Лекция
Привет, Вы узнаете о том , что такое алгоритм свёрточного декодирования витерби , Разберем основные их виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое алгоритм свёрточного декодирования витерби , настоятельно рекомендую прочитать все из категории Теория информации и кодирования.
В 1967 году Эндрю Витерби разработал и проанализировал алгоритм декодирования, основанный на принципе максимального правдоподобия. Алгоритм оптимизирован за счет использования особенностей структуры конкретной решетки кода. Преимущество декодирования Витерби по сравнению с декодированием по методу полного перебора заключается в том, что сложность декодера Витерби не является функцией количества символов в последовательности кодовых слов.
Алгоритм включает в себя вычисление меры подобия (или расстояния), между сигналом, полученным в момент времени  , и всеми путями решетки, входящими в каждое состояние в момент времени
, и всеми путями решетки, входящими в каждое состояние в момент времени  . В алгоритме Витерби не рассматриваются те пути решетки, которые, согласно принципу максимального правдоподобия, заведомо не могут быть оптимальными. Если в одно и то же состояние входят два пути, выбирается тот, который имеет лучшую метрику; такой путь называется выживающим. Отбор выживающих путей выполняется для каждого состояния. Таким образом, декодер углубляется в решетку, принимая решения путем исключения менее вероятных путей. Предварительный отказ от маловероятных путей упрощает процесс декодирования. В 1969 году Джим Омура (англ.) показал, что основу алгоритма Витерби составляет оценка максимального правдоподобия. Отметим, что задачу отбора оптимальных путей можно выразить как выбор кодового слова с максимальной метрикой правдоподобия или минимальной метрикой расстояния.
. В алгоритме Витерби не рассматриваются те пути решетки, которые, согласно принципу максимального правдоподобия, заведомо не могут быть оптимальными. Если в одно и то же состояние входят два пути, выбирается тот, который имеет лучшую метрику; такой путь называется выживающим. Отбор выживающих путей выполняется для каждого состояния. Таким образом, декодер углубляется в решетку, принимая решения путем исключения менее вероятных путей. Предварительный отказ от маловероятных путей упрощает процесс декодирования. В 1969 году Джим Омура (англ.) показал, что основу алгоритма Витерби составляет оценка максимального правдоподобия. Отметим, что задачу отбора оптимальных путей можно выразить как выбор кодового слова с максимальной метрикой правдоподобия или минимальной метрикой расстояния.
Наилучшей схемой декодирования корректирующих кодов является декодирование методом максимального правдоподобия , когда декодер определяет набор условных вероятностей  , соответствующих всем возможным кодовым векторам
, соответствующих всем возможным кодовым векторам  , и решение принимает в пользу кодового слова, соответствующего максимальному . Для двоичного симметричного канала без памяти (канала, в котором вероятности передачи 0 и 1, а также вероятности ошибок вида 0 -> 1 и 1 -> 0 одинаковы, ошибки в j-м и i-м символах кода независимы) декодер максимального правдоподобия сводится к декодеру минимального хеммингова расстояния. Последний вычисляет расстояние Хемминга между принятой последовательностью r и всеми возможными кодовыми векторами и выносит решение в пользу того вектора, который оказывается ближе к принятому. Естественно, что в общем случае такой декодер оказывается очень сложным и при больших размерах кодов
, и решение принимает в пользу кодового слова, соответствующего максимальному . Для двоичного симметричного канала без памяти (канала, в котором вероятности передачи 0 и 1, а также вероятности ошибок вида 0 -> 1 и 1 -> 0 одинаковы, ошибки в j-м и i-м символах кода независимы) декодер максимального правдоподобия сводится к декодеру минимального хеммингова расстояния. Последний вычисляет расстояние Хемминга между принятой последовательностью r и всеми возможными кодовыми векторами и выносит решение в пользу того вектора, который оказывается ближе к принятому. Естественно, что в общем случае такой декодер оказывается очень сложным и при больших размерах кодов  и
и  практически нереализуемым. Характерная структура сверточных кодов (повторяемость структуры за пределами окна длиной ) позволяет создать вполне приемлемый по сложности декодер максимального правдоподобия.
практически нереализуемым. Характерная структура сверточных кодов (повторяемость структуры за пределами окна длиной ) позволяет создать вполне приемлемый по сложности декодер максимального правдоподобия.
