Лекция
Это продолжение увлекательной статьи про сложность алгоритмов.
...
строгая
O-сложность большего масштаба, чем Θ, поэтому эта граница нестрогая. В самом деле, строгой границей здесь будет O( n2 ). Так что мы можем записать, что алгоритм является o( n3 )O-сложность большего масштаба, чем Θ, из чего мы заключаем, что граница нестрогая. Строгой будет O( 1 ), а O( n )можно переписать, как o( n )Θ( n ) алгоритм не может иметь верхнюю границу O( 1 ), поскольку n имеет большую сложность, чем 1. Не забывайте, O обозначает верхнюю границу2n и n — одинаковые, а O и Θ связаны только с асимптотиками. Так что мы имеем O( 2n ) = O( n ), следовательно, граница строгая, поскольку сложность равна ΘO-сложность алгоритма проще, чем его Θ-сложность.
О говорит нам о том, что наш код никогда не будет работать медленнее определенного предела. Из этого мы получаем основания для оценки: достаточно ли хороша наша программа? Если же мы поступим противоположным образом, сделав имеющийся код лучше, и найдем сложность того, что получится, то мы задействуем Ω-нотацию. Таким образом, Ω дает нам сложность, лучше которой наша программа быть не может. Она полезна, если мы хотим доказать, что программа работает медленно или алгоритм является плохим. Так же ее можно применить, когда мы утверждаем, что алгоритм слишком медленный для использования в данном конкретном случае. Например, высказывание, что алгоритм является Ω( n3 ), означает, что алгоритм не лучше, чемn3. Он может быть Θ( n3 ), или Θ( n4 ), или еще хуже, но мы будем знать предел его «хорошести». Таким образом, Ω дает нам нижнюю границу сложности нашего алгоритма. Аналогично ο, мы можем писать ω, если знаем, что этот предел нестрогий. Например, Θ( n3 ) алгоритм является ο( n4 ) и ω( n2 ). Ω( n ) произносится как «большое омега от n», в то время как ω( n ) произносится «маленькое омега от n».
O( 1 ) и Ω( 1 ). Нестрогой О-границей будет O( n ). Напоминаю, что О дает нам верхний предел. Поскольку n лежит на шкале выше, чем 1, то это — нестрогий предел, и мы также можем записать его как o( n ). А вот найти нестрогий предел для Ω мы не можем, потому что не существует функции ниже, чем 1. Так что придется иметь дело со строгой границейO( n ), поскольку n больше, чем √n. А поскольку эта граница нестрогая, то можем написать o( n ). В качестве нижней нестрогой границы мы попросту используем Ω( 1 ) (или ω( 1 ))O( n ) и Ω( n ). Нестрогими могут быть ω( 1 ) и o( n3 ). Не самые лучшие границы, поскольку обе достаточно далеки от оригинальной сложности, но они подходят под наше определениеO( n2 ) и Ω( n2 ). В качестве нестрогих границ мы используем ω( 1 ) и o( n3 ), как и в предыдущем примереO( n3 ) и Ω( n3 ), соответственно. Двумя нестрогими границами могут быть ω( √n n2 ) и o( √n n3 ). Хотя эти пределы по-прежнему нестрогие, но они лучше тех, что мы выводили вышеO и Ω вместо Θ, в том, что мы можем быть не уверены в точности найденных нами границ или просто не хотим копать алгоритм глубже.O и Θ.Ω и дает нам нижний предел поведения нашей функции (т.е. мы улучшаем программу, чтобы она вычисляла меньшее количество инструкций), мы все еще ссылаемся на анализ наихудшего случая. Это происходит потому, что мы подаем на вход программы наихудший набор данных и анализируем ее поведение.| Оператор сравнения асимптотических оценок | Оператор сравнения чисел |
|---|---|
| Алгоритм является o( что-то ) | Число < чего-то |
| Алгоритм является O( что-то ) | Число ≤ чего-то |
| Алгоритм является Θ( что-то ) | Число = чему-то |
| Алгоритм является Ω( что-то ) | Число ≥ чего-то |
| Алгоритм является ω( что-то ) | Число > чего-то |
O, o, Ω, ω и Θ необходимы время от времени, O используется чаще всего, поскольку его проще найти, чем Θ, и оно более полезно на практике, чем Ω.
