего.
В этом случае нам тоже необходимо выполнить Join 2-х логов по URL. Однако в этом случае нам не обязательно запускать 3 MapReduce, так как второй лог полностью влезет в память. Для того, чтобы решить задачу при помощи 1-го MapReduce, мы можем загрузить второй лог в Distributed Cache, а при инициализации Mapper’a просто считать его в память, положив его в словарь -> topic.
Далее задача решается следующим образом:
Map:
# находим тематику каждой из страниц первого лога
input_line -> [ip, topic]
Reduce:
Ip -> [topics] -> [ip, most_popular_topic]
Reduce получает на вход ip и список всех тематик, просто вычисляет, какая из тематик встретилась чаще всего. Таким образом задача решена при помощи 1-го MapReduce, а собственно Join вообще происходит внутри map (поэтому если бы не нужна была дополнительная агрегация по ключу – можно было бы обойтись MapOnly job-ом):
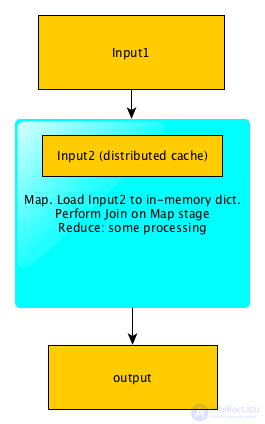
Схема работы MapJoin
В статье мы рассмотрели несколько паттернов и приемов решения задач при помощи MapReduce, показали, как объединять MapReduce-задачи в цепочки и join-ить логи по ключу.
В следующих статьях мы более подробно рассмотрим архитектуру Hadoop, а также инструменты, упрощающие работу с MapReduce и позволяющие обойти его недостатки.
Прочтение данной статьи про big data позволяет сделать вывод о значимости данной информации для обеспечения качества и оптимальности процессов. Надеюсь, что теперь ты понял что такое big data, mapreduce и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Комментарии
Оставить комментарий
Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Термины: Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL