Лекция
Привет, Вы узнаете о том , что такое контекстное кодирование, Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое контекстное кодирование, ppm, prediction by partial matching , настоятельно рекомендую прочитать все из категории Теория информации и кодирования.
PPM (англ. Prediction by Partial Matching — предсказание по частичному совпадению) — адаптивный статистический алгоритм сжатия данных без потерь, основанный на контекстном моделировании и предсказании. Модель PPM использует контекст — множество символов в несжатом потоке, предшествующих данному, чтобы предсказывать значение символа на основе статистических данных. Сама модель PPM лишь предсказывает значение символа, непосредственное сжатие осуществляется алгоритмами энтропийного кодирования, как например, алгоритм Хаффмана, арифметическое кодирование.
Длина контекста, который используется при предсказании, обычно сильно ограничена. Эта длина обозначается n и определяет порядок модели PPM, что обозначается как PPM(n). Неограниченные модели также существуют и обозначаются просто PPM*. Если предсказание символа по контексту из n символов не может быть произведено, то происходит попытка предсказать его с помощью n-1 символов. Рекурсивный переход к моделям с меньшим порядком происходит, пока предсказание не произойдет в одной из моделей либо когда контекст станет нулевой длины (n=0). Модели степени 0 и −1 следует описать особо. Модель нулевого порядка эквивалента случаю контекстно-свободного моделирования, когда вероятность символа определяется исключительно из частоты его появления в сжимаемом потоке данных. Подобная модель обычно применяется вместе с кодированием по Хаффману. Модель порядка −1 представляют собой статическую модель, присваивающую вероятности символа определенное фиксированное значение; обычно все символы, которые могут встретиться в сжимаемом потоке данных, при этом считаются равновероятными. Для получения хорошей оценки вероятности символа необходимо учитывать контексты разных длин. PPM представляет собой вариант стратегии перемешивания, когда оценки вероятностей, сделанные на основании контекстов разных длин, объединяются в одну общую вероятность. Полученная оценка кодируется любым энтропийным кодером (ЭК), обычно это некая разновидность арифметического кодера. На этапе энтропийного кодирования и происходит собственно сжатие.
| Определение: |
| Адаптивное моделирование (adaptive context modeling) — метод моделирования, при котором, по мере кодирования модель изменяется по заданному алгоритму. |
| Определение: |
| Энтропийное кодирование (entropy coding) — кодирование последовательности значений с возможностью однозначного восстановления с целью уменьшения объема данных с помощью усреднения вероятностей появления элементов в закодированной последовательности. |
Обычно термин РРМРРМ используется для обозначения контекстных методов в общем, по этой причине далее будет рассматриваться некий обобщенный алгоритм РРМРРМ.
РРМРРМ (Prediction by partial matching) — адаптивный алгоритм сжатия данных без потерь, основанный на контекстном моделировании и предсказании. Исходно кодеру и декодеру поставлена в соответствие начальная модель источника данных. Будем считать, что она состоит из КМ(−1), присваивающей одинаковую вероятность всем символам алфавита входной последовательности. После обработки текущего символа кодер и декодер изменяют свои модели одинаковым образом, в частности наращивая величину оценки вероятности рассматриваемого символа. Следующий символ кодируется (декодируется) на основании новой, измененной модели, после чего модель снова модифицируется и т. д. На каждом шаге обеспечивается идентичность модели кодера и декодера за счет применения одинакового механизма ее обновления.
Если символ «s » обрабатывается при помощи РРМРРМ, то, в первую очередь рассматривается KM(N) Если она оценивает вероятность «s » числом, не равным нулю, то сама и используется для кодирования «s ». Иначе выдается сигнал в виде символа ухода, и на основе меньшей по порядку KM(N−1) производится очередная попытка оценить вероятность «s ». Кодирование происходит через уход к КМКМ меньших порядков до тех пор, пока «s » не будет оценен. КМ(−1)КМ(−1) гарантирует, что это в конце концов произойдет. Таким образом, каждый символ кодируется серией кодов символа ухода, за которой следует код самого символа. Из этого следует, что вероятность ухода также можно рассматривать как вероятность перехода к контекстной модели меньшего порядка.
РРМ лишь предсказывает значение символа, непосредственное сжатие осуществляется алгоритмами энтропийного кодирования, как например, алгоритм Хаффмана или арифметическое кодирование.
Большое значение для алгоритма PPM имеет проблема обработки новых символов, еще не встречавшихся во входном потоке. Это проблема носит название проблема нулевой частоты. Некоторые варианты реализаций PPM полагают счетчик нового символа равным фиксированной величине, например, единице. Другие реализации, как например, PPM-D, увеличивают псевдосчетчик нового символа каждый раз, когда, действительно, в потоке появляется новый символ (другими словами, PPM-D оценивает вероятность появления нового символа как отношение числа уникальных символов к общему числу используемых символов).
Опубликованные исследования алгоритмов семейства PPM появились в середине 1980-х годов. Программные реализации не были популярны до 1990-х годов, потому как модели PPM требуют значительного количества оперативной памяти. Современные реализации PPM являются одними из лучших среди алгоритмов сжатия без потерь для текстов на естественном языке.

Исследования этого семейства алгоритмов публикуются с середины 1980-х годов . Однако программные реализации не пользовались популярностью до середины 1990-х годов из-за высокой потребности в энергозависимых ресурсах памяти . Самые последние реализации PPM являются одними из лучших систем сжатия без потерь для текста на естественном языке .
Имеется последовательность символов “абвавабввбббв” алфавита {а,б,в,г}, которая уже была закодирована.