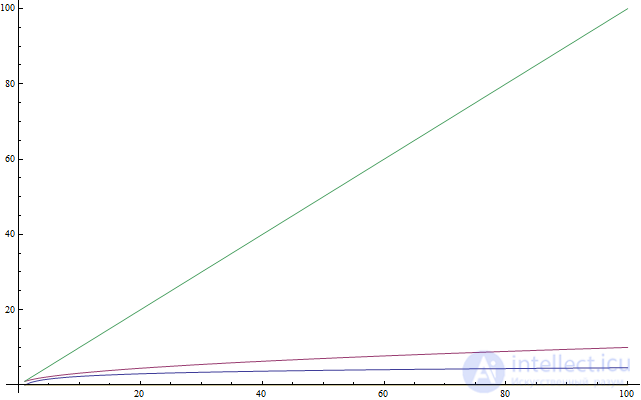
f(n) = n, красный — f(n) = sqrt(n), а наименее быстро возрастающий — f(n) = log(n). Далее: подобно тому, как взятие квадратного корня является операцией, обратной возведению в квадрат, логарифм — обратная операция возведению чего-либо в степень.2x = 1024x, спросим себя: в какую степень надо возвести 2, чтобы получить 1024? Ответ: в десятую. В самом деле, 210 = 1024, что легко проверить. Логарифмы помогают нам описать данную задачу, используя новую нотацию. В данном случае, 10 является логарифмом 1024 и записывается, как log( 1024 ). Читается: «логарифм 1024». Поскольку мы использовали 2 в качестве основания, то такие логарифмы называются «по основанию 2». Основанием может быть любое число, но в этой статье мы будем использовать только двойку. Если вы ученик-олимпиадник и не знакомы с логарифмами, то я рекомендую вам попрактиковаться после того, как закончите чтение этой статьи. В информатике логарифмы по основанию 2 распространены больше, чем какие-либо другие, поскольку часто мы имеем всего две сущности: 0 и 1. Также существует тенденция разбивать объемные задачи пополам, а половин, как известно, тоже бывает всего две. Поэтому для дальнейшего чтения статьи вам достаточно иметь представление только о логарифмах по основанию 2.
x = 6. Таким образом, log( 64 ) = 62x = 6 (потому что log( 64 ) = 6 из предыдущего примера) и, следовательно, x = 32x = 2, откуда x = 1. Это легко заметить по исходному уравнению, поскольку степень 1 дает основание в качестве результатаlog( 1 ) = 0), получим x = 02x + 2x — это тоже самое, что и 2 * (2x). Умножение на 2 даст 2x + 1, и мы получим уравнение 2x + 1 = 32. Находим, что log( 32 ) = 5, откудаx + 1 = 5 и x = 4.22x = 64, что мы уже делали выше. Ответ: x = 35 * 4 * 3 * 2 * 1. Обозначается он как «5!» и произносится «факториал пяти» (впрочем, некоторые предпочитают «ПЯТЬ!!!11»).
def factorial( n ):
if n == 1:
return 1
return n * factorial( n - 1 )
n, то она будет вычисляться n раз. (Если вы в этом не уверены, то можете вручную расписать ход вычисления при n = 5, чтобы определить, как это на самом деле работает.) Таким образом, мы видим, что эта функция является Θ( n ).Θ( n )).