На вход декодера поступает сегмент последовательности  длиной
длиной  , превышающей кодовую длину блока . Об этом говорит сайт https://intellect.icu . Назовем окном декодирования. Сравним все кодовые слова данного кода (в пределах сегмента длиной ) с принятым словом и выберем кодовое слово, ближайшее к принятому. Первый информационный кадр выбранного кодового слова принимается в качестве оценки информационного кадра декодированного слова. После этого в декодер вводится
, превышающей кодовую длину блока . Об этом говорит сайт https://intellect.icu . Назовем окном декодирования. Сравним все кодовые слова данного кода (в пределах сегмента длиной ) с принятым словом и выберем кодовое слово, ближайшее к принятому. Первый информационный кадр выбранного кодового слова принимается в качестве оценки информационного кадра декодированного слова. После этого в декодер вводится  новых символов, а введенные ранее самые старые символов сбрасываются, и процесс повторяется для определения следующего информационного кадра. Таким образом, декодер Витерби последовательно обрабатывает кадр за кадром, двигаясь по решетке, аналогичной используемой кодером. В каждый момент времени декодер не знает, в каком узле находится кодер, и не пытается его декодировать. Вместо этого декодер по принятой последовательности определяет наиболее правдоподобный путь к каждому узлу и определяет расстояние между каждым таким путем и принятой последовательностью. Это расстояние называется мерой расходимости пути. В качестве оценки принятой последовательности выбирается сегмент, имеющий наименьшую меру расходимости. Путь с наименьшей мерой расходимости называется выжившим путем.
новых символов, а введенные ранее самые старые символов сбрасываются, и процесс повторяется для определения следующего информационного кадра. Таким образом, декодер Витерби последовательно обрабатывает кадр за кадром, двигаясь по решетке, аналогичной используемой кодером. В каждый момент времени декодер не знает, в каком узле находится кодер, и не пытается его декодировать. Вместо этого декодер по принятой последовательности определяет наиболее правдоподобный путь к каждому узлу и определяет расстояние между каждым таким путем и принятой последовательностью. Это расстояние называется мерой расходимости пути. В качестве оценки принятой последовательности выбирается сегмент, имеющий наименьшую меру расходимости. Путь с наименьшей мерой расходимости называется выжившим путем.
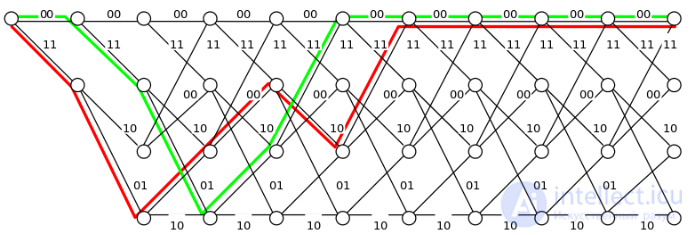
Рассмотрим работу декодера Витерби на простом примере. Полагаем, что кодирование производится с использованием сверточного (7,5)-кода. Пользуясь решетчатой диаграммой кодера, попытаемся, приняв некоторый сегмент , проследить наиболее вероятный путь кодера. При этом для каждого сечения решетчатой диаграммы будем отмечать меру расходимости пути к каждому ее узлу. Предположим, что передана кодовая последовательность U = (00000000…), а принятая последовательность имеет вид r = (10001000…), то есть в первом и в третьем кадрах кодового слова возникли ошибки. Как мы уже убедились, процедура и результат декодирования не зависят от передаваемого кодового слова и определяются только ошибкой, содержащейся в принятой последовательности. Поэтому проще всего считать, что передана нулевая последовательность, то есть U = (00000000…). Приняв первую пару символов (10), декодер определяет меру расходимости для первого сечения решетки, приняв следующую пару символов (00), — для второго сечения и т. д. При этом из входящих в каждый узел путей оставляем путь с меньшей расходимостью, поскольку путь с большей на данный момент расходимостью уже не сможет стать в дальнейшем короче. Заметим, что для рассматриваемого примера начиная с четвертого уровня метрика (или мера расходимости) нулевого пути меньше любой другой метрики. Поскольку ошибок в канале больше не было, ясно, что в конце концов в качестве ответа будет выбран именно этот путь. Из этого примера также видно, что выжившие пути могут достаточно долго отличаться друг от друга. Однако на шестом-седьмом уровне первые семь ребер всех выживших путей совпадут друг с другом. В этот момент согласно алгоритму Витерби и принимается решение о переданных символах, так как все выжившие пути выходят из одной вершины, то есть соответствуют одному информационному символу.