Пусть счетчик символа ухода равен единице для всех КМ, при обновлении модели счетчики символов увеличиваются на единицу во всех активных КМКМ, применяется метод исключения и максимальная длина контекста равна трем, т. е. N=3 . Первоначально модель состоит из КМ(−1), в которой счетчики всех четырех символов алфавита имеют значение 11. Состояние модели обработки последовательности “абвавабввбббв” представлено на рис.3, где прямоугольниками обозначены контекстные модели, при этом для каждой КМ указан курсивом контекст, а также встречавшиеся в контексте символы и их частоты.

Пусть текущий символ равен «г», т. е. «?» = «гг», тогда процесс его кодирования будет выглядеть следующим образом. Сначала рассматривается контекст 3-го порядка “ббв”. Ранее он не встречался, поэтому кодер, ничего не послав на выход, переходит к анализу статистики для контекста 2-го порядка. В этом контексте (“бв”) встречались символ «а» и символ «в», счетчики которых в соответствующей КМ равны 11 каждый, поэтому символ ухода кодируется с вероятностью 12+1, где в знаменателе число 2 — наблюдавшаяся частота появления контекста “бв”, 1 — значение счетчика символа ухода. В контексте 1-го порядка «вв» дважды встречался символ «а», который исключается (маскируется), один раз также исключаемый «вв» и один раз «б», поэтому оценка вероятности ухода будет равна 1+1. В КМ(0) символ «г» также оценить нельзя, причем все имеющиеся в этой КМ символы «а», «б», «в» исключаются, так как уже встречались нам в КМКМ более высокого порядка. Поэтому вероятность ухода получается равной единице. Цикл оценивания завершается на уровне КМ(−1), где «гг» к этому времени остается единственным до сих пор не попавшимся символом, поэтому он получает вероятность 1 и кодируется посредством 00 бит. Таким образом, при использовании хорошего статистического кодировщика для представления «г» потребуется в целом примерно 2.6 бит. Перед обработкой следующего символа создается КМ для строки “ббв” и производится модификация счетчиков символа «гг» в созданной и во всех просмотренных КМ. В данном случае требуется изменение КМ всех порядков от 0 до N
Алгоритм декодирования абсолютно симметричен алгоритму кодирования. После декодирования символа в текущей КМ проверяется, не является ли он символом ухода; если это так, то выполняется переход к КМКМ порядком ниже. Иначе считается, что исходный символ восстановлен, он записывается в декодированный поток и осуществляется переход к следующему шагу. Содержание процедур обновления счетчиков, создания новых контекстных моделей, прочих вспомогательных действий и последовательность их применения должны быть строго одинаковыми при кодировании и декодировании. Иначе возможна рассинхронизация копий модели кодера и декодера, что рано или поздно приведет к ошибочному декодированию какого-то символа. Начиная с этой позиции вся оставшаяся часть сжатой последовательности будет разжата неправильно. Разница между кодами символов, оценки вероятности которых одинаковы, достигается за счет того, что РРМ-предсказатель передает кодировщику так называемые накопленные частоты (или накопленные вероятности) оцениваемого символа и его соседей или кодовые пространства символов. Так, например, для контекста “бв”“бв” можно составить следующую таблицу:

Хороший кодировщик должен отобразить символ «s» с оценкой вероятности p(s) в код длины log2p(s), что и обеспечит сжатие всей обрабатываемой последовательности в целом.
| Определение: |
| Проблема нулевой частоты (zero frequency problem) — проблема обработки новых символов, еще не встречавшихся во входном потоке. |
На сегодняшний день можно выделить два подхода к решению этой проблемы: априорные методы, основанные на предположениях о природе сжимаемых данных, и адаптивные методы, которые пытаются приспособиться к сжимаемым данным.
Выедем следующие обозначения:
Изобретатели алгоритма РРМ предложили два метода ОВУОВУ: так называемые метод A и метод B. Частные случаи алгоритма РРМРРМ с использованием этих методов называются, соответственно, PPMA и PPMB.
PPMA: EscA=1/(С+1)
PPMB: EscB=(Q−Q1)/С
Затем был разработан метод С, а в след за ним метод D:
PPMC: EscC=Q/(С+Q)
PPMD: EscD=Q/(2⋅С)
| Определение: |
| SEE (Secondary Escape Estimation) — модель оценки, которая адаптируется к обрабатываемым данным. |
Для нахождения ОВУОВУ строятся контексты уходаконтексты ухода (Escape Context), формируемые из различный полей. Всего используется 44 поля, в которых содержится информация о:
ОВУОВУ для текущего контекста находится путем взвешивания оценок, которые дают три контекста ухода (order−2 EC , order−1 EC, order−0 EC, соответствующие текущему РРМ−контексту. Order−2 EC наиболее точно соответствует текущему контексту, контексты ухода порядком ниже формируются путем выбрасывания части информации полей order−2 EC.
При взвешивании контекстов ухода используются следующие веса w:
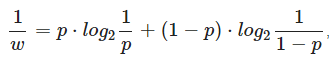 , где p−ОВУ, которую дает данный взвешиваемый контекст.
, где p−ОВУ, которую дает данный взвешиваемый контекст.
Величину, которая формируется из фактического количества успешных кодирований и количества уходов в PPM-контекстах, соответствующих этому EC обозначим как pi.
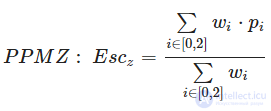
Варианты алгоритма PPM на данный момент широко используются, главным образом для компрессии избыточной информации и текстовых данных. Следующие архиваторы используют PPM :
Исследование, описанное в статье про контекстное кодирование, подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое контекстное кодирование, ppm, prediction by partial matching и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Теория информации и кодирования

Комментарии