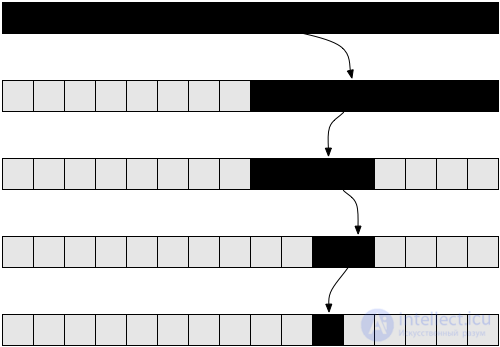

floor() или ceil(). Однако, предположим, что в нашем случае деление всегда будет успешным, наш код защищен от ошибок off-by-one, и все, что мы хотим — это проанализировать сложность данного метода. Если вы никогда раньше не реализовывали бинарный поиск, то можете сделать это на вашем любимом языке программирования. Такая задача по-настоящему поучительна.n на первом рекурсивном вызове, n / 2 на втором, n / 4 на третьем и так далее. В общем, наш массив разбивается пополам на каждом вызове до тех пор, пока мы не достигнем единицы. Давайте запишем количество элементов в массиве на каждом вызове:nn / 2n / 4n / 8n / 2i1n / 2i элементов. Мы каждый раз разбиваем его пополам, что подразумевает деление количества элементов на два (равноценно умножению знаменателя на два). Проделав это i раз, получим n / 2i. Процесс будет продолжаться, и из каждого большого i мы будем получать меньшее количество элементов до тех пор, пока не достигнем единицы. Если мы захотим узнать, на какой итерации это произошло, нам нужно будет просто решить следующее уравнение:1 = n / 2ibinarySearch(), так что узнав из него i, мы будем знать номер последней рекурсивной итерации. Умножив обе части на 2i, получим:2i = ni = log( n )log( n ), где n — размер оригинального массива.n = 32 (массив из 32-х элементов). Сколько раз нам потребуется разделить его, чтобы получить один элемент? Считаем: 32 → 16 → 8 → 4 → 2 → 1 — итого 5 раз, что является логарифмом 32. Таким образом, сложность бинарного поиска равна Θ( log( n ) ).log( n ) намного меньше n, из чего правомерно заключить, что первый намного быстрее второго. Так что имеет смысл хранить массивы в отсортированном виде, если мы собираемся часто искать в них значения.
O( 1 ), O( log( n ) ), O( n ), O( n2 ) и так далее. Вы знакомы с символами o, O, ω, Ω, Θ и понятием «наихудшего случая». Если вы добрались до этого места, то моя статья уже выполнила свою задачу.merge, и пусть она принимает два уже отсортированных массива и соединяет их в один (тоже отсортированный). Это легко сделать:
def merge( A, B ):
if empty( A ):
return B
if empty( B ):
return A
if A[ 0 ] < B[ 0 ]:
return concat( A[ 0 ], merge( A[ 1...A_n ], B ) )
else:
return concat( B[ 0 ], merge( A, B[ 1...B_n ] ) )
concat принимает элемент («голову») и массив («хвост») и соединяет их, возвращая новый массив с «головой» в качестве первого элемента и «хвостом» в качестве оставшихся элементов. Например, concat( 3, [ 4, 5, 6 ] ) вернет [ 3, 4, 5, 6 ]. Мы используем A_n иB_n, чтобы обозначить размеры массивов A и B соответственно.
Θ( n ), где n — длина результирующего массива (n = A_n + B_n).
merge является Θ( n ).