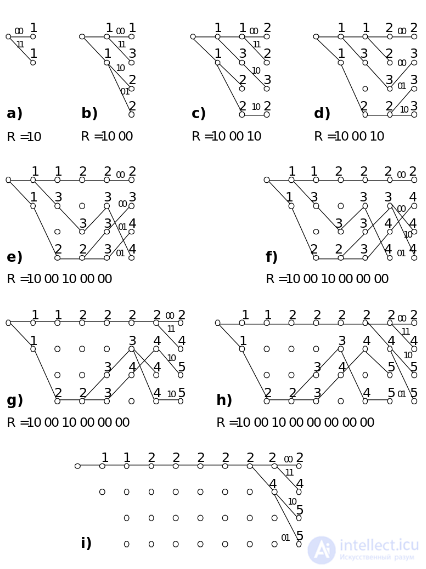
Глубина, на которой происходит слияние выживших путей, не может быть вычислена заранее; она является случайной величиной, зависящей от кратности и вероятности возникающих в канале ошибок. Поэтому на практике обычно не ждут слияния путей, а устанавливают фиксированную глубину декодирования.
На шаге i) степень различия метрик правильного и неправильного путей достаточно велика (  ,
,  ), то есть в данном случае можно было бы ограничить глубину декодирования величиной
), то есть в данном случае можно было бы ограничить глубину декодирования величиной  . Но иногда более длинный к данному сечению путь может оказаться в конечном итоге самым коротким, поэтому особенно увлекаться уменьшением размера окна декодирования b с целью упрощения работы декодера не стоит. На практике глубину декодирования обычно выбирают в диапазоне
. Но иногда более длинный к данному сечению путь может оказаться в конечном итоге самым коротким, поэтому особенно увлекаться уменьшением размера окна декодирования b с целью упрощения работы декодера не стоит. На практике глубину декодирования обычно выбирают в диапазоне  , где
, где  — число исправляемых данным кодом ошибок. Несмотря на наличие в принятом фрагменте двух ошибок, его декодирование произошло без ошибки и в качестве ответа будет принята переданная нулевая последовательность.
— число исправляемых данным кодом ошибок. Несмотря на наличие в принятом фрагменте двух ошибок, его декодирование произошло без ошибки и в качестве ответа будет принята переданная нулевая последовательность.
Физическая реализация декодера Витерби не даст точного потока максимального правдоподобия из-за квантования входного сигнала, показателей ветвления и пути и конечной длины обратной трассировки . Практические реализации приближаются к идеалу в пределах 1 дБ.
На выходе декодера Витерби при декодировании сообщения, поврежденного аддитивным гауссовым каналом, ошибки сгруппированы в пакеты ошибок. Коды с исправлением одиночных ошибок сами по себе не могут исправить такие пакеты, поэтому либо сверточный код и декодер Витерби должны быть разработаны достаточно мощными, чтобы снизить количество ошибок до приемлемого уровня, либо должны использоваться коды с исправлением пакетов .
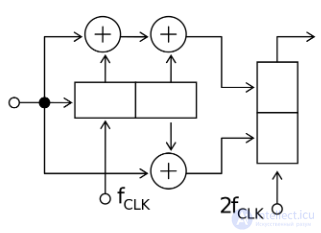
Аппаратный декодер Витерби перфорированных кодов обычно реализуется следующим образом:
Одной из наиболее трудоемких операций является ACS-бабочка, которая обычно реализуется с использованием языка ассемблера и соответствующих расширений набора инструкций (таких как SSE2 ) для ускорения времени декодирования.
Алгоритм декодирования Витерби широко используется в следующих областях:
Исследование, описанное в статье про алгоритм свёрточного декодирования витерби , подчеркивает ее значимость в современном мире. Надеюсь, что теперь ты понял что такое алгоритм свёрточного декодирования витерби и для чего все это нужно, а если не понял, или есть замечания, то не стесняйся, пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Теория информации и кодирования
Из статьи мы узнали кратко, но содержательно про алгоритм свёрточного декодирования витерби
Комментарии