def mergeSort( A, n ):
if n = 1:
return A # it is already sorted
middle = floor( n / 2 )
leftHalf = A[ 1...middle ]
rightHalf = A[ ( middle + 1 )...n ]
return merge( mergeSort( leftHalf, middle ), mergeSort( rightHalf, n - middle ) )
mergeSort (т.е. проверьте, что она верно сортирует переданный ей массив). Если вы не можете понять, почему она в принципе работает, то прорешайте вручную небольшой пример. При этом не забудьте убедиться, что leftHalf и rightHalf получаются при разбиении массива примерно пополам. Разбиение не обязательно должно приходиться точно на середину, если, например, массив содержит нечетное количество элементов (вот для чего нам нужна функция floor).mergeSort. На каждом шаге мы разбиваем исходный массив на две равные части (аналогично binarySearch). Однако, в этом случае дальнейшие вычисления происходят на обеих частях. После возврата рекурсии мы применяем к результатам операцию merge, что занимает Θ( n ) времени.n / 2 каждая. Когда мы будем их соединять, в операции будут участвовать nэлементов, следовательно, время выполнения будет Θ( n ). Рисунок ниже поясняет эту рекурсию: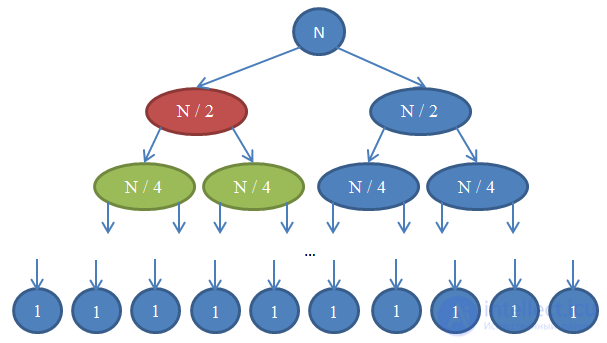
mergeSort. Число в кружке показывает количество элементов в массиве, который будет отсортирован. Верхний синий кружок — первоначальный вызов mergeSort для массива, размером n. Стрелочки показывают рекурсивные вызовы между функциями. Оригинальный вызов mergeSort порождает два новых для массивов, размером n / 2 каждый. В свою очередь, каждый из них порождает еще два вызова с массивами в n / 4 элементов, и так далее до тех пор, пока мы не получим массив размера 1. Эта диаграмма называется рекурсивным деревом, потому что иллюстрирует работу рекурсии и выглядит как дерево (точнее, как инверсия дерева с корнем вверху и листьями внизу).n. Так же обратите внимание, что каждый вызывающий узел использует для операции merge результаты, полученные от вызываемых узлов. Например, красный узел сортирует n / 2 элементов. Чтобы сделать это, он разбивает n / 2 массив на два по n / 4, рекурсивно вызывает с каждым из них mergeSort (зеленые узлы) и объединяет результаты в единое целое размером n / 2.Θ( n ). Мы знаем, что количество таких строк, называемое глубиной рекурсивного дерева, будет log( n ). Основанием для этого являются те же аргументы, которые мы использовали для бинарного поиска. Итак, у нас log( n ) строк со сложностью Θ( n ), следовательно, общая сложность mergeSort: Θ( n * log( n ) ). Это намного лучше, чем Θ( n2 ), которую нам дает сортировка выбором (помните, log( n ) намного меньше n, поэтому n * log( n ) так же намного меньше n * n = n2).Θ( n * log( n ) ) широко используются на практике. Например, ядро Linux использует алгоритм, называемый «сортировкой кучей», который имеет такое же время выполнения, как и сортировка слиянием. Заметим, что мы не будем доказывать оптимальность данных алгоритмов сортировки. Это потребовало бы гораздо более громоздких математических аргументов, но будьте уверены: с точки зрения сложности нельзя найти вариант лучше.Существует несколько способов измерения сложности алгоритма. Программисты обычно сосредотачивают внимание на скорости алгоритма, но не менее важны и другие показатели – требования к объему памяти, свободному месте на диске. Использование быстрого алгоритма не приведет к ожидаемым результатам, если для его работы понадобится больше памяти, чем есть у компьютера.
При сравнении различных алгоритмов важно знать, как их сложность зависит от объема входных данных. Допустим, при сортировке одним методом обработка тысячи чисел занимает 1 с., а обработка миллиона чисел – 10 с., при использовании другого алгоритма может потребоваться 2 с. и 5 с. соответственно. В таких условиях нельзя однозначно сказать, какой алгоритм лучше.
В общем случае сложность алгоритма можно оценить по порядку величины. Алгоритм имеет сложность O(f(n)), если при увеличении размерности входных данных N, время выполнения алгоритма возрастает с той же скоростью, что и функция f(N). Рассмотрим код, который для матрицы A[NxN] находит максимальный элемент в каждой строке.
for i:=1 to N do
begin
max:=A[i,1];
for j:=1 to N do
begin
if A[i,j]>max then
max:=A[i,j]
end;
writeln(max);
end;
В этом алгоритме переменная i меняется от 1 до N. При каждом изменении i, переменная j тоже меняется от 1 до N. Во время каждой из N итераций внешнего цикла, внутренний цикл тоже выполняется N раз. Общее количество итераций внутреннего цикла равно N*N. Это определяет сложность алгоритма O(N^2).
Оценивая порядок сложности алгоритма, необходимо использовать только ту часть, которая возрастает быстрее всего. Предположим, что рабочий цикл описывается выражением N^3+N. В таком случае его сложность будет равна O(N^3). Рассмотрение быстро растущей части функции позволяет оценить поведение алгоритма при увеличении N. Например, при N=100, то разница между N^3+N=1000100 и N=1000000 равна всего лишь 100, что составляет 0,01%.
При вычислении O можно не учитывать постоянные множители в выражениях. Алгоритм с рабочим шагом 3N^3 рассматривается, как O(N^3). Это делает зависимость отношения O(N) от изменения размера задачи более очевидной.
Наиболее сложными частями программы обычно является выполнение циклов и вызов процедур. В предыдущем примере весь алгоритм выполнен с помощью двух циклов.
Если одна процедура вызывает другую, то необходимо более тщательно оценить сложность последней. Если в ней выполняется определенное число инструкций (например, вывод на печать), то на оценку сложности это практически не влияет. Если же в вызываемой процедуре выполняется O(N) шагов, то функция может значительно усложнить алгоритм. Если же процедура вызывается внутри цикла, то влияние может быть намного больше.
В качестве примера рассмотрим две процедуры: Slow со сложностью O(N^3) и Fast со сложностью O(N^2).
procedure Slow;
var
i,j,k: integer;
begin
for i:=1 to N do
for j:=1 to N do
for k:=1 to N do
{какое-то действие}
end;
procedure Fast;
var
i,j: integer;
begin
for i:=1 to N do
for j:=1 to N do
Slow;
end;
procedure Both;
begin
Fast;
end;
Если во внутренних циклах процедуры Fast происходит вызов процедуры Slow, то сложности процедур перемножаются. В данном случае сложность алгоритма составляет O(N^2 )*O(N^3 )=O(N^5).
Если же основная программа вызывает процедуры по очереди, то их сложности складываются: O(N^2 )+O(N^3 )=O(N^3). Следующий фрагмент имеет именно такую сложность:
procedure Slow;
var
i,j,k: integer;
begin
for i:=1 to N do
for j:=1 to N do
for k:=1 to N do
{какое-то действие}
end;
procedure Fast;
var
i,j: integer;
begin
for i:=1 to N do
for j:=1 to N do
{какое-то действие}
end;
procedure Both;
begin
Fast;
Slow;
end;
function Factorial(n: Word): integer;
begin
if n > 1 then
Factorial:=n*Factorial(n-1)
else
Factorial:=1;
end;procedure DoubleRecursive(N: integer);
begin
if N>0 then
begin
DoubleRecursive(N-1);
DoubleRecursive(N-1);
end;
end;продолжение следует...
Часть 1 Анализ и оценка сложности алгоритмов, О большое, функции оценки сложности
Часть 2 Оптимальная сортировка - Анализ и оценка сложности алгоритмов, О большое,
Часть 3 Примеры - Анализ и оценка сложности алгоритмов, О большое, функции
Часть 4 Почему О большое может не имеет значения - Анализ и
А как ты думаешь, при улучшении сложность алгоритмов, будет лучше нам? Надеюсь, что теперь ты понял что такое сложность алгоритмов, оценка сложности алгоритмов, анализ сложности алгоритмов, большое o, доминирующий оператор, о большое, big o, рекурсивная сложность, логарифмическая сложность, сложность рекурсивных алгоритмов, функции оценки сложности, практическая оценка сложности алгоритмов и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Алгоритмы и теория алгоритмов
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.

Комментарии
Оставить комментарий
Алгоритмы и теория алгоритмов
Термины: Алгоритмы и теория алгоритмов